 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-Centric Active Learning for Temporal Action Segmentation
Apr 16, 2026Temporal action segmentation (TAS) demands dense temporal supervision, yet most of the annotation cost in untrimmed videos is spent identifying and refining action transitions, where segmentation errors concentrate and small temporal shifts disproportionately degrade segmental metrics. We introduce B-ACT, a clip-budgeted active learning framework that explicitly allocates supervision to these high-leverage boundary regions. B-ACT operates in a hierarchical two-stage loop: (i) it ranks and queries unlabeled videos using predictive uncertainty, and (ii) within each selected video, it detects candidate transitions from the current model predictions and selects the top-$K$ boundaries via a novel boundary score that fuses neighborhood uncertainty, class ambiguity, and temporal predictive dynamics. Importantly, our annotation protocol requests labels for only the boundary frames while still training on boundary-centered clips to exploit temporal context through the model's receptive field. Extensive experiments on GTEA, 50Salads, and Breakfast demonstrate that boundary-centric supervision delivers strong label efficiency and consistently surpasses representative TAS active learning baselines and prior state of the art under sparse budgets, with the largest gains on datasets where boundary placement dominates edit and overlap-based F1 scores.
MMTA: Multi Membership Temporal Attention for Fine-Grained Stroke Rehabilitation Assessment
Mar 01, 2026To empower the iterative assessments involved during a person's rehabilitation, automated assessment of a person's abilities during daily activities requires temporally precise segmentation of fine-grained actions in therapy videos. Existing temporal action segmentation (TAS) models struggle to capture sub-second micro-movements while retaining exercise context, blurring rapid phase transitions and limiting reliable downstream assessment of motor recovery. We introduce Multi-Membership Temporal Attention (MMTA), a high-resolution temporal transformer for fine-grained rehabilitation assessment. Unlike standard temporal attention, which assigns each frame a single attention context per layer, MMTA lets each frame attend to multiple locally normalized temporal attention windows within the same layer. We fuse these concurrent temporal views via feature-space overlap resolution, preserving competing local contexts near transitions while enabling longer-range reasoning through layer-wise propagation. This increases boundary sensitivity without additional depth or multi-stage refinement. MMTA supports both video and wearable IMU inputs within a unified single-stage architecture, making it applicable to both clinical and home settings. MMTA consistently improves over the Global Attention transformer, boosting Edit Score by +1.3 (Video) and +1.6 (IMU) on StrokeRehab while further improving 50Salads by +3.3. Ablations confirm that performance gains stem from multi-membership temporal views rather than architectural complexity, offering a practical solution for resource-constrained rehabilitation assessment.
Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Nov 15, 2025Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of "Seeing is Believing", we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o's capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
Localizing Moments of Actions in Untrimmed Videos of Infants with Autism Spectrum Disorder
Apr 08, 2024



Autism Spectrum Disorder (ASD) presents significant challenges in early diagnosis and intervention, impacting children and their families. With prevalence rates rising, there is a critical need for accessible and efficient screening tools. Leveraging machine learning (ML) techniques, in particular Temporal Action Localization (TAL), holds promise for automating ASD screening. This paper introduces a self-attention based TAL model designed to identify ASD-related behaviors in infant videos. Unlike existing methods, our approach simplifies complex modeling and emphasizes efficiency, which is essential for practical deployment in real-world scenarios. Importantly, this work underscores the importance of developing computer vision methods capable of operating in naturilistic environments with little equipment control, addressing key challenges in ASD screening. This study is the first to conduct end-to-end temporal action localization in untrimmed videos of infants with ASD, offering promising avenues for early intervention and support. We report baseline results of behavior detection using our TAL model. We achieve 70% accuracy for look face, 79% accuracy for look object, 72% for smile and 65% for vocalization.
Differentially Private Generative Adversarial Networks with Model Inversion
Jan 10, 2022

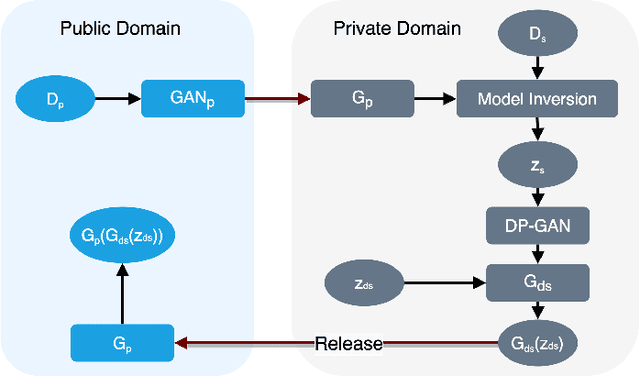
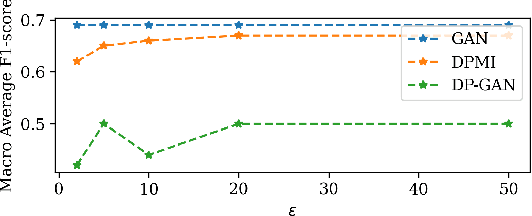
To protect sensitive data in training a Generative Adversarial Network (GAN), the standard approach is to use differentially private (DP) stochastic gradient descent method in which controlled noise is added to the gradients. The quality of the output synthetic samples can be adversely affected and the training of the network may not even converge in the presence of these noises. We propose Differentially Private Model Inversion (DPMI) method where the private data is first mapped to the latent space via a public generator, followed by a lower-dimensional DP-GAN with better convergent properties. Experimental results on standard datasets CIFAR10 and SVHN as well as on a facial landmark dataset for Autism screening show that our approach outperforms the standard DP-GAN method based on Inception Score, Fr\'echet Inception Distance, and classification accuracy under the same privacy guarantee.