 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyKey: Hyperspectral Keypoint Detection and Matching in Minimally Invasive Surgery
Apr 19, 2026Purpose: 3D reconstruction in minimally invasive surgery (MIS) enables enhanced surgical guidance through improved visualisation, tool tracking, and augmented reality. However, traditional RGB-based keypoint detection and matching pipelines struggle with surgical challenges, such as poor texture and complex illumination. We investigate whether using snapshot hyperspectral imaging (HSI) can provide improved results on keypoint detection and matching surgical scenes. Methods: We developed HyKey, a HYperspectral KEYpoint detection and description model made up of a hybrid 3D-2D convolutional neural network that jointly extracts spatial-spectral features from HSI. The model was trained using synthetic homographic augmentation and epipolar geometry constraints on a robotically-acquired dual-camera RGB-HSI laparoscopic dataset of ex-vivo organs with calibrated camera poses. We benchmarked performance against established RGB-based methods, including SuperPoint and ALIKE. Results: Our HSI-based model outperformed RGB baselines on registered RGB frames, achieving 96.62% mean matching accuracy and 67.18% mean average accuracy at 10 degree on pose estimation, demonstrating consistent improvements across multiple evaluation metrics. Conclusion: Integrating spectral information from an HSI cube offers a promising approach for robust monocular 3D reconstruction in MIS, addressing limitations of texture-poor surgical environments through enhanced spectral-spatial feature discrimination. Our model and dataset are available at https://github.com/alexsaikia/HyKey-Hyperspectral-Keypoint-Detection
Robotic Arm Platform for Multi-View Image Acquisition and 3D Reconstruction in Minimally Invasive Surgery
Oct 15, 2024Minimally invasive surgery (MIS) offers significant benefits such as reduced recovery time and minimised patient trauma, but poses challenges in visibility and access, making accurate 3D reconstruction a significant tool in surgical planning and navigation. This work introduces a robotic arm platform for efficient multi-view image acquisition and precise 3D reconstruction in MIS settings. We adapted a laparoscope to a robotic arm and captured ex-vivo images of several ovine organs across varying lighting conditions (operating room and laparoscopic) and trajectories (spherical and laparoscopic). We employed recently released learning-based feature matchers combined with COLMAP to produce our reconstructions. The reconstructions were evaluated against high-precision laser scans for quantitative evaluation. Our results show that whilst reconstructions suffer most under realistic MIS lighting and trajectory, many versions of our pipeline achieve close to sub-millimetre accuracy with an average of 1.05 mm Root Mean Squared Error and 0.82 mm Chamfer distance. Our best reconstruction results occur with operating room lighting and spherical trajectories. Our robotic platform provides a tool for controlled, repeatable multi-view data acquisition for 3D generation in MIS environments which we hope leads to new datasets for training learning-based models.
Classifying Autism from Crowdsourced Semi-Structured Speech Recordings: A Machine Learning Approach
Jan 04, 2022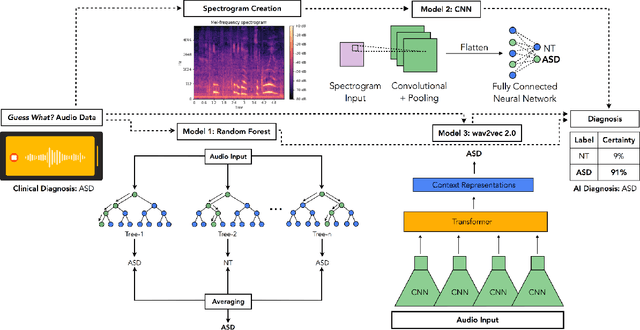

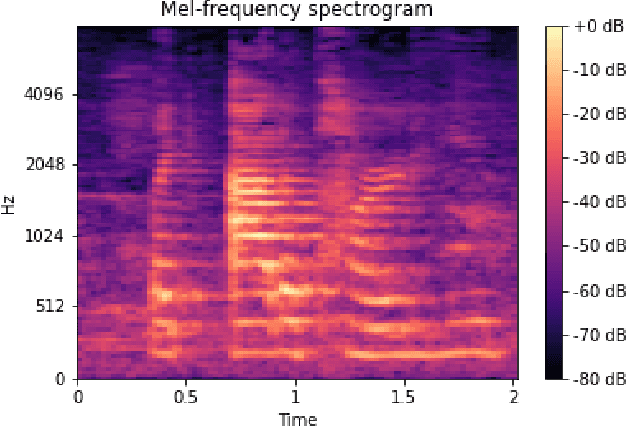
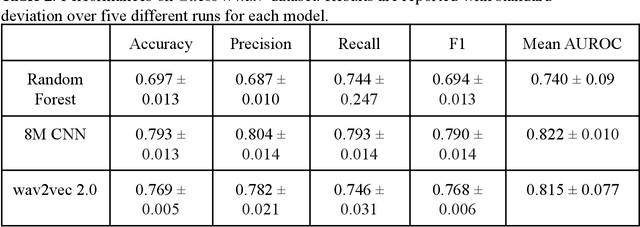
Autism spectrum disorder (ASD) is a neurodevelopmental disorder which results in altered behavior, social development, and communication patterns. In past years, autism prevalence has tripled, with 1 in 54 children now affected. Given that traditional diagnosis is a lengthy, labor-intensive process, significant attention has been given to developing systems that automatically screen for autism. Prosody abnormalities are among the clearest signs of autism, with affected children displaying speech idiosyncrasies including echolalia, monotonous intonation, atypical pitch, and irregular linguistic stress patterns. In this work, we present a suite of machine learning approaches to detect autism in self-recorded speech audio captured from autistic and neurotypical (NT) children in home environments. We consider three methods to detect autism in child speech: first, Random Forests trained on extracted audio features (including Mel-frequency cepstral coefficients); second, convolutional neural networks (CNNs) trained on spectrograms; and third, fine-tuned wav2vec 2.0--a state-of-the-art Transformer-based ASR model. We train our classifiers on our novel dataset of cellphone-recorded child speech audio curated from Stanford's Guess What? mobile game, an app designed to crowdsource videos of autistic and neurotypical children in a natural home environment. The Random Forest classifier achieves 70% accuracy, the fine-tuned wav2vec 2.0 model achieves 77% accuracy, and the CNN achieves 79% accuracy when classifying children's audio as either ASD or NT. Our models were able to predict autism status when training on a varied selection of home audio clips with inconsistent recording quality, which may be more generalizable to real world conditions. These results demonstrate that machine learning methods offer promise in detecting autism automatically from speech without specialized equipment.
Beyond NDCG: behavioral testing of recommender systems with RecList
Nov 18, 2021
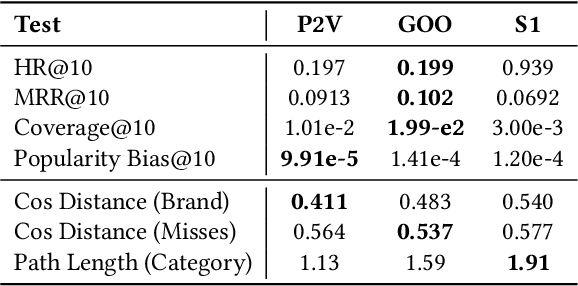
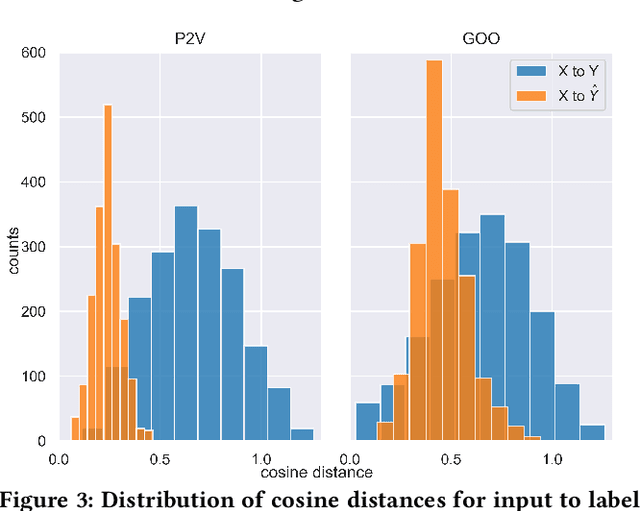
As with most Machine Learning systems, recommender systems are typically evaluated through performance metrics computed over held-out data points. However, real-world behavior is undoubtedly nuanced: ad hoc error analysis and deployment-specific tests must be employed to ensure the desired quality in actual deployments. In this paper, we propose RecList, a behavioral-based testing methodology. RecList organizes recommender systems by use case and introduces a general plug-and-play procedure to scale up behavioral testing. We demonstrate its capabilities by analyzing known algorithms and black-box commercial systems, and we release RecList as an open source, extensible package for the community.