 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepWalking Backwards: From Embeddings Back to Graphs
Feb 17, 2021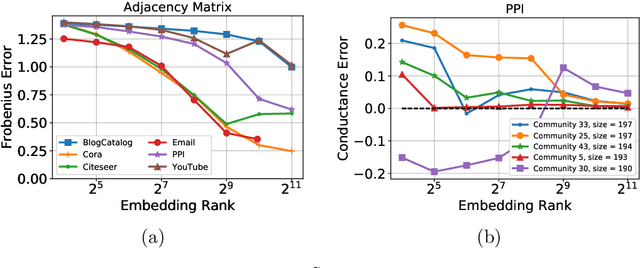
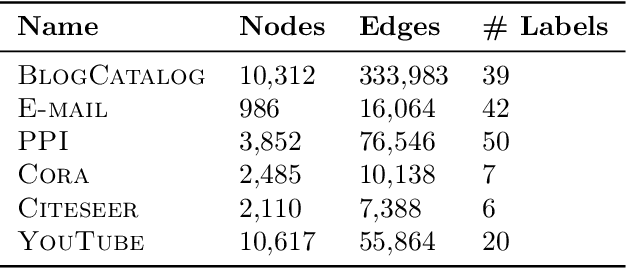
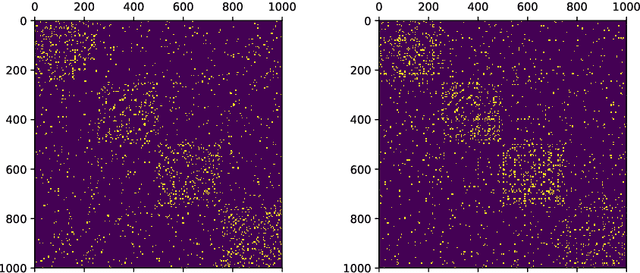
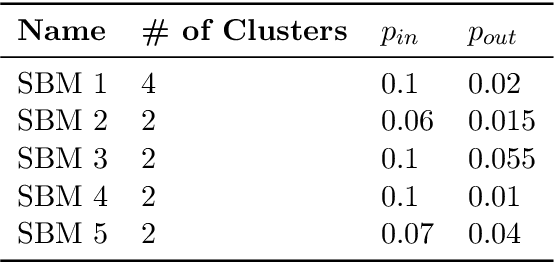
Low-dimensional node embeddings play a key role in analyzing graph datasets. However, little work studies exactly what information is encoded by popular embedding methods, and how this information correlates with performance in downstream machine learning tasks. We tackle this question by studying whether embeddings can be inverted to (approximately) recover the graph used to generate them. Focusing on a variant of the popular DeepWalk method (Perozzi et al., 2014; Qiu et al., 2018), we present algorithms for accurate embedding inversion - i.e., from the low-dimensional embedding of a graph G, we can find a graph H with a very similar embedding. We perform numerous experiments on real-world networks, observing that significant information about G, such as specific edges and bulk properties like triangle density, is often lost in H. However, community structure is often preserved or even enhanced. Our findings are a step towards a more rigorous understanding of exactly what information embeddings encode about the input graph, and why this information is useful for learning tasks.
Faster Kernel Matrix Algebra via Density Estimation
Feb 16, 2021
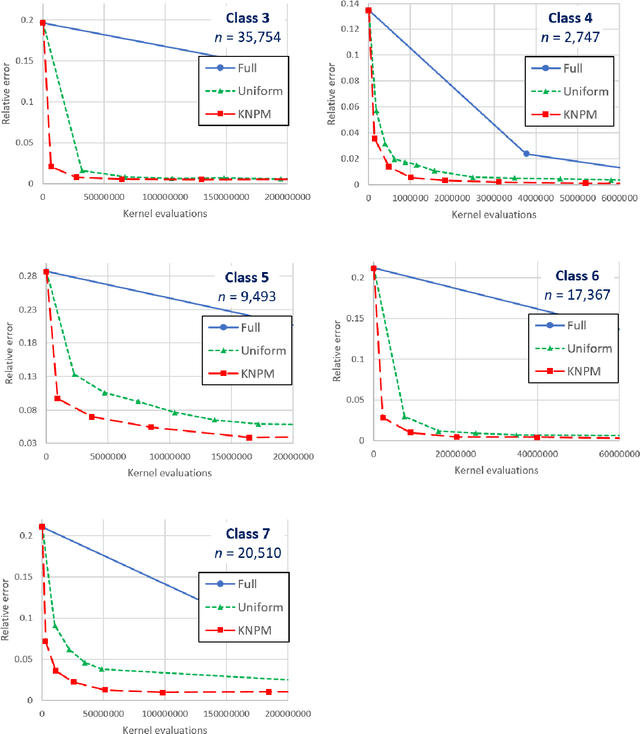
We study fast algorithms for computing fundamental properties of a positive semidefinite kernel matrix $K \in \mathbb{R}^{n \times n}$ corresponding to $n$ points $x_1,\ldots,x_n \in \mathbb{R}^d$. In particular, we consider estimating the sum of kernel matrix entries, along with its top eigenvalue and eigenvector. We show that the sum of matrix entries can be estimated to $1+\epsilon$ relative error in time $sublinear$ in $n$ and linear in $d$ for many popular kernels, including the Gaussian, exponential, and rational quadratic kernels. For these kernels, we also show that the top eigenvalue (and an approximate eigenvector) can be approximated to $1+\epsilon$ relative error in time $subquadratic$ in $n$ and linear in $d$. Our algorithms represent significant advances in the best known runtimes for these problems. They leverage the positive definiteness of the kernel matrix, along with a recent line of work on efficient kernel density estimation.
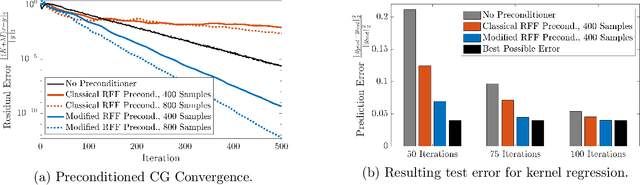
Faster Kernel Interpolation for Gaussian Processes
Jan 28, 2021
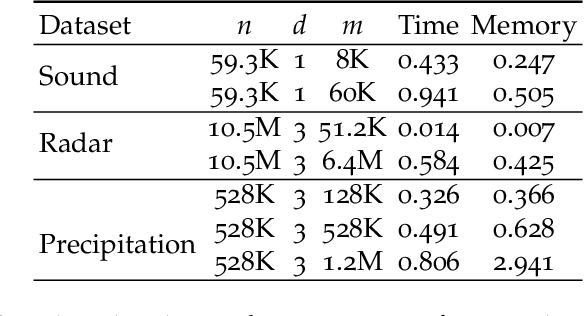

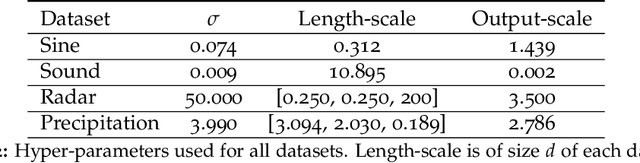
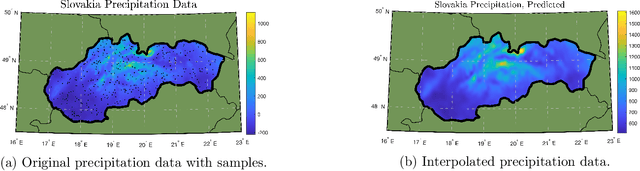
A key challenge in scaling Gaussian Process (GP) regression to massive datasets is that exact inference requires computation with a dense n x n kernel matrix, where n is the number of data points. Significant work focuses on approximating the kernel matrix via interpolation using a smaller set of m inducing points. Structured kernel interpolation (SKI) is among the most scalable methods: by placing inducing points on a dense grid and using structured matrix algebra, SKI achieves per-iteration time of O(n + m log m) for approximate inference. This linear scaling in n enables inference for very large data sets; however the cost is per-iteration, which remains a limitation for extremely large n. We show that the SKI per-iteration time can be reduced to O(m log m) after a single O(n) time precomputation step by reframing SKI as solving a natural Bayesian linear regression problem with a fixed set of m compact basis functions. With per-iteration complexity independent of the dataset size n for a fixed grid, our method scales to truly massive data sets. We demonstrate speedups in practice for a wide range of m and n and apply the method to GP inference on a three-dimensional weather radar dataset with over 100 million points.
Intervention Efficient Algorithms for Approximate Learning of Causal Graphs
Dec 27, 2020We study the problem of learning the causal relationships between a set of observed variables in the presence of latents, while minimizing the cost of interventions on the observed variables. We assume access to an undirected graph $G$ on the observed variables whose edges represent either all direct causal relationships or, less restrictively, a superset of causal relationships (identified, e.g., via conditional independence tests or a domain expert). Our goal is to recover the directions of all causal or ancestral relations in $G$, via a minimum cost set of interventions. It is known that constructing an exact minimum cost intervention set for an arbitrary graph $G$ is NP-hard. We further argue that, conditioned on the hardness of approximate graph coloring, no polynomial time algorithm can achieve an approximation factor better than $\Theta(\log n)$, where $n$ is the number of observed variables in $G$. To overcome this limitation, we introduce a bi-criteria approximation goal that lets us recover the directions of all but $\epsilon n^2$ edges in $G$, for some specified error parameter $\epsilon > 0$. Under this relaxed goal, we give polynomial time algorithms that achieve intervention cost within a small constant factor of the optimal. Our algorithms combine work on efficient intervention design and the design of low-cost separating set systems, with ideas from the literature on graph property testing.
Estimation of Shortest Path Covariance Matrices
Nov 19, 2020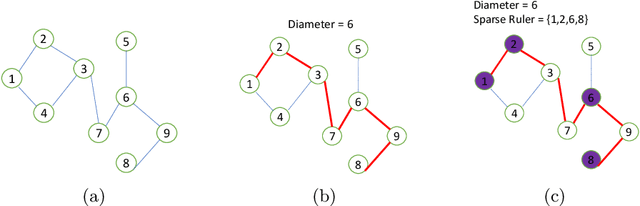
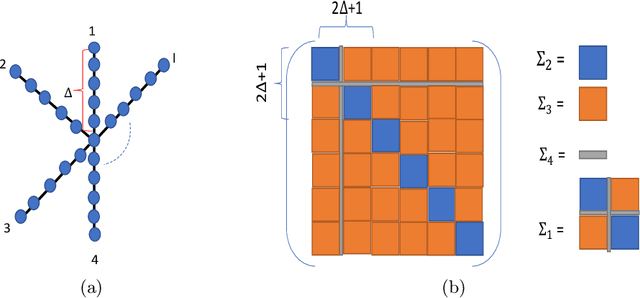
We study the sample complexity of estimating the covariance matrix $\mathbf{\Sigma} \in \mathbb{R}^{d\times d}$ of a distribution $\mathcal D$ over $\mathbb{R}^d$ given independent samples, under the assumption that $\mathbf{\Sigma}$ is graph-structured. In particular, we focus on shortest path covariance matrices, where the covariance between any two measurements is determined by the shortest path distance in an underlying graph with $d$ nodes. Such matrices generalize Toeplitz and circulant covariance matrices and are widely applied in signal processing applications, where the covariance between two measurements depends on the (shortest path) distance between them in time or space. We focus on minimizing both the vector sample complexity: the number of samples drawn from $\mathcal{D}$ and the entry sample complexity: the number of entries read in each sample. The entry sample complexity corresponds to measurement equipment costs in signal processing applications. We give a very simple algorithm for estimating $\mathbf{\Sigma}$ up to spectral norm error $\epsilon \left\|\mathbf{\Sigma}\right\|_2$ using just $O(\sqrt{D})$ entry sample complexity and $\tilde O(r^2/\epsilon^2)$ vector sample complexity, where $D$ is the diameter of the underlying graph and $r \le d$ is the rank of $\mathbf{\Sigma}$. Our method is based on extending the widely applied idea of sparse rulers for Toeplitz covariance estimation to the graph setting. In the special case when $\mathbf{\Sigma}$ is a low-rank Toeplitz matrix, our result matches the state-of-the-art, with a far simpler proof. We also give an information theoretic lower bound matching our upper bound up to a factor $D$ and discuss some directions towards closing this gap.
Hutch++: Optimal Stochastic Trace Estimation
Nov 12, 2020
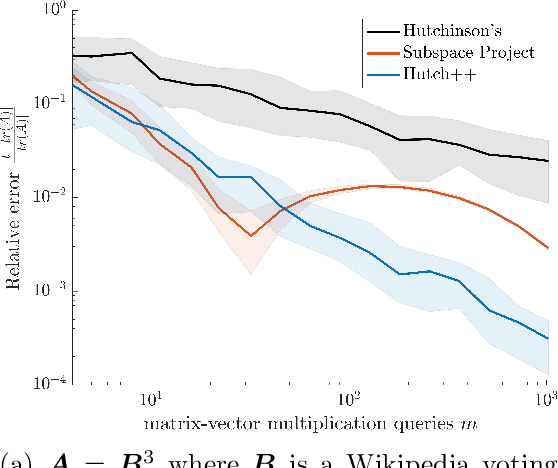
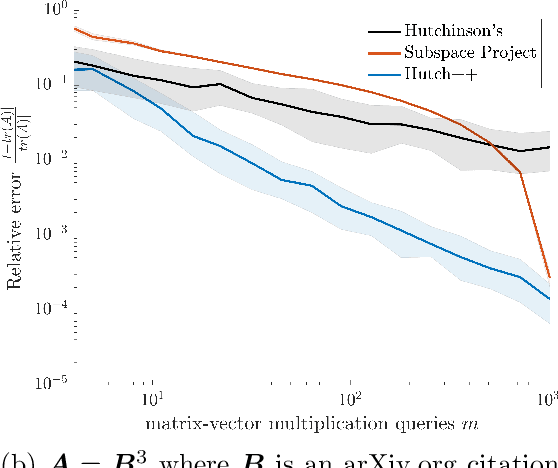
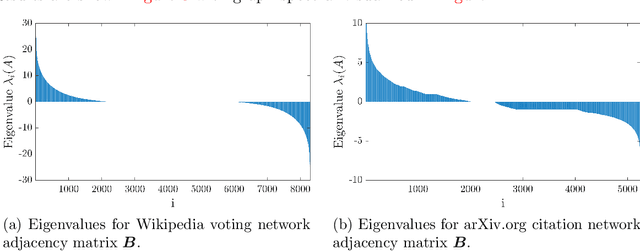
We study the problem of estimating the trace of a matrix $A$ that can only be accessed through matrix-vector multiplication. We introduce a new randomized algorithm, Hutch++, which computes a $(1 \pm \epsilon)$ approximation to $tr(A)$ for any positive semidefinite (PSD) $A$ using just $O(1/\epsilon)$ matrix-vector products. This improves on the ubiquitous Hutchinson's estimator, which requires $O(1/\epsilon^2)$ matrix-vector products. Our approach is based on a simple technique for reducing the variance of Hutchinson's estimator using a low-rank approximation step, and is easy to implement and analyze. Moreover, we prove that, up to a logarithmic factor, the complexity of Hutch++ is optimal amongst all matrix-vector query algorithms, even when queries can be chosen adaptively. We show that it significantly outperforms Hutchinson's method in experiments. While our theory requires $A$ to be positive semidefinite, empirical gains extend to applications involving non-PSD matrices, such as triangle estimation in networks.
Model-specific Data Subsampling with Influence Functions
Oct 20, 2020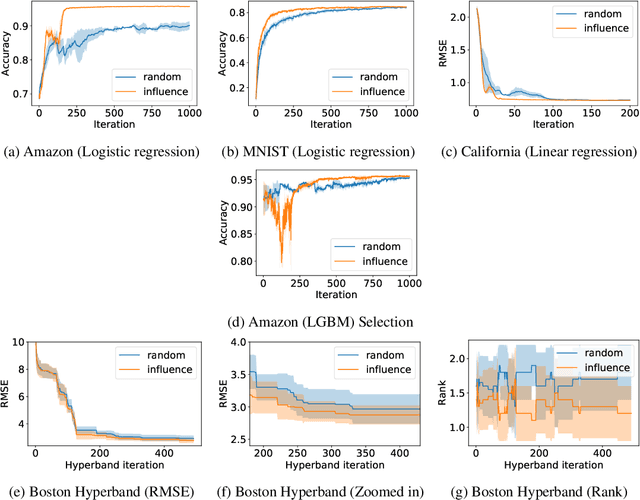
Model selection requires repeatedly evaluating models on a given dataset and measuring their relative performances. In modern applications of machine learning, the models being considered are increasingly more expensive to evaluate and the datasets of interest are increasing in size. As a result, the process of model selection is time-consuming and computationally inefficient. In this work, we develop a model-specific data subsampling strategy that improves over random sampling whenever training points have varying influence. Specifically, we leverage influence functions to guide our selection strategy, proving theoretically, and demonstrating empirically that our approach quickly selects high-quality models.
Subspace Embeddings Under Nonlinear Transformations
Oct 05, 2020
We consider low-distortion embeddings for subspaces under \emph{entrywise nonlinear transformations}. In particular we seek embeddings that preserve the norm of all vectors in a space $S = \{y: y = f(x)\text{ for }x \in Z\}$, where $Z$ is a $k$-dimensional subspace of $\mathbb{R}^n$ and $f(x)$ is a nonlinear activation function applied entrywise to $x$. When $f$ is the identity, and so $S$ is just a $k$-dimensional subspace, it is known that, with high probability, a random embedding into $O(k/\epsilon^2)$ dimensions preserves the norm of all $y \in S$ up to $(1\pm \epsilon)$ relative error. Such embeddings are known as \emph{subspace embeddings}, and have found widespread use in compressed sensing and approximation algorithms. We give the first low-distortion embeddings for a wide class of nonlinear functions $f$. In particular, we give additive $\epsilon$ error embeddings into $O(\frac{k\log (n/\epsilon)}{\epsilon^2})$ dimensions for a class of nonlinearities that includes the popular Sigmoid SoftPlus, and Gaussian functions. We strengthen this result to give relative error embeddings under some further restrictions, which are satisfied e.g., by the Tanh, SoftSign, Exponential Linear Unit, and many other `soft' step functions and rectifying units. Understanding embeddings for subspaces under nonlinear transformations is a key step towards extending random sketching and compressing sensing techniques for linear problems to nonlinear ones. We discuss example applications of our results to improved bounds for compressed sensing via generative neural networks.
Fourier Sparse Leverage Scores and Approximate Kernel Learning
Jun 12, 2020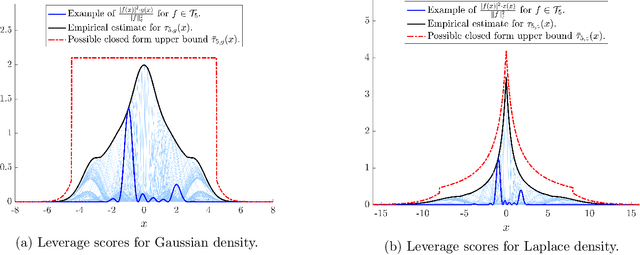
We prove new explicit upper bounds on the leverage scores of Fourier sparse functions under both the Gaussian and Laplace measures. In particular, we study $s$-sparse functions of the form $f(x) = \sum_{j=1}^s a_j e^{i \lambda_j x}$ for coefficients $a_j \in \mathbb{C}$ and frequencies $\lambda_j \in \mathbb{R}$. Bounding Fourier sparse leverage scores under various measures is of pure mathematical interest in approximation theory, and our work extends existing results for the uniform measure [Erd17,CP19a]. Practically, our bounds are motivated by two important applications in machine learning: 1. Kernel Approximation. They yield a new random Fourier features algorithm for approximating Gaussian and Cauchy (rational quadratic) kernel matrices. For low-dimensional data, our method uses a near optimal number of features, and its runtime is polynomial in the $statistical\ dimension$ of the approximated kernel matrix. It is the first "oblivious sketching method" with this property for any kernel besides the polynomial kernel, resolving an open question of [AKM+17,AKK+20b]. 2. Active Learning. They can be used as non-uniform sampling distributions for robust active learning when data follows a Gaussian or Laplace distribution. Using the framework of [AKM+19], we provide essentially optimal results for bandlimited and multiband interpolation, and Gaussian process regression. These results generalize existing work that only applies to uniformly distributed data.
Node Embeddings and Exact Low-Rank Representations of Complex Networks
Jun 10, 2020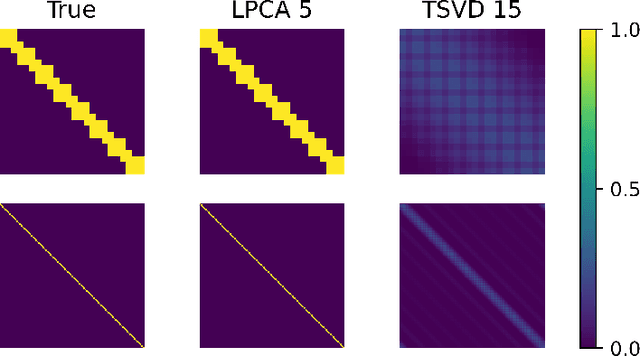
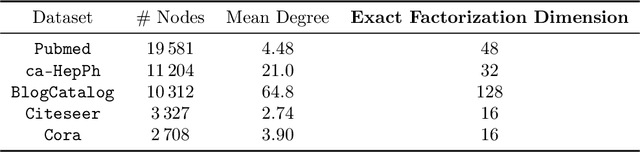
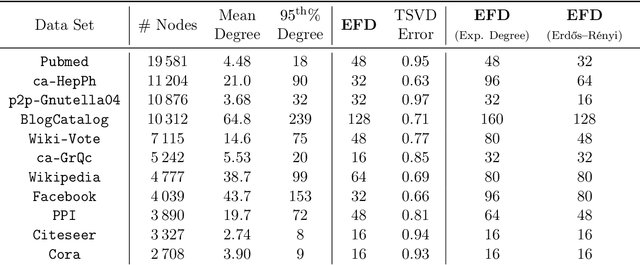
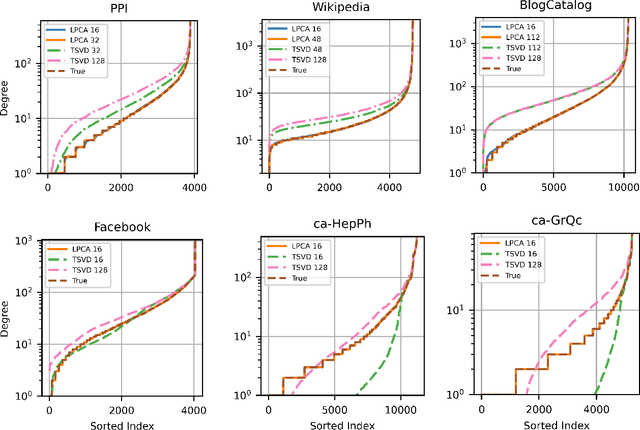
Low-dimensional embeddings, from classical spectral embeddings to modern neural-net-inspired methods, are a cornerstone in the modeling and analysis of complex networks. Recent work by Seshadhri et al. (PNAS 2020) suggests that such embeddings cannot capture local structure arising in complex networks. In particular, they show that any network generated from a natural low-dimensional model cannot be both sparse and have high triangle density (high clustering coefficient), two hallmark properties of many real-world networks. In this work we show that the results of Seshadhri et al. are intimately connected to the model they use rather than the low-dimensional structure of complex networks. Specifically, we prove that a minor relaxation of their model can generate sparse graphs with high triangle density. Surprisingly, we show that this same model leads to exact low-dimensional factorizations of many real-world networks. We give a simple algorithm based on logistic principal component analysis (LPCA) that succeeds in finding such exact embeddings. Finally, we perform a large number of experiments that verify the ability of very low-dimensional embeddings to capture local structure in real-world networks.