 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Artificial Intelligence based Biological-Tree Construction: Priorities, Methods, Applications and Trends
Oct 07, 2024



Biological tree analysis serves as a pivotal tool in uncovering the evolutionary and differentiation relationships among organisms, genes, and cells. Its applications span diverse fields including phylogenetics, developmental biology, ecology, and medicine. Traditional tree inference methods, while foundational in early studies, face increasing limitations in processing the large-scale, complex datasets generated by modern high-throughput technologies. Recent advances in deep learning offer promising solutions, providing enhanced data processing and pattern recognition capabilities. However, challenges remain, particularly in accurately representing the inherently discrete and non-Euclidean nature of biological trees. In this review, we first outline the key biological priors fundamental to phylogenetic and differentiation tree analyses, facilitating a deeper interdisciplinary understanding between deep learning researchers and biologists. We then systematically examine the commonly used data formats and databases, serving as a comprehensive resource for model testing and development. We provide a critical analysis of traditional tree generation methods, exploring their underlying biological assumptions, technical characteristics, and limitations. Current developments in deep learning-based tree generation are reviewed, highlighting both recent advancements and existing challenges. Furthermore, we discuss the diverse applications of biological trees across various biological domains. Finally, we propose potential future directions and trends in leveraging deep learning for biological tree research, aiming to guide further exploration and innovation in this field.
Must: Maximizing Latent Capacity of Spatial Transcriptomics Data
Jan 15, 2024Spatial transcriptomics (ST) technologies have revolutionized the study of gene expression patterns in tissues by providing multimodality data in transcriptomic, spatial, and morphological, offering opportunities for understanding tissue biology beyond transcriptomics. However, we identify the modality bias phenomenon in ST data species, i.e., the inconsistent contribution of different modalities to the labels leads to a tendency for the analysis methods to retain the information of the dominant modality. How to mitigate the adverse effects of modality bias to satisfy various downstream tasks remains a fundamental challenge. This paper introduces Multiple-modality Structure Transformation, named MuST, a novel methodology to tackle the challenge. MuST integrates the multi-modality information contained in the ST data effectively into a uniform latent space to provide a foundation for all the downstream tasks. It learns intrinsic local structures by topology discovery strategy and topology fusion loss function to solve the inconsistencies among different modalities. Thus, these topology-based and deep learning techniques provide a solid foundation for a variety of analytical tasks while coordinating different modalities. The effectiveness of MuST is assessed by performance metrics and biological significance. The results show that it outperforms existing state-of-the-art methods with clear advantages in the precision of identifying and preserving structures of tissues and biomarkers. MuST offers a versatile toolkit for the intricate analysis of complex biological systems.
Video Captioning in Compressed Video
Jan 02, 2021
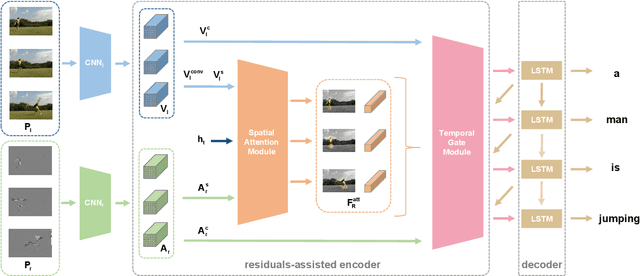
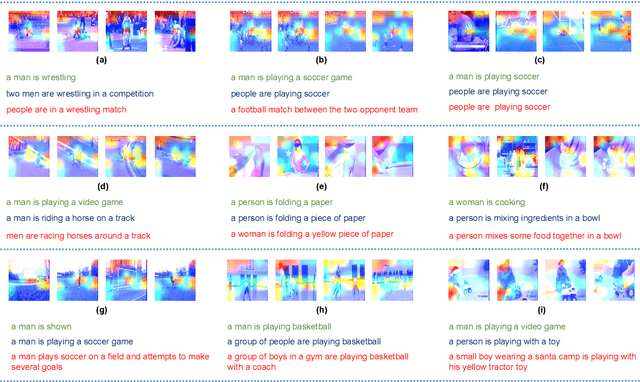

Existing approaches in video captioning concentrate on exploring global frame features in the uncompressed videos, while the free of charge and critical saliency information already encoded in the compressed videos is generally neglected. We propose a video captioning method which operates directly on the stored compressed videos. To learn a discriminative visual representation for video captioning, we design a residuals-assisted encoder (RAE), which spots regions of interest in I-frames under the assistance of the residuals frames. First, we obtain the spatial attention weights by extracting features of residuals as the saliency value of each location in I-frame and design a spatial attention module to refine the attention weights. We further propose a temporal gate module to determine how much the attended features contribute to the caption generation, which enables the model to resist the disturbance of some noisy signals in the compressed videos. Finally, Long Short-Term Memory is utilized to decode the visual representations into descriptions. We evaluate our method on two benchmark datasets and demonstrate the effectiveness of our approach.