 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Attention Localization (SAL): Methodology and Application to Object Classification
Aug 03, 2022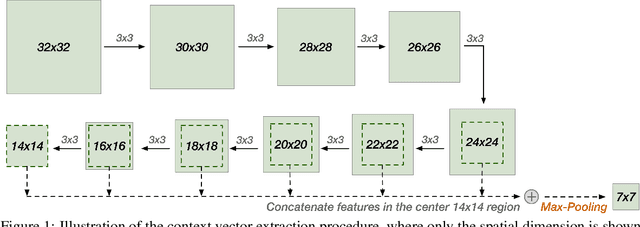
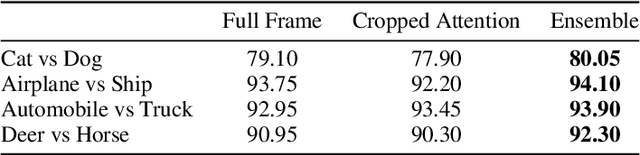
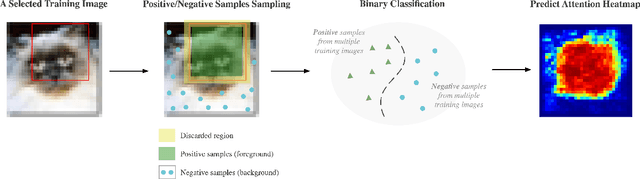
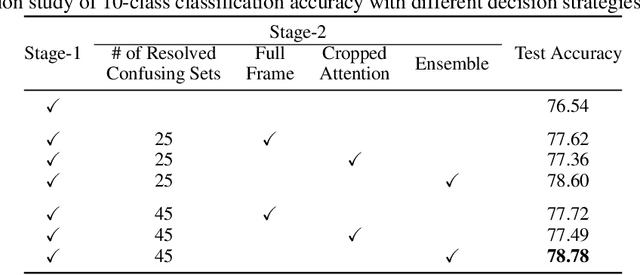
A statistical attention localization (SAL) method is proposed to facilitate the object classification task in this work. SAL consists of three steps: 1) preliminary attention window selection via decision statistics, 2) attention map refinement, and 3) rectangular attention region finalization. SAL computes soft-decision scores of local squared windows and uses them to identify salient regions in Step 1. To accommodate object of various sizes and shapes, SAL refines the preliminary result and obtain an attention map of more flexible shape in Step 2. Finally, SAL yields a rectangular attention region using the refined attention map and bounding box regularization in Step 3. As an application, we adopt E-PixelHop, which is an object classification solution based on successive subspace learning (SSL), as the baseline. We apply SAL so as to obtain a cropped-out and resized attention region as an alternative input. Classification results of the whole image as well as the attention region are ensembled to achieve the highest classification accuracy. Experiments on the CIFAR-10 dataset are given to demonstrate the advantage of the SAL-assisted object classification method.
Augmenting Vision Language Pretraining by Learning Codebook with Visual Semantics
Jul 31, 2022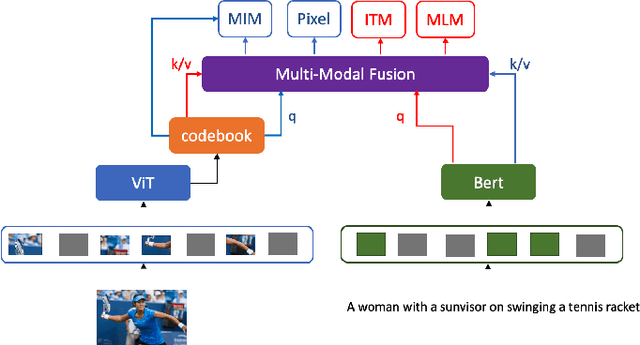



Language modality within the vision language pretraining framework is innately discretized, endowing each word in the language vocabulary a semantic meaning. In contrast, visual modality is inherently continuous and high-dimensional, which potentially prohibits the alignment as well as fusion between vision and language modalities. We therefore propose to "discretize" the visual representation by joint learning a codebook that imbues each visual token a semantic. We then utilize these discretized visual semantics as self-supervised ground-truths for building our Masked Image Modeling objective, a counterpart of Masked Language Modeling which proves successful for language models. To optimize the codebook, we extend the formulation of VQ-VAE which gives a theoretic guarantee. Experiments validate the effectiveness of our approach across common vision-language benchmarks.
Enhancing Image Rescaling using Dual Latent Variables in Invertible Neural Network
Jul 24, 2022
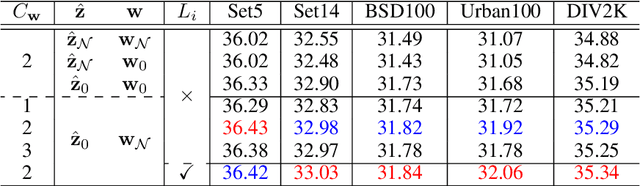
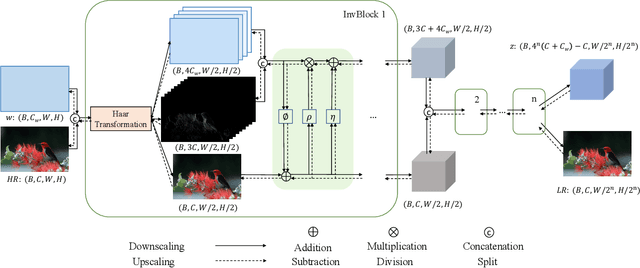
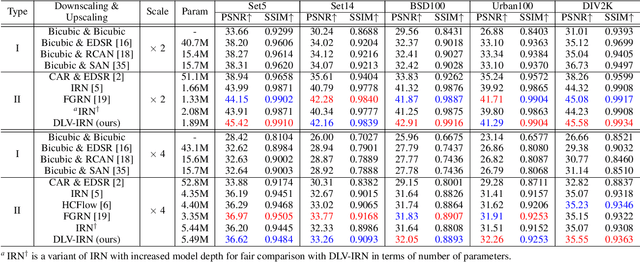
Normalizing flow models have been used successfully for generative image super-resolution (SR) by approximating complex distribution of natural images to simple tractable distribution in latent space through Invertible Neural Networks (INN). These models can generate multiple realistic SR images from one low-resolution (LR) input using randomly sampled points in the latent space, simulating the ill-posed nature of image upscaling where multiple high-resolution (HR) images correspond to the same LR. Lately, the invertible process in INN has also been used successfully by bidirectional image rescaling models like IRN and HCFlow for joint optimization of downscaling and inverse upscaling, resulting in significant improvements in upscaled image quality. While they are optimized for image downscaling too, the ill-posed nature of image downscaling, where one HR image could be downsized to multiple LR images depending on different interpolation kernels and resampling methods, is not considered. A new downscaling latent variable, in addition to the original one representing uncertainties in image upscaling, is introduced to model variations in the image downscaling process. This dual latent variable enhancement is applicable to different image rescaling models and it is shown in extensive experiments that it can improve image upscaling accuracy consistently without sacrificing image quality in downscaled LR images. It is also shown to be effective in enhancing other INN-based models for image restoration applications like image hiding.
GUSOT: Green and Unsupervised Single Object Tracking for Long Video Sequences
Jul 15, 2022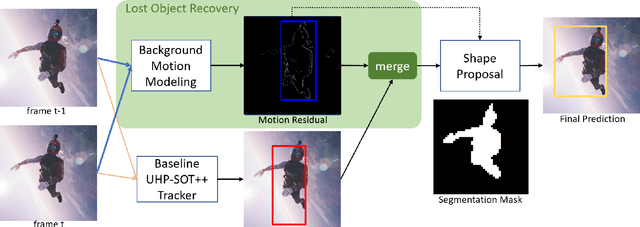
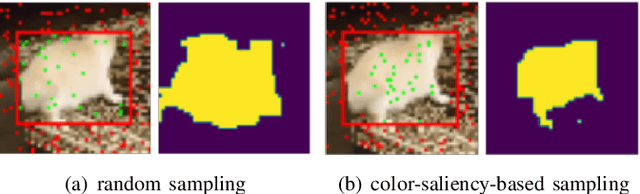
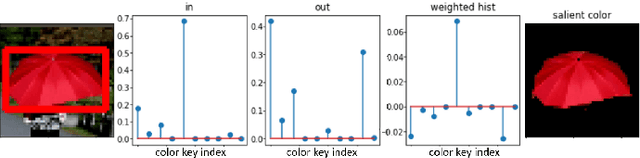
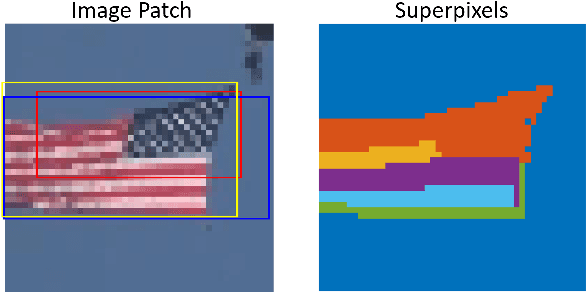
Supervised and unsupervised deep trackers that rely on deep learning technologies are popular in recent years. Yet, they demand high computational complexity and a high memory cost. A green unsupervised single-object tracker, called GUSOT, that aims at object tracking for long videos under a resource-constrained environment is proposed in this work. Built upon a baseline tracker, UHP-SOT++, which works well for short-term tracking, GUSOT contains two additional new modules: 1) lost object recovery, and 2) color-saliency-based shape proposal. They help resolve the tracking loss problem and offer a more flexible object proposal, respectively. Thus, they enable GUSOT to achieve higher tracking accuracy in the long run. We conduct experiments on the large-scale dataset LaSOT with long video sequences, and show that GUSOT offers a lightweight high-performance tracking solution that finds applications in mobile and edge computing platforms.
CompoundE: Knowledge Graph Embedding with Translation, Rotation and Scaling Compound Operations
Jul 12, 2022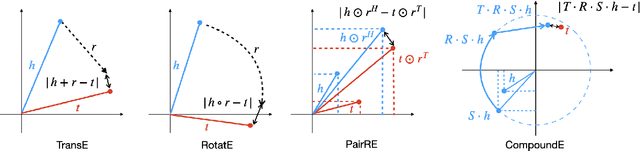
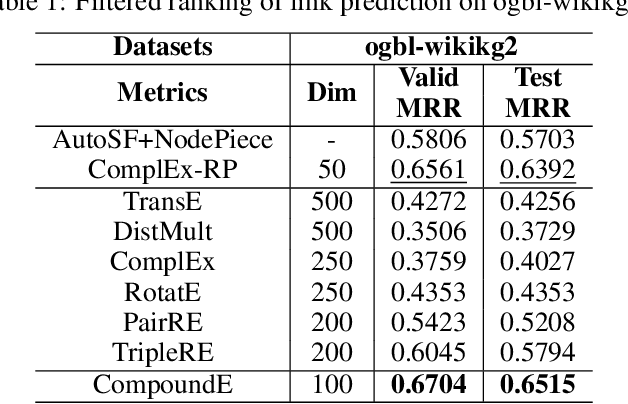
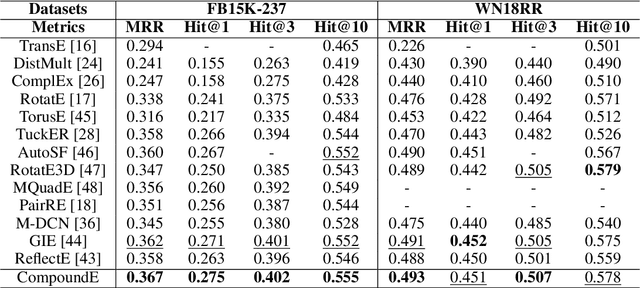
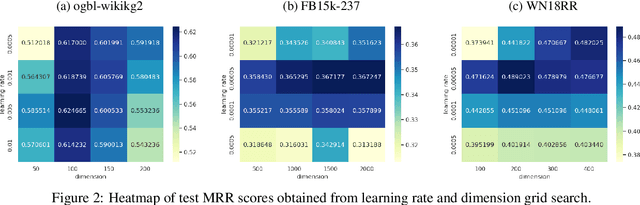
Translation, rotation, and scaling are three commonly used geometric manipulation operations in image processing. Besides, some of them are successfully used in developing effective knowledge graph embedding (KGE) models such as TransE and RotatE. Inspired by the synergy, we propose a new KGE model by leveraging all three operations in this work. Since translation, rotation, and scaling operations are cascaded to form a compound one, the new model is named CompoundE. By casting CompoundE in the framework of group theory, we show that quite a few scoring-function-based KGE models are special cases of CompoundE. CompoundE extends the simple distance-based relation to relation-dependent compound operations on head and/or tail entities. To demonstrate the effectiveness of CompoundE, we conduct experiments on three popular KG completion datasets. Experimental results show that CompoundE consistently achieves the state of-the-art performance.
GreenBIQA: A Lightweight Blind Image Quality Assessment Method
Jun 29, 2022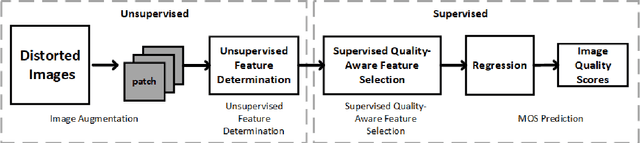
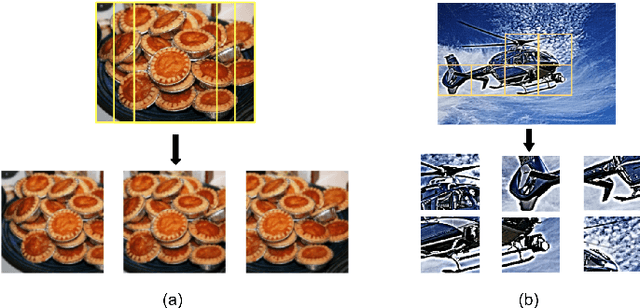
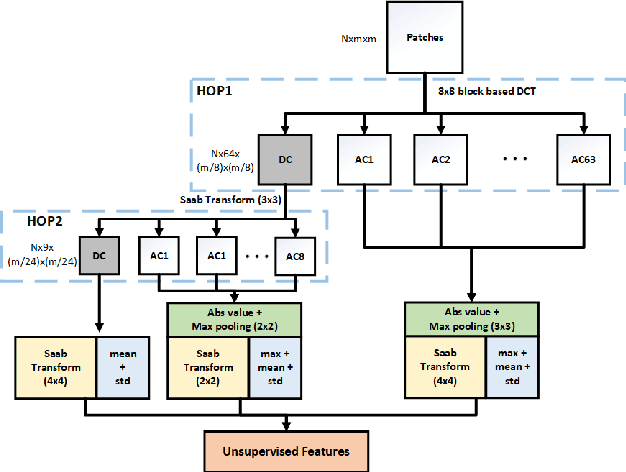
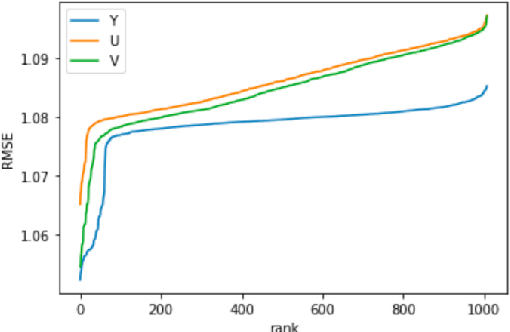
Deep neural networks (DNNs) achieve great success in blind image quality assessment (BIQA) with large pre-trained models in recent years. Their solutions cannot be easily deployed at mobile or edge devices, and a lightweight solution is desired. In this work, we propose a novel BIQA model, called GreenBIQA, that aims at high performance, low computational complexity and a small model size. GreenBIQA adopts an unsupervised feature generation method and a supervised feature selection method to extract quality-aware features. Then, it trains an XGBoost regressor to predict quality scores of test images. We conduct experiments on four popular IQA datasets, which include two synthetic-distortion and two authentic-distortion datasets. Experimental results show that GreenBIQA is competitive in performance against state-of-the-art DNNs with lower complexity and smaller model sizes.
SynWMD: Syntax-aware Word Mover's Distance for Sentence Similarity Evaluation
Jun 20, 2022
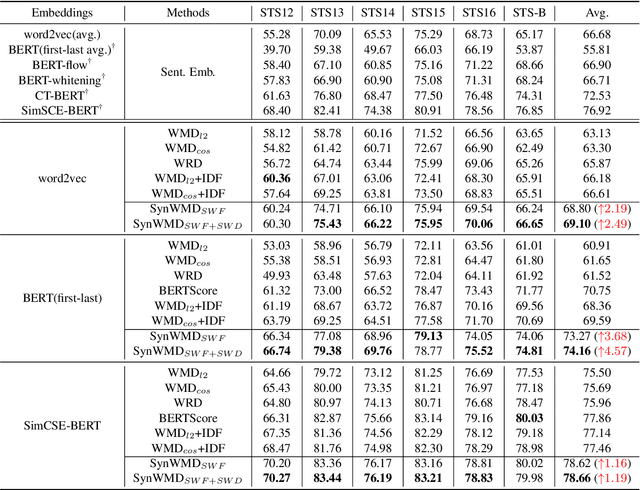
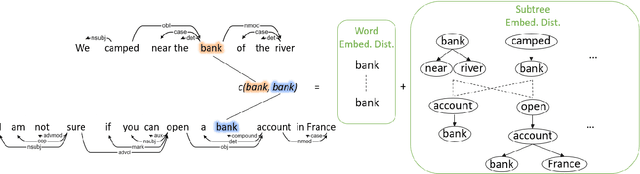
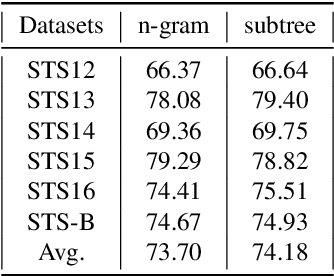
Word Mover's Distance (WMD) computes the distance between words and models text similarity with the moving cost between words in two text sequences. Yet, it does not offer good performance in sentence similarity evaluation since it does not incorporate word importance and fails to take inherent contextual and structural information in a sentence into account. An improved WMD method using the syntactic parse tree, called Syntax-aware Word Mover's Distance (SynWMD), is proposed to address these two shortcomings in this work. First, a weighted graph is built upon the word co-occurrence statistics extracted from the syntactic parse trees of sentences. The importance of each word is inferred from graph connectivities. Second, the local syntactic parsing structure of words is considered in computing the distance between words. To demonstrate the effectiveness of the proposed SynWMD, we conduct experiments on 6 textual semantic similarity (STS) datasets and 4 sentence classification datasets. Experimental results show that SynWMD achieves state-of-the-art performance on STS tasks. It also outperforms other WMD-based methods on sentence classification tasks.
Design of Supervision-Scalable Learning Systems: Methodology and Performance Benchmarking
Jun 18, 2022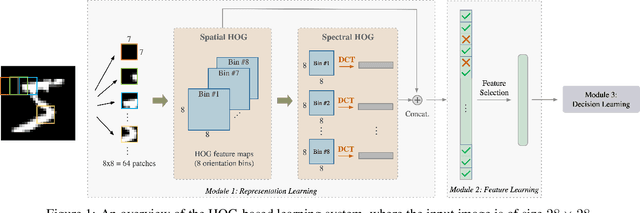
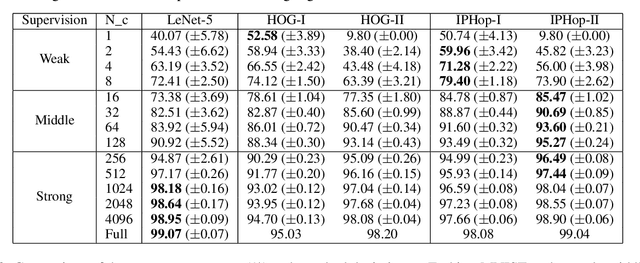
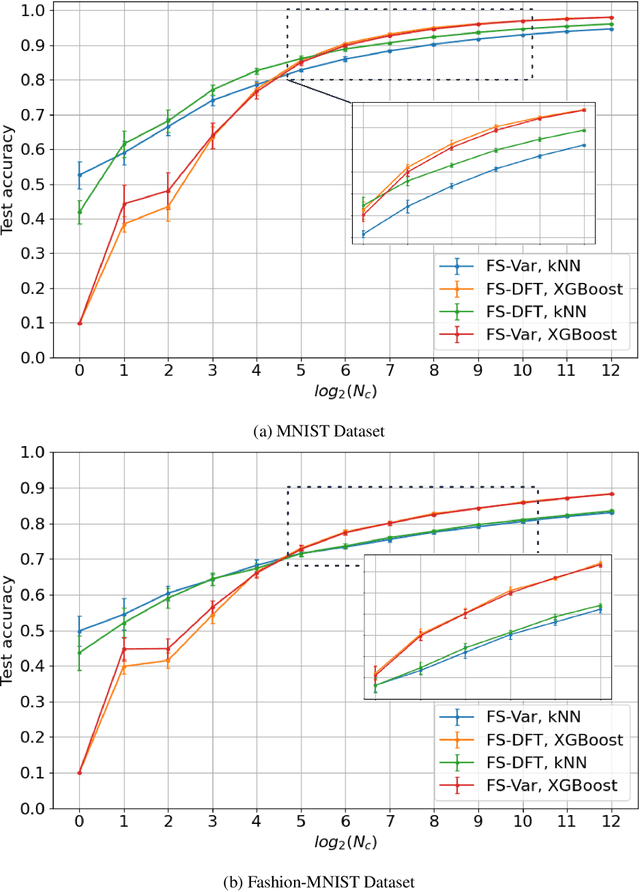
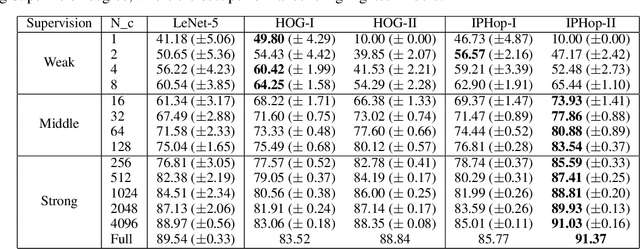
The design of robust learning systems that offer stable performance under a wide range of supervision degrees is investigated in this work. We choose the image classification problem as an illustrative example and focus on the design of modularized systems that consist of three learning modules: representation learning, feature learning and decision learning. We discuss ways to adjust each module so that the design is robust with respect to different training sample numbers. Based on these ideas, we propose two families of learning systems. One adopts the classical histogram of oriented gradients (HOG) features while the other uses successive-subspace-learning (SSL) features. We test their performance against LeNet-5, which is an end-to-end optimized neural network, for MNIST and Fashion-MNIST datasets. The number of training samples per image class goes from the extremely weak supervision condition (i.e., 1 labeled sample per class) to the strong supervision condition (i.e., 4096 labeled sample per class) with gradual transition in between (i.e., $2^n$, $n=0, 1, \cdots, 12$). Experimental results show that the two families of modularized learning systems have more robust performance than LeNet-5. They both outperform LeNet-5 by a large margin for small $n$ and have performance comparable with that of LeNet-5 for large $n$.
PAGER: Progressive Attribute-Guided Extendable Robust Image Generation
Jun 01, 2022
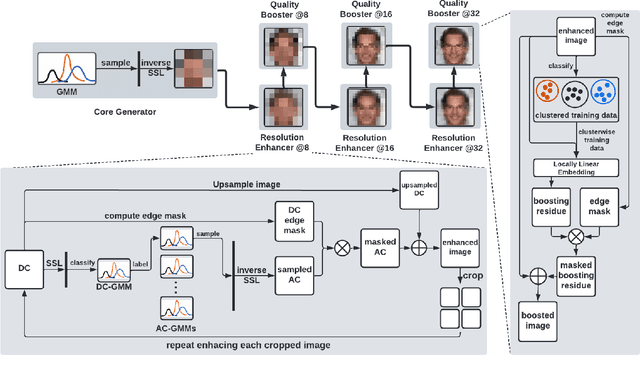

This work presents a generative modeling approach based on successive subspace learning (SSL). Unlike most generative models in the literature, our method does not utilize neural networks to analyze the underlying source distribution and synthesize images. The resulting method, called the progressive attribute-guided extendable robust image generative (PAGER) model, has advantages in mathematical transparency, progressive content generation, lower training time, robust performance with fewer training samples, and extendibility to conditional image generation. PAGER consists of three modules: core generator, resolution enhancer, and quality booster. The core generator learns the distribution of low-resolution images and performs unconditional image generation. The resolution enhancer increases image resolution via conditional generation. Finally, the quality booster adds finer details to generated images. Extensive experiments on MNIST, Fashion-MNIST, and CelebA datasets are conducted to demonstrate generative performance of PAGER.
Subspace Learning Machine (SLM): Methodology and Performance
May 11, 2022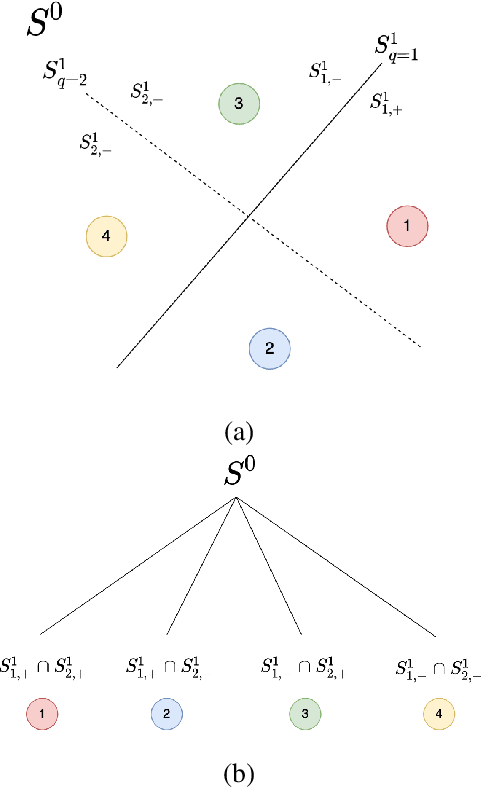
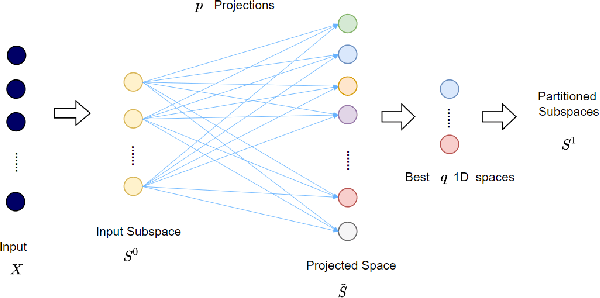
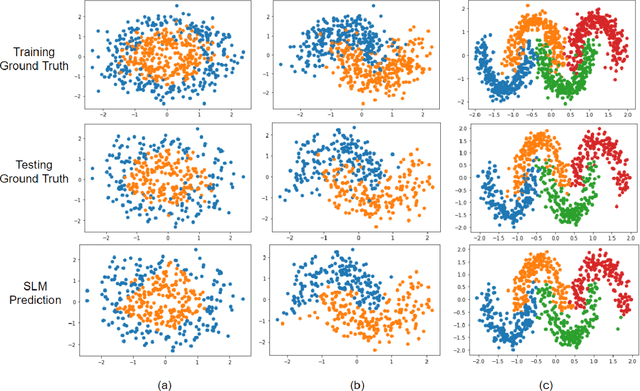
Inspired by the feedforward multilayer perceptron (FF-MLP), decision tree (DT) and extreme learning machine (ELM), a new classification model, called the subspace learning machine (SLM), is proposed in this work. SLM first identifies a discriminant subspace, $S^0$, by examining the discriminant power of each input feature. Then, it uses probabilistic projections of features in $S^0$ to yield 1D subspaces and finds the optimal partition for each of them. This is equivalent to partitioning $S^0$ with hyperplanes. A criterion is developed to choose the best $q$ partitions that yield $2q$ partitioned subspaces among them. We assign $S^0$ to the root node of a decision tree and the intersections of $2q$ subspaces to its child nodes of depth one. The partitioning process is recursively applied at each child node to build an SLM tree. When the samples at a child node are sufficiently pure, the partitioning process stops and each leaf node makes a prediction. The idea can be generalized to regression, leading to the subspace learning regressor (SLR). Furthermore, ensembles of SLM/SLR trees can yield a stronger predictor. Extensive experiments are conducted for performance benchmarking among SLM/SLR trees, ensembles and classical classifiers/regressors.