 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitorBench: A Comprehensive Benchmark for Chain-of-Thought Monitorability in Large Language Models
Apr 02, 2026Large language models (LLMs) can generate chains of thought (CoTs) that are not always causally responsible for their final outputs. When such a mismatch occurs, the CoT no longer faithfully reflects the actual reasons (i.e., decision-critical factors) driving the model's behavior, leading to the reduced CoT monitorability problem. However, a comprehensive and fully open-source benchmark for thoroughly evaluating CoT monitorability remains lacking. To address this gap, we propose MonitorBench, a systematic benchmark for evaluating CoT monitorability in LLMs. MonitorBench provides: (1) a diverse set of 1,514 test instances with carefully designed decision-critical factors across 19 tasks spanning 7 categories to characterize \textit{when} CoTs can be used to monitor the factors driving LLM behavior; and (2) two stress-test settings to quantify \textit{the extent to which} CoT monitorability can be degraded. Extensive experiments across multiple popular LLMs with varying capabilities show that CoT monitorability is higher when the decision-critical factors shape the intermediate reasoning process without merely influencing the final answer. More capable LLMs tend to exhibit lower monitorability. And all evaluated LLMs can intentionally reduce monitorability under stress-tests, with monitorability dropping by up to 30\% in some tasks that do not require structural reasoning over the decision-critical factors. Overall, MonitorBench provides a basis for further research on evaluating future LLMs, studying advanced stress-test monitorability techniques, and developing new monitoring approaches. The code is available at https://github.com/ASTRAL-Group/MonitorBench.
An insertable glucose sensor using a compact and cost-effective phosphorescence lifetime imager and machine learning
Jun 12, 2024Optical continuous glucose monitoring (CGM) systems are emerging for personalized glucose management owing to their lower cost and prolonged durability compared to conventional electrochemical CGMs. Here, we report a computational CGM system, which integrates a biocompatible phosphorescence-based insertable biosensor and a custom-designed phosphorescence lifetime imager (PLI). This compact and cost-effective PLI is designed to capture phosphorescence lifetime images of an insertable sensor through the skin, where the lifetime of the emitted phosphorescence signal is modulated by the local concentration of glucose. Because this phosphorescence signal has a very long lifetime compared to tissue autofluorescence or excitation leakage processes, it completely bypasses these noise sources by measuring the sensor emission over several tens of microseconds after the excitation light is turned off. The lifetime images acquired through the skin are processed by neural network-based models for misalignment-tolerant inference of glucose levels, accurately revealing normal, low (hypoglycemia) and high (hyperglycemia) concentration ranges. Using a 1-mm thick skin phantom mimicking the optical properties of human skin, we performed in vitro testing of the PLI using glucose-spiked samples, yielding 88.8% inference accuracy, also showing resilience to random and unknown misalignments within a lateral distance of ~4.7 mm with respect to the position of the insertable sensor underneath the skin phantom. Furthermore, the PLI accurately identified larger lateral misalignments beyond 5 mm, prompting user intervention for re-alignment. The misalignment-resilient glucose concentration inference capability of this compact and cost-effective phosphorescence lifetime imager makes it an appealing wearable diagnostics tool for real-time tracking of glucose and other biomarkers.
Beyond NDCG: behavioral testing of recommender systems with RecList
Nov 18, 2021
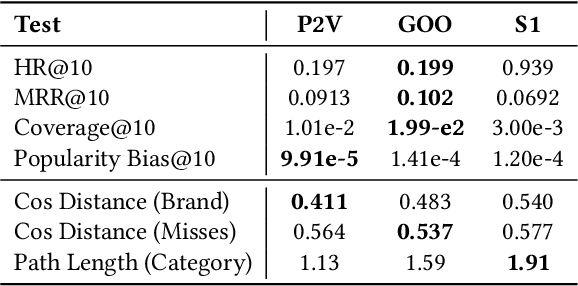
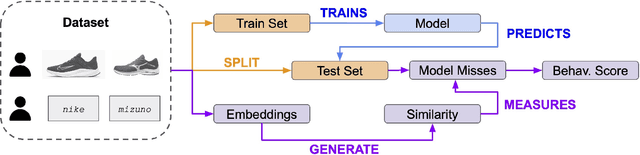
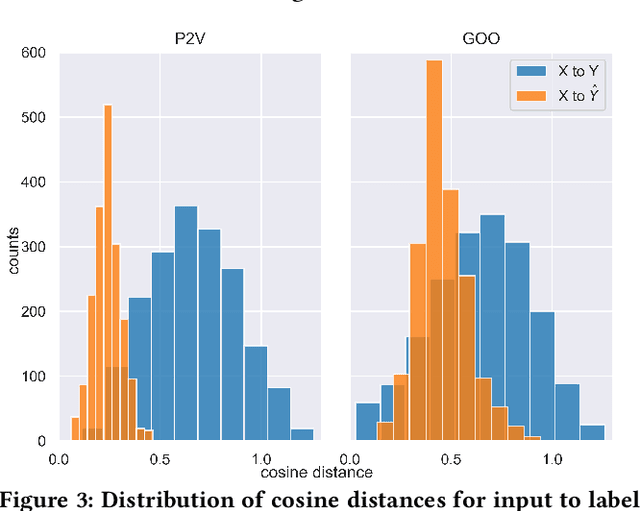
As with most Machine Learning systems, recommender systems are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced: ad hoc error analysis and deployment-specific tests must be employed to ensure the desired quality in actual deployments. In this paper, we propose RecList, a behavioral-based testing methodology. RecList organizes recommender systems by use case and introduces a general plug-and-play procedure to scale up behavioral testing. We demonstrate its capabilities by analyzing known algorithms and black-box commercial systems, and we release RecList as an open source, extensible package for the community.