 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to be adversarially robust and differentially private
Jan 06, 2022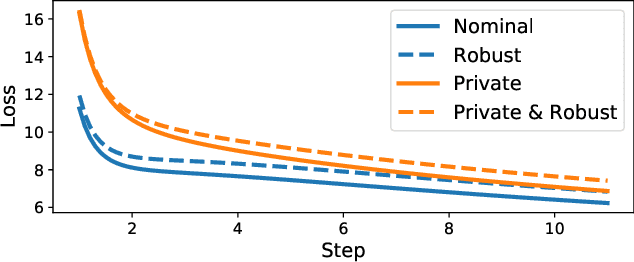

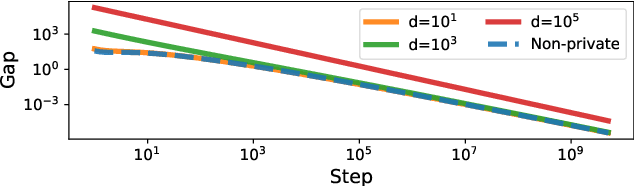
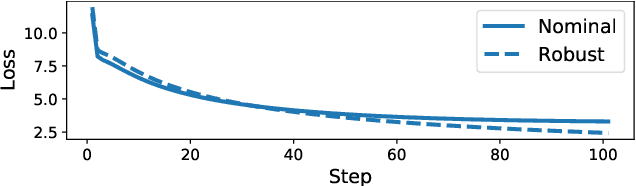
We study the difficulties in learning that arise from robust and differentially private optimization. We first study convergence of gradient descent based adversarial training with differential privacy, taking a simple binary classification task on linearly separable data as an illustrative example. We compare the gap between adversarial and nominal risk in both private and non-private settings, showing that the data dimensionality dependent term introduced by private optimization compounds the difficulties of learning a robust model. After this, we discuss what parts of adversarial training and differential privacy hurt optimization, identifying that the size of adversarial perturbation and clipping norm in differential privacy both increase the curvature of the loss landscape, implying poorer generalization performance.
Ethical and social risks of harm from Language Models
Dec 08, 2021
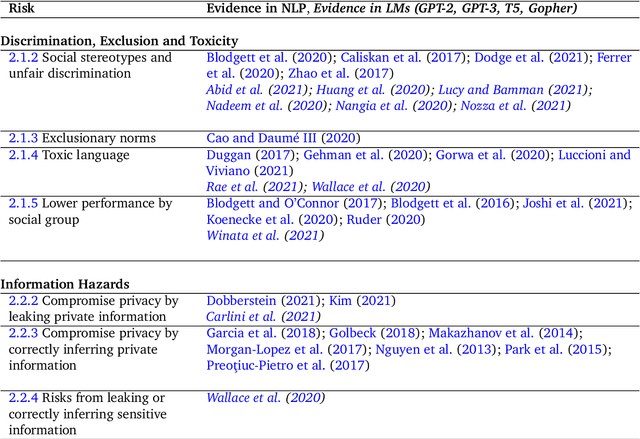
This paper aims to help structure the risk landscape associated with large-scale Language Models (LMs). In order to foster advances in responsible innovation, an in-depth understanding of the potential risks posed by these models is needed. A wide range of established and anticipated risks are analysed in detail, drawing on multidisciplinary expertise and literature from computer science, linguistics, and social sciences. We outline six specific risk areas: I. Discrimination, Exclusion and Toxicity, II. Information Hazards, III. Misinformation Harms, V. Malicious Uses, V. Human-Computer Interaction Harms, VI. Automation, Access, and Environmental Harms. The first area concerns the perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group for LMs. The second focuses on risks from private data leaks or LMs correctly inferring sensitive information. The third addresses risks arising from poor, false or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information. The fourth considers risks from actors who try to use LMs to cause harm. The fifth focuses on risks specific to LLMs used to underpin conversational agents that interact with human users, including unsafe use, manipulation or deception. The sixth discusses the risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities. In total, we review 21 risks in-depth. We discuss the points of origin of different risks and point to potential mitigation approaches. Lastly, we discuss organisational responsibilities in implementing mitigations, and the role of collaboration and participation. We highlight directions for further research, particularly on expanding the toolkit for assessing and evaluating the outlined risks in LMs.
A Law of Robustness for Weight-bounded Neural Networks
Mar 12, 2021Robustness of deep neural networks against adversarial perturbations is a pressing concern motivated by recent findings showing the pervasive nature of such vulnerabilities. One method of characterizing the robustness of a neural network model is through its Lipschitz constant, which forms a robustness certificate. A natural question to ask is, for a fixed model class (such as neural networks) and a dataset of size $n$, what is the smallest achievable Lipschitz constant among all models that fit the dataset? Recently, (Bubeck et al., 2020) conjectured that when using two-layer networks with $k$ neurons to fit a generic dataset, the smallest Lipschitz constant is $\Omega(\sqrt{\frac{n}{k}})$. This implies that one would require one neuron per data point to robustly fit the data. In this work we derive a lower bound on the Lipschitz constant for any arbitrary model class with bounded Rademacher complexity. Our result coincides with that conjectured in (Bubeck et al., 2020) for two-layer networks under the assumption of bounded weights. However, due to our result's generality, we also derive bounds for multi-layer neural networks, discovering that one requires $\log n$ constant-sized layers to robustly fit the data. Thus, our work establishes a law of robustness for weight bounded neural networks and provides formal evidence on the necessity of over-parametrization in deep learning.
Private Reinforcement Learning with PAC and Regret Guarantees
Sep 18, 2020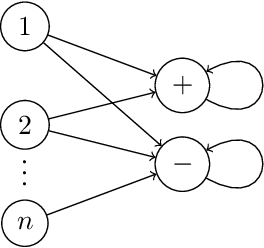
Motivated by high-stakes decision-making domains like personalized medicine where user information is inherently sensitive, we design privacy preserving exploration policies for episodic reinforcement learning (RL). We first provide a meaningful privacy formulation using the notion of joint differential privacy (JDP)--a strong variant of differential privacy for settings where each user receives their own sets of output (e.g., policy recommendations). We then develop a private optimism-based learning algorithm that simultaneously achieves strong PAC and regret bounds, and enjoys a JDP guarantee. Our algorithm only pays for a moderate privacy cost on exploration: in comparison to the non-private bounds, the privacy parameter only appears in lower-order terms. Finally, we present lower bounds on sample complexity and regret for reinforcement learning subject to JDP.
Privacy Amplification via Random Check-Ins
Jul 30, 2020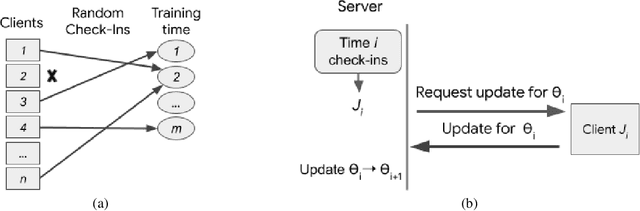

Differentially Private Stochastic Gradient Descent (DP-SGD) forms a fundamental building block in many applications for learning over sensitive data. Two standard approaches, privacy amplification by subsampling, and privacy amplification by shuffling, permit adding lower noise in DP-SGD than via na\"{\i}ve schemes. A key assumption in both these approaches is that the elements in the data set can be uniformly sampled, or be uniformly permuted -- constraints that may become prohibitive when the data is processed in a decentralized or distributed fashion. In this paper, we focus on conducting iterative methods like DP-SGD in the setting of federated learning (FL) wherein the data is distributed among many devices (clients). Our main contribution is the \emph{random check-in} distributed protocol, which crucially relies only on randomized participation decisions made locally and independently by each client. It has privacy/accuracy trade-offs similar to privacy amplification by subsampling/shuffling. However, our method does not require server-initiated communication, or even knowledge of the population size. To our knowledge, this is the first privacy amplification tailored for a distributed learning framework, and it may have broader applicability beyond FL. Along the way, we extend privacy amplification by shuffling to incorporate $(\epsilon,\delta)$-DP local randomizers, and exponentially improve its guarantees. In practical regimes, this improvement allows for similar privacy and utility using data from an order of magnitude fewer users.
Privacy- and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations
Oct 20, 2019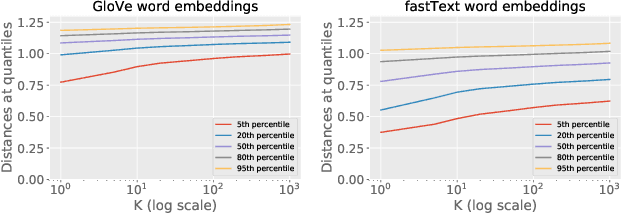
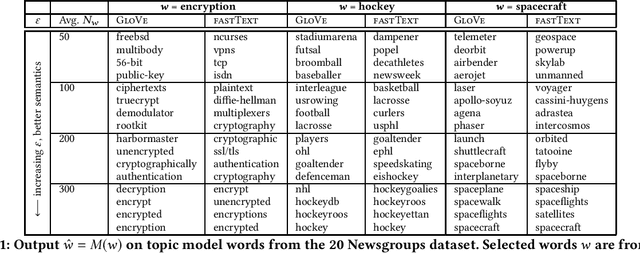

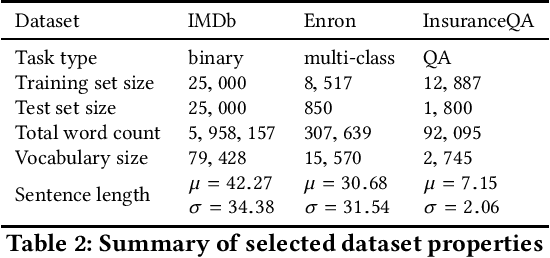
Accurately learning from user data while providing quantifiable privacy guarantees provides an opportunity to build better ML models while maintaining user trust. This paper presents a formal approach to carrying out privacy preserving text perturbation using the notion of dx-privacy designed to achieve geo-indistinguishability in location data. Our approach applies carefully calibrated noise to vector representation of words in a high dimension space as defined by word embedding models. We present a privacy proof that satisfies dx-privacy where the privacy parameter epsilon provides guarantees with respect to a distance metric defined by the word embedding space. We demonstrate how epsilon can be selected by analyzing plausible deniability statistics backed up by large scale analysis on GloVe and fastText embeddings. We conduct privacy audit experiments against 2 baseline models and utility experiments on 3 datasets to demonstrate the tradeoff between privacy and utility for varying values of epsilon on different task types. Our results demonstrate practical utility (< 2% utility loss for training binary classifiers) while providing better privacy guarantees than baseline models.
Actor Critic with Differentially Private Critic
Oct 14, 2019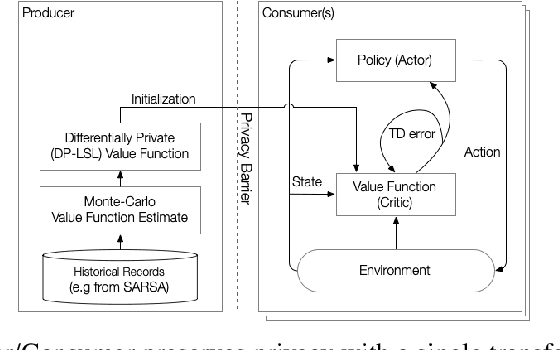
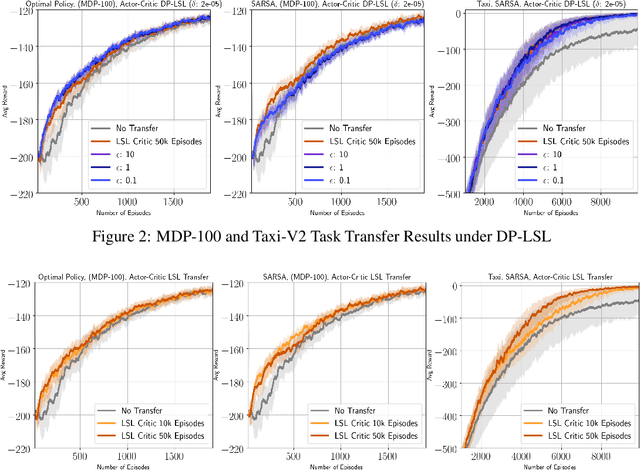
Reinforcement learning algorithms are known to be sample inefficient, and often performance on one task can be substantially improved by leveraging information (e.g., via pre-training) on other related tasks. In this work, we propose a technique to achieve such knowledge transfer in cases where agent trajectories contain sensitive or private information, such as in the healthcare domain. Our approach leverages a differentially private policy evaluation algorithm to initialize an actor-critic model and improve the effectiveness of learning in downstream tasks. We empirically show this technique increases sample efficiency in resource-constrained control problems while preserving the privacy of trajectories collected in an upstream task.
Differentially Private Summation with Multi-Message Shuffling
Jun 24, 2019In recent work, Cheu et al. (Eurocrypt 2019) proposed a protocol for $n$-party real summation in the shuffle model of differential privacy with $O_{\epsilon, \delta}(1)$ error and $\Theta(\epsilon\sqrt{n})$ one-bit messages per party. In contrast, every local model protocol for real summation must incur error $\Omega(1/\sqrt{n})$, and there exist protocols matching this lower bound which require just one bit of communication per party. Whether this gap in number of messages is necessary was left open by Cheu et al. In this note we show a protocol with $O(1/\epsilon)$ error and $O(\log(n/\delta))$ messages of size $O(\log(n))$ per party. This protocol is based on the work of Ishai et al.\ (FOCS 2006) showing how to implement distributed summation from secure shuffling, and the observation that this allows simulating the Laplace mechanism in the shuffle model.
Privacy Amplification by Mixing and Diffusion Mechanisms
May 29, 2019
A fundamental result in differential privacy states that the privacy guarantees of a mechanism are preserved by any post-processing of its output. In this paper we investigate under what conditions stochastic post-processing can amplify the privacy of a mechanism. By interpreting post-processing as the application of a Markov operator, we first give a series of amplification results in terms of uniform mixing properties of the Markov process defined by said operator. Next we provide amplification bounds in terms of coupling arguments which can be applied in cases where uniform mixing is not available. Finally, we introduce a new family of mechanisms based on diffusion processes which are closed under post-processing, and analyze their privacy via a novel heat flow argument. As applications, we show that the rate of "privacy amplification by iteration" in Noisy SGD introduced by Feldman et al. [FOCS'18] admits an exponential improvement in the strongly convex case, and propose a simple mechanism based on the Ornstein-Uhlenbeck process which has better mean squared error than the Gaussian mechanism when releasing a bounded function of the data.
Model-Agnostic Counterfactual Explanations for Consequential Decisions
May 28, 2019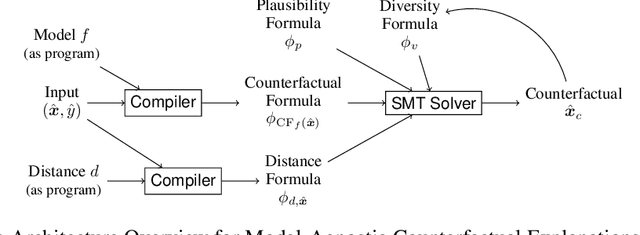



Predictive models are being increasingly used to support consequential decision making at the individual level in contexts such as pretrial bail and loan approval. As a result, there is increasing social and legal pressure to provide explanations that help the affected individuals not only to understand why a prediction was output, but also how to act to obtain a desired outcome. To this end, several works have proposed methods to generate counterfactual explanations. However, they are often restricted to a particular subset of models (e.g., decision trees or linear models), and cannot directly handle the mixed (numerical and nominal) nature of the features describing each individual. In this paper, we propose a model-agnostic algorithm to generate counterfactual explanations that builds on the standard theory and tools from formal verification. Specifically, our algorithm solves a sequence of satisfiability problems, where a wide variety of predictive models and distances in mixed feature spaces, as well as natural notions of plausibility and diversity, are represented as logic formulas. Our experiments on real-world data demonstrate that our approach can flexibly handle widely deployed predictive models, while providing meaningfully closer counterfactuals than existing approaches.