 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeaveLA: Event Driven Cross-Subtask Latent Memory Weaving for Repetitive Robot Manipulation
Jun 16, 2026Vision-Language-Action (VLA) policies have achieved remarkable single-step manipulation, yet they remain brittle precisely where each stage depends on what was just completed. The core issue is structural: short-window VLAs lack an explicit channel for rouxting information across sub-task boundaries, and existing memory-augmented variants either write at every frame, retrieve from demonstration-time stages, or fire at sub-goal events without performing an explicit sub-task-to-sub-task hand-off into the action expert. We identify the sub-goal completion event as the natural temporal unit for cross-subtask memory hand-off, and present WeaveLA (Weave Latent memory for Vision-Language-Action policies), a cross-subtask memory interface that, on top of a frozen VLA backbone, compresses each completed segment into latent tokens via query-driven attention pooling and routes them directly into the action-generation path of the next sub-task. This event-triggered, action-side design preserves the base policy's short-window interface while adding a lightweight cross-subtask channel. Through stratified evaluation on RoboMME with a $π_{0.5}$ backbone, WeaveLA's gains land exactly where the channel is needed: on the hardest repetition slice (SwingXtimes, $N{=}3$), success rises from $0\%$ to $47.8\%$, while single-execution episodes remain unchanged. Per-episode paired analysis confirms the gains are confined to tasks whose causal structure requires cross-subtask information.
From Reaction to Anticipation: Proactive Failure Recovery through Agentic Task Graph for Robotic Manipulation
May 12, 2026Although robotic manipulation has made significant progress, reliable execution remains challenging because task failures are inevitable in dynamic and unstructured environments. To handle such failures, existing frameworks typically follow a stepwise detect-reason-recover pipeline, which often incurs high latency and limited robustness due to delayed reasoning and reactive planning. Inspired by the human capability to anticipate and proactively plan for potential failures, we introduce AgentChord, an agentic system that models a manipulation task as a directed task graph. Before execution, this graph is enriched with anticipatory recovery branches that specify context-aware corrective behaviors, enabling immediate and targeted responses when failures occur. Specifically, AgentChord operates through a choreography of specialized agents: a composer that structures the nominal task graph, an arranger that augments the graph with anticipatory recovery branches, and a conductor that compiles and coordinates executable transitions using low-latency monitors to detect deviations and trigger pre-compiled recoveries without re-planning. Empirical studies on diverse long-horizon bimanual manipulation tasks demonstrate that AgentChord substantially improves success rates and execution efficiency, advancing the reliability and autonomy of real-world robotic systems. The project page is available at: https://shengxu.net/AgentChord/.
Grounding Sim-to-Real Generalization in Dexterous Manipulation: An Empirical Study with Vision-Language-Action Models
Mar 24, 2026Learning a generalist control policy for dexterous manipulation typically relies on large-scale datasets. Given the high cost of real-world data collection, a practical alternative is to generate synthetic data through simulation. However, the resulting synthetic data often exhibits a significant gap from real-world distributions. While many prior studies have proposed algorithms to bridge the Sim-to-Real discrepancy, there remains a lack of principled research that grounds these methods in real-world manipulation tasks, particularly their performance on generalist policies such as Vision-Language-Action (VLA) models. In this study, we empirically examine the primary determinants of Sim-to-Real generalization across four dimensions: multi-level domain randomization, photorealistic rendering, physics-realistic modeling, and reinforcement learning updates. To support this study, we design a comprehensive evaluation protocol to quantify the real-world performance of manipulation tasks. The protocol accounts for key variations in background, lighting, distractors, object types, and spatial features. Through experiments involving over 10k real-world trials, we derive critical insights into Sim-to-Real transfer. To inform and advance future studies, we release both the robotic platforms and the evaluation protocol for public access to facilitate independent verification, thereby establishing a realistic and standardized benchmark for dexterous manipulation policies.
Toward Humanoid Brain-Body Co-design: Joint Optimization of Control and Morphology for Fall Recovery
Oct 25, 2025Humanoid robots represent a central frontier in embodied intelligence, as their anthropomorphic form enables natural deployment in humans' workspace. Brain-body co-design for humanoids presents a promising approach to realizing this potential by jointly optimizing control policies and physical morphology. Within this context, fall recovery emerges as a critical capability. It not only enhances safety and resilience but also integrates naturally with locomotion systems, thereby advancing the autonomy of humanoids. In this paper, we propose RoboCraft, a scalable humanoid co-design framework for fall recovery that iteratively improves performance through the coupled updates of control policy and morphology. A shared policy pretrained across multiple designs is progressively finetuned on high-performing morphologies, enabling efficient adaptation without retraining from scratch. Concurrently, morphology search is guided by human-inspired priors and optimization algorithms, supported by a priority buffer that balances reevaluation of promising candidates with the exploration of novel designs. Experiments show that \ourmethod{} achieves an average performance gain of 44.55% on seven public humanoid robots, with morphology optimization drives at least 40% of improvements in co-designing four humanoid robots, underscoring the critical role of humanoid co-design.
Real-Time Verification of Embodied Reasoning for Generative Skill Acquisition
May 19, 2025Generative skill acquisition enables embodied agents to actively learn a scalable and evolving repertoire of control skills, crucial for the advancement of large decision models. While prior approaches often rely on supervision signals from generalist agents (e.g., LLMs), their effectiveness in complex 3D environments remains unclear; exhaustive evaluation incurs substantial computational costs, significantly hindering the efficiency of skill learning. Inspired by recent successes in verification models for mathematical reasoning, we propose VERGSA (Verifying Embodied Reasoning in Generative Skill Acquisition), a framework that systematically integrates real-time verification principles into embodied skill learning. VERGSA establishes 1) a seamless extension from verification of mathematical reasoning into embodied learning by dynamically incorporating contextually relevant tasks into prompts and defining success metrics for both subtasks and overall tasks, and 2) an automated, scalable reward labeling scheme that synthesizes dense reward signals by iteratively finalizing the contribution of scene configuration and subtask learning to overall skill acquisition. To the best of our knowledge, this approach constitutes the first comprehensive training dataset for verification-driven generative skill acquisition, eliminating arduous manual reward engineering. Experiments validate the efficacy of our approach: 1) the exemplar task pool improves the average task success rates by 21%, 2) our verification model boosts success rates by 24% for novel tasks and 36% for encountered tasks, and 3) outperforms LLM-as-a-Judge baselines in verification quality.
Provably Efficient Exploration in Inverse Constrained Reinforcement Learning
Sep 24, 2024



To obtain the optimal constraints in complex environments, Inverse Constrained Reinforcement Learning (ICRL) seeks to recover these constraints from expert demonstrations in a data-driven manner. Existing ICRL algorithms collect training samples from an interactive environment. However, the efficacy and efficiency of these sampling strategies remain unknown. To bridge this gap, we introduce a strategic exploration framework with provable efficiency. Specifically, we define a feasible constraint set for ICRL problems and investigate how expert policy and environmental dynamics influence the optimality of constraints. Motivated by our findings, we propose two exploratory algorithms to achieve efficient constraint inference via 1) dynamically reducing the bounded aggregate error of cost estimation and 2) strategically constraining the exploration policy. Both algorithms are theoretically grounded with tractable sample complexity. We empirically demonstrate the performance of our algorithms under various environments.
How Does the Low-Rank Matrix Decomposition Help Internal and External Learnings for Super-Resolution
Jun 30, 2017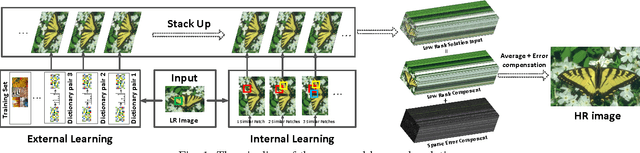
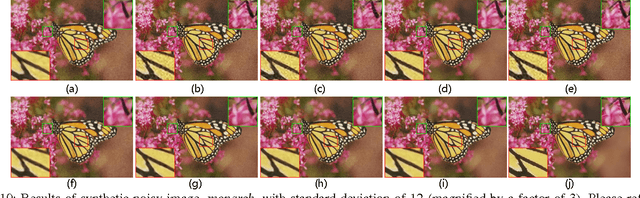
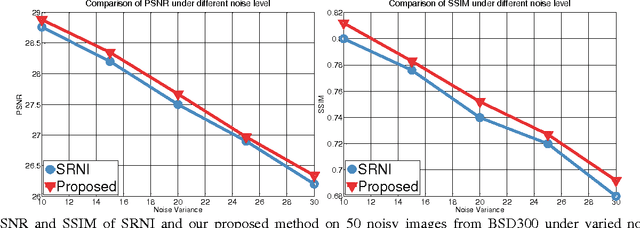
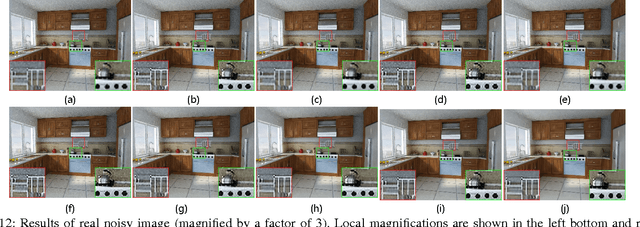
Wisely utilizing the internal and external learning methods is a new challenge in super-resolution problem. To address this issue, we analyze the attributes of two methodologies and find two observations of their recovered details: 1) they are complementary in both feature space and image plane, 2) they distribute sparsely in the spatial space. These inspire us to propose a low-rank solution which effectively integrates two learning methods and then achieves a superior result. To fit this solution, the internal learning method and the external learning method are tailored to produce multiple preliminary results. Our theoretical analysis and experiment prove that the proposed low-rank solution does not require massive inputs to guarantee the performance, and thereby simplifying the design of two learning methods for the solution. Intensive experiments show the proposed solution improves the single learning method in both qualitative and quantitative assessments. Surprisingly, it shows more superior capability on noisy images and outperforms state-of-the-art methods.