 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadText-1K: Text Detection & Recognition Dataset for Driving Videos
May 19, 2020



Perceiving text is crucial to understand semantics of outdoor scenes and hence is a critical requirement to build intelligent systems for driver assistance and self-driving. Most of the existing datasets for text detection and recognition comprise still images and are mostly compiled keeping text in mind. This paper introduces a new "RoadText-1K" dataset for text in driving videos. The dataset is 20 times larger than the existing largest dataset for text in videos. Our dataset comprises 1000 video clips of driving without any bias towards text and with annotations for text bounding boxes and transcriptions in every frame. State of the art methods for text detection, recognition and tracking are evaluated on the new dataset and the results signify the challenges in unconstrained driving videos compared to existing datasets. This suggests that RoadText-1K is suited for research and development of reading systems, robust enough to be incorporated into more complex downstream tasks like driver assistance and self-driving. The dataset can be found at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtext-1k
Towards Automatic Face-to-Face Translation
Mar 01, 2020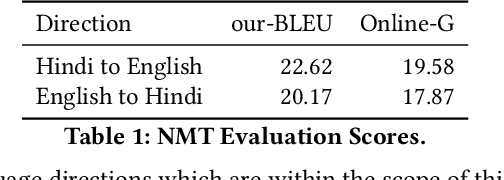
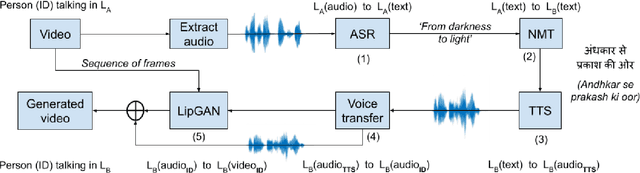

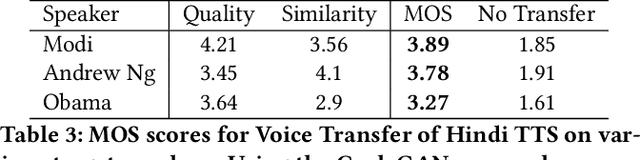
In light of the recent breakthroughs in automatic machine translation systems, we propose a novel approach that we term as "Face-to-Face Translation". As today's digital communication becomes increasingly visual, we argue that there is a need for systems that can automatically translate a video of a person speaking in language A into a target language B with realistic lip synchronization. In this work, we create an automatic pipeline for this problem and demonstrate its impact on multiple real-world applications. First, we build a working speech-to-speech translation system by bringing together multiple existing modules from speech and language. We then move towards "Face-to-Face Translation" by incorporating a novel visual module, LipGAN for generating realistic talking faces from the translated audio. Quantitative evaluation of LipGAN on the standard LRW test set shows that it significantly outperforms existing approaches across all standard metrics. We also subject our Face-to-Face Translation pipeline, to multiple human evaluations and show that it can significantly improve the overall user experience for consuming and interacting with multimodal content across languages. Code, models and demo video are made publicly available. Demo video: https://www.youtube.com/watch?v=aHG6Oei8jF0 Code and models: https://github.com/Rudrabha/LipGAN
* 9 pages (including references), 5 figures, Published in ACM Multimedia, 2019
ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard
Dec 20, 2019


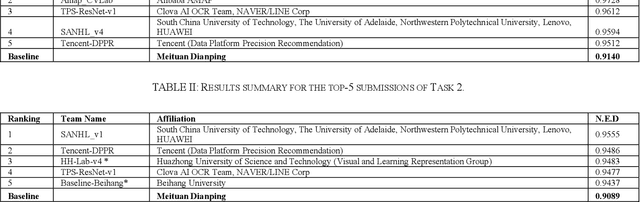
Chinese scene text reading is one of the most challenging problems in computer vision and has attracted great interest. Different from English text, Chinese has more than 6000 commonly used characters and Chinesecharacters can be arranged in various layouts with numerous fonts. The Chinese signboards in street view are a good choice for Chinese scene text images since they have different backgrounds, fonts and layouts. We organized a competition called ICDAR2019-ReCTS, which mainly focuses on reading Chinese text on signboard. This report presents the final results of the competition. A large-scale dataset of 25,000 annotated signboard images, in which all the text lines and characters are annotated with locations and transcriptions, were released. Four tasks, namely character recognition, text line recognition, text line detection and end-to-end recognition were set up. Besides, considering the Chinese text ambiguity issue, we proposed a multi ground truth (multi-GT) evaluation method to make evaluation fairer. The competition started on March 1, 2019 and ended on April 30, 2019. 262 submissions from 46 teams are received. Most of the participants come from universities, research institutes, and tech companies in China. There are also some participants from the United States, Australia, Singapore, and Korea. 21 teams submit results for Task 1, 23 teams submit results for Task 2, 24 teams submit results for Task 3, and 13 teams submit results for Task 4. The official website for the competition is http://rrc.cvc.uab.es/?ch=12.
A Deep Learning Approach for Robust Corridor Following
Nov 18, 2019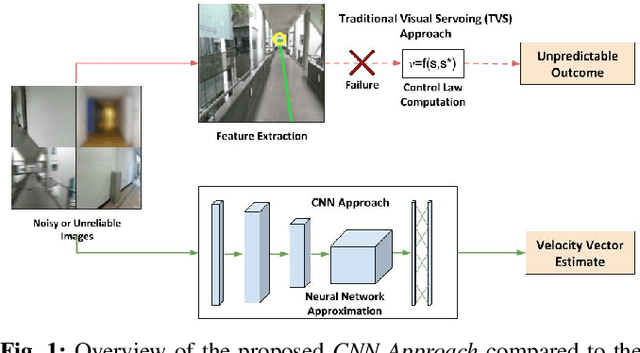
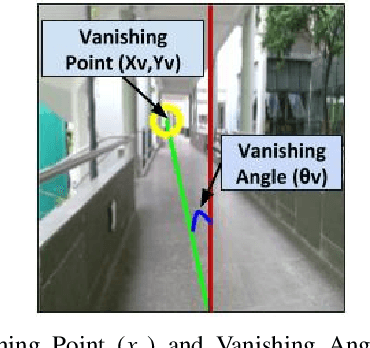

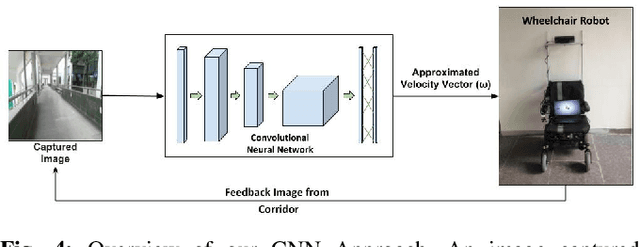
For an autonomous corridor following task where the environment is continuously changing, several forms of environmental noise prevent an automated feature extraction procedure from performing reliably. Moreover, in cases where pre-defined features are absent from the captured data, a well defined control signal for performing the servoing task fails to get produced. In order to overcome these drawbacks, we present in this work, using a convolutional neural network (CNN) to directly estimate the required control signal from an image, encompassing feature extraction and control law computation into one single end-to-end framework. In particular, we study the task of autonomous corridor following using a CNN and present clear advantages in cases where a traditional method used for performing the same task fails to give a reliable outcome. We evaluate the performance of our method on this task on a Wheelchair Platform developed at our institute for this purpose.
A Baseline Neural Machine Translation System for Indian Languages
Jul 29, 2019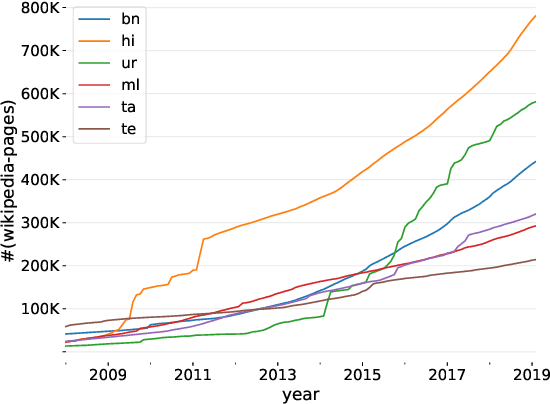
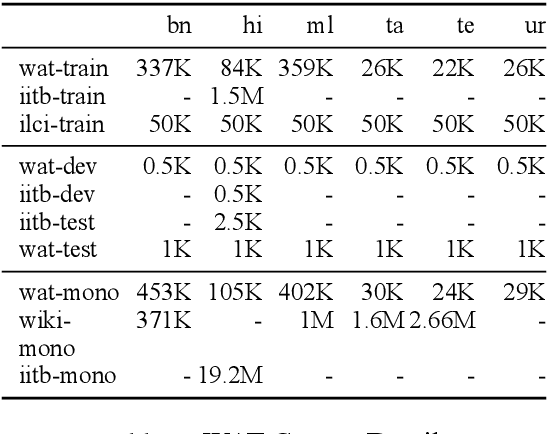
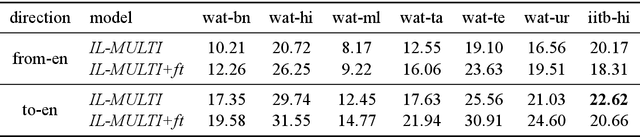

We present a simple, yet effective, Neural Machine Translation system for Indian languages. We demonstrate the feasibility for multiple language pairs, and establish a strong baseline for further research.
ICDAR 2019 Competition on Scene Text Visual Question Answering
Jun 30, 2019
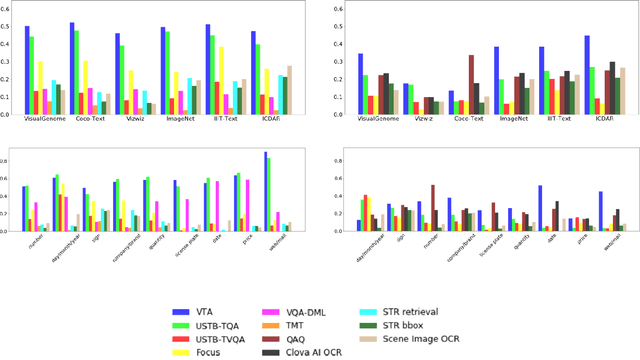
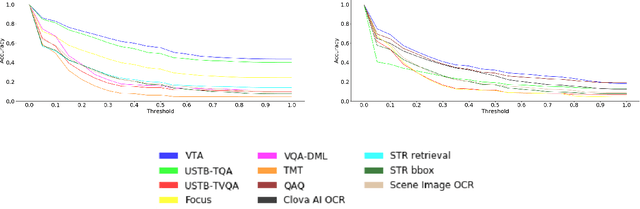
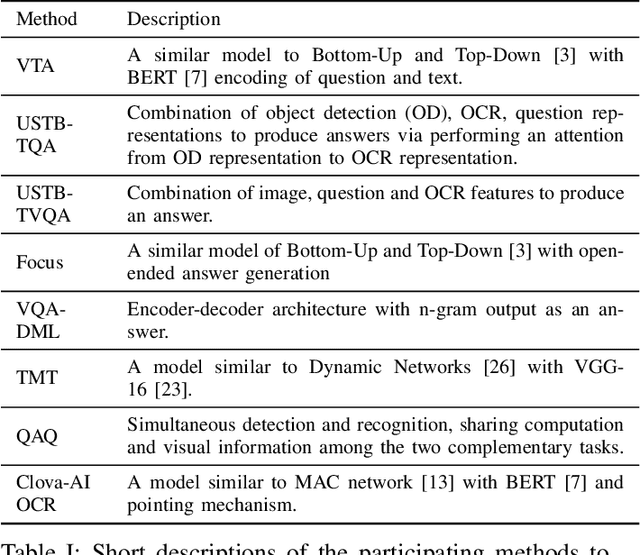
This paper presents final results of ICDAR 2019 Scene Text Visual Question Answering competition (ST-VQA). ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image. The competition introduces a new dataset comprising 23,038 images annotated with 31,791 question/answer pairs where the answer is always grounded on text instances present in the image. The images are taken from 7 different public computer vision datasets, covering a wide range of scenarios. The competition was structured in three tasks of increasing difficulty, that require reading the text in a scene and understanding it in the context of the scene, to correctly answer a given question. A novel evaluation metric is presented, which elegantly assesses both key capabilities expected from an optimal model: text recognition and image understanding. A detailed analysis of results from different participants is showcased, which provides insight into the current capabilities of VQA systems that can read. We firmly believe the dataset proposed in this challenge will be an important milestone to consider towards a path of more robust and general models that can exploit scene text to achieve holistic image understanding.
Scene Text Visual Question Answering
May 31, 2019
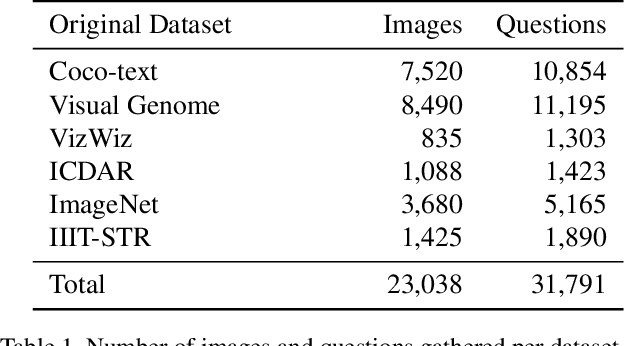
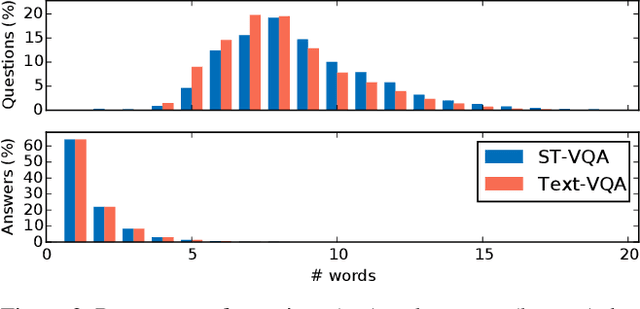
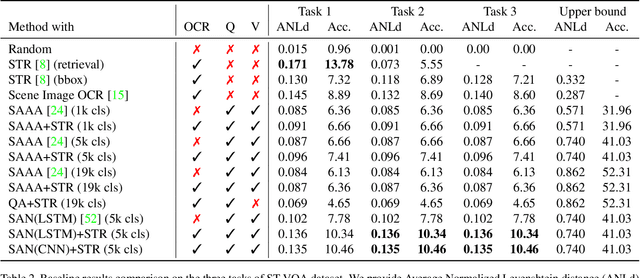
Current visual question answering datasets do not consider the rich semantic information conveyed by text within an image. In this work, we present a new dataset, ST-VQA, that aims to highlight the importance of exploiting high-level semantic information present in images as textual cues in the VQA process. We use this dataset to define a series of tasks of increasing difficulty for which reading the scene text in the context provided by the visual information is necessary to reason and generate an appropriate answer. We propose a new evaluation metric for these tasks to account both for reasoning errors as well as shortcomings of the text recognition module. In addition we put forward a series of baseline methods, which provide further insight to the newly released dataset, and set the scene for further research.
A Cost Efficient Approach to Correct OCR Errors in Large Document Collections
May 28, 2019


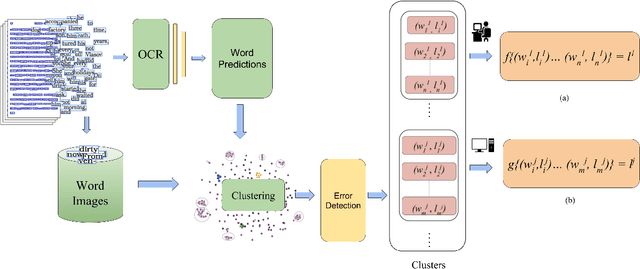
Word error rate of an ocr is often higher than its character error rate. This is especially true when ocrs are designed by recognizing characters. High word accuracies are critical to tasks like the creation of content in digital libraries and text-to-speech applications. In order to detect and correct the misrecognised words, it is common for an ocr module to employ a post-processor to further improve the word accuracy. However, conventional approaches to post-processing like looking up a dictionary or using a statistical language model (slm), are still limited. In many such scenarios, it is often required to remove the outstanding errors manually. We observe that the traditional post-processing schemes look at error words sequentially since ocrs process documents one at a time. We propose a cost-efficient model to address the error words in batches rather than correcting them individually. We exploit the fact that a collection of documents, unlike a single document, has a structure leading to repetition of words. Such words, if efficiently grouped together and corrected as a whole can lead to a significant reduction in the cost. Correction can be fully automatic or with a human in the loop. Towards this, we employ a novel clustering scheme to obtain fairly homogeneous clusters. We compare the performance of our model with various baseline approaches including the case where all the errors are removed by a human. We demonstrate the efficacy of our solution empirically by reporting more than 70% reduction in the human effort with near perfect error correction. We validate our method on Books from multiple languages.
CVIT-MT Systems for WAT-2018
Mar 19, 2019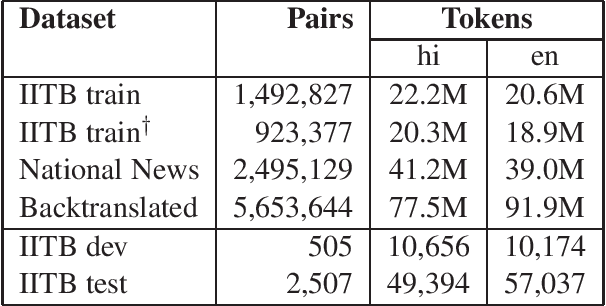
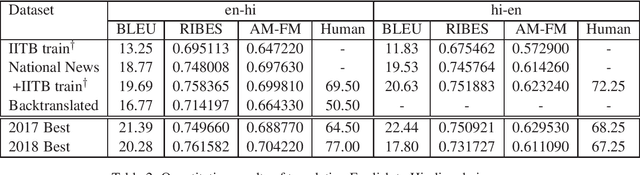
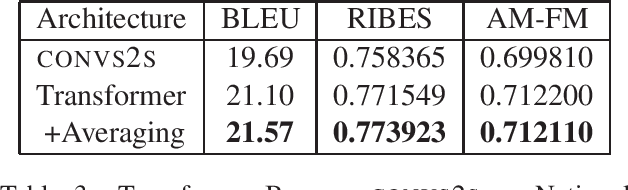
This document describes the machine translation system used in the submissions of IIIT-Hyderabad CVIT-MT for the WAT-2018 English-Hindi translation task. Performance is evaluated on the associated corpus provided by the organizers. We experimented with convolutional sequence to sequence architectures. We also train with additional data obtained through backtranslation.
Self-Supervised Visual Representations for Cross-Modal Retrieval
Jan 31, 2019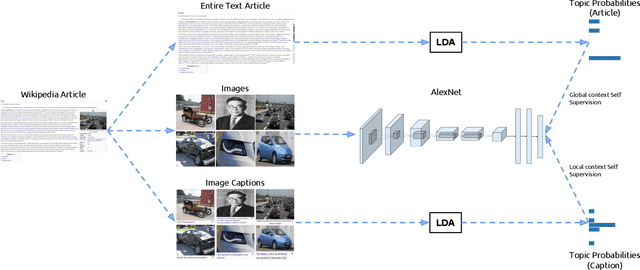
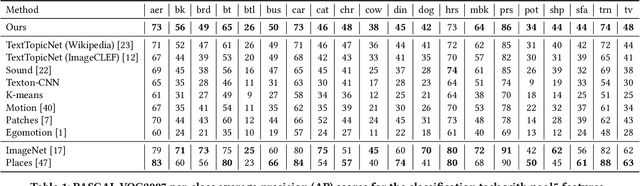

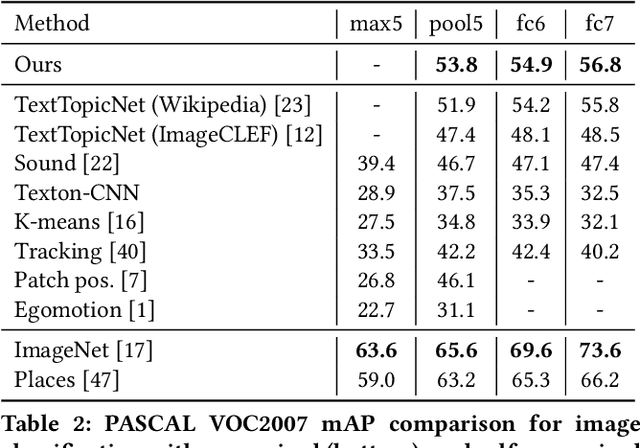
Cross-modal retrieval methods have been significantly improved in last years with the use of deep neural networks and large-scale annotated datasets such as ImageNet and Places. However, collecting and annotating such datasets requires a tremendous amount of human effort and, besides, their annotations are usually limited to discrete sets of popular visual classes that may not be representative of the richer semantics found on large-scale cross-modal retrieval datasets. In this paper, we present a self-supervised cross-modal retrieval framework that leverages as training data the correlations between images and text on the entire set of Wikipedia articles. Our method consists in training a CNN to predict: (1) the semantic context of the article in which an image is more probable to appear as an illustration (global context), and (2) the semantic context of its caption (local context). Our experiments demonstrate that the proposed method is not only capable of learning discriminative visual representations for solving vision tasks like image classification and object detection, but that the learned representations are better for cross-modal retrieval when compared to supervised pre-training of the network on the ImageNet dataset.