 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Study on the Accuracy vs Cost Trade-offs of Training and Evaluation Settings in Fine-Grained Image Recognition
May 18, 2026Prior work on fine-grained image recognition (FGIR) has established the importance of the backbone selection, but has neglected the accuracy-vs-cost trade-offs under different training and evaluation settings. In this work we conduct a large-scale study with over 2000 experiments across 6 training and evaluation settings, 9 pretrained backbones, and 17 datasets. Preliminary observations on the effectiveness of data augmentation for fine-grained training motivate us to extend Counterfactual Attention Learning (CAL), a state-of-the-art method based on data-aware cropping and masking augmentations, with cross-image discriminative region mixing augmentation. We also propose an efficient evaluation-only variant that maintains competitive accuracy while reducing inference costs by forfeiting the forward pass on discriminative crops that is normally used by CAL and similar FGIR methods. Our results show that data-aware augmentations during training only can enable a model to achieve excellent accuracy even without crops, significantly reducing inference costs. To support future research we share our code and checkpoints at: \url{https://github.com/arkel23/FGIR-Backbones}
Machine Learning on Heterogeneous, Edge, and Quantum Hardware for Particle Physics (ML-HEQUPP)
Feb 24, 2026The next generation of particle physics experiments will face a new era of challenges in data acquisition, due to unprecedented data rates and volumes along with extreme environments and operational constraints. Harnessing this data for scientific discovery demands real-time inference and decision-making, intelligent data reduction, and efficient processing architectures beyond current capabilities. Crucial to the success of this experimental paradigm are several emerging technologies, such as artificial intelligence and machine learning (AI/ML) and silicon microelectronics, and the advent of quantum algorithms and processing. Their intersection includes areas of research such as low-power and low-latency devices for edge computing, heterogeneous accelerator systems, reconfigurable hardware, novel codesign and synthesis strategies, readout for cryogenic or high-radiation environments, and analog computing. This white paper presents a community-driven vision to identify and prioritize research and development opportunities in hardware-based ML systems and corresponding physics applications, contributing towards a successful transition to the new data frontier of fundamental science.
Fine-Grained Image Recognition from Scratch with Teacher-Guided Data Augmentation
Jul 16, 2025Fine-grained image recognition (FGIR) aims to distinguish visually similar sub-categories within a broader class, such as identifying bird species. While most existing FGIR methods rely on backbones pretrained on large-scale datasets like ImageNet, this dependence limits adaptability to resource-constrained environments and hinders the development of task-specific architectures tailored to the unique challenges of FGIR. In this work, we challenge the conventional reliance on pretrained models by demonstrating that high-performance FGIR systems can be trained entirely from scratch. We introduce a novel training framework, TGDA, that integrates data-aware augmentation with weak supervision via a fine-grained-aware teacher model, implemented through knowledge distillation. This framework unlocks the design of task-specific and hardware-aware architectures, including LRNets for low-resolution FGIR and ViTFS, a family of Vision Transformers optimized for efficient inference. Extensive experiments across three FGIR benchmarks over diverse settings involving low-resolution and high-resolution inputs show that our method consistently matches or surpasses state-of-the-art pretrained counterparts. In particular, in the low-resolution setting, LRNets trained with TGDA improve accuracy by up to 23\% over prior methods while requiring up to 20.6x less parameters, lower FLOPs, and significantly less training data. Similarly, ViTFS-T can match the performance of a ViT B-16 pretrained on ImageNet-21k while using 15.3x fewer trainable parameters and requiring orders of magnitudes less data. These results highlight TGDA's potential as an adaptable alternative to pretraining, paving the way for more efficient fine-grained vision systems.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
Cross-Layer Cache Aggregation for Token Reduction in Ultra-Fine-Grained Image Recognition
Dec 31, 2024



Ultra-fine-grained image recognition (UFGIR) is a challenging task that involves classifying images within a macro-category. While traditional FGIR deals with classifying different species, UFGIR goes beyond by classifying sub-categories within a species such as cultivars of a plant. In recent times the usage of Vision Transformer-based backbones has allowed methods to obtain outstanding recognition performances in this task but this comes at a significant cost in terms of computation specially since this task significantly benefits from incorporating higher resolution images. Therefore, techniques such as token reduction have emerged to reduce the computational cost. However, dropping tokens leads to loss of essential information for fine-grained categories, specially as the token keep rate is reduced. Therefore, to counteract the loss of information brought by the usage of token reduction we propose a novel Cross-Layer Aggregation Classification Head and a Cross-Layer Cache mechanism to recover and access information from previous layers in later locations. Extensive experiments covering more than 2000 runs across diverse settings including 5 datasets, 9 backbones, 7 token reduction methods, 5 keep rates, and 2 image sizes demonstrate the effectiveness of the proposed plug-and-play modules and allow us to push the boundaries of accuracy vs cost for UFGIR by reducing the kept tokens to extremely low ratios of up to 10\% while maintaining a competitive accuracy to state-of-the-art models. Code is available at: \url{https://github.com/arkel23/CLCA}
Down-Sampling Inter-Layer Adapter for Parameter and Computation Efficient Ultra-Fine-Grained Image Recognition
Sep 17, 2024



Ultra-fine-grained image recognition (UFGIR) categorizes objects with extremely small differences between classes, such as distinguishing between cultivars within the same species, as opposed to species-level classification in fine-grained image recognition (FGIR). The difficulty of this task is exacerbated due to the scarcity of samples per category. To tackle these challenges we introduce a novel approach employing down-sampling inter-layer adapters in a parameter-efficient setting, where the backbone parameters are frozen and we only fine-tune a small set of additional modules. By integrating dual-branch down-sampling, we significantly reduce the number of parameters and floating-point operations (FLOPs) required, making our method highly efficient. Comprehensive experiments on ten datasets demonstrate that our approach obtains outstanding accuracy-cost performance, highlighting its potential for practical applications in resource-constrained environments. In particular, our method increases the average accuracy by at least 6.8\% compared to other methods in the parameter-efficient setting while requiring at least 123x less trainable parameters compared to current state-of-the-art UFGIR methods and reducing the FLOPs by 30\% in average compared to other methods.
Global-Local Similarity for Efficient Fine-Grained Image Recognition with Vision Transformers
Jul 17, 2024



Fine-grained recognition involves the classification of images from subordinate macro-categories, and it is challenging due to small inter-class differences. To overcome this, most methods perform discriminative feature selection enabled by a feature extraction backbone followed by a high-level feature refinement step. Recently, many studies have shown the potential behind vision transformers as a backbone for fine-grained recognition, but their usage of its attention mechanism to select discriminative tokens can be computationally expensive. In this work, we propose a novel and computationally inexpensive metric to identify discriminative regions in an image. We compare the similarity between the global representation of an image given by the CLS token, a learnable token used by transformers for classification, and the local representation of individual patches. We select the regions with the highest similarity to obtain crops, which are forwarded through the same transformer encoder. Finally, high-level features of the original and cropped representations are further refined together in order to make more robust predictions. Through extensive experimental evaluation we demonstrate the effectiveness of our proposed method, obtaining favorable results in terms of accuracy across a variety of datasets. Furthermore, our method achieves these results at a much lower computational cost compared to the alternatives. Code and checkpoints are available at: \url{https://github.com/arkel23/GLSim}.
FPGA Deployment of LFADS for Real-time Neuroscience Experiments
Feb 02, 2024



Large-scale recordings of neural activity are providing new opportunities to study neural population dynamics. A powerful method for analyzing such high-dimensional measurements is to deploy an algorithm to learn the low-dimensional latent dynamics. LFADS (Latent Factor Analysis via Dynamical Systems) is a deep learning method for inferring latent dynamics from high-dimensional neural spiking data recorded simultaneously in single trials. This method has shown a remarkable performance in modeling complex brain signals with an average inference latency in milliseconds. As our capacity of simultaneously recording many neurons is increasing exponentially, it is becoming crucial to build capacity for deploying low-latency inference of the computing algorithms. To improve the real-time processing ability of LFADS, we introduce an efficient implementation of the LFADS models onto Field Programmable Gate Arrays (FPGA). Our implementation shows an inference latency of 41.97 $\mu$s for processing the data in a single trial on a Xilinx U55C.
* 6 pages, 8 figures
Low Latency Edge Classification GNN for Particle Trajectory Tracking on FPGAs
Jun 27, 2023In-time particle trajectory reconstruction in the Large Hadron Collider is challenging due to the high collision rate and numerous particle hits. Using GNN (Graph Neural Network) on FPGA has enabled superior accuracy with flexible trajectory classification. However, existing GNN architectures have inefficient resource usage and insufficient parallelism for edge classification. This paper introduces a resource-efficient GNN architecture on FPGAs for low latency particle tracking. The modular architecture facilitates design scalability to support large graphs. Leveraging the geometric properties of hit detectors further reduces graph complexity and resource usage. Our results on Xilinx UltraScale+ VU9P demonstrate 1625x and 1574x performance improvement over CPU and GPU respectively.
Graph Neural Networks for Charged Particle Tracking on FPGAs
Dec 03, 2021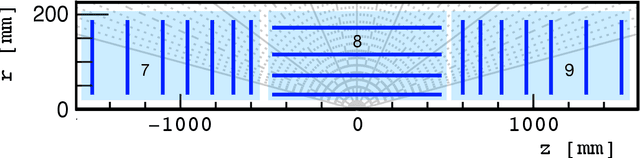

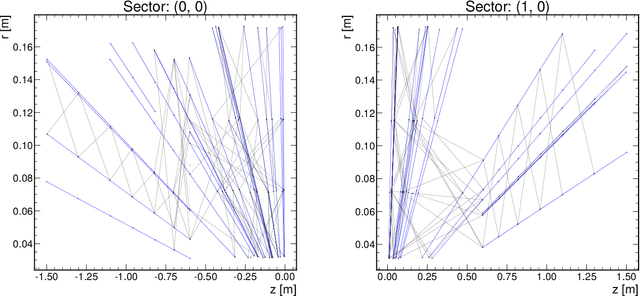
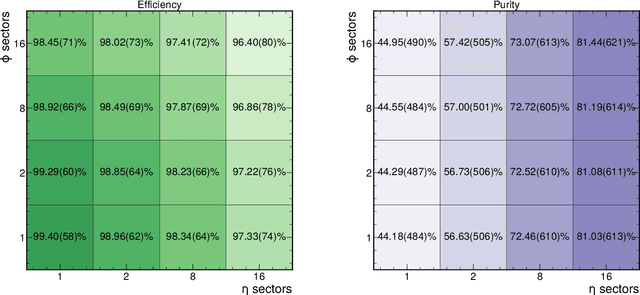
The determination of charged particle trajectories in collisions at the CERN Large Hadron Collider (LHC) is an important but challenging problem, especially in the high interaction density conditions expected during the future high-luminosity phase of the LHC (HL-LHC). Graph neural networks (GNNs) are a type of geometric deep learning algorithm that has successfully been applied to this task by embedding tracker data as a graph -- nodes represent hits, while edges represent possible track segments -- and classifying the edges as true or fake track segments. However, their study in hardware- or software-based trigger applications has been limited due to their large computational cost. In this paper, we introduce an automated translation workflow, integrated into a broader tool called $\texttt{hls4ml}$, for converting GNNs into firmware for field-programmable gate arrays (FPGAs). We use this translation tool to implement GNNs for charged particle tracking, trained using the TrackML challenge dataset, on FPGAs with designs targeting different graph sizes, task complexites, and latency/throughput requirements. This work could enable the inclusion of charged particle tracking GNNs at the trigger level for HL-LHC experiments.