 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation based meta-learning for few-shot spoken intent recognition
Jun 29, 2021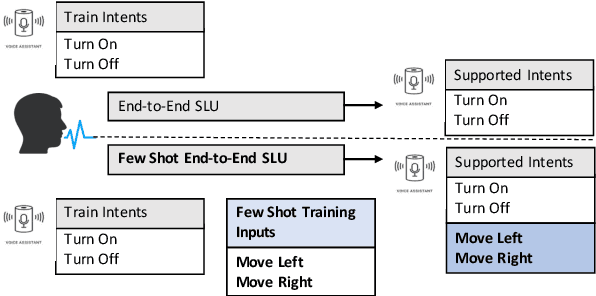
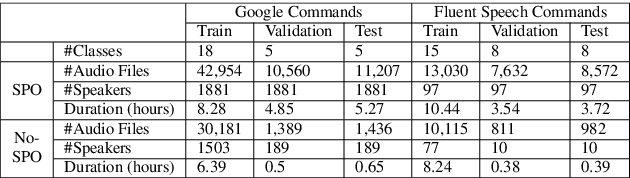
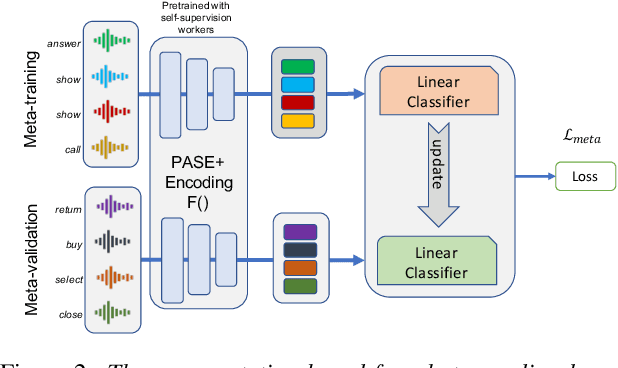
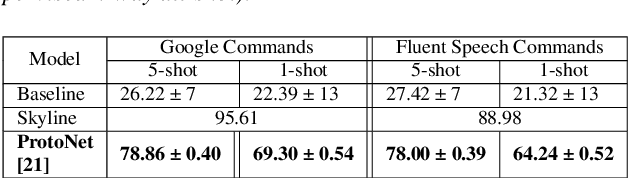
Spoken intent detection has become a popular approach to interface with various smart devices with ease. However, such systems are limited to the preset list of intents-terms or commands, which restricts the quick customization of personal devices to new intents. This paper presents a few-shot spoken intent classification approach with task-agnostic representations via meta-learning paradigm. Specifically, we leverage the popular representation-based meta-learning learning to build a task-agnostic representation of utterances, that then use a linear classifier for prediction. We evaluate three such approaches on our novel experimental protocol developed on two popular spoken intent classification datasets: Google Commands and the Fluent Speech Commands dataset. For a 5-shot (1-shot) classification of novel classes, the proposed framework provides an average classification accuracy of 88.6% (76.3%) on the Google Commands dataset, and 78.5% (64.2%) on the Fluent Speech Commands dataset. The performance is comparable to traditionally supervised classification models with abundant training samples.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021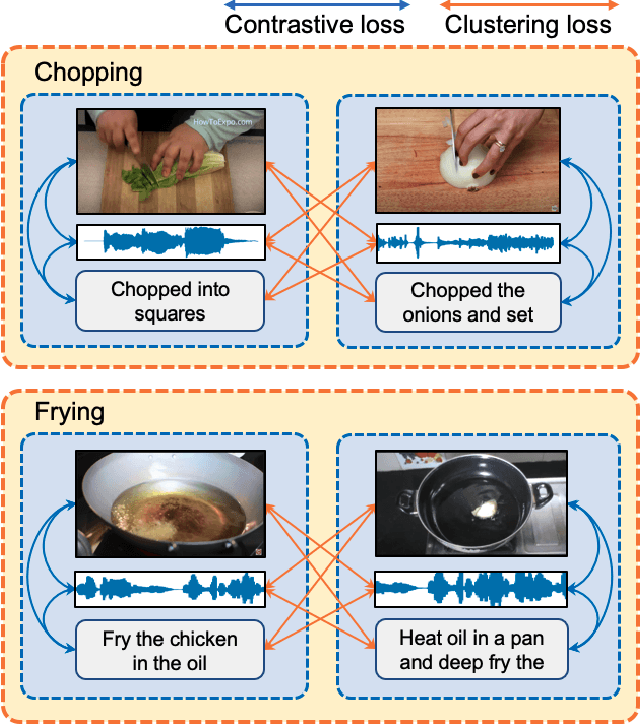
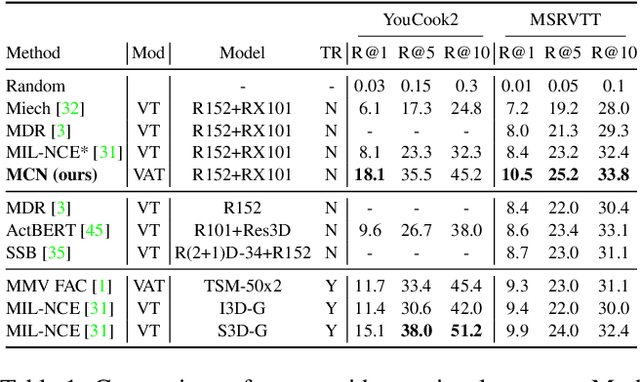
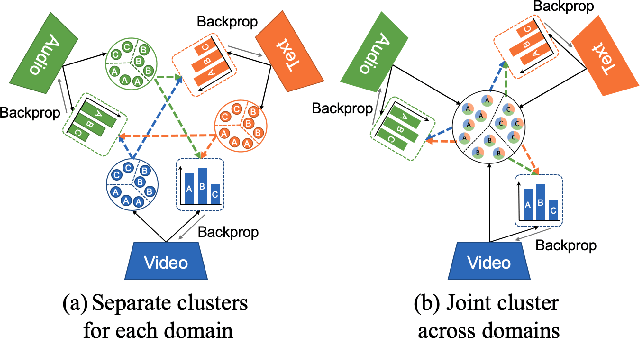
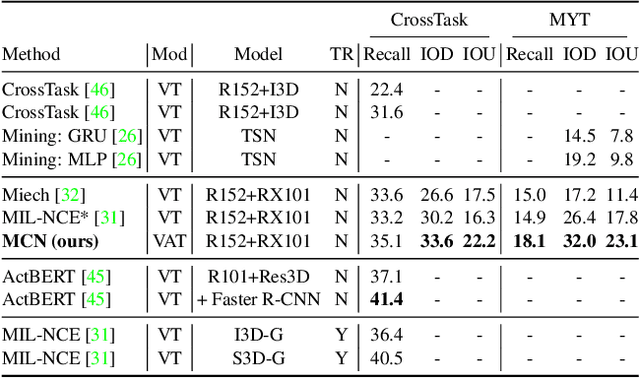
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
On the limit of English conversational speech recognition
May 03, 2021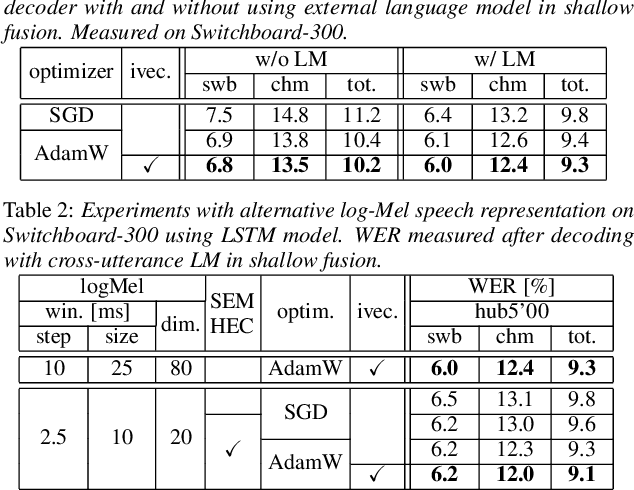
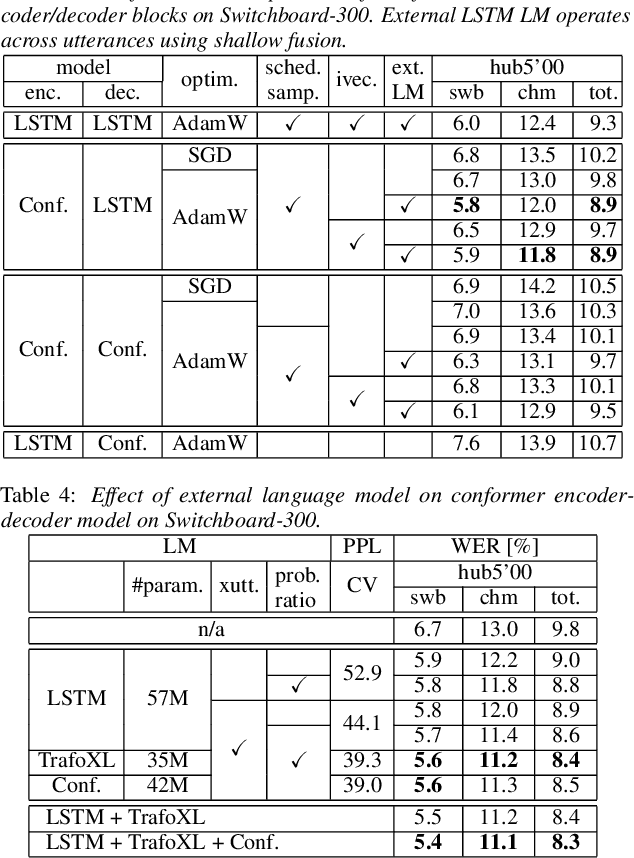
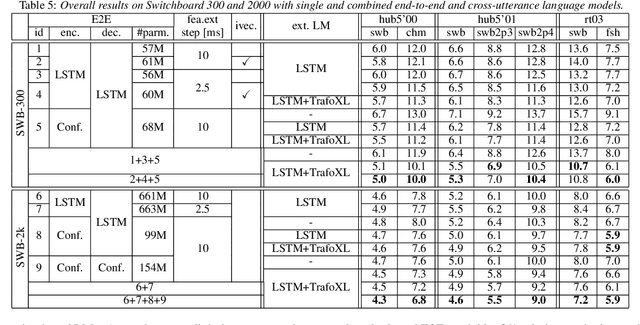
In our previous work we demonstrated that a single headed attention encoder-decoder model is able to reach state-of-the-art results in conversational speech recognition. In this paper, we further improve the results for both Switchboard 300 and 2000. Through use of an improved optimizer, speaker vector embeddings, and alternative speech representations we reduce the recognition errors of our LSTM system on Switchboard-300 by 4% relative. Compensation of the decoder model with the probability ratio approach allows more efficient integration of an external language model, and we report 5.9% and 11.5% WER on the SWB and CHM parts of Hub5'00 with very simple LSTM models. Our study also considers the recently proposed conformer, and more advanced self-attention based language models. Overall, the conformer shows similar performance to the LSTM; nevertheless, their combination and decoding with an improved LM reaches a new record on Switchboard-300, 5.0% and 10.0% WER on SWB and CHM. Our findings are also confirmed on Switchboard-2000, and a new state of the art is reported, practically reaching the limit of the benchmark.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
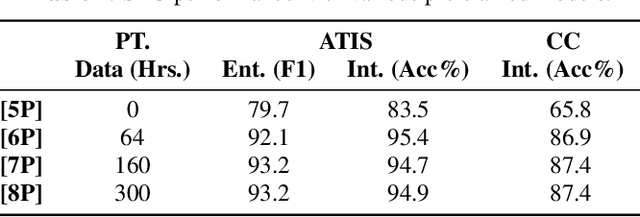


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
Advancing RNN Transducer Technology for Speech Recognition
Mar 17, 2021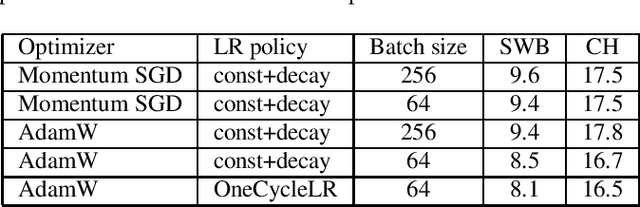
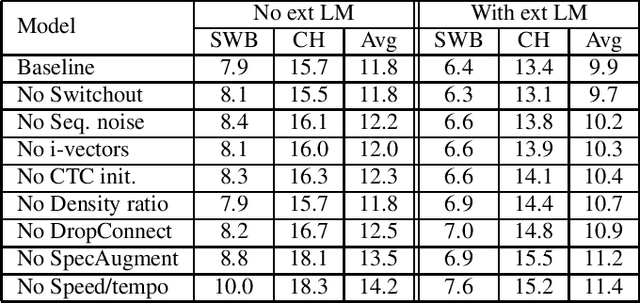
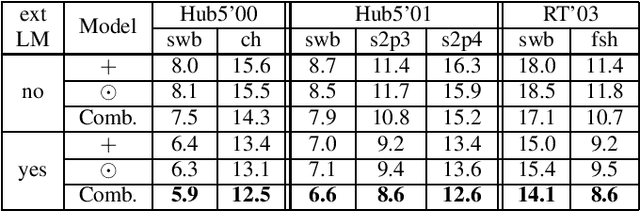
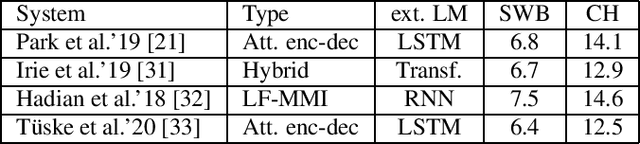
We investigate a set of techniques for RNN Transducers (RNN-Ts) that were instrumental in lowering the word error rate on three different tasks (Switchboard 300 hours, conversational Spanish 780 hours and conversational Italian 900 hours). The techniques pertain to architectural changes, speaker adaptation, language model fusion, model combination and general training recipe. First, we introduce a novel multiplicative integration of the encoder and prediction network vectors in the joint network (as opposed to additive). Second, we discuss the applicability of i-vector speaker adaptation to RNN-Ts in conjunction with data perturbation. Third, we explore the effectiveness of the recently proposed density ratio language model fusion for these tasks. Last but not least, we describe the other components of our training recipe and their effect on recognition performance. We report a 5.9% and 12.5% word error rate on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation and a 12.7% WER on the Mozilla CommonVoice Italian test set.
Federated Acoustic Modeling For Automatic Speech Recognition
Feb 08, 2021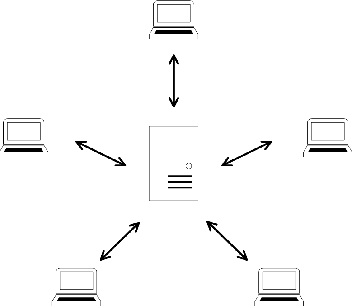


Data privacy and protection is a crucial issue for any automatic speech recognition (ASR) service provider when dealing with clients. In this paper, we investigate federated acoustic modeling using data from multiple clients. A client's data is stored on a local data server and the clients communicate only model parameters with a central server, and not their data. The communication happens infrequently to reduce the communication cost. To mitigate the non-iid issue, client adaptive federated training (CAFT) is proposed to canonicalize data across clients. The experiments are carried out on 1,150 hours of speech data from multiple domains. Hybrid LSTM acoustic models are trained via federated learning and their performance is compared to traditional centralized acoustic model training. The experimental results demonstrate the effectiveness of the proposed federated acoustic modeling strategy. We also show that CAFT can further improve the performance of the federated acoustic model.
End-to-end spoken language understanding using transformer networks and self-supervised pre-trained features
Nov 16, 2020
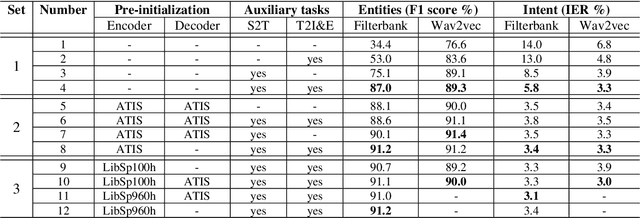


Transformer networks and self-supervised pre-training have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of spoken language understanding (SLU) still need further investigation. In this paper we introduce a modular End-to-End (E2E) SLU transformer network based architecture which allows the use of self-supervised pre-trained acoustic features, pre-trained model initialization and multi-task training. Several SLU experiments for predicting intent and entity labels/values using the ATIS dataset are performed. These experiments investigate the interaction of pre-trained model initialization and multi-task training with either traditional filterbank or self-supervised pre-trained acoustic features. Results show not only that self-supervised pre-trained acoustic features outperform filterbank features in almost all the experiments, but also that when these features are used in combination with multi-task training, they almost eliminate the necessity of pre-trained model initialization.
Leveraging Unpaired Text Data for Training End-to-End Speech-to-Intent Systems
Oct 08, 2020

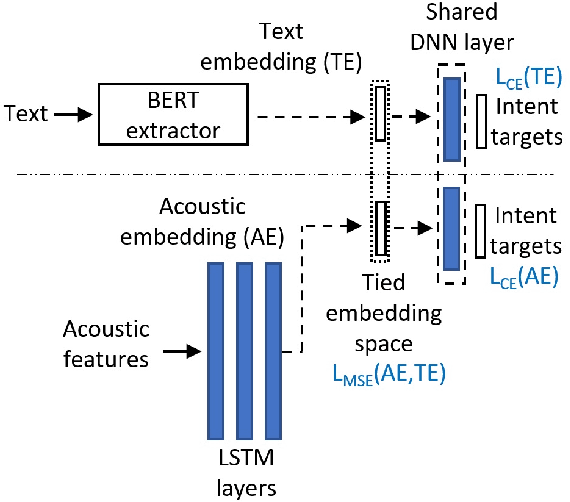
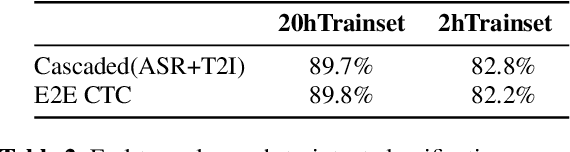
Training an end-to-end (E2E) neural network speech-to-intent (S2I) system that directly extracts intents from speech requires large amounts of intent-labeled speech data, which is time consuming and expensive to collect. Initializing the S2I model with an ASR model trained on copious speech data can alleviate data sparsity. In this paper, we attempt to leverage NLU text resources. We implemented a CTC-based S2I system that matches the performance of a state-of-the-art, traditional cascaded SLU system. We performed controlled experiments with varying amounts of speech and text training data. When only a tenth of the original data is available, intent classification accuracy degrades by 7.6% absolute. Assuming we have additional text-to-intent data (without speech) available, we investigated two techniques to improve the S2I system: (1) transfer learning, in which acoustic embeddings for intent classification are tied to fine-tuned BERT text embeddings; and (2) data augmentation, in which the text-to-intent data is converted into speech-to-intent data using a multi-speaker text-to-speech system. The proposed approaches recover 80% of performance lost due to using limited intent-labeled speech.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020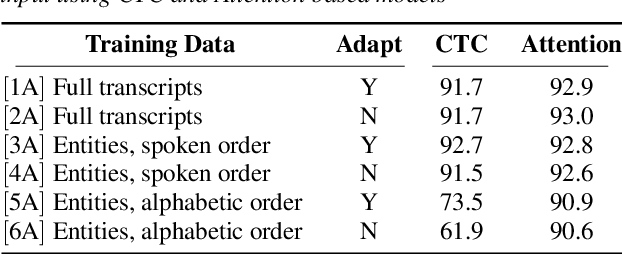
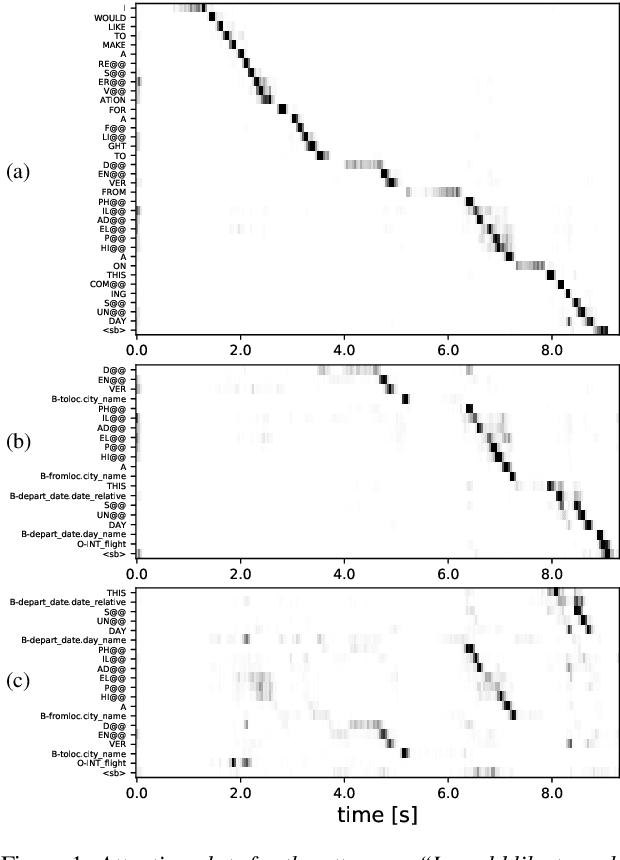

An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.
AVLnet: Learning Audio-Visual Language Representations from Instructional Videos
Jun 16, 2020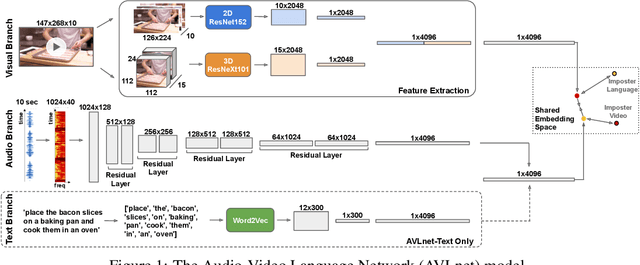
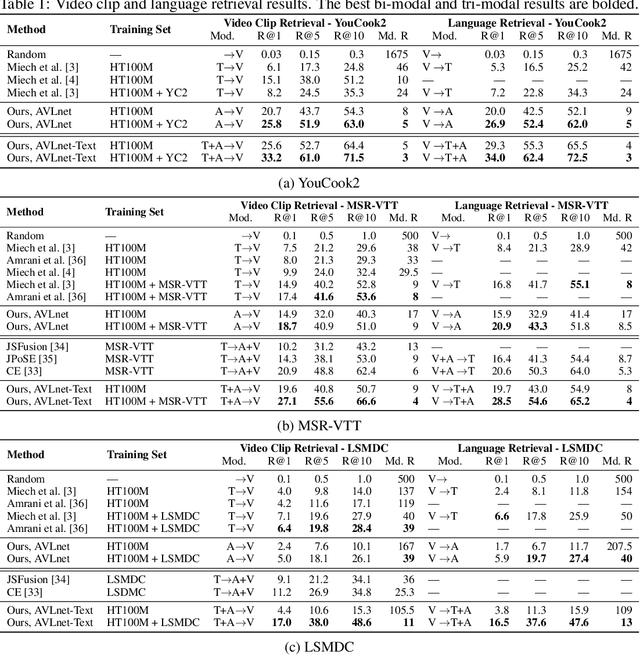
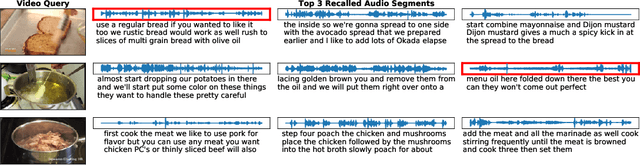
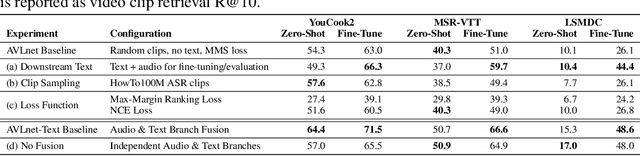
Current methods for learning visually grounded language from videos often rely on time-consuming and expensive data collection, such as human annotated textual summaries or machine generated automatic speech recognition transcripts. In this work, we introduce Audio-Video Language Network (AVLnet), a self-supervised network that learns a shared audio-visual embedding space directly from raw video inputs. We circumvent the need for annotation and instead learn audio-visual language representations directly from randomly segmented video clips and their raw audio waveforms. We train AVLnet on publicly available instructional videos and evaluate our model on video clip and language retrieval tasks on three video datasets. Our proposed model outperforms several state-of-the-art text-video baselines by up to 11.8% in a video clip retrieval task, despite operating on the raw audio instead of manually annotated text captions. Further, we show AVLnet is capable of integrating textual information, increasing its modularity and improving performance by up to 20.3% on the video clip retrieval task. Finally, we perform analysis of AVLnet's learned representations, showing our model has learned to relate visual objects with salient words and natural sounds.