 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential Moving Average Normalization for Self-supervised and Semi-supervised Learning
Jan 21, 2021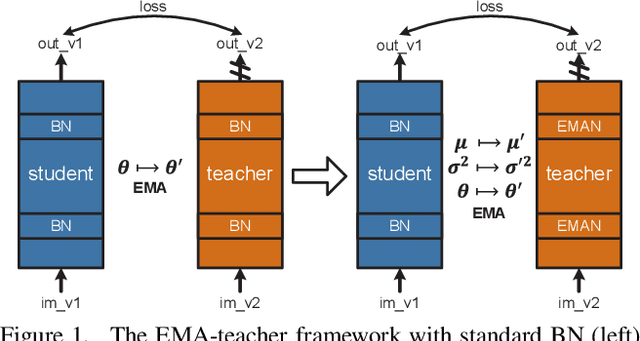
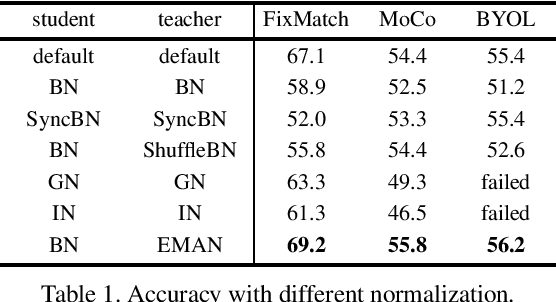
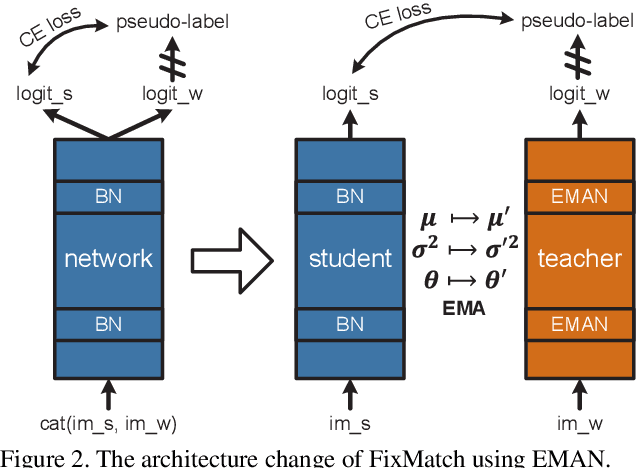
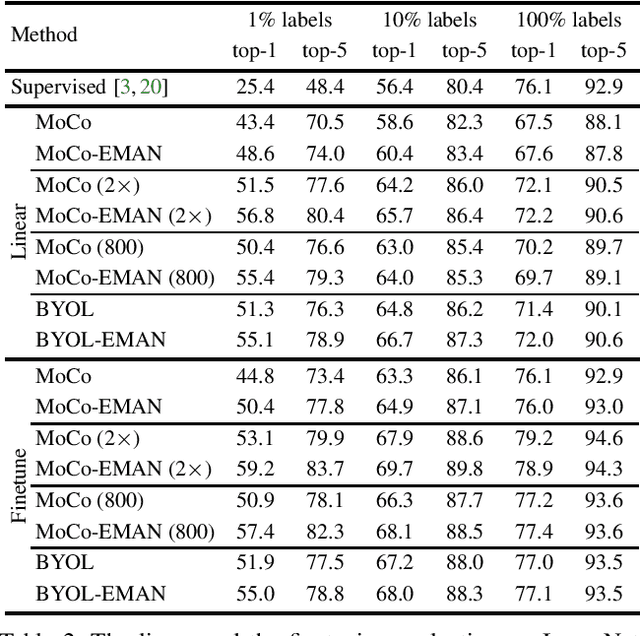
We present a plug-in replacement for batch normalization (BN) called exponential moving average normalization (EMAN), which improves the performance of existing student-teacher based self- and semi-supervised learning techniques. Unlike the standard BN, where the statistics are computed within each batch, EMAN, used in the teacher, updates its statistics by exponential moving average from the BN statistics of the student. This design reduces the intrinsic cross-sample dependency of BN and enhance the generalization of the teacher. EMAN improves strong baselines for self-supervised learning by 4-6/1-2 points and semi-supervised learning by about 7/2 points, when 1%/10% supervised labels are available on ImageNet. These improvements are consistent across methods, network architectures, training duration, and datasets, demonstrating the general effectiveness of this technique.
When Perspective Comes for Free: Improving Depth Prediction with Camera Pose Encoding
Jul 08, 2020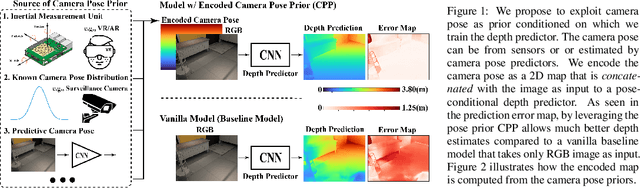
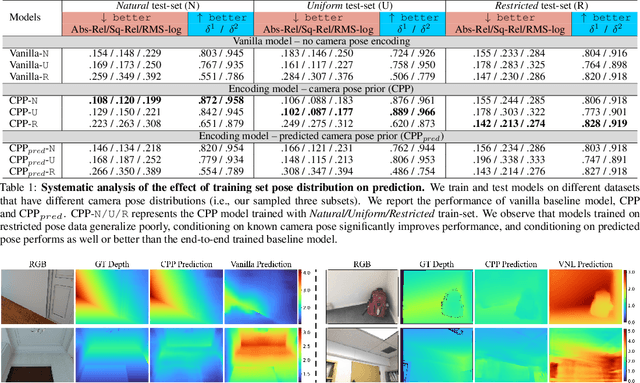
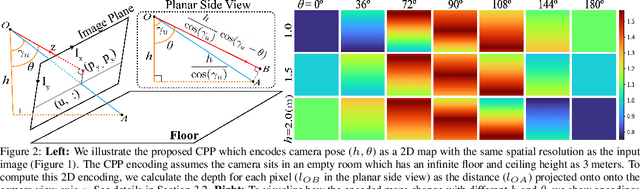

Monocular depth prediction is a highly underdetermined problem and recent progress has relied on high-capacity CNNs to effectively learn scene statistics that disambiguate estimation. However, we observe that such models are strongly biased by the distribution of camera poses seen during training and fail to generalize to novel viewpoints, even when the scene geometry distribution remains fixed. To address this challenge, we propose a factored approach that estimates pose first, followed by a conditional depth estimation model that takes an encoding of the camera pose prior (CPP) as input. In many applications, a strong test-time pose prior comes for free, e.g., from inertial sensors or static camera deployment. A factored approach also allows for adapting pose prior estimation to new test domains using only pose supervision, without the need for collecting expensive ground-truth depth required for end-to-end training. We evaluate our pose-conditional depth predictor (trained on synthetic indoor scenes) on a real-world test set. Our factored approach, which only requires camera pose supervision for training, outperforms recent state-of-the-art methods trained with full scene depth supervision on 10x more data.
Weak Supervision and Referring Attention for Temporal-Textual Association Learning
Jun 27, 2020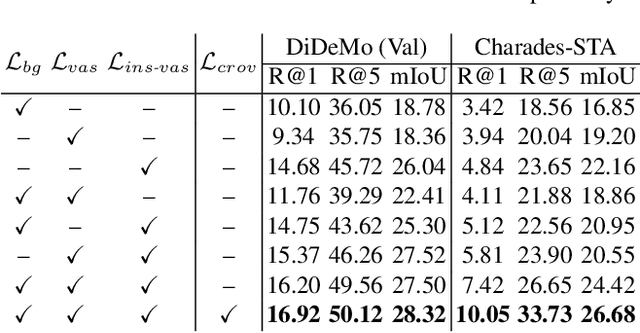
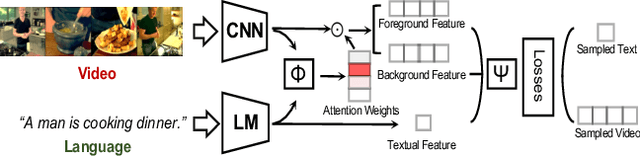
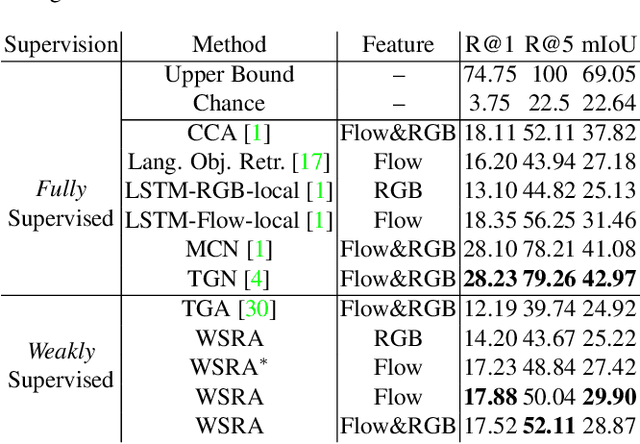
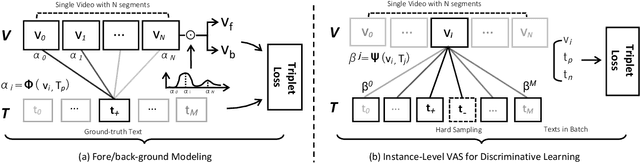
A system capturing the association between video frames and textual queries offer great potential for better video analysis. However, training such a system in a fully supervised way inevitably demands a meticulously curated video dataset with temporal-textual annotations. Therefore we provide a Weak-Supervised alternative with our proposed Referring Attention mechanism to learn temporal-textual association (dubbed WSRA). The weak supervision is simply a textual expression (e.g., short phrases or sentences) at video level, indicating this video contains relevant frames. The referring attention is our designed mechanism acting as a scoring function for grounding the given queries over frames temporally. It consists of multiple novel losses and sampling strategies for better training. The principle in our designed mechanism is to fully exploit 1) the weak supervision by considering informative and discriminative cues from intra-video segments anchored with the textual query, 2) multiple queries compared to the single video, and 3) cross-video visual similarities. We validate our WSRA through extensive experiments for temporally grounding by languages, demonstrating that it outperforms the state-of-the-art weakly-supervised methods notably.
Celeganser: Automated Analysis of Nematode Morphology and Age
May 11, 2020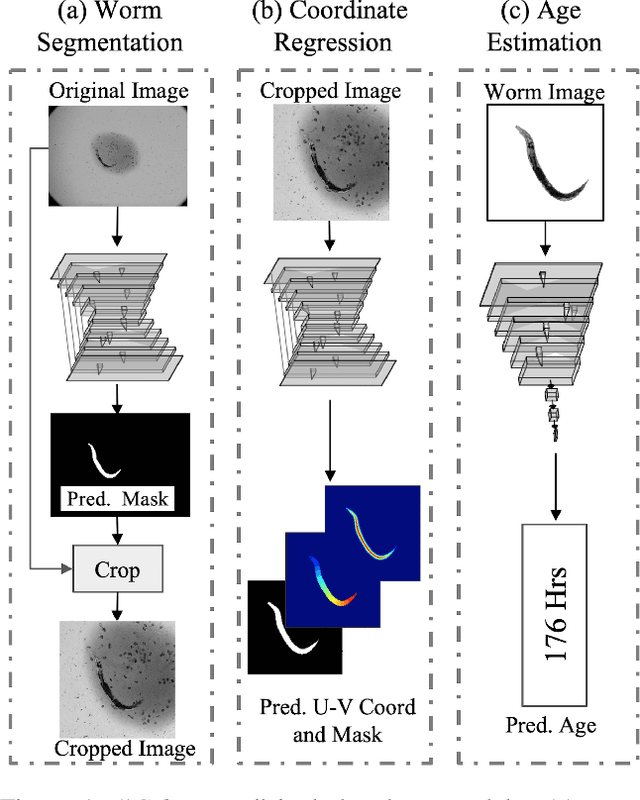

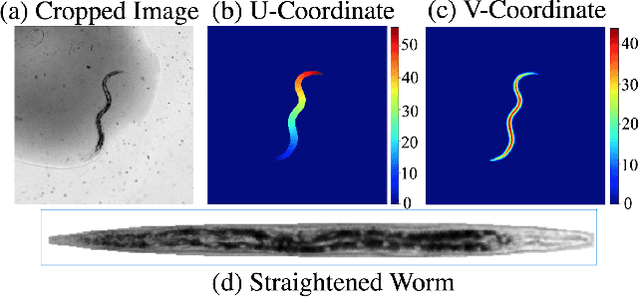
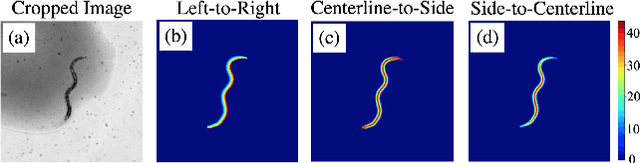
The nematode Caenorhabditis elegans (C. elegans) serves as an important model organism in a wide variety of biological studies. In this paper we introduce a pipeline for automated analysis of C. elegans imagery for the purpose of studying life-span, health-span and the underlying genetic determinants of aging. Our system detects and segments the worm, and predicts body coordinates at each pixel location inside the worm. These coordinates provide dense correspondence across individual animals to allow for meaningful comparative analysis. We show that a model pre-trained to perform body-coordinate regression extracts rich features that can be used to predict the age of individual worms with high accuracy. This lays the ground for future research in quantifying the relation between organs' physiologic and biochemical state, and individual life/health-span.
Domain Decluttering: Simplifying Images to Mitigate Synthetic-Real Domain Shift and Improve Depth Estimation
Feb 27, 2020
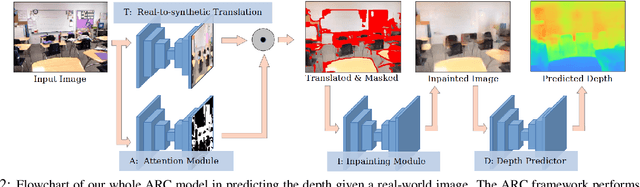
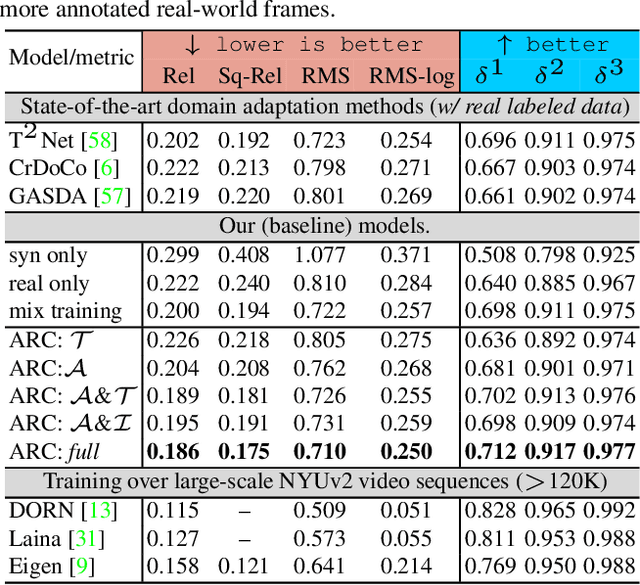
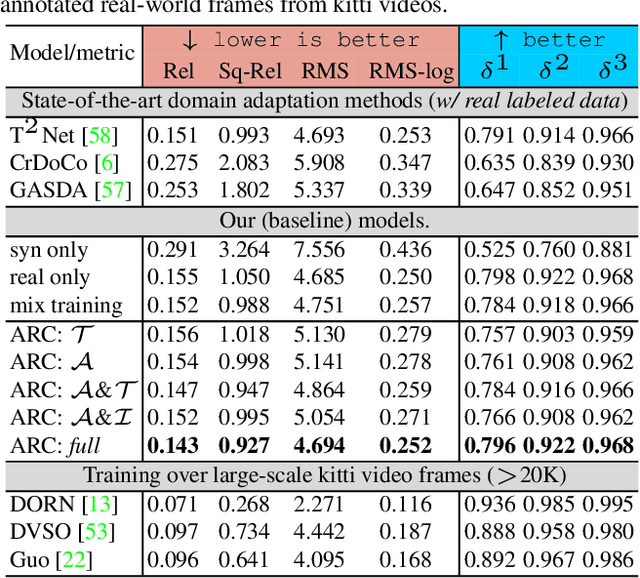
Leveraging synthetically rendered data offers great potential to improve monocular depth estimation, but closing the synthetic-real domain gap is a non-trivial and important task. While much recent work has focused on unsupervised domain adaptation, we consider a more realistic scenario where a large amount of synthetic training data is supplemented by a small set of real images with ground-truth. In this setting we find that existing domain translation approaches are difficult to train and offer little advantage over simple baselines that use a mix of real and synthetic data. A key failure mode is that real-world images contain novel objects and clutter not present in synthetic training. This high-level domain shift isn't handled by existing image translation models. Based on these observations, we develop an attentional module that learns to identify and remove (hard) out-of-domain regions in real images in order to improve depth prediction for a model trained primarily on synthetic data. We carry out extensive experiments to validate our attend-remove-complete approach (ARC) and find that it significantly outperforms state-of-the-art domain adaptation methods for depth prediction. Visualizing the removed regions provides interpretable insights into the synthetic-real domain gap.
Geometric Pose Affordance: 3D Human Pose with Scene Constraints
May 19, 2019
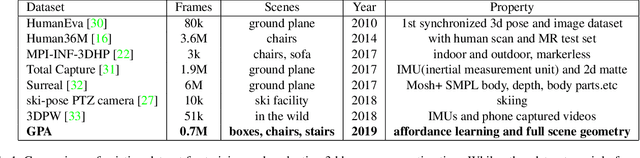
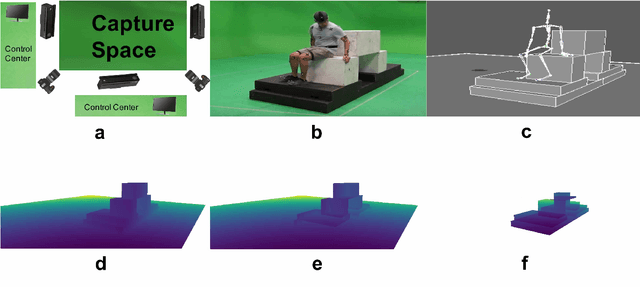
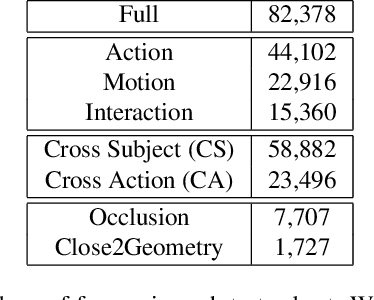
Full 3D estimation of human pose from a single image remains a challenging task despite many recent advances. In this paper, we explore the hypothesis that strong prior information about scene geometry can be used to improve pose estimation accuracy. To tackle this question empirically, we have assembled a novel $\textbf{Geometric Pose Affordance}$ dataset, consisting of multi-view imagery of people interacting with a variety of rich 3D environments. We utilized a commercial motion capture system to collect gold-standard estimates of pose and construct accurate geometric 3D CAD models of the scene itself. To inject prior knowledge of scene constraints into existing frameworks for pose estimation from images, we introduce a novel, view-based representation of scene geometry, a $\textbf{multi-layer depth map}$, which employs multi-hit ray tracing to concisely encode multiple surface entry and exit points along each camera view ray direction. We propose two different mechanisms for integrating multi-layer depth information pose estimation: input as encoded ray features used in lifting 2D pose to full 3D, and secondly as a differentiable loss that encourages learned models to favor geometrically consistent pose estimates. We show experimentally that these techniques can improve the accuracy of 3D pose estimates, particularly in the presence of occlusion and complex scene geometry.
Modularized Textual Grounding for Counterfactual Resilience
Apr 07, 2019
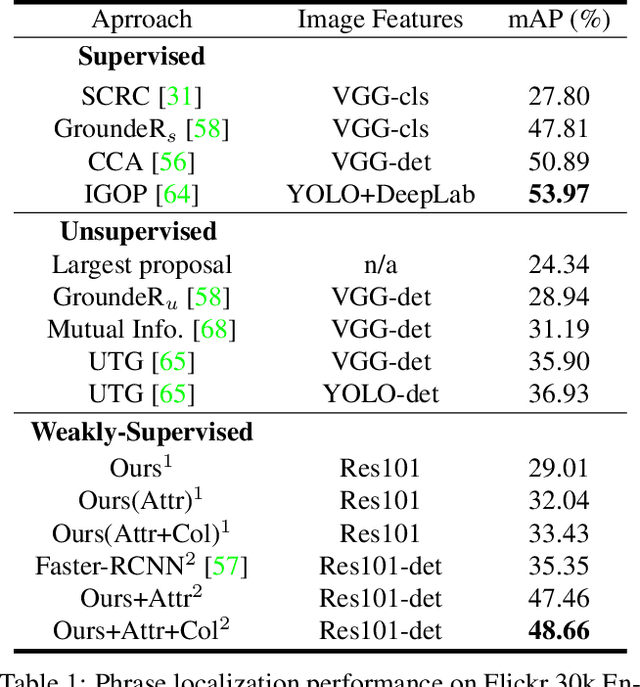
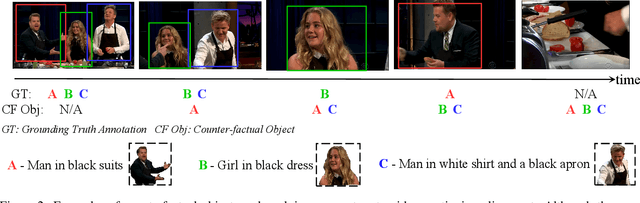
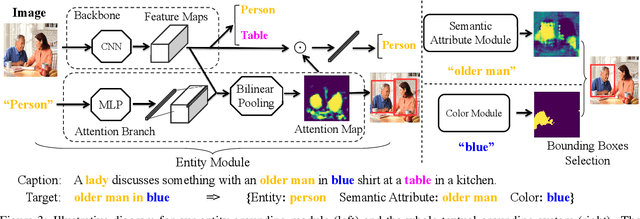
Computer Vision applications often require a textual grounding module with precision, interpretability, and resilience to counterfactual inputs/queries. To achieve high grounding precision, current textual grounding methods heavily rely on large-scale training data with manual annotations at the pixel level. Such annotations are expensive to obtain and thus severely narrow the model's scope of real-world applications. Moreover, most of these methods sacrifice interpretability, generalizability, and they neglect the importance of being resilient to counterfactual inputs. To address these issues, we propose a visual grounding system which is 1) end-to-end trainable in a weakly supervised fashion with only image-level annotations, and 2) counterfactually resilient owing to the modular design. Specifically, we decompose textual descriptions into three levels: entity, semantic attribute, color information, and perform compositional grounding progressively. We validate our model through a series of experiments and demonstrate its improvement over the state-of-the-art methods. In particular, our model's performance not only surpasses other weakly/un-supervised methods and even approaches the strongly supervised ones, but also is interpretable for decision making and performs much better in face of counterfactual classes than all the others.
Multigrid Predictive Filter Flow for Unsupervised Learning on Videos
Apr 02, 2019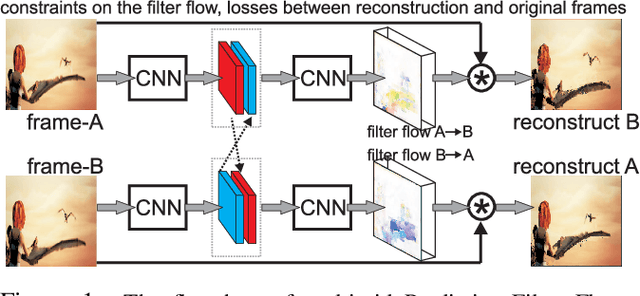
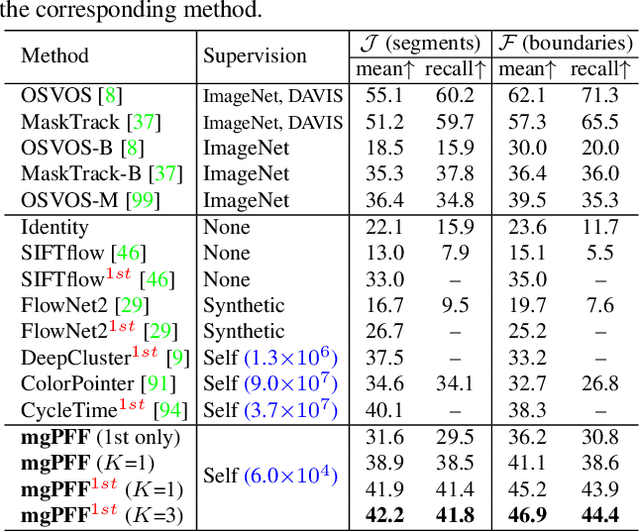
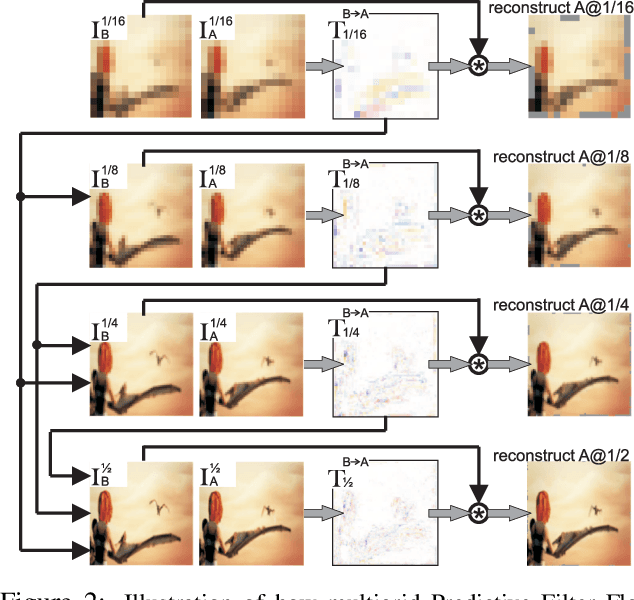
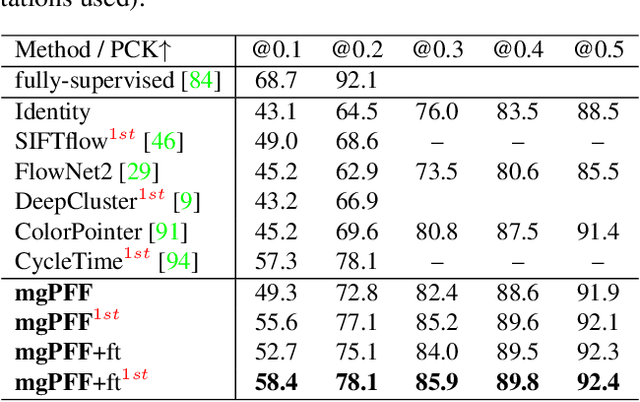
We introduce multigrid Predictive Filter Flow (mgPFF), a framework for unsupervised learning on videos. The mgPFF takes as input a pair of frames and outputs per-pixel filters to warp one frame to the other. Compared to optical flow used for warping frames, mgPFF is more powerful in modeling sub-pixel movement and dealing with corruption (e.g., motion blur). We develop a multigrid coarse-to-fine modeling strategy that avoids the requirement of learning large filters to capture large displacement. This allows us to train an extremely compact model (4.6MB) which operates in a progressive way over multiple resolutions with shared weights. We train mgPFF on unsupervised, free-form videos and show that mgPFF is able to not only estimate long-range flow for frame reconstruction and detect video shot transitions, but also readily amendable for video object segmentation and pose tracking, where it substantially outperforms the published state-of-the-art without bells and whistles. Moreover, owing to mgPFF's nature of per-pixel filter prediction, we have the unique opportunity to visualize how each pixel is evolving during solving these tasks, thus gaining better interpretability.
Sparse Representations for Object and Ego-motion Estimation in Dynamic Scenes
Mar 09, 2019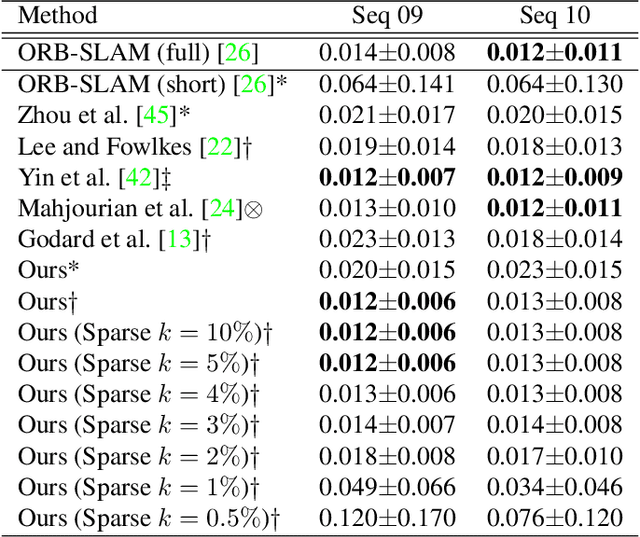

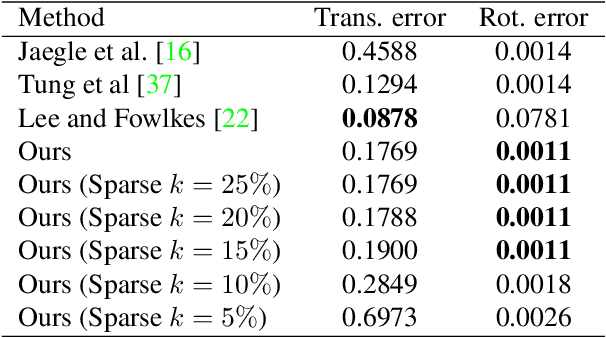
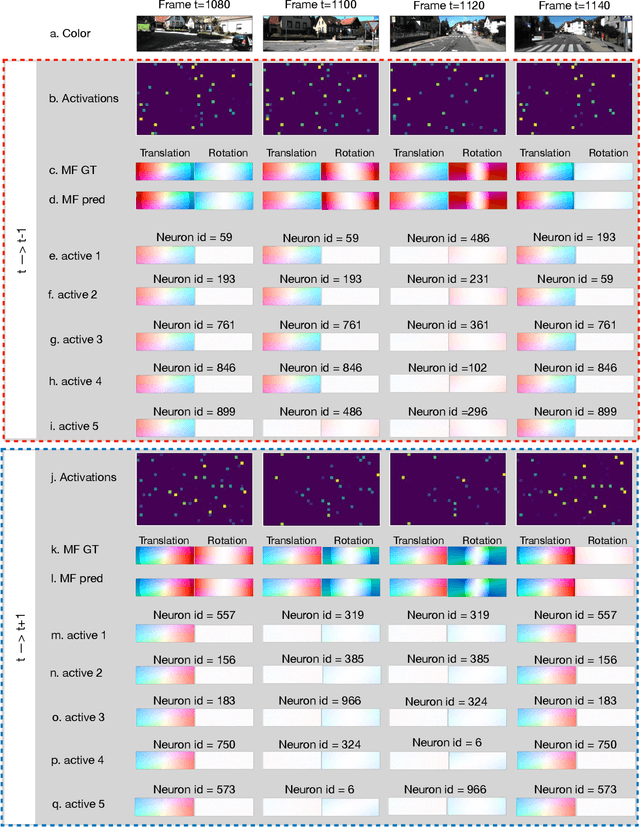
Dynamic scenes that contain both object motion and egomotion are a challenge for monocular visual odometry (VO). Another issue with monocular VO is the scale ambiguity, i.e. these methods cannot estimate scene depth and camera motion in real scale. Here, we propose a learning based approach to predict camera motion parameters directly from optic flow, by marginalizing depthmap variations and outliers. This is achieved by learning a sparse overcomplete basis set of egomotion in an autoencoder network, which is able to eliminate irrelevant components of optic flow for the task of camera parameter or motionfield estimation. The model is trained using a sparsity regularizer and a supervised egomotion loss, and achieves the state-of-the-art performances on trajectory prediction and camera rotation prediction tasks on KITTI and Virtual KITTI datasets, respectively. The sparse latent space egomotion representation learned by the model is robust and requires only 5% of the hidden layer neurons to maintain the best trajectory prediction accuracy on KITTI dataset. Additionally, in presence of depth information, the proposed method demonstrates faithful object velocity prediction for wide range of object sizes and speeds by global compensation of predicted egomotion and a divisive normalization procedure.
Task2Vec: Task Embedding for Meta-Learning
Feb 10, 2019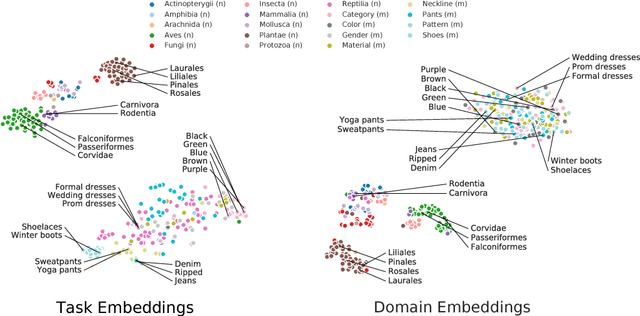
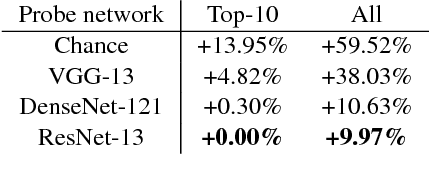
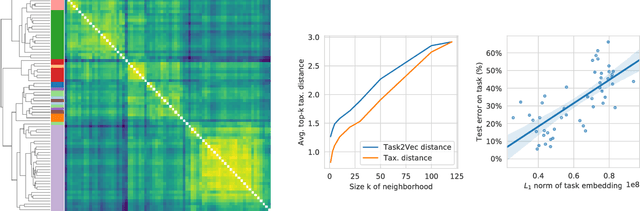

We introduce a method to provide vectorial representations of visual classification tasks which can be used to reason about the nature of those tasks and their relations. Given a dataset with ground-truth labels and a loss function defined over those labels, we process images through a "probe network" and compute an embedding based on estimates of the Fisher information matrix associated with the probe network parameters. This provides a fixed-dimensional embedding of the task that is independent of details such as the number of classes and does not require any understanding of the class label semantics. We demonstrate that this embedding is capable of predicting task similarities that match our intuition about semantic and taxonomic relations between different visual tasks (e.g., tasks based on classifying different types of plants are similar) We also demonstrate the practical value of this framework for the meta-task of selecting a pre-trained feature extractor for a new task. We present a simple meta-learning framework for learning a metric on embeddings that is capable of predicting which feature extractors will perform well. Selecting a feature extractor with task embedding obtains a performance close to the best available feature extractor, while costing substantially less than exhaustively training and evaluating on all available feature extractors.