 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Learning Machine (SLM): Methodology and Performance
May 11, 2022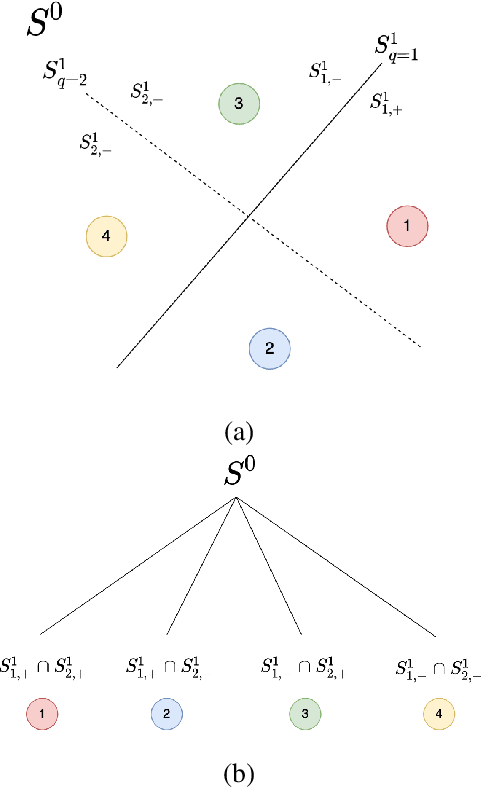
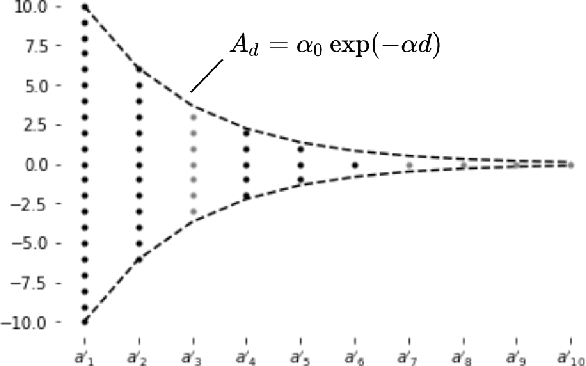
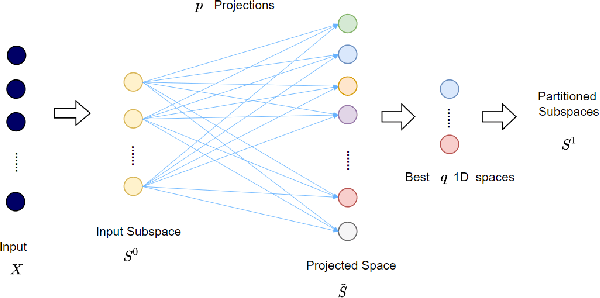
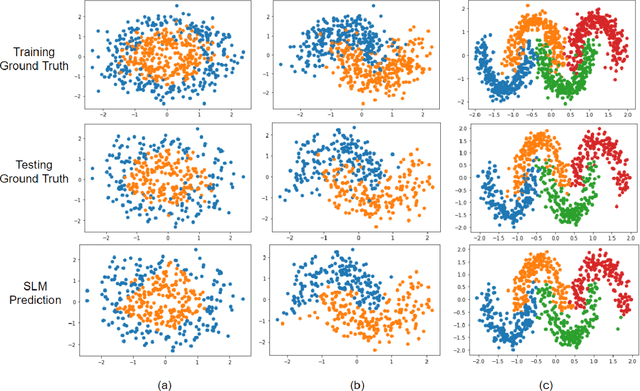
Inspired by the feedforward multilayer perceptron (FF-MLP), decision tree (DT) and extreme learning machine (ELM), a new classification model, called the subspace learning machine (SLM), is proposed in this work. SLM first identifies a discriminant subspace, $S^0$, by examining the discriminant power of each input feature. Then, it uses probabilistic projections of features in $S^0$ to yield 1D subspaces and finds the optimal partition for each of them. This is equivalent to partitioning $S^0$ with hyperplanes. A criterion is developed to choose the best $q$ partitions that yield $2q$ partitioned subspaces among them. We assign $S^0$ to the root node of a decision tree and the intersections of $2q$ subspaces to its child nodes of depth one. The partitioning process is recursively applied at each child node to build an SLM tree. When the samples at a child node are sufficiently pure, the partitioning process stops and each leaf node makes a prediction. The idea can be generalized to regression, leading to the subspace learning regressor (SLR). Furthermore, ensembles of SLM/SLR trees can yield a stronger predictor. Extensive experiments are conducted for performance benchmarking among SLM/SLR trees, ensembles and classical classifiers/regressors.
DefakeHop++: An Enhanced Lightweight Deepfake Detector
Apr 30, 2022
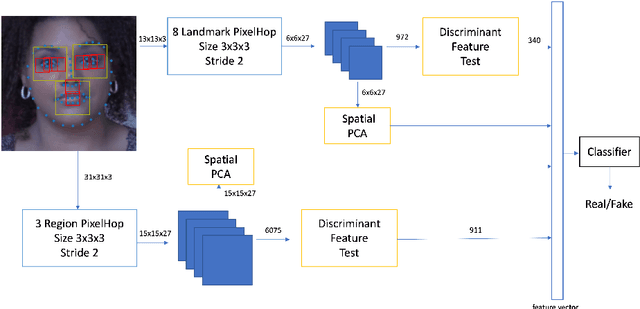
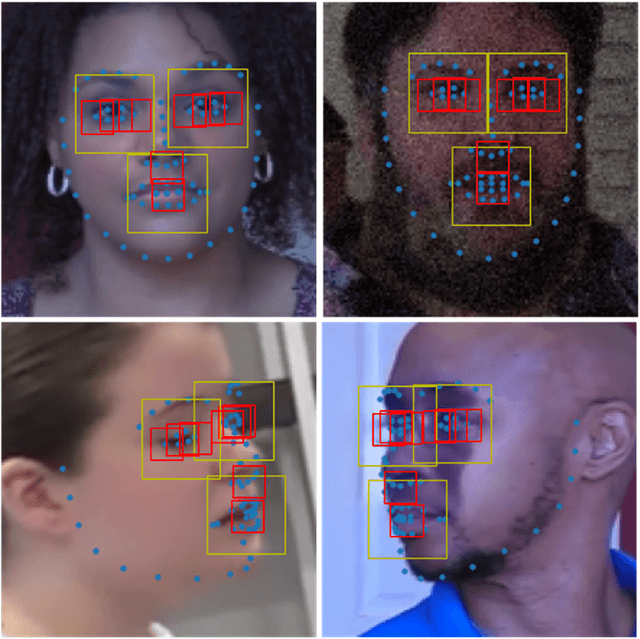
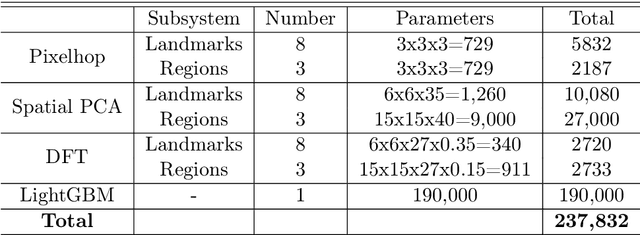
On the basis of DefakeHop, an enhanced lightweight Deepfake detector called DefakeHop++ is proposed in this work. The improvements lie in two areas. First, DefakeHop examines three facial regions (i.e., two eyes and mouth) while DefakeHop++ includes eight more landmarks for broader coverage. Second, for discriminant features selection, DefakeHop uses an unsupervised approach while DefakeHop++ adopts a more effective approach with supervision, called the Discriminant Feature Test (DFT). In DefakeHop++, rich spatial and spectral features are first derived from facial regions and landmarks automatically. Then, DFT is used to select a subset of discriminant features for classifier training. As compared with MobileNet v3 (a lightweight CNN model of 1.5M parameters targeting at mobile applications), DefakeHop++ has a model of 238K parameters, which is 16% of MobileNet v3. Furthermore, DefakeHop++ outperforms MobileNet v3 in Deepfake image detection performance in a weakly-supervised setting.
GraphHop++: New Insights into GraphHop and Its Enhancement
Apr 19, 2022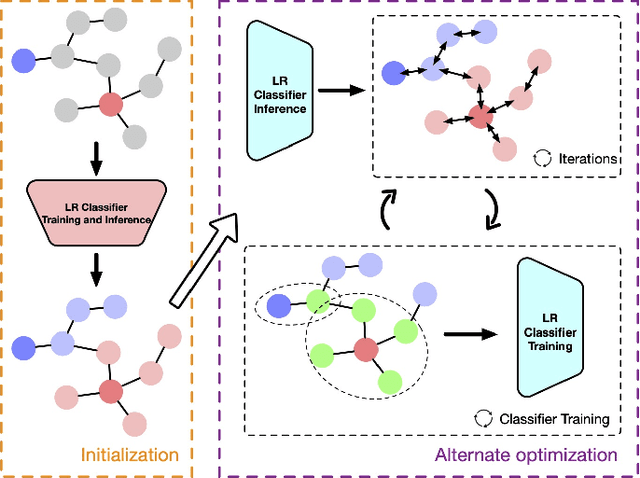
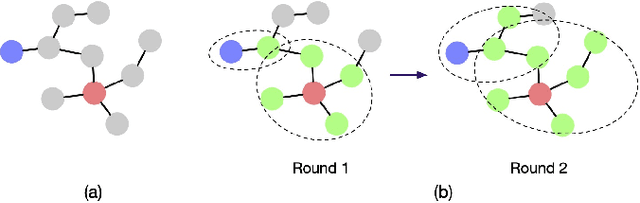
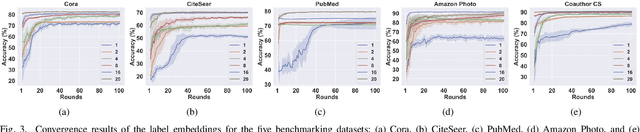
An enhanced label propagation (LP) method called GraphHop has been proposed recently. It outperforms graph convolutional networks (GCNs) in the semi-supervised node classification task on various networks. Although the performance of GraphHop was explained intuitively with joint node attributes and labels smoothening, its rigorous mathematical treatment is lacking. In this paper, new insights into GraphHop are provided by analyzing it from a constrained optimization viewpoint. We show that GraphHop offers an alternate optimization to a certain regularization problem defined on graphs. Based on this interpretation, we propose two ideas to improve GraphHop furthermore, which leads to GraphHop++. We conduct extensive experiments to demonstrate the effectiveness and efficiency of GraphHop++. It is observed that GraphHop++ outperforms all other benchmarking methods, including GraphHop, consistently on five test datasets as well as an object recognition task at extremely low label rates (i.e., 1, 2, 4, 8, 16, and 20 labeled samples per class).
HUNIS: High-Performance Unsupervised Nuclei Instance Segmentation
Mar 28, 2022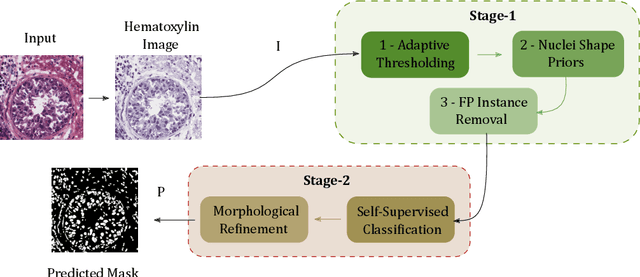
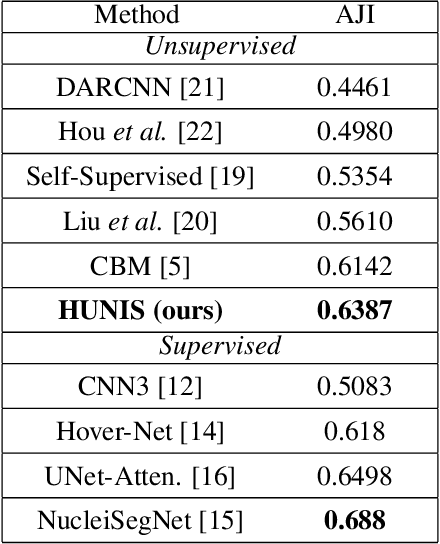
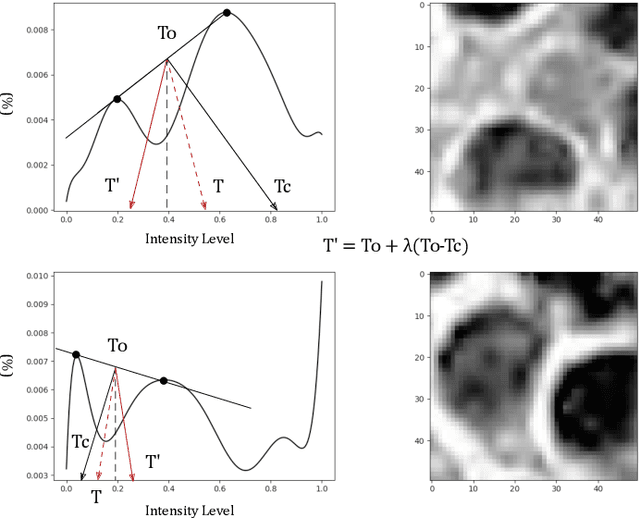
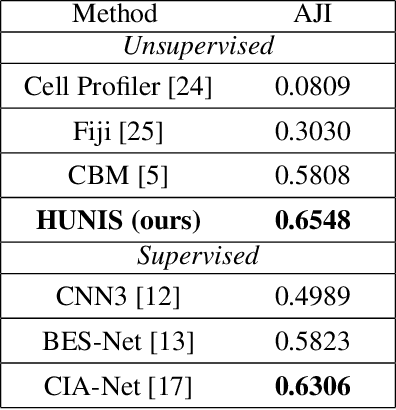
A high-performance unsupervised nuclei instance segmentation (HUNIS) method is proposed in this work. HUNIS consists of two-stage block-wise operations. The first stage includes: 1) adaptive thresholding of pixel intensities, 2) incorporation of nuclei size/shape priors and 3) removal of false positive nuclei instances. Then, HUNIS conducts the second stage segmentation by receiving guidance from the first one. The second stage exploits the segmentation masks obtained in the first stage and leverages color and shape distributions for a more accurate segmentation. The main purpose of the two-stage design is to provide pixel-wise pseudo-labels from the first to the second stage. This self-supervision mechanism is novel and effective. Experimental results on the MoNuSeg dataset show that HUNIS outperforms all other unsupervised methods by a substantial margin. It also has a competitive standing among state-of-the-art supervised methods.
On Supervised Feature Selection from High Dimensional Feature Spaces
Mar 22, 2022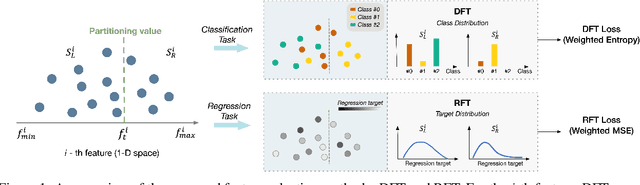
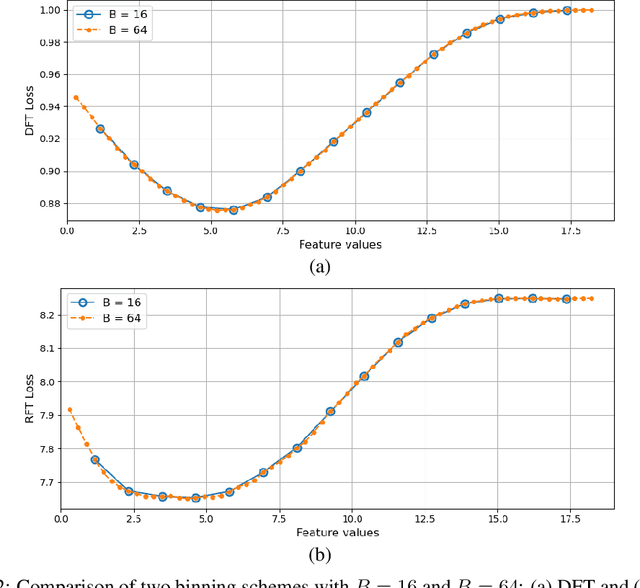
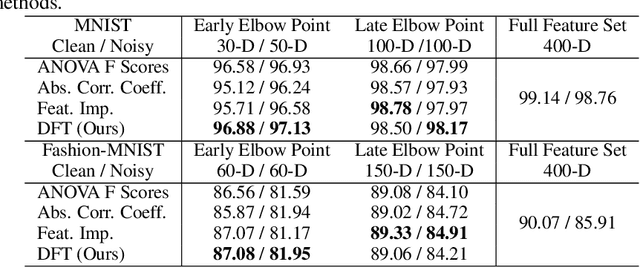
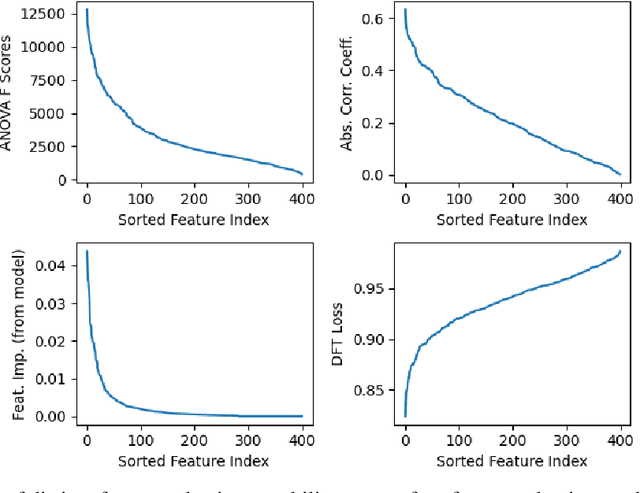
The application of machine learning to image and video data often yields a high dimensional feature space. Effective feature selection techniques identify a discriminant feature subspace that lowers computational and modeling costs with little performance degradation. A novel supervised feature selection methodology is proposed for machine learning decisions in this work. The resulting tests are called the discriminant feature test (DFT) and the relevant feature test (RFT) for the classification and regression problems, respectively. The DFT and RFT procedures are described in detail. Furthermore, we compare the effectiveness of DFT and RFT with several classic feature selection methods. To this end, we use deep features obtained by LeNet-5 for MNIST and Fashion-MNIST datasets as illustrative examples. It is shown by experimental results that DFT and RFT can select a lower dimensional feature subspace distinctly and robustly while maintaining high decision performance.
Just Rank: Rethinking Evaluation with Word and Sentence Similarities
Mar 21, 2022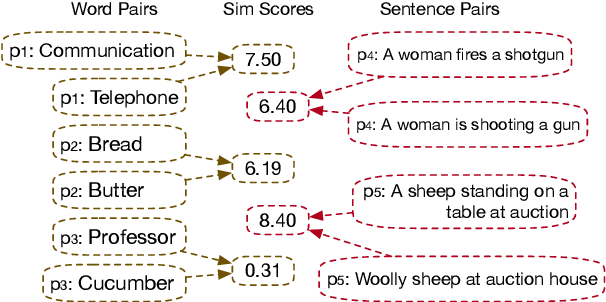
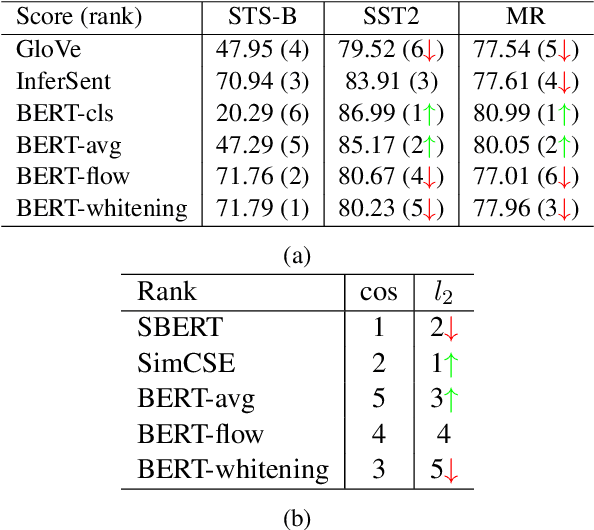
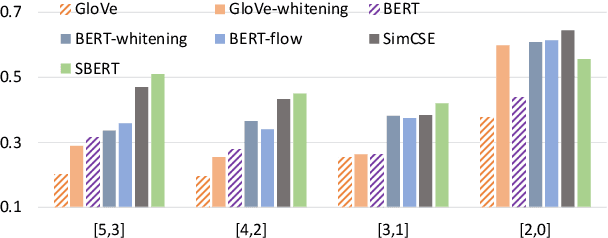

Word and sentence embeddings are useful feature representations in natural language processing. However, intrinsic evaluation for embeddings lags far behind, and there has been no significant update since the past decade. Word and sentence similarity tasks have become the de facto evaluation method. It leads models to overfit to such evaluations, negatively impacting embedding models' development. This paper first points out the problems using semantic similarity as the gold standard for word and sentence embedding evaluations. Further, we propose a new intrinsic evaluation method called EvalRank, which shows a much stronger correlation with downstream tasks. Extensive experiments are conducted based on 60+ models and popular datasets to certify our judgments. Finally, the practical evaluation toolkit is released for future benchmarking purposes.
PCRP: Unsupervised Point Cloud Object Retrieval and Pose Estimation
Feb 16, 2022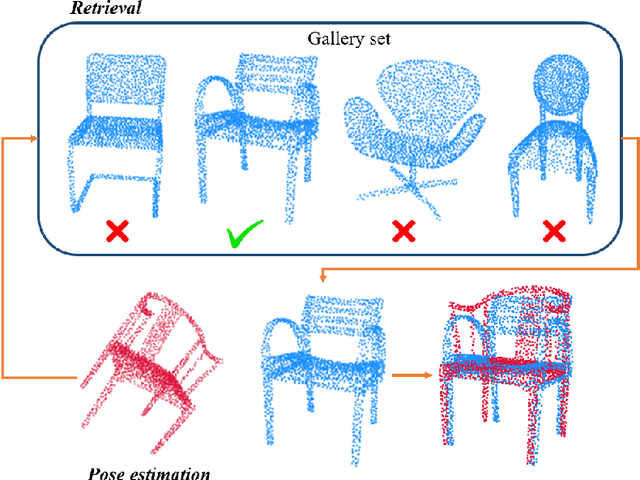
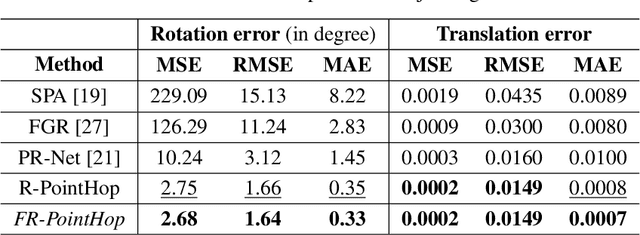
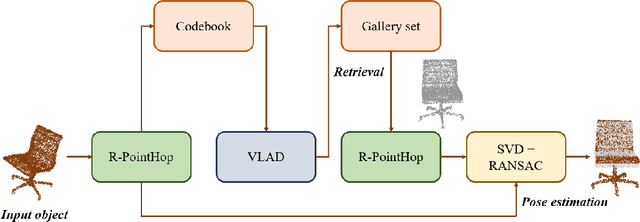
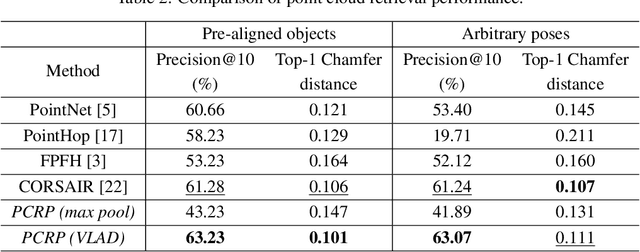
An unsupervised point cloud object retrieval and pose estimation method, called PCRP, is proposed in this work. It is assumed that there exists a gallery point cloud set that contains point cloud objects with given pose orientation information. PCRP attempts to register the unknown point cloud object with those in the gallery set so as to achieve content-based object retrieval and pose estimation jointly, where the point cloud registration task is built upon an enhanced version of the unsupervised R-PointHop method. Experiments on the ModelNet40 dataset demonstrate the superior performance of PCRP in comparison with traditional and learning based methods.
A Survey on Perceptually Optimized Video Coding
Dec 23, 2021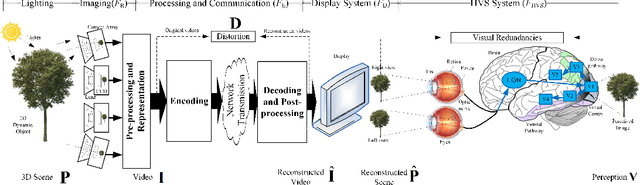
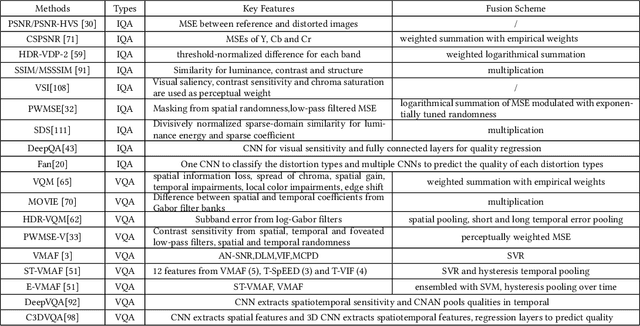
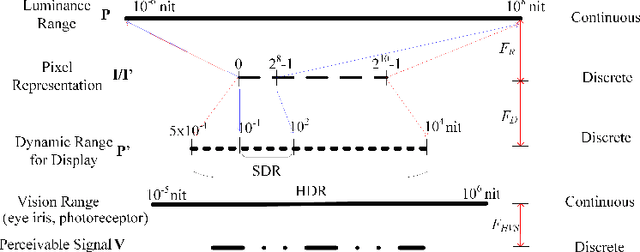
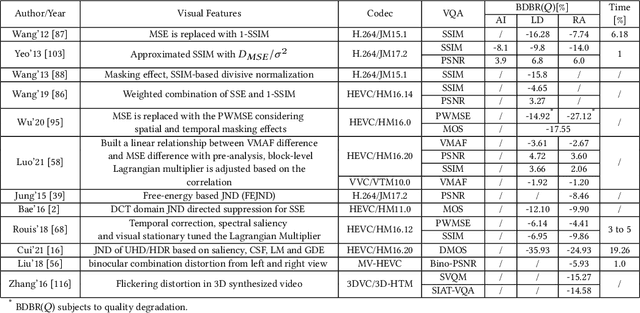
Videos are developing in the trends of Ultra High Definition (UHD), High Frame Rate (HFR), High Dynamic Range (HDR), Wide Color Gammut (WCG) and high fidelity, which provide users with more realistic visual experiences. However, the amount of video data increases exponentially and requires high efficiency video compression for storage and network transmission. Perceptually optimized video coding aims to exploit visual redundancies in videos so as to maximize compression efficiency. In this paper, we present a systematic survey on the recent advances and challenges on perceptually optimized video coding. Firstly, we present problem formulation and framework of perceptually optimized video coding, which includes visual perception modelling, visual quality assessment and perception guided coding optimization. Secondly, the recent advances on visual factors, key computational visual models and quality assessment models are presented. Thirdly, we do systematic review on perceptual video coding optimizations from four key aspects, which includes perceptually optimized bit allocation, rate-distortion optimization, transform and quantization, filtering and enhancement. In each part, problem formulation, working flow, recent advances, advantages and challenges are presented. Fourthly, perceptual coding performance of latest coding standards and tools are experimentally analyzed. Finally, challenging issues and future opportunities on perceptual video coding are identified.
CORE: A Knowledge Graph Entity Type Prediction Method via Complex Space Regression and Embedding
Dec 19, 2021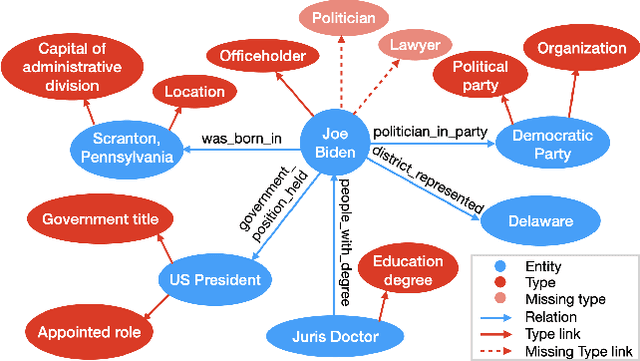

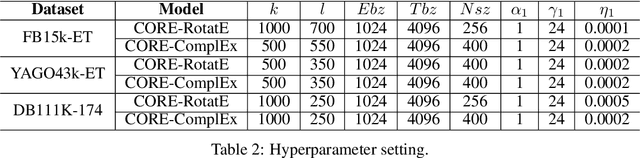
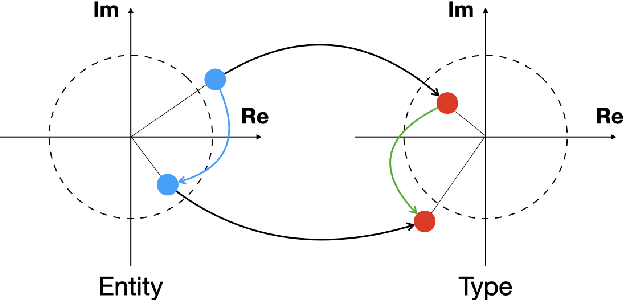
Entity type prediction is an important problem in knowledge graph (KG) research. A new KG entity type prediction method, named CORE (COmplex space Regression and Embedding), is proposed in this work. The proposed CORE method leverages the expressive power of two complex space embedding models; namely, RotatE and ComplEx models. It embeds entities and types in two different complex spaces using either RotatE or ComplEx. Then, we derive a complex regression model to link these two spaces. Finally, a mechanism to optimize embedding and regression parameters jointly is introduced. Experiments show that CORE outperforms benchmarking methods on representative KG entity type inference datasets. Strengths and weaknesses of various entity type prediction methods are analyzed.
KGBoost: A Classification-based Knowledge Base Completion Method with Negative Sampling
Dec 17, 2021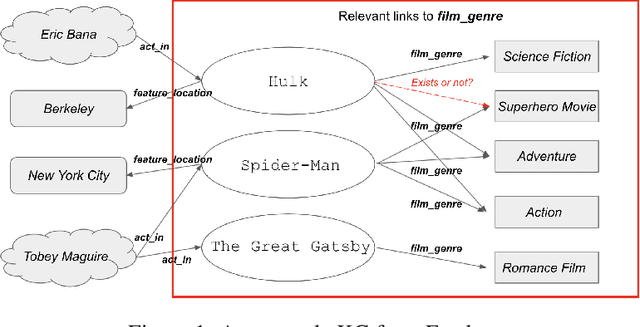
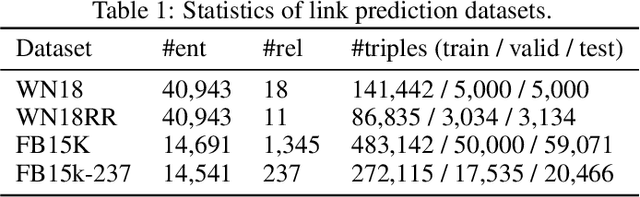

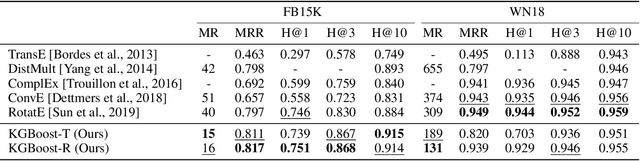
Knowledge base completion is formulated as a binary classification problem in this work, where an XGBoost binary classifier is trained for each relation using relevant links in knowledge graphs (KGs). The new method, named KGBoost, adopts a modularized design and attempts to find hard negative samples so as to train a powerful classifier for missing link prediction. We conduct experiments on multiple benchmark datasets, and demonstrate that KGBoost outperforms state-of-the-art methods across most datasets. Furthermore, as compared with models trained by end-to-end optimization, KGBoost works well under the low-dimensional setting so as to allow a smaller model size.