 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Comparison of Explainable Artificial Intelligence Methods for Clinical Data: A Case Study on Traumatic Brain Injury
Aug 13, 2022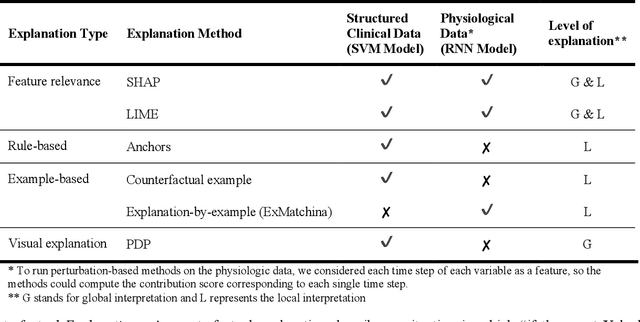



A longstanding challenge surrounding deep learning algorithms is unpacking and understanding how they make their decisions. Explainable Artificial Intelligence (XAI) offers methods to provide explanations of internal functions of algorithms and reasons behind their decisions in ways that are interpretable and understandable to human users. . Numerous XAI approaches have been developed thus far, and a comparative analysis of these strategies seems necessary to discern their relevance to clinical prediction models. To this end, we first implemented two prediction models for short- and long-term outcomes of traumatic brain injury (TBI) utilizing structured tabular as well as time-series physiologic data, respectively. Six different interpretation techniques were used to describe both prediction models at the local and global levels. We then performed a critical analysis of merits and drawbacks of each strategy, highlighting the implications for researchers who are interested in applying these methodologies. The implemented methods were compared to one another in terms of several XAI characteristics such as understandability, fidelity, and stability. Our findings show that SHAP is the most stable with the highest fidelity but falls short of understandability. Anchors, on the other hand, is the most understandable approach, but it is only applicable to tabular data and not time series data.
Text Enriched Sparse Hyperbolic Graph Convolutional Networks
Jul 07, 2022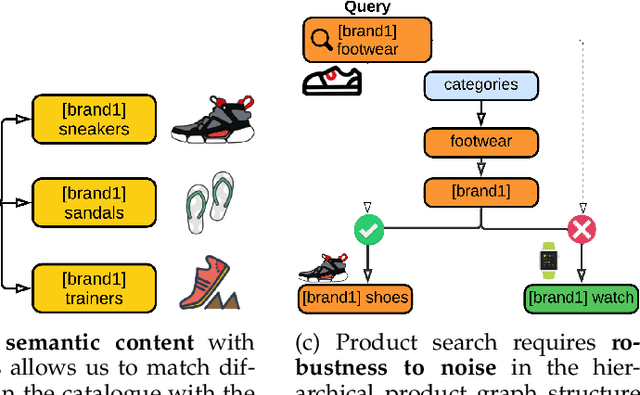

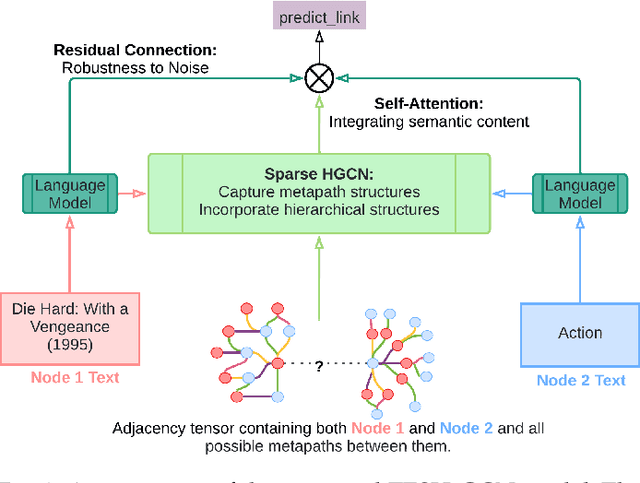
Heterogeneous networks, which connect informative nodes containing text with different edge types, are routinely used to store and process information in various real-world applications. Graph Neural Networks (GNNs) and their hyperbolic variants provide a promising approach to encode such networks in a low-dimensional latent space through neighborhood aggregation and hierarchical feature extraction, respectively. However, these approaches typically ignore metapath structures and the available semantic information. Furthermore, these approaches are sensitive to the noise present in the training data. To tackle these limitations, in this paper, we propose Text Enriched Sparse Hyperbolic Graph Convolution Network (TESH-GCN) to capture the graph's metapath structures using semantic signals and further improve prediction in large heterogeneous graphs. In TESH-GCN, we extract semantic node information, which successively acts as a connection signal to extract relevant nodes' local neighborhood and graph-level metapath features from the sparse adjacency tensor in a reformulated hyperbolic graph convolution layer. These extracted features in conjunction with semantic features from the language model (for robustness) are used for the final downstream task. Experiments on various heterogeneous graph datasets show that our model outperforms the current state-of-the-art approaches by a large margin on the task of link prediction. We also report a reduction in both the training time and model parameters compared to the existing hyperbolic approaches through a reformulated hyperbolic graph convolution. Furthermore, we illustrate the robustness of our model by experimenting with different levels of simulated noise in both the graph structure and text, and also, present a mechanism to explain TESH-GCN's prediction by analyzing the extracted metapaths.
XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence
Jun 16, 2022
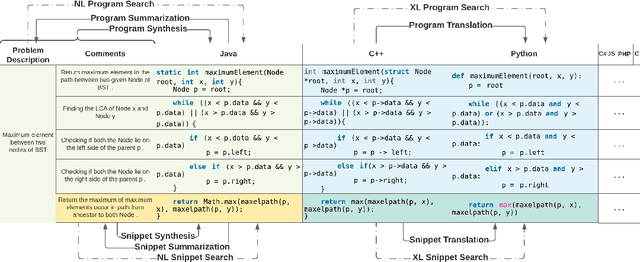
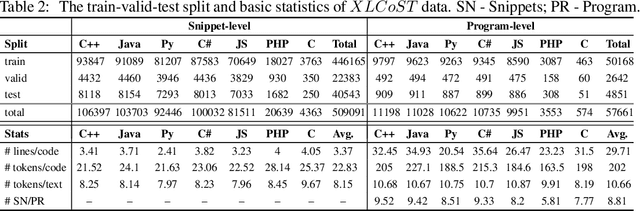
Recent advances in machine learning have significantly improved the understanding of source code data and achieved good performance on a number of downstream tasks. Open source repositories like GitHub enable this process with rich unlabeled code data. However, the lack of high quality labeled data has largely hindered the progress of several code related tasks, such as program translation, summarization, synthesis, and code search. This paper introduces XLCoST, Cross-Lingual Code SnippeT dataset, a new benchmark dataset for cross-lingual code intelligence. Our dataset contains fine-grained parallel data from 8 languages (7 commonly used programming languages and English), and supports 10 cross-lingual code tasks. To the best of our knowledge, it is the largest parallel dataset for source code both in terms of size and the number of languages. We also provide the performance of several state-of-the-art baseline models for each task. We believe this new dataset can be a valuable asset for the research community and facilitate the development and validation of new methods for cross-lingual code intelligence.
Shopping Queries Dataset: A Large-Scale ESCI Benchmark for Improving Product Search
Jun 14, 2022


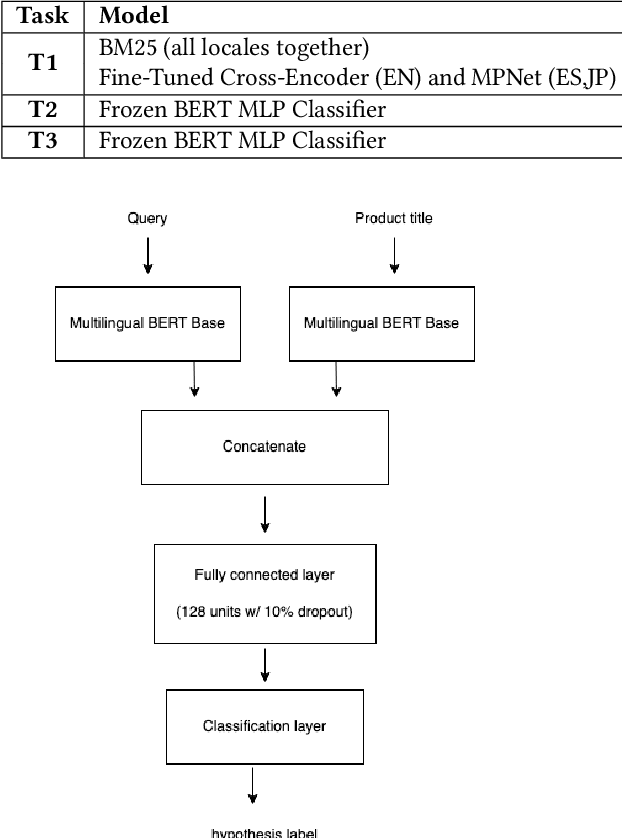
Improving the quality of search results can significantly enhance users experience and engagement with search engines. In spite of several recent advancements in the fields of machine learning and data mining, correctly classifying items for a particular user search query has been a long-standing challenge, which still has a large room for improvement. This paper introduces the "Shopping Queries Dataset", a large dataset of difficult Amazon search queries and results, publicly released with the aim of fostering research in improving the quality of search results. The dataset contains around 130 thousand unique queries and 2.6 million manually labeled (query,product) relevance judgements. The dataset is multilingual with queries in English, Japanese, and Spanish. The Shopping Queries Dataset is being used in one of the KDDCup'22 challenges. In this paper, we describe the dataset and present three evaluation tasks along with baseline results: (i) ranking the results list, (ii) classifying product results into relevance categories, and (iii) identifying substitute products for a given query. We anticipate that this data will become the gold standard for future research in the topic of product search.
StructCoder: Structure-Aware Transformer for Code Generation
Jun 10, 2022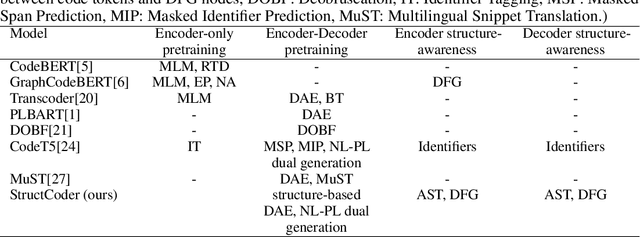
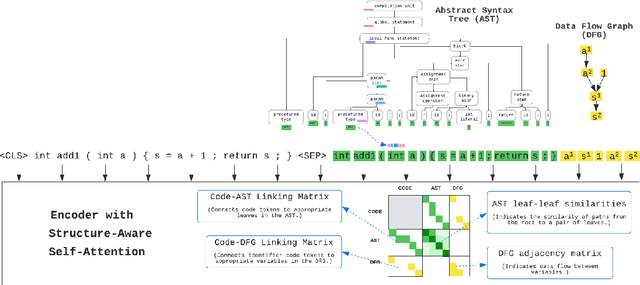
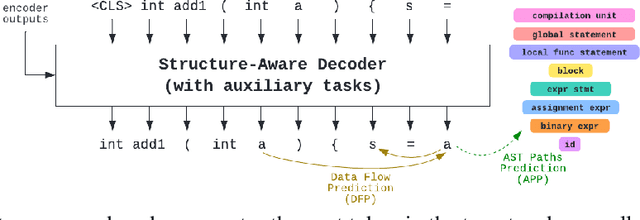
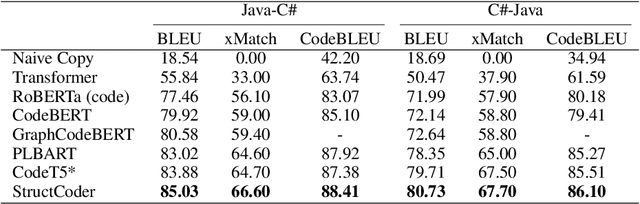
There has been a recent surge of interest in automating software engineering tasks using deep learning. This work addresses the problem of code generation where the goal is to generate target code given source code in a different language or a natural language description. Most of the state-of-the-art deep learning models for code generation use training strategies that are primarily designed for natural language. However, understanding and generating code requires a more rigorous comprehension of the code syntax and semantics. With this motivation, we develop an encoder-decoder Transformer model where both the encoder and decoder are trained to recognize the syntax and data flow in the source and target codes, respectively. We not only make the encoder structure-aware by leveraging the source code's syntax tree and data flow graph, but we also ensure that our decoder preserves the syntax and data flow of the target code by introducing two auxiliary tasks: AST (Abstract Syntax Tree) paths prediction and data flow prediction. To the best of our knowledge, this is the first work to introduce a structure-aware Transformer decoder to enhance the quality of generated code by modeling target syntax and data flow. The proposed StructCoder model achieves state-of-the-art performance on code translation and text-to-code generation tasks in the CodeXGLUE benchmark.
Pseudo-Poincaré: A Unification Framework for Euclidean and Hyperbolic Graph Neural Networks
Jun 09, 2022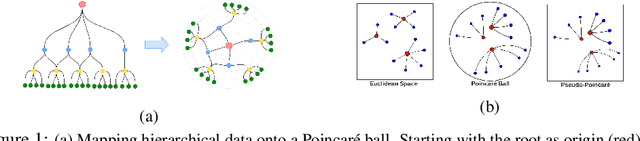
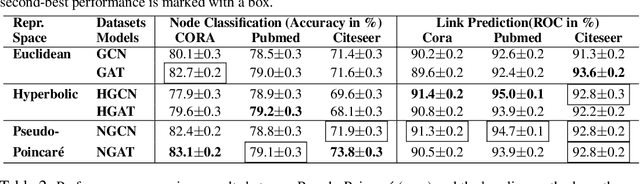
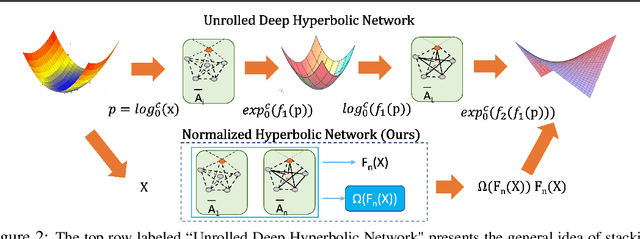
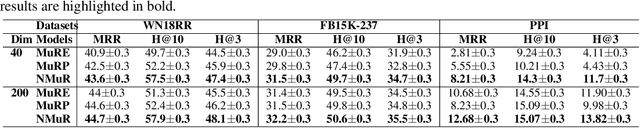
Hyperbolic neural networks have recently gained significant attention due to their promising results on several graph problems including node classification and link prediction. The primary reason for this success is the effectiveness of the hyperbolic space in capturing the inherent hierarchy of graph datasets. However, they are limited in terms of generalization, scalability, and have inferior performance when it comes to non-hierarchical datasets. In this paper, we take a completely orthogonal perspective for modeling hyperbolic networks. We use Poincar\'e disk to model the hyperbolic geometry and also treat it as if the disk itself is a tangent space at origin. This enables us to replace non-scalable M\"obius gyrovector operations with an Euclidean approximation, and thus simplifying the entire hyperbolic model to a Euclidean model cascaded with a hyperbolic normalization function. Our approach does not adhere to M\"obius math, yet it still works in the Riemannian manifold, hence we call it Pseudo-Poincar\'e framework. We applied our non-linear hyperbolic normalization to the current state-of-the-art homogeneous and multi-relational graph networks and demonstrate significant improvements in performance compared to both Euclidean and hyperbolic counterparts. The primary impact of this work lies in its ability to capture hierarchical features in the Euclidean space, and thus, can replace hyperbolic networks without loss in performance metrics while simultaneously leveraging the power of Euclidean networks such as interpretability and efficient execution of various model components.
Towards Scalable Hyperbolic Neural Networks using Taylor Series Approximations
Jun 07, 2022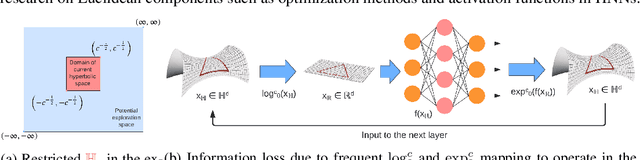
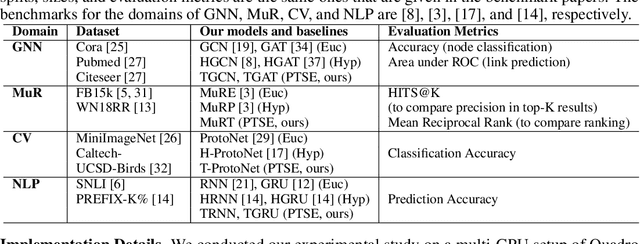
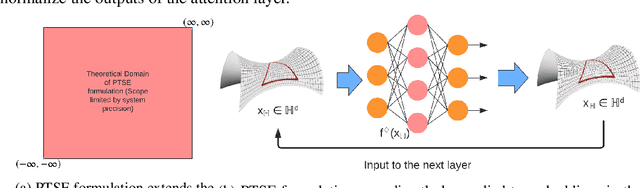
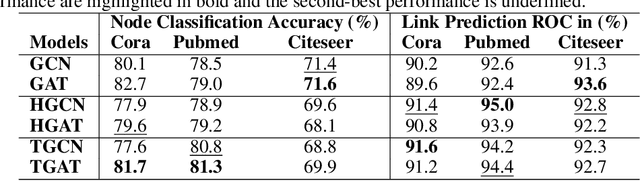
Hyperbolic networks have shown prominent improvements over their Euclidean counterparts in several areas involving hierarchical datasets in various domains such as computer vision, graph analysis, and natural language processing. However, their adoption in practice remains restricted due to (i) non-scalability on accelerated deep learning hardware, (ii) vanishing gradients due to the closure of hyperbolic space, and (iii) information loss due to frequent mapping between local tangent space and fully hyperbolic space. To tackle these issues, we propose the approximation of hyperbolic operators using Taylor series expansions, which allows us to reformulate the computationally expensive tangent and cosine hyperbolic functions into their polynomial equivariants which are more efficient. This allows us to retain the benefits of preserving the hierarchical anatomy of the hyperbolic space, while maintaining the scalability over current accelerated deep learning infrastructure. The polynomial formulation also enables us to utilize the advancements in Euclidean networks such as gradient clipping and ReLU activation to avoid vanishing gradients and remove errors due to frequent switching between tangent space and hyperbolic space. Our empirical evaluation on standard benchmarks in the domain of graph analysis and computer vision shows that our polynomial formulation is as scalable as Euclidean architectures, both in terms of memory and time complexity, while providing results as effective as hyperbolic models. Moreover, our formulation also shows a considerable improvement over its baselines due to our solution to vanishing gradients and information loss.
CodeAttack: Code-based Adversarial Attacks for Pre-Trained Programming Language Models
May 31, 2022

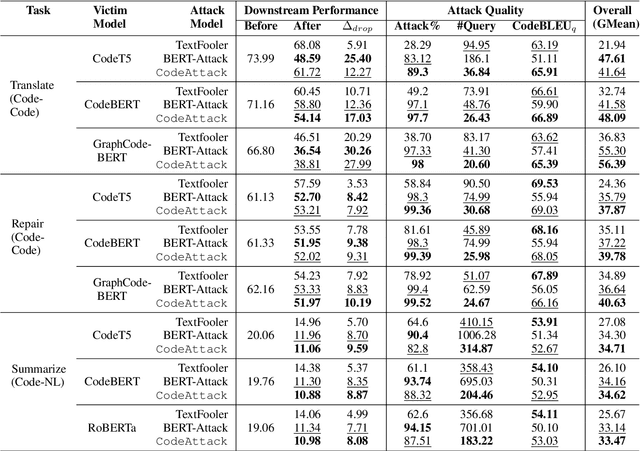
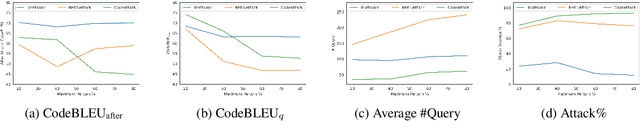
Pre-trained programming language (PL) models (such as CodeT5, CodeBERT, GraphCodeBERT, etc.,) have the potential to automate software engineering tasks involving code understanding and code generation. However, these models are not robust to changes in the input and thus, are potentially susceptible to adversarial attacks. We propose, CodeAttack, a simple yet effective black-box attack model that uses code structure to generate imperceptible, effective, and minimally perturbed adversarial code samples. We demonstrate the vulnerabilities of the state-of-the-art PL models to code-specific adversarial attacks. We evaluate the transferability of CodeAttack on several code-code (translation and repair) and code-NL (summarization) tasks across different programming languages. CodeAttack outperforms state-of-the-art adversarial NLP attack models to achieve the best overall performance while being more efficient and imperceptible.
Multi-Label Clinical Time-Series Generation via Conditional GAN
Apr 10, 2022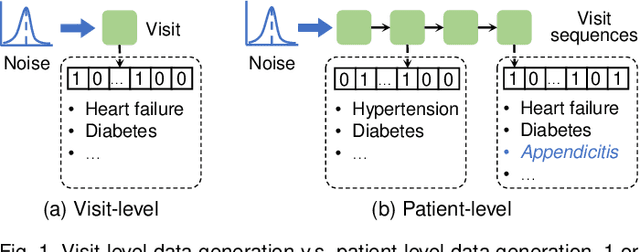

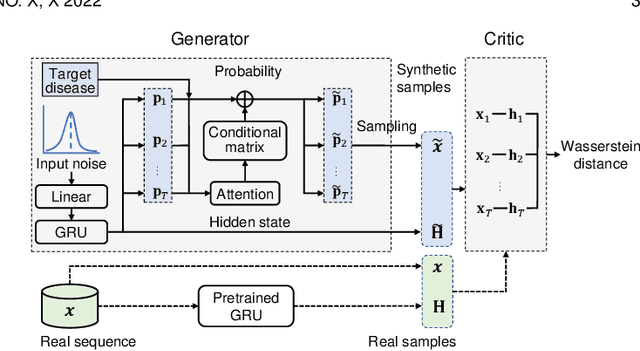

With wide applications of electronic health records (EHR), deep learning methods have been adopted to analyze EHR data on various tasks such as representation learning, clinical event prediction, and phenotyping. However, due to privacy constraints, limited access to EHR becomes a bottleneck for deep learning research. Recently, generative adversarial networks (GANs) have been successful in generating EHR data. However, there are still challenges in high-quality EHR generation, including generating time-series EHR and uncommon diseases given imbalanced datasets. In this work, we propose a Multi-label Time-series GAN (MTGAN) to generate EHR data and simultaneously improve the quality of uncommon disease generation. The generator of MTGAN uses a gated recurrent unit (GRU) with a smooth conditional matrix to generate sequences and uncommon diseases. The critic gives scores using Wasserstein distance to recognize real samples from synthetic samples by considering both data and temporal features. We also propose a training strategy to calculate temporal features for real data and stabilize GAN training. Furthermore, we design multiple statistical metrics and prediction tasks to evaluate the generated data. Experimental results demonstrate the quality of the synthetic data and the effectiveness of MTGAN in generating realistic sequential EHR data, especially for uncommon diseases.
Probabilistic Entity Representation Model for Reasoning over Knowledge Graphs
Oct 30, 2021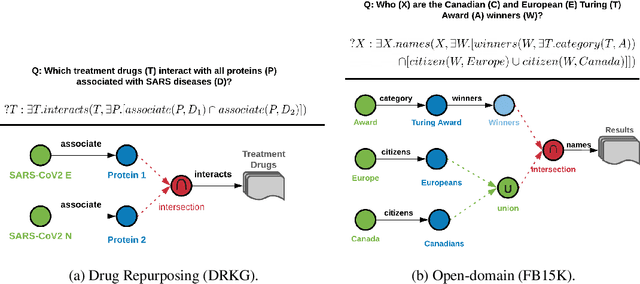
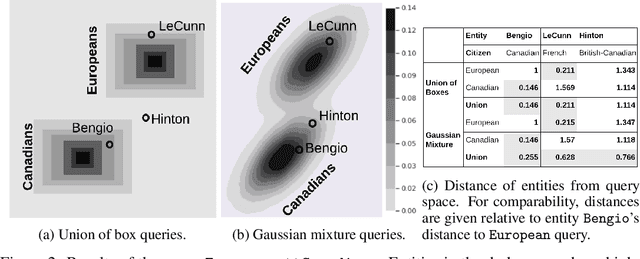
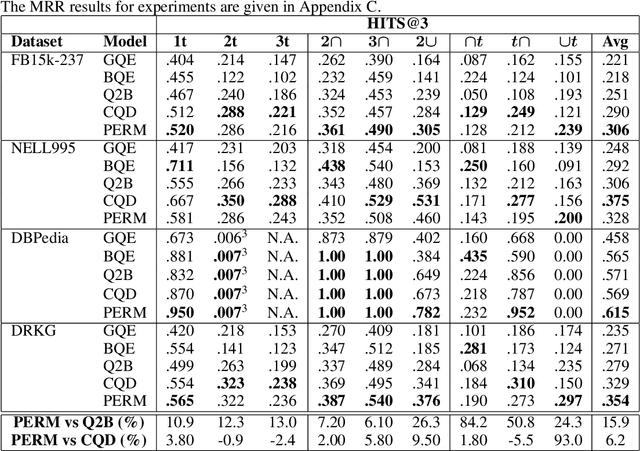
Logical reasoning over Knowledge Graphs (KGs) is a fundamental technique that can provide efficient querying mechanism over large and incomplete databases. Current approaches employ spatial geometries such as boxes to learn query representations that encompass the answer entities and model the logical operations of projection and intersection. However, their geometry is restrictive and leads to non-smooth strict boundaries, which further results in ambiguous answer entities. Furthermore, previous works propose transformation tricks to handle unions which results in non-closure and, thus, cannot be chained in a stream. In this paper, we propose a Probabilistic Entity Representation Model (PERM) to encode entities as a Multivariate Gaussian density with mean and covariance parameters to capture its semantic position and smooth decision boundary, respectively. Additionally, we also define the closed logical operations of projection, intersection, and union that can be aggregated using an end-to-end objective function. On the logical query reasoning problem, we demonstrate that the proposed PERM significantly outperforms the state-of-the-art methods on various public benchmark KG datasets on standard evaluation metrics. We also evaluate PERM's competence on a COVID-19 drug-repurposing case study and show that our proposed work is able to recommend drugs with substantially better F1 than current methods. Finally, we demonstrate the working of our PERM's query answering process through a low-dimensional visualization of the Gaussian representations.