 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSePiCo: Semantic-Guided Pixel Contrast for Domain Adaptive Semantic Segmentation
Apr 19, 2022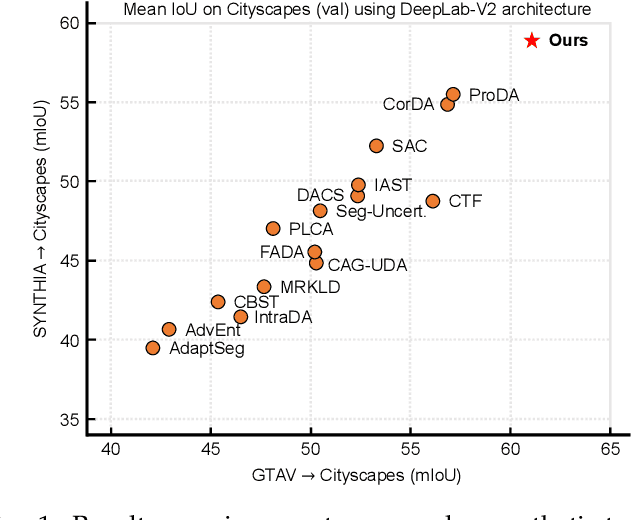
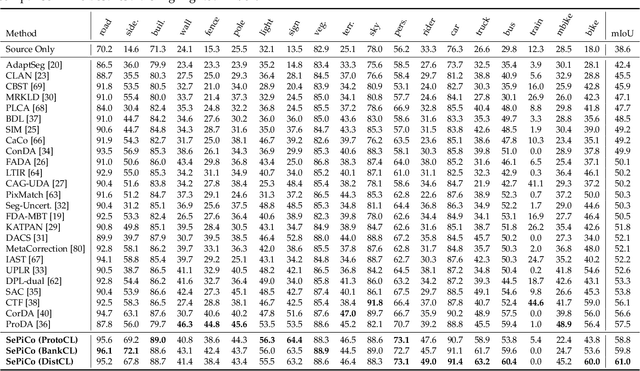
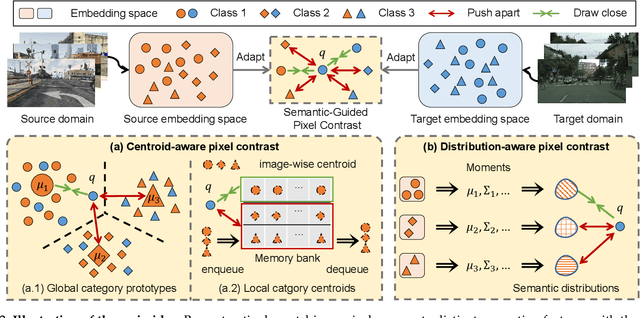
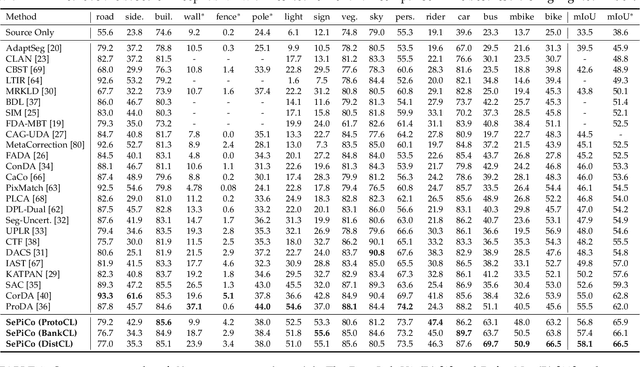
Domain adaptive semantic segmentation attempts to make satisfactory dense predictions on an unlabeled target domain by utilizing the model trained on a labeled source domain. One solution is self-training, which retrains models with target pseudo labels. Many methods tend to alleviate noisy pseudo labels, however, they ignore intrinsic connections among cross-domain pixels with similar semantic concepts. Thus, they would struggle to deal with the semantic variations across domains, leading to less discrimination and poor generalization. In this work, we propose Semantic-Guided Pixel Contrast (SePiCo), a novel one-stage adaptation framework that highlights the semantic concepts of individual pixel to promote learning of class-discriminative and class-balanced pixel embedding space across domains. Specifically, to explore proper semantic concepts, we first investigate a centroid-aware pixel contrast that employs the category centroids of the entire source domain or a single source image to guide the learning of discriminative features. Considering the possible lack of category diversity in semantic concepts, we then blaze a trail of distributional perspective to involve a sufficient quantity of instances, namely distribution-aware pixel contrast, in which we approximate the true distribution of each semantic category from the statistics of labeled source data. Moreover, such an optimization objective can derive a closed-form upper bound by implicitly involving an infinite number of (dis)similar pairs. Extensive experiments show that SePiCo not only helps stabilize training but also yields discriminative features, making significant progress in both daytime and nighttime scenarios. Most notably, SePiCo establishes excellent results on tasks of GTAV/SYNTHIA-to-Cityscapes and Cityscapes-to-Dark Zurich, improving by 12.8, 8.8, and 9.2 mIoUs compared to the previous best method, respectively.
Active Learning for Domain Adaptation: An Energy-based Approach
Dec 08, 2021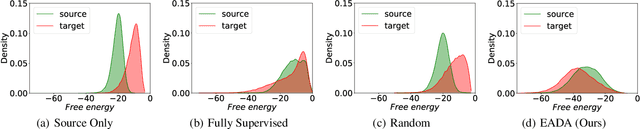
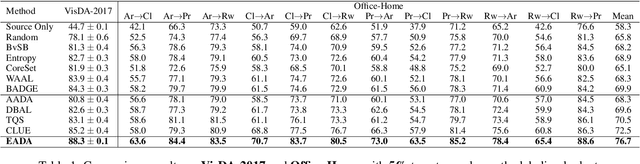
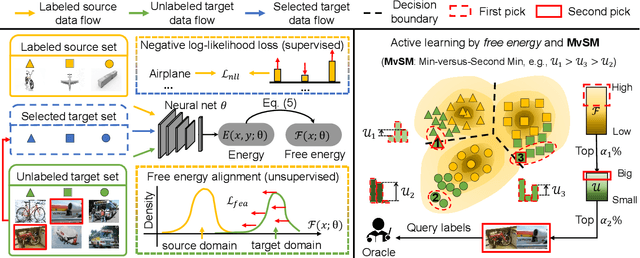
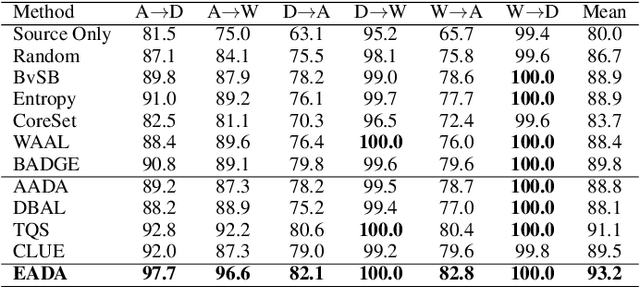
Unsupervised domain adaptation has recently emerged as an effective paradigm for generalizing deep neural networks to new target domains. However, there is still enormous potential to be tapped to reach the fully supervised performance. In this paper, we present a novel active learning strategy to assist knowledge transfer in the target domain, dubbed active domain adaptation. We start from an observation that energy-based models exhibit free energy biases when training (source) and test (target) data come from different distributions. Inspired by this inherent mechanism, we empirically reveal that a simple yet efficient energy-based sampling strategy sheds light on selecting the most valuable target samples than existing approaches requiring particular architectures or computation of the distances. Our algorithm, Energy-based Active Domain Adaptation (EADA), queries groups of targe data that incorporate both domain characteristic and instance uncertainty into every selection round. Meanwhile, by aligning the free energy of target data compact around the source domain via a regularization term, domain gap can be implicitly diminished. Through extensive experiments, we show that EADA surpasses state-of-the-art methods on well-known challenging benchmarks with substantial improvements, making it a useful option in the open world. Code is available at https://github.com/BIT-DA/EADA.
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
Nov 25, 2021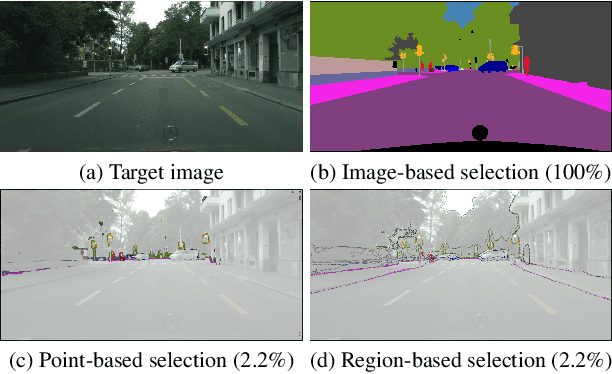
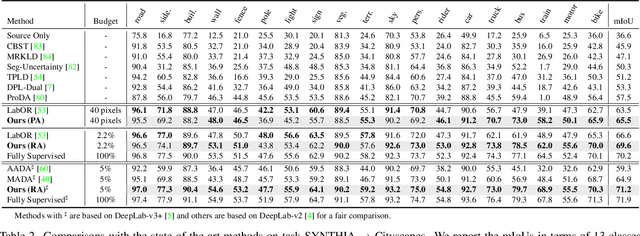
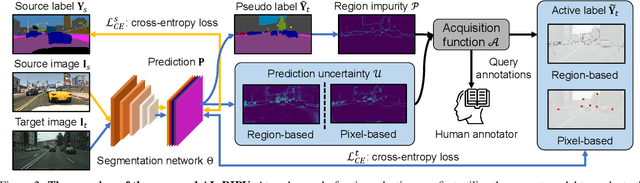
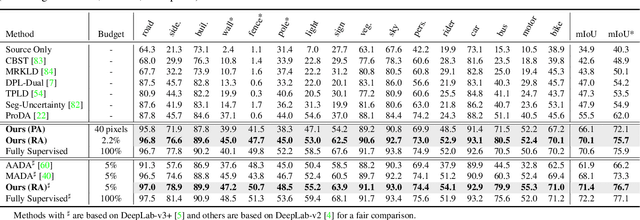
Self-training has greatly facilitated domain adaptive semantic segmentation, which iteratively generates pseudo labels on the target domain and retrains the network. However, since the realistic segmentation datasets are highly imbalanced, target pseudo labels are typically biased to the majority classes and basically noisy, leading to an error-prone and sub-optimal model. To address this issue, we propose a region-based active learning approach for semantic segmentation under a domain shift, aiming to automatically query a small partition of image regions to be labeled while maximizing segmentation performance. Our algorithm, Active Learning via Region Impurity and Prediction Uncertainty (AL-RIPU), introduces a novel acquisition strategy characterizing the spatial adjacency of image regions along with the prediction confidence. We show that the proposed region-based selection strategy makes more efficient use of a limited budget than image-based or point-based counterparts. Meanwhile, we enforce local prediction consistency between a pixel and its nearest neighbor on a source image. Further, we develop a negative learning loss to enhance the discriminative representation learning on the target domain. Extensive experiments demonstrate that our method only requires very few annotations to almost reach the supervised performance and substantially outperforms state-of-the-art methods.
SPCL: A New Framework for Domain Adaptive Semantic Segmentation via Semantic Prototype-based Contrastive Learning
Nov 24, 2021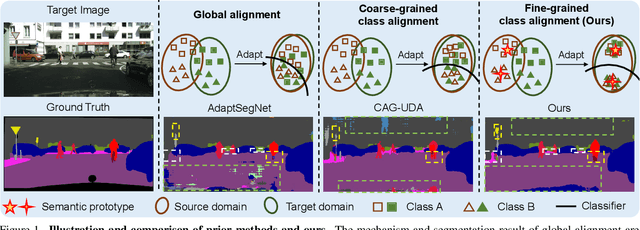
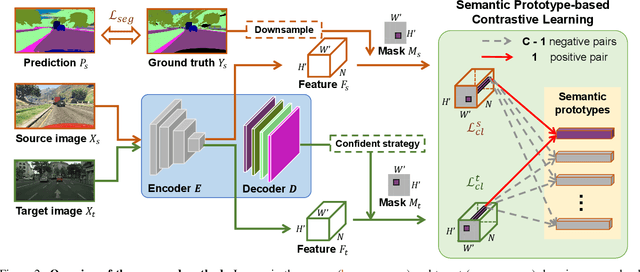

Although there is significant progress in supervised semantic segmentation, it remains challenging to deploy the segmentation models to unseen domains due to domain biases. Domain adaptation can help in this regard by transferring knowledge from a labeled source domain to an unlabeled target domain. Previous methods typically attempt to perform the adaptation on global features, however, the local semantic affiliations accounting for each pixel in the feature space are often ignored, resulting in less discriminability. To solve this issue, we propose a novel semantic prototype-based contrastive learning framework for fine-grained class alignment. Specifically, the semantic prototypes provide supervisory signals for per-pixel discriminative representation learning and each pixel of source and target domains in the feature space is required to reflect the content of the corresponding semantic prototype. In this way, our framework is able to explicitly make intra-class pixel representations closer and inter-class pixel representations further apart to improve the robustness of the segmentation model as well as alleviate the domain shift problem. Our method is easy to implement and attains superior results compared to state-of-the-art approaches, as is demonstrated with a number of experiments. The code is publicly available at [this https URL](https://github.com/BinhuiXie/SPCL).
Semantic Distribution-aware Contrastive Adaptation for Semantic Segmentation
May 11, 2021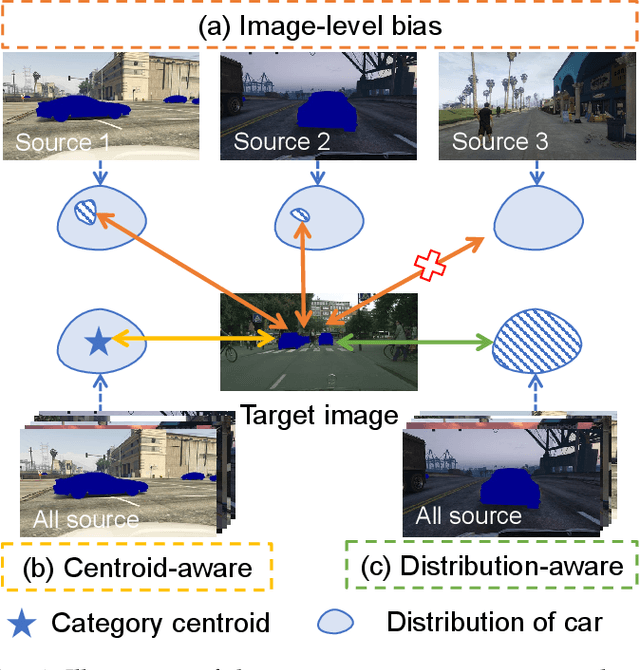
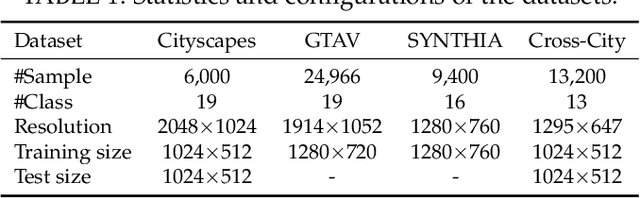
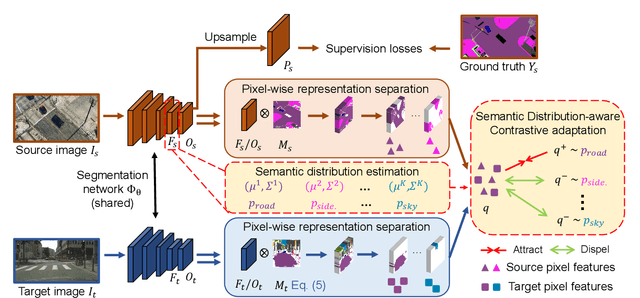
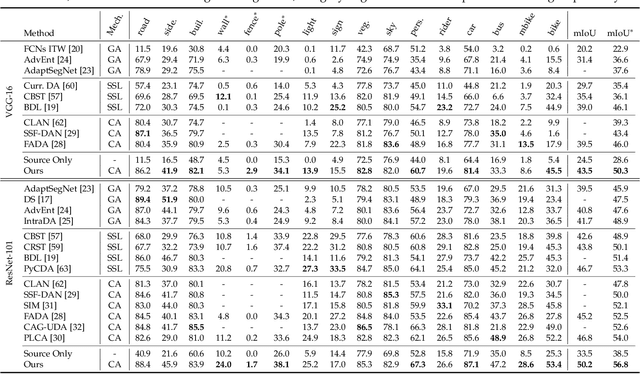
Domain adaptive semantic segmentation refers to making predictions on a certain target domain with only annotations of a specific source domain. Current state-of-the-art works suggest that performing category alignment can alleviate domain shift reasonably. However, they are mainly based on image-to-image adversarial training and little consideration is given to semantic variations of an object among images, failing to capture a comprehensive picture of different categories. This motivates us to explore a holistic representative, the semantic distribution from each category in source domain, to mitigate the problem above. In this paper, we present semantic distribution-aware contrastive adaptation algorithm that enables pixel-wise representation alignment under the guidance of semantic distributions. Specifically, we first design a pixel-wise contrastive loss by considering the correspondences between semantic distributions and pixel-wise representations from both domains. Essentially, clusters of pixel representations from the same category should cluster together and those from different categories should spread out. Next, an upper bound on this formulation is derived by involving the learning of an infinite number of (dis)similar pairs, making it efficient. Finally, we verify that SDCA can further improve segmentation accuracy when integrated with the self-supervised learning. We evaluate SDCA on multiple benchmarks, achieving considerable improvements over existing algorithms.The code is publicly available at https://github.com/BIT-DA/SDCA
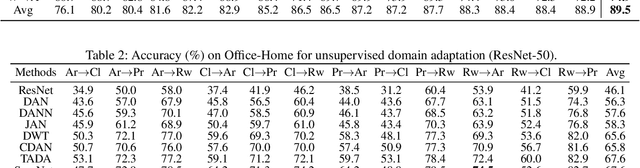
Generalized Domain Conditioned Adaptation Network
Mar 23, 2021
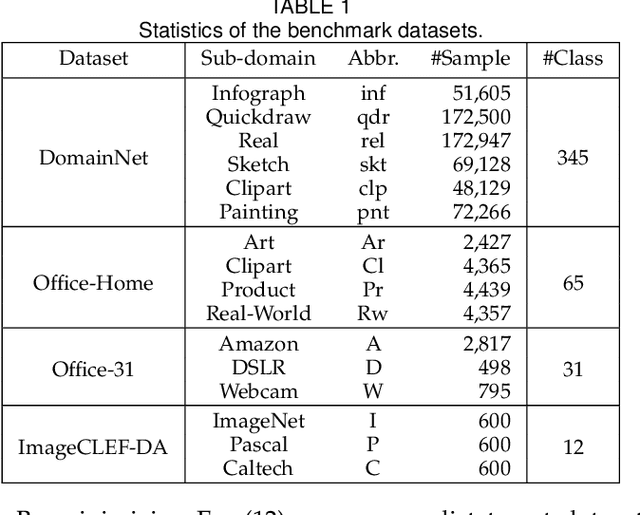
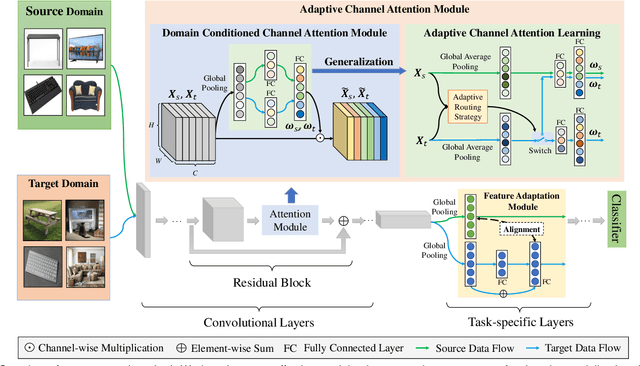
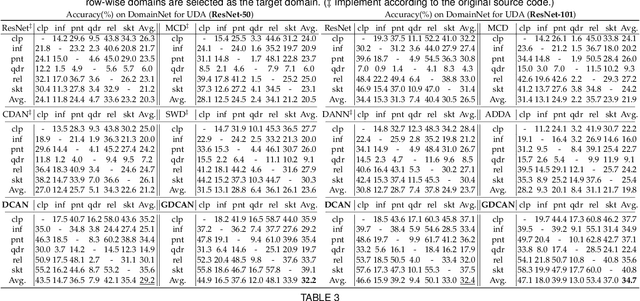
Domain Adaptation (DA) attempts to transfer knowledge learned in the labeled source domain to the unlabeled but related target domain without requiring large amounts of target supervision. Recent advances in DA mainly proceed by aligning the source and target distributions. Despite the significant success, the adaptation performance still degrades accordingly when the source and target domains encounter a large distribution discrepancy. We consider this limitation may attribute to the insufficient exploration of domain-specialized features because most studies merely concentrate on domain-general feature learning in task-specific layers and integrate totally-shared convolutional networks (convnets) to generate common features for both domains. In this paper, we relax the completely-shared convnets assumption adopted by previous DA methods and propose Domain Conditioned Adaptation Network (DCAN), which introduces domain conditioned channel attention module with a multi-path structure to separately excite channel activation for each domain. Such a partially-shared convnets module allows domain-specialized features in low-level to be explored appropriately. Further, given the knowledge transferability varying along with convolutional layers, we develop Generalized Domain Conditioned Adaptation Network (GDCAN) to automatically determine whether domain channel activations should be separately modeled in each attention module. Afterward, the critical domain-specialized knowledge could be adaptively extracted according to the domain statistic gaps. As far as we know, this is the first work to explore the domain-wise convolutional channel activations separately for deep DA networks. Additionally, to effectively match high-level feature distributions across domains, we consider deploying feature adaptation blocks after task-specific layers, which can explicitly mitigate the domain discrepancy.
Bi-Classifier Determinacy Maximization for Unsupervised Domain Adaptation
Dec 13, 2020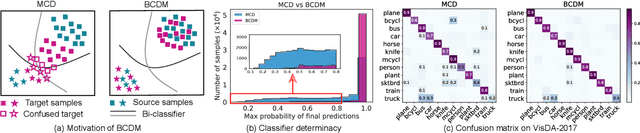
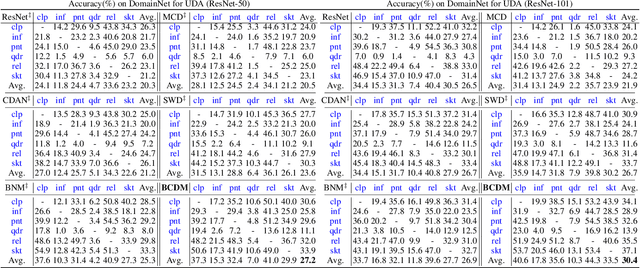
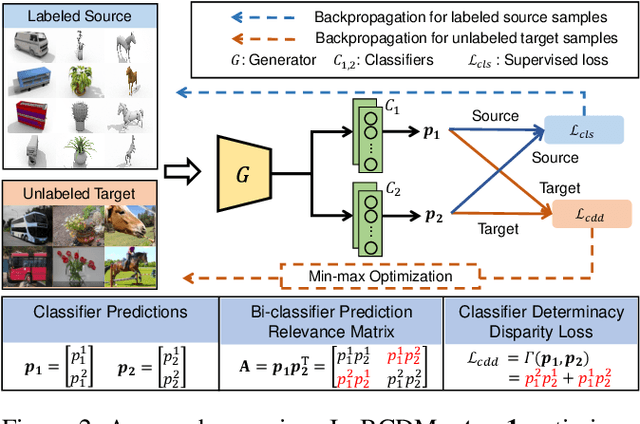
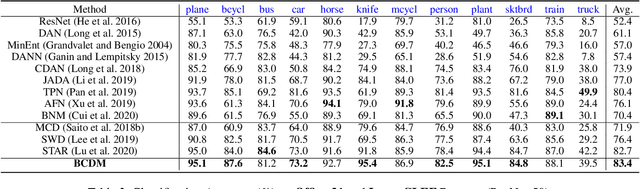
Unsupervised domain adaptation challenges the problem of transferring knowledge from a well-labelled source domain to an unlabelled target domain. Recently,adversarial learning with bi-classifier has been proven effective in pushing cross-domain distributions close. Prior approaches typically leverage the disagreement between bi-classifier to learn transferable representations, however, they often neglect the classifier determinacy in the target domain, which could result in a lack of feature discriminability. In this paper, we present a simple yet effective method, namely Bi-Classifier Determinacy Maximization(BCDM), to tackle this problem. Motivated by the observation that target samples cannot always be separated distinctly by the decision boundary, here in the proposed BCDM, we design a novel classifier determinacy disparity (CDD) metric, which formulates classifier discrepancy as the class relevance of distinct target predictions and implicitly introduces constraint on the target feature discriminability. To this end, the BCDM can generate discriminative representations by encouraging target predictive outputs to be consistent and determined, meanwhile, preserve the diversity of predictions in an adversarial manner. Furthermore, the properties of CDD as well as the theoretical guarantees of BCDM's generalization bound are both elaborated. Extensive experiments show that BCDM compares favorably against the existing state-of-the-art domain adaptation methods.
Simultaneous Semantic Alignment Network for Heterogeneous Domain Adaptation
Aug 05, 2020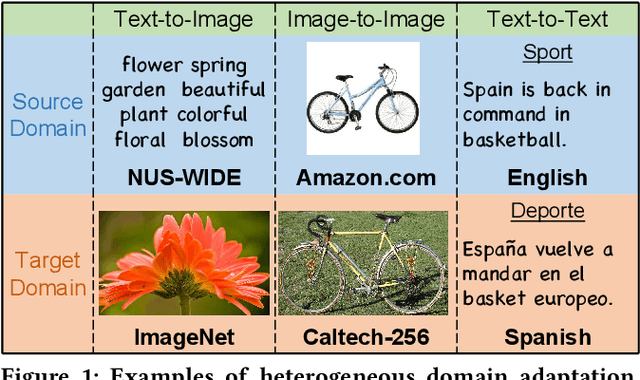
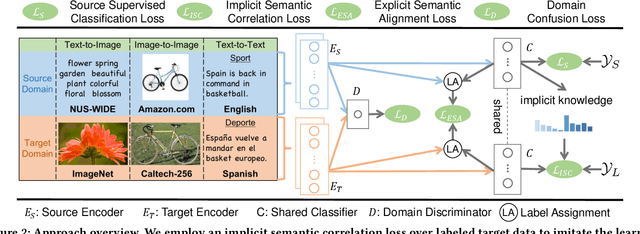
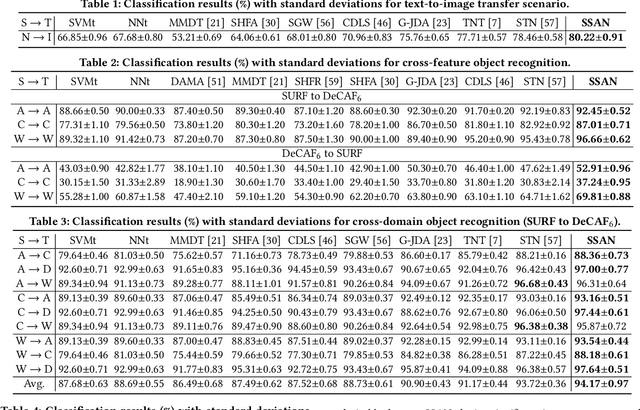
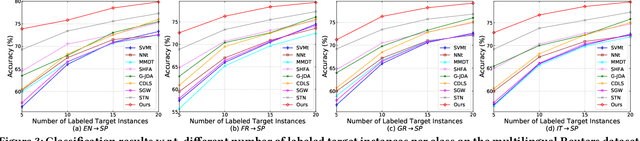
Heterogeneous domain adaptation (HDA) transfers knowledge across source and target domains that present heterogeneities e.g., distinct domain distributions and difference in feature type or dimension. Most previous HDA methods tackle this problem through learning a domain-invariant feature subspace to reduce the discrepancy between domains. However, the intrinsic semantic properties contained in data are under-explored in such alignment strategy, which is also indispensable to achieve promising adaptability. In this paper, we propose a Simultaneous Semantic Alignment Network (SSAN) to simultaneously exploit correlations among categories and align the centroids for each category across domains. In particular, we propose an implicit semantic correlation loss to transfer the correlation knowledge of source categorical prediction distributions to target domain. Meanwhile, by leveraging target pseudo-labels, a robust triplet-centroid alignment mechanism is explicitly applied to align feature representations for each category. Notably, a pseudo-label refinement procedure with geometric similarity involved is introduced to enhance the target pseudo-label assignment accuracy. Comprehensive experiments on various HDA tasks across text-to-image, image-to-image and text-to-text successfully validate the superiority of our SSAN against state-of-the-art HDA methods. The code is publicly available at https://github.com/BIT-DA/SSAN.
Domain Conditioned Adaptation Network
May 14, 2020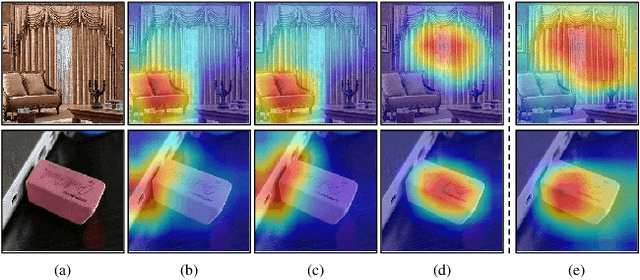
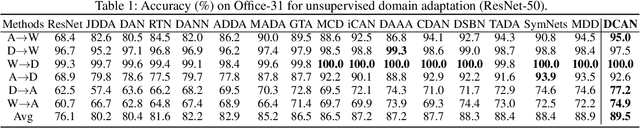
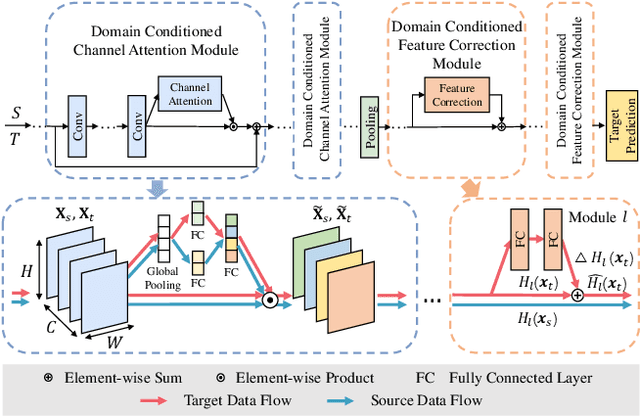
Tremendous research efforts have been made to thrive deep domain adaptation (DA) by seeking domain-invariant features. Most existing deep DA models only focus on aligning feature representations of task-specific layers across domains while integrating a totally shared convolutional architecture for source and target. However, we argue that such strongly-shared convolutional layers might be harmful for domain-specific feature learning when source and target data distribution differs to a large extent. In this paper, we relax a shared-convnets assumption made by previous DA methods and propose a Domain Conditioned Adaptation Network (DCAN), which aims to excite distinct convolutional channels with a domain conditioned channel attention mechanism. As a result, the critical low-level domain-dependent knowledge could be explored appropriately. As far as we know, this is the first work to explore the domain-wise convolutional channel activation for deep DA networks. Moreover, to effectively align high-level feature distributions across two domains, we further deploy domain conditioned feature correction blocks after task-specific layers, which will explicitly correct the domain discrepancy. Extensive experiments on three cross-domain benchmarks demonstrate the proposed approach outperforms existing methods by a large margin, especially on very tough cross-domain learning tasks.