 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering-Refined Stable Diffusion for Privacy Compliant Synthetic Data
Dec 09, 2024Growing privacy concerns and regulations like GDPR and CCPA necessitate pseudonymization techniques that protect identity in image datasets. However, retaining utility is also essential. Traditional methods like masking and blurring degrade quality and obscure critical context, especially in human-centric images. We introduce Rendering-Refined Stable Diffusion (RefSD), a pipeline that combines 3D-rendering with Stable Diffusion, enabling prompt-based control over human attributes while preserving posture. Unlike standard diffusion models that fail to retain posture or GANs that lack realism and flexible attribute control, RefSD balances posture preservation, realism, and customization. We also propose HumanGenAI, a framework for human perception and utility evaluation. Human perception assessments reveal attribute-specific strengths and weaknesses of RefSD. Our utility experiments show that models trained on RefSD pseudonymized data outperform those trained on real data in detection tasks, with further performance gains when combining RefSD with real data. For classification tasks, we consistently observe performance improvements when using RefSD data with real data, confirming the utility of our pseudonymized data.
Empowering Source-Free Domain Adaptation with MLLM-driven Curriculum Learning
May 28, 2024Source-Free Domain Adaptation (SFDA) aims to adapt a pre-trained source model to a target domain using only unlabeled target data. Current SFDA methods face challenges in effectively leveraging pre-trained knowledge and exploiting target domain data. Multimodal Large Language Models (MLLMs) offer remarkable capabilities in understanding visual and textual information, but their applicability to SFDA poses challenges such as instruction-following failures, intensive computational demands, and difficulties in performance measurement prior to adaptation. To alleviate these issues, we propose Reliability-based Curriculum Learning (RCL), a novel framework that integrates multiple MLLMs for knowledge exploitation via pseudo-labeling in SFDA. Our framework incorporates proposed Reliable Knowledge Transfer, Self-correcting and MLLM-guided Knowledge Expansion, and Multi-hot Masking Refinement to progressively exploit unlabeled data in the target domain. RCL achieves state-of-the-art (SOTA) performance on multiple SFDA benchmarks, e.g., $\textbf{+9.4%}$ on DomainNet, demonstrating its effectiveness in enhancing adaptability and robustness without requiring access to source data. Code: https://github.com/Dong-Jie-Chen/RCL.
Localizing Moments of Actions in Untrimmed Videos of Infants with Autism Spectrum Disorder
Apr 08, 2024Autism Spectrum Disorder (ASD) presents significant challenges in early diagnosis and intervention, impacting children and their families. With prevalence rates rising, there is a critical need for accessible and efficient screening tools. Leveraging machine learning (ML) techniques, in particular Temporal Action Localization (TAL), holds promise for automating ASD screening. This paper introduces a self-attention based TAL model designed to identify ASD-related behaviors in infant videos. Unlike existing methods, our approach simplifies complex modeling and emphasizes efficiency, which is essential for practical deployment in real-world scenarios. Importantly, this work underscores the importance of developing computer vision methods capable of operating in naturilistic environments with little equipment control, addressing key challenges in ASD screening. This study is the first to conduct end-to-end temporal action localization in untrimmed videos of infants with ASD, offering promising avenues for early intervention and support. We report baseline results of behavior detection using our TAL model. We achieve 70% accuracy for look face, 79% accuracy for look object, 72% for smile and 65% for vocalization.
MobilityGPT: Enhanced Human Mobility Modeling with a GPT model
Feb 05, 2024



Generative models have shown promising results in capturing human mobility characteristics and generating synthetic trajectories. However, it remains challenging to ensure that the generated geospatial mobility data is semantically realistic, including consistent location sequences, and reflects real-world characteristics, such as constraining on geospatial limits. To address these issues, we reformat human mobility modeling as an autoregressive generation task, leveraging Generative Pre-trained Transformer (GPT). To ensure its controllable generation to alleviate the above challenges, we propose a geospatially-aware generative model, MobilityGPT. We propose a gravity-based sampling method to train a transformer for semantic sequence similarity. Then, we constrained the training process via a road connectivity matrix that provides the connectivity of sequences in trajectory generation, thereby keeping generated trajectories in geospatial limits. Lastly, we constructed a Reinforcement Learning from Trajectory Feedback (RLTF) to minimize the travel distance between training and the synthetically generated trajectories. Our experiments on real-world datasets demonstrate that MobilityGPT outperforms state-of-the-art methods in generating high-quality mobility trajectories that are closest to real data in terms of origin-destination similarity, trip length, travel radius, link, and gravity distributions.
From Scarcity to Efficiency: Improving CLIP Training via Visual-enriched Captions
Oct 11, 2023Web-crawled datasets are pivotal to the success of pre-training vision-language models, exemplified by CLIP. However, web-crawled AltTexts can be noisy and potentially irrelevant to images, thereby undermining the crucial image-text alignment. Existing methods for rewriting captions using large language models (LLMs) have shown promise on small, curated datasets like CC3M and CC12M. Nevertheless, their efficacy on massive web-captured captions is constrained by the inherent noise and randomness in such data. In this study, we address this limitation by focusing on two key aspects: data quality and data variety. Unlike recent LLM rewriting techniques, we emphasize exploiting visual concepts and their integration into the captions to improve data quality. For data variety, we propose a novel mixed training scheme that optimally leverages AltTexts alongside newly generated Visual-enriched Captions (VeC). We use CLIP as one example and adapt the method for CLIP training on large-scale web-crawled datasets, named VeCLIP. We conduct a comprehensive evaluation of VeCLIP across small, medium, and large scales of raw data. Our results show significant advantages in image-text alignment and overall model performance, underscoring the effectiveness of VeCLIP in improving CLIP training. For example, VeCLIP achieves a remarkable over 20% improvement in COCO and Flickr30k retrieval tasks under the 12M setting. For data efficiency, we also achieve a notable over 3% improvement while using only 14% of the data employed in the vanilla CLIP and 11% in ALIGN.
DPGOMI: Differentially Private Data Publishing with Gaussian Optimized Model Inversion
Oct 06, 2023High-dimensional data are widely used in the era of deep learning with numerous applications. However, certain data which has sensitive information are not allowed to be shared without privacy protection. In this paper, we propose a novel differentially private data releasing method called Differentially Private Data Publishing with Gaussian Optimized Model Inversion (DPGOMI) to address this issue. Our approach involves mapping private data to the latent space using a public generator, followed by a lower-dimensional DP-GAN with better convergence properties. We evaluate the performance of DPGOMI on standard datasets CIFAR10 and SVHN. Our results show that DPGOMI outperforms the standard DP-GAN method in terms of Inception Score, Fr\'echet Inception Distance, and classification performance, while providing the same level of privacy. Our proposed approach offers a promising solution for protecting sensitive data in GAN training while maintaining high-quality results.
Benchmarking Adversarial Robustness of Compressed Deep Learning Models
Aug 16, 2023



The increasing size of Deep Neural Networks (DNNs) poses a pressing need for model compression, particularly when employed on resource constrained devices. Concurrently, the susceptibility of DNNs to adversarial attacks presents another significant hurdle. Despite substantial research on both model compression and adversarial robustness, their joint examination remains underexplored. Our study bridges this gap, seeking to understand the effect of adversarial inputs crafted for base models on their pruned versions. To examine this relationship, we have developed a comprehensive benchmark across diverse adversarial attacks and popular DNN models. We uniquely focus on models not previously exposed to adversarial training and apply pruning schemes optimized for accuracy and performance. Our findings reveal that while the benefits of pruning enhanced generalizability, compression, and faster inference times are preserved, adversarial robustness remains comparable to the base model. This suggests that model compression while offering its unique advantages, does not undermine adversarial robustness.
Automated Detection of Gait Events and Travel Distance Using Waist-worn Accelerometers Across a Typical Range of Walking and Running Speeds
Jul 10, 2023



Background: Estimation of temporospatial clinical features of gait (CFs), such as step count and length, step duration, step frequency, gait speed and distance traveled is an important component of community-based mobility evaluation using wearable accelerometers. However, challenges arising from device complexity and availability, cost and analytical methodology have limited widespread application of such tools. Research Question: Can accelerometer data from commercially-available smartphones be used to extract gait CFs across a broad range of attainable gait velocities in children with Duchenne muscular dystrophy (DMD) and typically developing controls (TDs) using machine learning (ML)-based methods Methods: Fifteen children with DMD and 15 TDs underwent supervised clinical testing across a range of gait speeds using 10 or 25m run/walk (10MRW, 25MRW), 100m run/walk (100MRW), 6-minute walk (6MWT) and free-walk (FW) evaluations while wearing a mobile phone-based accelerometer at the waist near the body's center of mass. Gait CFs were extracted from the accelerometer data using a multi-step machine learning-based process and results were compared to ground-truth observation data. Results: Model predictions vs. observed values for step counts, distance traveled, and step length showed a strong correlation (Pearson's r = -0.9929 to 0.9986, p<0.0001). The estimates demonstrated a mean (SD) percentage error of 1.49% (7.04%) for step counts, 1.18% (9.91%) for distance traveled, and 0.37% (7.52%) for step length compared to ground truth observations for the combined 6MWT, 100MRW, and FW tasks. Significance: The study findings indicate that a single accelerometer placed near the body's center of mass can accurately measure CFs across different gait speeds in both TD and DMD peers, suggesting that there is potential for accurately measuring CFs in the community with consumer-level smartphones.
Differentially Private Generative Adversarial Networks with Model Inversion
Jan 10, 2022

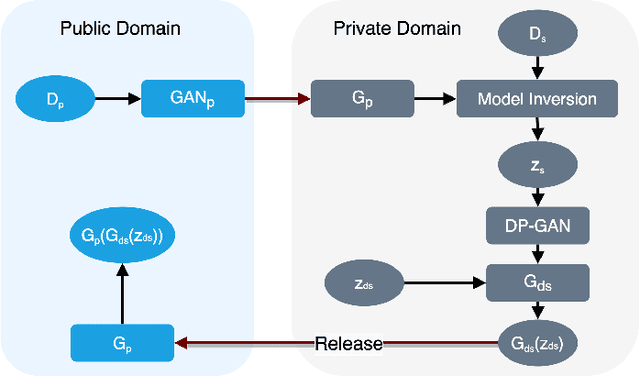
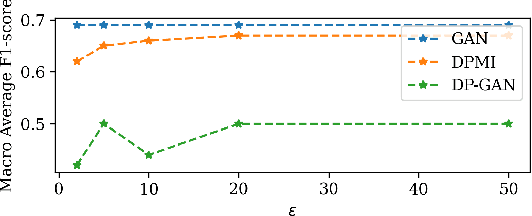
To protect sensitive data in training a Generative Adversarial Network (GAN), the standard approach is to use differentially private (DP) stochastic gradient descent method in which controlled noise is added to the gradients. The quality of the output synthetic samples can be adversely affected and the training of the network may not even converge in the presence of these noises. We propose Differentially Private Model Inversion (DPMI) method where the private data is first mapped to the latent space via a public generator, followed by a lower-dimensional DP-GAN with better convergent properties. Experimental results on standard datasets CIFAR10 and SVHN as well as on a facial landmark dataset for Autism screening show that our approach outperforms the standard DP-GAN method based on Inception Score, Fr\'echet Inception Distance, and classification accuracy under the same privacy guarantee.
A Natural Language Processing and Deep Learning based Model for Automated Vehicle Diagnostics using Free-Text Customer Service Reports
Nov 29, 2021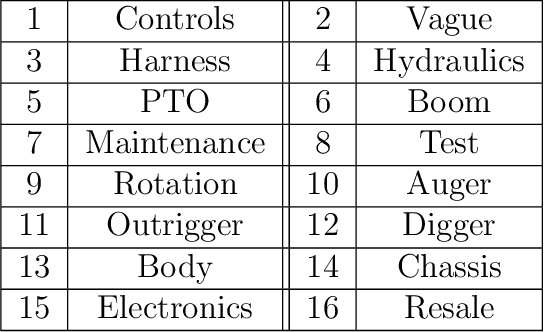
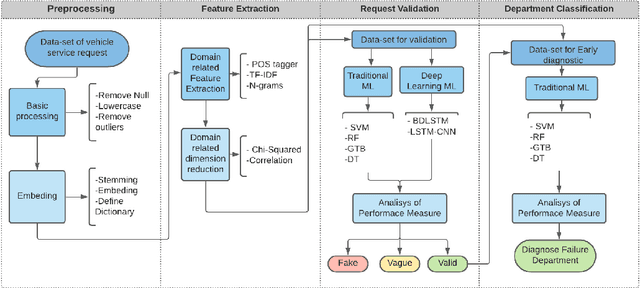

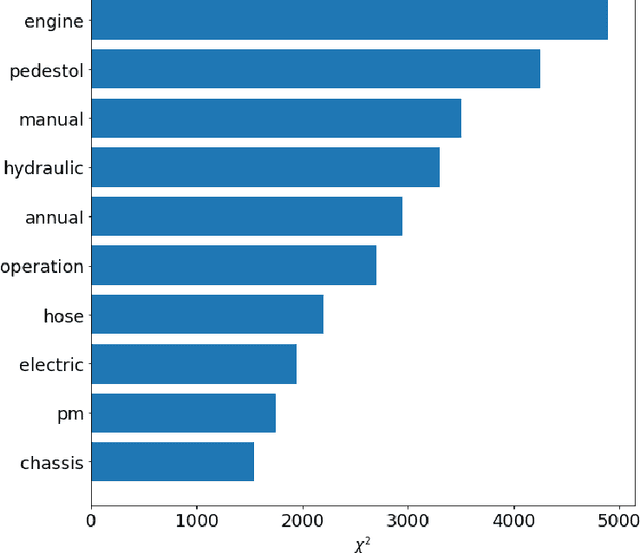
Initial fault detection and diagnostics are imperative measures to improve the efficiency, safety, and stability of vehicle operation. In recent years, numerous studies have investigated data-driven approaches to improve the vehicle diagnostics process using available vehicle data. Moreover, data-driven methods are employed to enhance customer-service agent interactions. In this study, we demonstrate a machine learning pipeline to improve automated vehicle diagnostics. First, Natural Language Processing (NLP) is used to automate the extraction of crucial information from free-text failure reports (generated during customers' calls to the service department). Then, deep learning algorithms are employed to validate service requests and filter vague or misleading claims. Ultimately, different classification algorithms are implemented to classify service requests so that valid service requests can be directed to the relevant service department. The proposed model- Bidirectional Long Short Term Memory (BiLSTM) along with Convolution Neural Network (CNN)- shows more than 18\% accuracy improvement in validating service requests compared to technicians' capabilities. In addition, using domain-based NLP techniques at preprocessing and feature extraction stages along with CNN-BiLSTM based request validation enhanced the accuracy ($>25\%$), sensitivity ($>39\%$), specificity ($>11\%$), and precision ($>11\%$) of Gradient Tree Boosting (GTB) service classification model. The Receiver Operating Characteristic Area Under the Curve (ROC-AUC) reached 0.82.