 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriSTI: A Conditional Diffusion Framework for Spatiotemporal Imputation
Feb 20, 2023



Spatiotemporal data mining plays an important role in air quality monitoring, crowd flow modeling, and climate forecasting. However, the originally collected spatiotemporal data in real-world scenarios is usually incomplete due to sensor failures or transmission loss. Spatiotemporal imputation aims to fill the missing values according to the observed values and the underlying spatiotemporal dependence of them. The previous dominant models impute missing values autoregressively and suffer from the problem of error accumulation. As emerging powerful generative models, the diffusion probabilistic models can be adopted to impute missing values conditioned by observations and avoid inferring missing values from inaccurate historical imputation. However, the construction and utilization of conditional information are inevitable challenges when applying diffusion models to spatiotemporal imputation. To address above issues, we propose a conditional diffusion framework for spatiotemporal imputation with enhanced prior modeling, named PriSTI. Our proposed framework provides a conditional feature extraction module first to extract the coarse yet effective spatiotemporal dependencies from conditional information as the global context prior. Then, a noise estimation module transforms random noise to realistic values, with the spatiotemporal attention weights calculated by the conditional feature, as well as the consideration of geographic relationships. PriSTI outperforms existing imputation methods in various missing patterns of different real-world spatiotemporal data, and effectively handles scenarios such as high missing rates and sensor failure. The implementation code is available at https://github.com/LMZZML/PriSTI.
Conditional Diffusion Based on Discrete Graph Structures for Molecular Graph Generation
Jan 01, 2023



Learning the underlying distribution of molecular graphs and generating high-fidelity samples is a fundamental research problem in drug discovery and material science. However, accurately modeling distribution and rapidly generating novel molecular graphs remain crucial and challenging goals. To accomplish these goals, we propose a novel Conditional Diffusion model based on discrete Graph Structures (CDGS) for molecular graph generation. Specifically, we construct a forward graph diffusion process on both graph structures and inherent features through stochastic differential equations (SDE) and derive discrete graph structures as the condition for reverse generative processes. We present a specialized hybrid graph noise prediction model that extracts the global context and the local node-edge dependency from intermediate graph states. We further utilize ordinary differential equation (ODE) solvers for efficient graph sampling, based on the semi-linear structure of the probability flow ODE. Experiments on diverse datasets validate the effectiveness of our framework. Particularly, the proposed method still generates high-quality molecular graphs in a limited number of steps.
GraphGDP: Generative Diffusion Processes for Permutation Invariant Graph Generation
Dec 04, 2022



Graph generative models have broad applications in biology, chemistry and social science. However, modelling and understanding the generative process of graphs is challenging due to the discrete and high-dimensional nature of graphs, as well as permutation invariance to node orderings in underlying graph distributions. Current leading autoregressive models fail to capture the permutation invariance nature of graphs for the reliance on generation ordering and have high time complexity. Here, we propose a continuous-time generative diffusion process for permutation invariant graph generation to mitigate these issues. Specifically, we first construct a forward diffusion process defined by a stochastic differential equation (SDE), which smoothly converts graphs within the complex distribution to random graphs that follow a known edge probability. Solving the corresponding reverse-time SDE, graphs can be generated from newly sampled random graphs. To facilitate the reverse-time SDE, we newly design a position-enhanced graph score network, capturing the evolving structure and position information from perturbed graphs for permutation equivariant score estimation. Under the evaluation of comprehensive metrics, our proposed generative diffusion process achieves competitive performance in graph distribution learning. Experimental results also show that GraphGDP can generate high-quality graphs in only 24 function evaluations, much faster than previous autoregressive models.
Fleet Rebalancing for Expanding Shared e-Mobility Systems: A Multi-agent Deep Reinforcement Learning Approach
Nov 11, 2022



The electrification of shared mobility has become popular across the globe. Many cities have their new shared e-mobility systems deployed, with continuously expanding coverage from central areas to the city edges. A key challenge in the operation of these systems is fleet rebalancing, i.e., how EVs should be repositioned to better satisfy future demand. This is particularly challenging in the context of expanding systems, because i) the range of the EVs is limited while charging time is typically long, which constrain the viable rebalancing operations; and ii) the EV stations in the system are dynamically changing, i.e., the legitimate targets for rebalancing operations can vary over time. We tackle these challenges by first investigating rich sets of data collected from a real-world shared e-mobility system for one year, analyzing the operation model, usage patterns and expansion dynamics of this new mobility mode. With the learned knowledge we design a high-fidelity simulator, which is able to abstract key operation details of EV sharing at fine granularity. Then we model the rebalancing task for shared e-mobility systems under continuous expansion as a Multi-Agent Reinforcement Learning (MARL) problem, which directly takes the range and charging properties of the EVs into account. We further propose a novel policy optimization approach with action cascading, which is able to cope with the expansion dynamics and solve the formulated MARL. We evaluate the proposed approach extensively, and experimental results show that our approach outperforms the state-of-the-art, offering significant performance gain in both satisfied demand and net revenue.
Automated Urban Planning aware Spatial Hierarchies and Human Instructions
Sep 26, 2022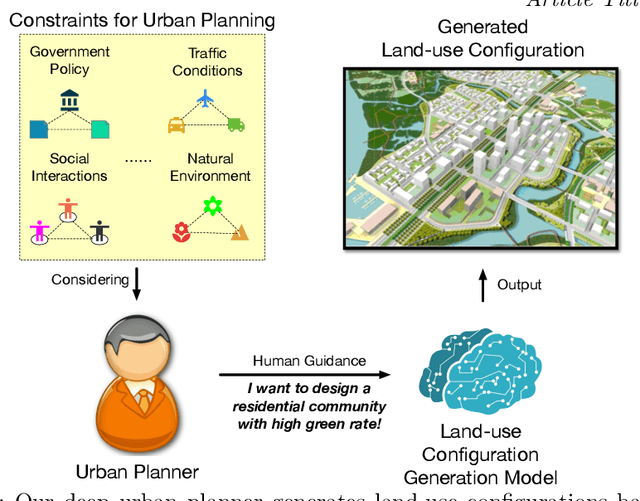
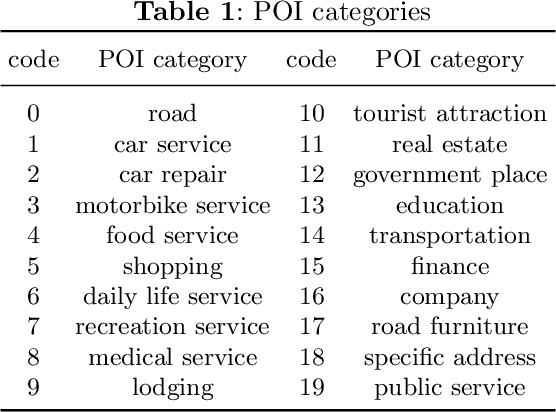
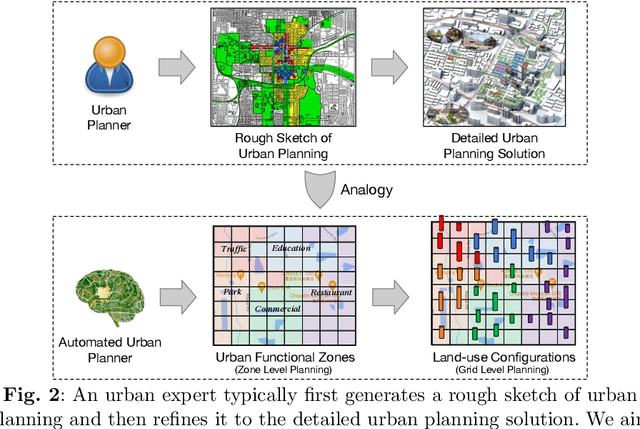
Traditional urban planning demands urban experts to spend considerable time and effort producing an optimal urban plan under many architectural constraints. The remarkable imaginative ability of deep generative learning provides hope for renovating urban planning. While automated urban planners have been examined, they are constrained because of the following: 1) neglecting human requirements in urban planning; 2) omitting spatial hierarchies in urban planning, and 3) lacking numerous urban plan data samples. To overcome these limitations, we propose a novel, deep, human-instructed urban planner. In the preliminary work, we formulate it into an encoder-decoder paradigm. The encoder is to learn the information distribution of surrounding contexts, human instructions, and land-use configuration. The decoder is to reconstruct the land-use configuration and the associated urban functional zones. The reconstruction procedure will capture the spatial hierarchies between functional zones and spatial grids. Meanwhile, we introduce a variational Gaussian mechanism to mitigate the data sparsity issue. Even though early work has led to good results, the performance of generation is still unstable because the way spatial hierarchies are captured may lead to unclear optimization directions. In this journal version, we propose a cascading deep generative framework based on generative adversarial networks (GANs) to solve this problem, inspired by the workflow of urban experts. In particular, the purpose of the first GAN is to build urban functional zones based on information from human instructions and surrounding contexts. The second GAN will produce the land-use configuration based on the functional zones that have been constructed. Additionally, we provide a conditioning augmentation module to augment data samples. Finally, we conduct extensive experiments to validate the efficacy of our work.
Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction
Jun 30, 2022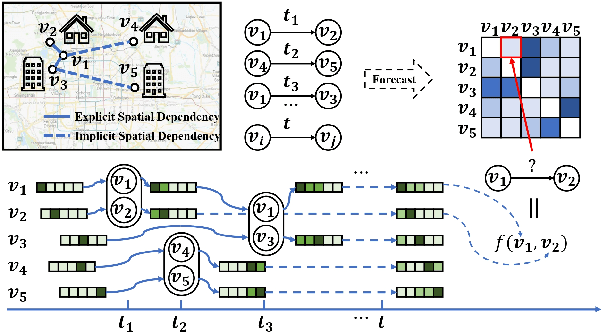
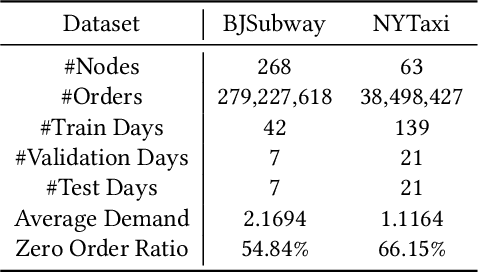
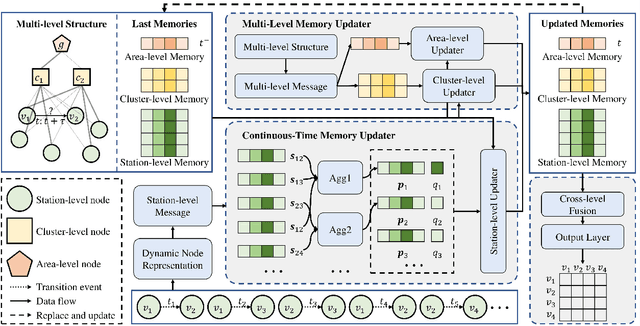
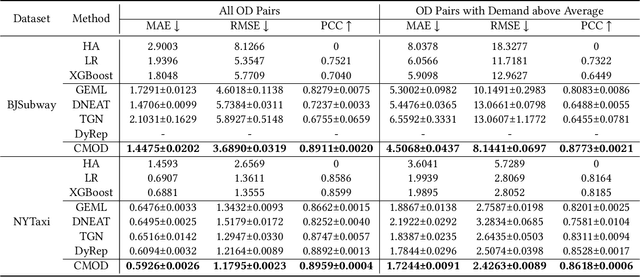
Traffic demand forecasting by deep neural networks has attracted widespread interest in both academia and industry society. Among them, the pairwise Origin-Destination (OD) demand prediction is a valuable but challenging problem due to several factors: (i) the large number of possible OD pairs, (ii) implicitness of spatial dependence, and (iii) complexity of traffic states. To address the above issues, this paper proposes a Continuous-time and Multi-level dynamic graph representation learning method for Origin-Destination demand prediction (CMOD). Firstly, a continuous-time dynamic graph representation learning framework is constructed, which maintains a dynamic state vector for each traffic node (metro stations or taxi zones). The state vectors keep historical transaction information and are continuously updated according to the most recently happened transactions. Secondly, a multi-level structure learning module is proposed to model the spatial dependency of station-level nodes. It can not only exploit relations between nodes adaptively from data, but also share messages and representations via cluster-level and area-level virtual nodes. Lastly, a cross-level fusion module is designed to integrate multi-level memories and generate comprehensive node representations for the final prediction. Extensive experiments are conducted on two real-world datasets from Beijing Subway and New York Taxi, and the results demonstrate the superiority of our model against the state-of-the-art approaches.
Learning the Evolutionary and Multi-scale Graph Structure for Multivariate Time Series Forecasting
Jun 28, 2022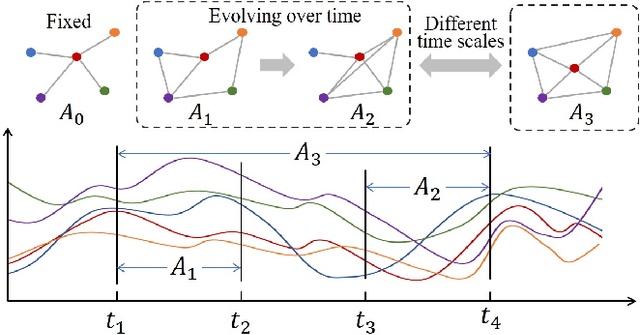

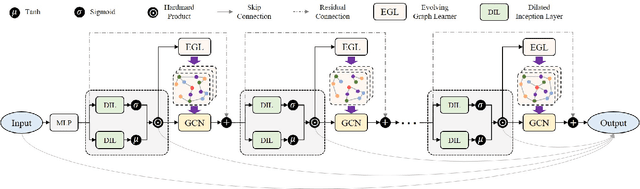
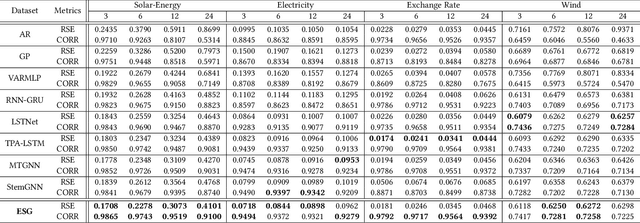
Recent studies have shown great promise in applying graph neural networks for multivariate time series forecasting, where the interactions of time series are described as a graph structure and the variables are represented as the graph nodes. Along this line, existing methods usually assume that the graph structure (or the adjacency matrix), which determines the aggregation manner of graph neural network, is fixed either by definition or self-learning. However, the interactions of variables can be dynamic and evolutionary in real-world scenarios. Furthermore, the interactions of time series are quite different if they are observed at different time scales. To equip the graph neural network with a flexible and practical graph structure, in this paper, we investigate how to model the evolutionary and multi-scale interactions of time series. In particular, we first provide a hierarchical graph structure cooperated with the dilated convolution to capture the scale-specific correlations among time series. Then, a series of adjacency matrices are constructed under a recurrent manner to represent the evolving correlations at each layer. Moreover, a unified neural network is provided to integrate the components above to get the final prediction. In this way, we can capture the pair-wise correlations and temporal dependency simultaneously. Finally, experiments on both single-step and multi-step forecasting tasks demonstrate the superiority of our method over the state-of-the-art approaches.
Label-Enhanced Graph Neural Network for Semi-supervised Node Classification
May 31, 2022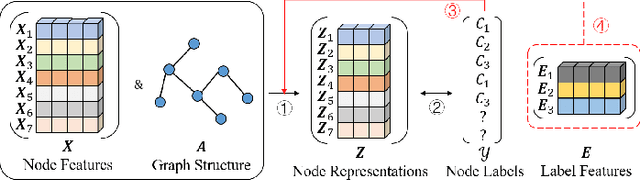

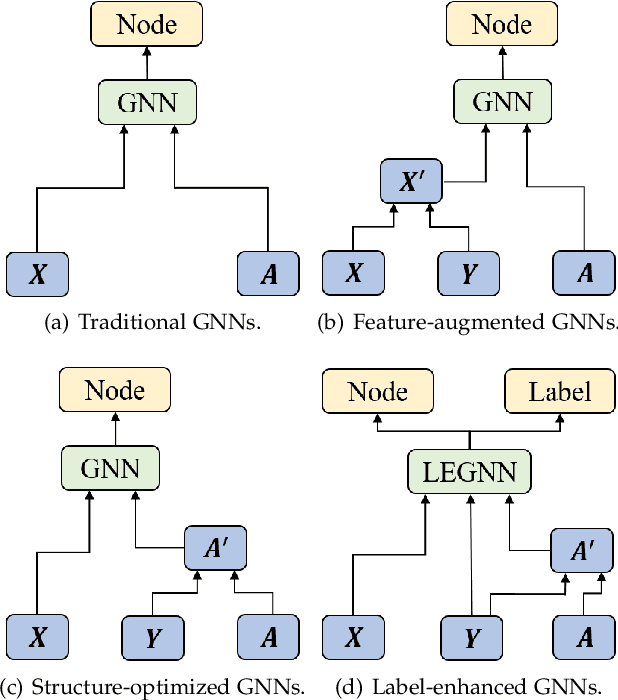
Graph Neural Networks (GNNs) have been widely applied in the semi-supervised node classification task, where a key point lies in how to sufficiently leverage the limited but valuable label information. Most of the classical GNNs solely use the known labels for computing the classification loss at the output. In recent years, several methods have been designed to additionally utilize the labels at the input. One part of the methods augment the node features via concatenating or adding them with the one-hot encodings of labels, while other methods optimize the graph structure by assuming neighboring nodes tend to have the same label. To bring into full play the rich information of labels, in this paper, we present a label-enhanced learning framework for GNNs, which first models each label as a virtual center for intra-class nodes and then jointly learns the representations of both nodes and labels. Our approach could not only smooth the representations of nodes belonging to the same class, but also explicitly encode the label semantics into the learning process of GNNs. Moreover, a training node selection technique is provided to eliminate the potential label leakage issue and guarantee the model generalization ability. Finally, an adaptive self-training strategy is proposed to iteratively enlarge the training set with more reliable pseudo labels and distinguish the importance of each pseudo-labeled node during the model training process. Experimental results on both real-world and synthetic datasets demonstrate our approach can not only consistently outperform the state-of-the-arts, but also effectively smooth the representations of intra-class nodes.
Modelling Evolutionary and Stationary User Preferences for Temporal Sets Prediction
Apr 14, 2022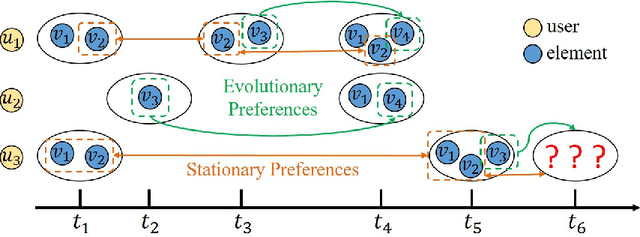

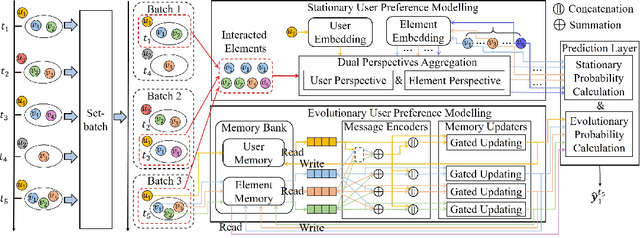

Given a sequence of sets, where each set is associated with a timestamp and contains an arbitrary number of elements, the task of temporal sets prediction aims to predict the elements in the subsequent set. Previous studies for temporal sets prediction mainly capture each user's evolutionary preference by learning from his/her own sequence. Although insightful, we argue that: 1) the collaborative signals latent in different users' sequences are essential but have not been exploited; 2) users also tend to show stationary preferences while existing methods fail to consider. To this end, we propose an integrated learning framework to model both the evolutionary and the stationary preferences of users for temporal sets prediction, which first constructs a universal sequence by chronologically arranging all the user-set interactions, and then learns on each user-set interaction. In particular, for each user-set interaction, we first design an evolutionary user preference modelling component to track the user's time-evolving preference and exploit the latent collaborative signals among different users. This component maintains a memory bank to store memories of the related user and elements, and continuously updates their memories based on the currently encoded messages and the past memories. Then, we devise a stationary user preference modelling module to discover each user's personalized characteristics according to the historical sequence, which adaptively aggregates the previously interacted elements from dual perspectives with the guidance of the user's and elements' embeddings. Finally, we develop a set-batch algorithm to improve the model efficiency, which can create time-consistent batches in advance and achieve 3.5x training speedups on average. Experiments on real-world datasets demonstrate the effectiveness and good interpretability of our approach.
Deployment Optimization for Shared e-Mobility Systems with Multi-agent Deep Neural Search
Nov 03, 2021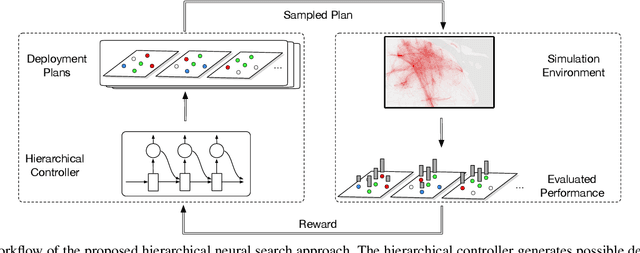
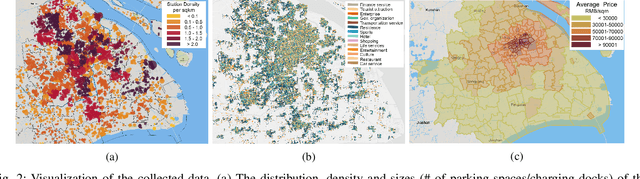
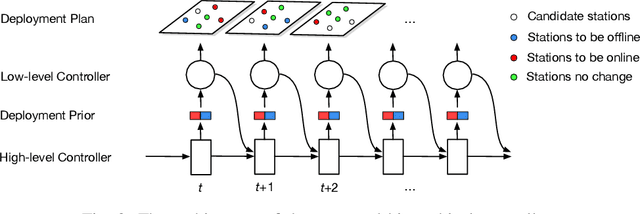
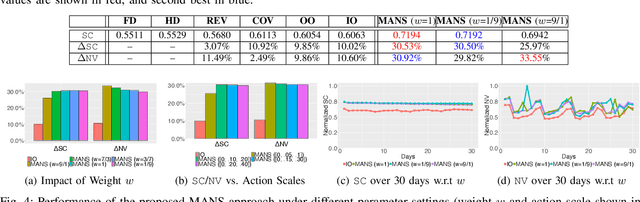
Shared e-mobility services have been widely tested and piloted in cities across the globe, and already woven into the fabric of modern urban planning. This paper studies a practical yet important problem in those systems: how to deploy and manage their infrastructure across space and time, so that the services are ubiquitous to the users while sustainable in profitability. However, in real-world systems evaluating the performance of different deployment strategies and then finding the optimal plan is prohibitively expensive, as it is often infeasible to conduct many iterations of trial-and-error. We tackle this by designing a high-fidelity simulation environment, which abstracts the key operation details of the shared e-mobility systems at fine-granularity, and is calibrated using data collected from the real-world. This allows us to try out arbitrary deployment plans to learn the optimal given specific context, before actually implementing any in the real-world systems. In particular, we propose a novel multi-agent neural search approach, in which we design a hierarchical controller to produce tentative deployment plans. The generated deployment plans are then tested using a multi-simulation paradigm, i.e., evaluated in parallel, where the results are used to train the controller with deep reinforcement learning. With this closed loop, the controller can be steered to have higher probability of generating better deployment plans in future iterations. The proposed approach has been evaluated extensively in our simulation environment, and experimental results show that it outperforms baselines e.g., human knowledge, and state-of-the-art heuristic-based optimization approaches in both service coverage and net revenue.