 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Caption: Training-free improvement of multimodal large language model on referring expression comprehension
Feb 09, 2026Given a textual description, the task of referring expression comprehension (REC) involves the localisation of the referred object in an image. Multimodal large language models (MLLMs) have achieved high accuracy on REC benchmarks through scaling up the model size and training data. Moreover, the performance of MLLMs can be further improved using techniques such as Chain-of-Thought and tool use, which provides additional visual or textual context to the model. In this paper, we analyse the effect of various techniques for providing additional visual and textual context via tool use to the MLLM and its effect on the REC task. Furthermore, we propose a training-free framework named Chain-of-Caption to improve the REC performance of MLLMs. We perform experiments on RefCOCO/RefCOCOg/RefCOCO+ and Ref-L4 datasets and show that individual textual or visual context can improve the REC performance without any fine-tuning. By combining multiple contexts, our training-free framework shows between 5% to 30% performance gain over the baseline model on accuracy at various Intersection over Union (IoU) thresholds.
LaVA-Man: Learning Visual Action Representations for Robot Manipulation
Aug 26, 2025Visual-textual understanding is essential for language-guided robot manipulation. Recent works leverage pre-trained vision-language models to measure the similarity between encoded visual observations and textual instructions, and then train a model to map this similarity to robot actions. However, this two-step approach limits the model to capture the relationship between visual observations and textual instructions, leading to reduced precision in manipulation tasks. We propose to learn visual-textual associations through a self-supervised pretext task: reconstructing a masked goal image conditioned on an input image and textual instructions. This formulation allows the model to learn visual-action representations without robot action supervision. The learned representations can then be fine-tuned for manipulation tasks with only a few demonstrations. We also introduce the \textit{Omni-Object Pick-and-Place} dataset, which consists of annotated robot tabletop manipulation episodes, including 180 object classes and 3,200 instances with corresponding textual instructions. This dataset enables the model to acquire diverse object priors and allows for a more comprehensive evaluation of its generalisation capability across object instances. Experimental results on the five benchmarks, including both simulated and real-robot validations, demonstrate that our method outperforms prior art.
Stereo Hand-Object Reconstruction for Human-to-Robot Handover
Dec 10, 2024



Jointly estimating hand and object shape ensures the success of the robot grasp in human-to-robot handovers. However, relying on hand-crafted prior knowledge about the geometric structure of the object fails when generalising to unseen objects, and depth sensors fail to detect transparent objects such as drinking glasses. In this work, we propose a stereo-based method for hand-object reconstruction that combines single-view reconstructions probabilistically to form a coherent stereo reconstruction. We learn 3D shape priors from a large synthetic hand-object dataset to ensure that our method is generalisable, and use RGB inputs instead of depth as RGB can better capture transparent objects. We show that our method achieves a lower object Chamfer distance compared to existing RGB based hand-object reconstruction methods on single view and stereo settings. We process the reconstructed hand-object shape with a projection-based outlier removal step and use the output to guide a human-to-robot handover pipeline with wide-baseline stereo RGB cameras. Our hand-object reconstruction enables a robot to successfully receive a diverse range of household objects from the human.
Sparse multi-view hand-object reconstruction for unseen environments
May 02, 2024



Recent works in hand-object reconstruction mainly focus on the single-view and dense multi-view settings. On the one hand, single-view methods can leverage learned shape priors to generalise to unseen objects but are prone to inaccuracies due to occlusions. On the other hand, dense multi-view methods are very accurate but cannot easily adapt to unseen objects without further data collection. In contrast, sparse multi-view methods can take advantage of the additional views to tackle occlusion, while keeping the computational cost low compared to dense multi-view methods. In this paper, we consider the problem of hand-object reconstruction with unseen objects in the sparse multi-view setting. Given multiple RGB images of the hand and object captured at the same time, our model SVHO combines the predictions from each view into a unified reconstruction without optimisation across views. We train our model on a synthetic hand-object dataset and evaluate directly on a real world recorded hand-object dataset with unseen objects. We show that while reconstruction of unseen hands and objects from RGB is challenging, additional views can help improve the reconstruction quality.
OHPL: One-shot Hand-eye Policy Learner
Aug 06, 2021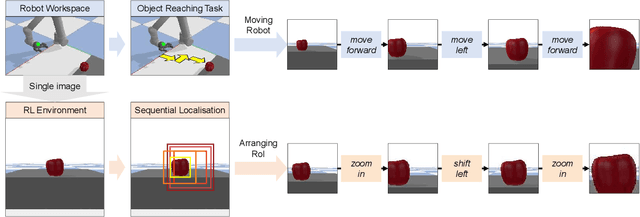
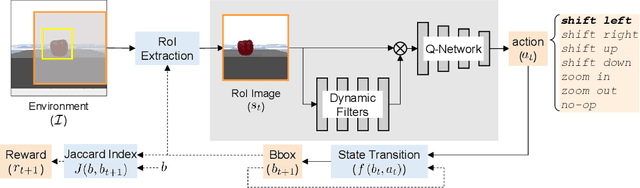

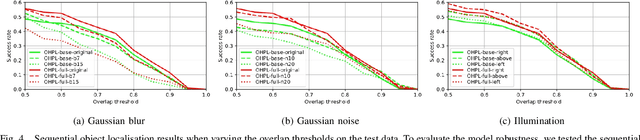
The control of a robot for manipulation tasks generally relies on object detection and pose estimation. An attractive alternative is to learn control policies directly from raw input data. However, this approach is time-consuming and expensive since learning the policy requires many trials with robot actions in the physical environment. To reduce the training cost, the policy can be learned in simulation with a large set of synthetic images. The limit of this approach is the domain gap between the simulation and the robot workspace. In this paper, we propose to learn a policy for robot reaching movements from a single image captured directly in the robot workspace from a camera placed on the end-effector (a hand-eye camera). The idea behind the proposed policy learner is that view changes seen from the hand-eye camera produced by actions in the robot workspace are analogous to locating a region-of-interest in a single image by performing sequential object localisation. This similar view change enables training of object reaching policies using reinforcement-learning-based sequential object localisation. To facilitate the adaptation of the policy to view changes in the robot workspace, we further present a dynamic filter that learns to bias an input state to remove irrelevant information for an action decision. The proposed policy learner can be used as a powerful representation for robotic tasks, and we validate it on static and moving object reaching tasks.
Towards safe human-to-robot handovers of unknown containers
Jul 03, 2021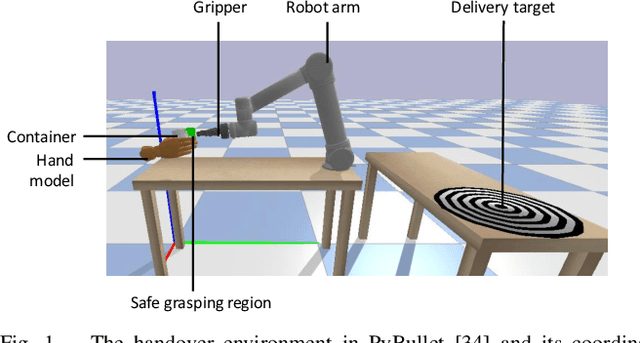


Safe human-to-robot handovers of unknown objects require accurate estimation of hand poses and object properties, such as shape, trajectory, and weight. Accurately estimating these properties requires the use of scanned 3D object models or expensive equipment, such as motion capture systems and markers, or both. However, testing handover algorithms with robots may be dangerous for the human and, when the object is an open container with liquids, for the robot. In this paper, we propose a real-to-simulation framework to develop safe human-to-robot handovers with estimations of the physical properties of unknown cups or drinking glasses and estimations of the human hands from videos of a human manipulating the container. We complete the handover in simulation, and we estimate a region that is not occluded by the hand of the human holding the container. We also quantify the safeness of the human and object in simulation. We validate the framework using public recordings of containers manipulated before a handover and show the safeness of the handover when using noisy estimates from a range of perceptual algorithms.