 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-guided Prioritized Planning for Lifelong Multi-Agent Path Finding in Warehouse Automation
Mar 25, 2026Lifelong Multi-Agent Path Finding (MAPF) is critical for modern warehouse automation, which requires multiple robots to continuously navigate conflict-free paths to optimize the overall system throughput. However, the complexity of warehouse environments and the long-term dynamics of lifelong MAPF often demand costly adaptations to classical search-based solvers. While machine learning methods have been explored, their superiority over search-based methods remains inconclusive. In this paper, we introduce Reinforcement Learning (RL) guided Rolling Horizon Prioritized Planning (RL-RH-PP), the first framework integrating RL with search-based planning for lifelong MAPF. Specifically, we leverage classical Prioritized Planning (PP) as a backbone for its simplicity and flexibility in integrating with a learning-based priority assignment policy. By formulating dynamic priority assignment as a Partially Observable Markov Decision Process (POMDP), RL-RH-PP exploits the sequential decision-making nature of lifelong planning while delegating complex spatial-temporal interactions among agents to reinforcement learning. An attention-based neural network autoregressively decodes priority orders on-the-fly, enabling efficient sequential single-agent planning by the PP planner. Evaluations in realistic warehouse simulations show that RL-RH-PP achieves the highest total throughput among baselines and generalizes effectively across agent densities, planning horizons, and warehouse layouts. Our interpretive analyses reveal that RL-RH-PP proactively prioritizes congested agents and strategically redirects agents from congestion, easing traffic flow and boosting throughput. These findings highlight the potential of learning-guided approaches to augment traditional heuristics in modern warehouse automation.
The Logical Options Framework
Feb 24, 2021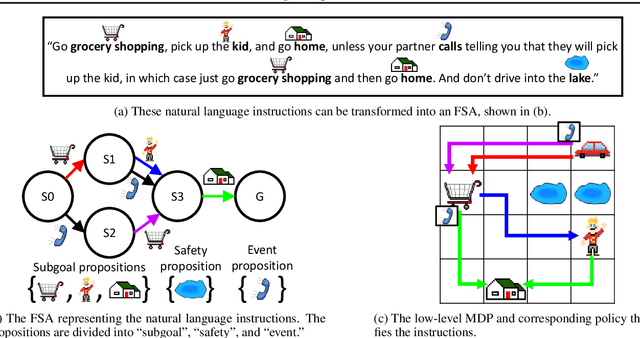
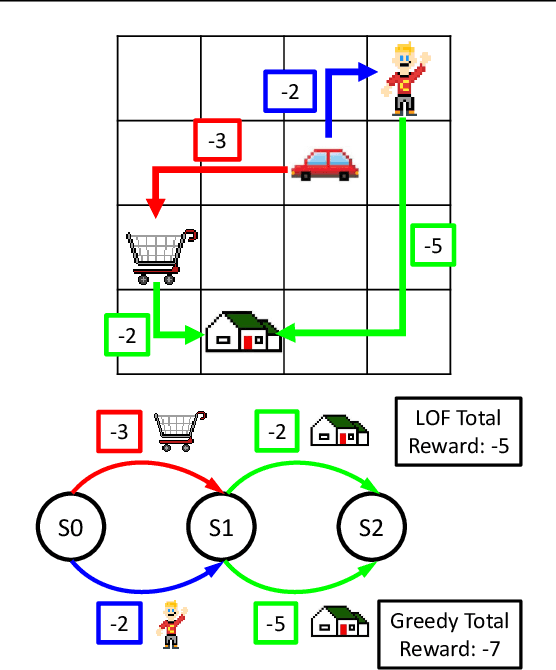
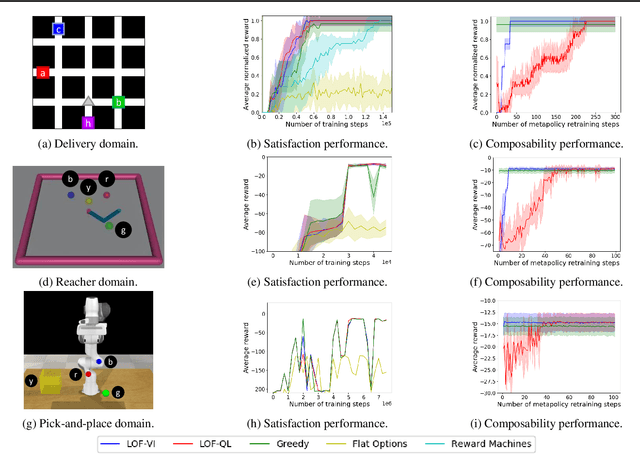
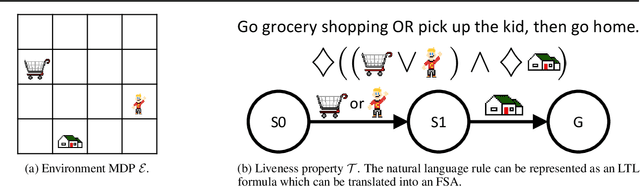
Learning composable policies for environments with complex rules and tasks is a challenging problem. We introduce a hierarchical reinforcement learning framework called the Logical Options Framework (LOF) that learns policies that are satisfying, optimal, and composable. LOF efficiently learns policies that satisfy tasks by representing the task as an automaton and integrating it into learning and planning. We provide and prove conditions under which LOF will learn satisfying, optimal policies. And lastly, we show how LOF's learned policies can be composed to satisfy unseen tasks with only 10-50 retraining steps. We evaluate LOF on four tasks in discrete and continuous domains, including a 3D pick-and-place environment.
Functional Co-Optimization of Articulated Robots
Jul 20, 2017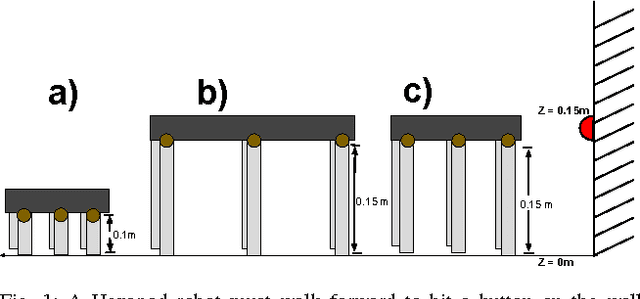
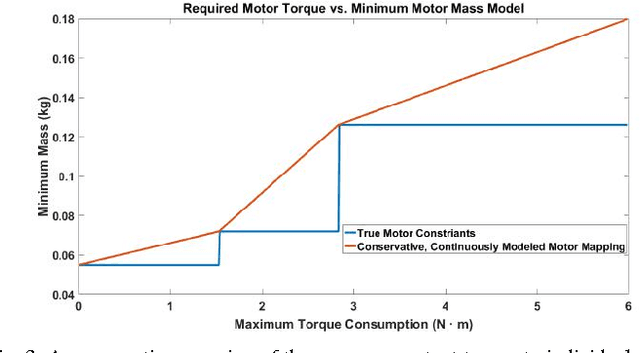
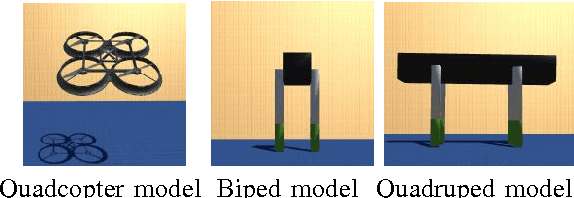
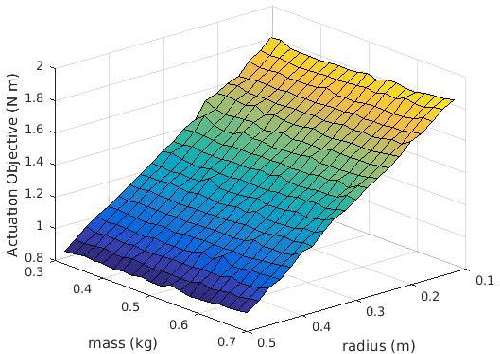
We present parametric trajectory optimization, a method for simultaneously computing physical parameters, actuation requirements, and robot motions for more efficient robot designs. In this scheme, robot dimensions, masses, and other physical parameters are solved for concurrently with traditional motion planning variables, including dynamically consistent robot states, actuation inputs, and contact forces. Our method requires minimal user domain knowledge, requiring only a coarse guess of the target robot configuration sequence and a parameterized robot topology as input. We demonstrate our results on four simulated robots, one of which we physically fabricated in order to demonstrate physical consistency. We demonstrate that by optimizing robot body parameters alongside robot trajectories, motion planning problems which would otherwise be infeasible can be made feasible, and actuation requirements can be significantly reduced.