 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sharpness-Aware Optimization Through Variance Suppression
Sep 28, 2023



Sharpness-aware minimization (SAM) has well documented merits in enhancing generalization of deep neural networks, even without sizable data augmentation. Embracing the geometry of the loss function, where neighborhoods of 'flat minima' heighten generalization ability, SAM seeks 'flat valleys' by minimizing the maximum loss caused by an adversary perturbing parameters within the neighborhood. Although critical to account for sharpness of the loss function, such an 'over-friendly adversary' can curtail the outmost level of generalization. The novel approach of this contribution fosters stabilization of adversaries through variance suppression (VaSSO) to avoid such friendliness. VaSSO's provable stability safeguards its numerical improvement over SAM in model-agnostic tasks, including image classification and machine translation. In addition, experiments confirm that VaSSO endows SAM with robustness against high levels of label noise.
Conic Descent Redux for Memory-Efficient Optimization
Aug 13, 2023Conic programming has well-documented merits in a gamut of signal processing and machine learning tasks. This contribution revisits a recently developed first-order conic descent (CD) solver, and advances it in three aspects: intuition, theory, and algorithmic implementation. It is found that CD can afford an intuitive geometric derivation that originates from the dual problem. This opens the door to novel algorithmic designs, with a momentum variant of CD, momentum conic descent (MOCO) exemplified. Diving deeper into the dual behavior CD and MOCO reveals: i) an analytically justified stopping criterion; and, ii) the potential to design preconditioners to speed up dual convergence. Lastly, to scale semidefinite programming (SDP) especially for low-rank solutions, a memory efficient MOCO variant is developed and numerically validated.
Scalable Bayesian Meta-Learning through Generalized Implicit Gradients
Mar 31, 2023



Meta-learning owns unique effectiveness and swiftness in tackling emerging tasks with limited data. Its broad applicability is revealed by viewing it as a bi-level optimization problem. The resultant algorithmic viewpoint however, faces scalability issues when the inner-level optimization relies on gradient-based iterations. Implicit differentiation has been considered to alleviate this challenge, but it is restricted to an isotropic Gaussian prior, and only favors deterministic meta-learning approaches. This work markedly mitigates the scalability bottleneck by cross-fertilizing the benefits of implicit differentiation to probabilistic Bayesian meta-learning. The novel implicit Bayesian meta-learning (iBaML) method not only broadens the scope of learnable priors, but also quantifies the associated uncertainty. Furthermore, the ultimate complexity is well controlled regardless of the inner-level optimization trajectory. Analytical error bounds are established to demonstrate the precision and efficiency of the generalized implicit gradient over the explicit one. Extensive numerical tests are also carried out to empirically validate the performance of the proposed method.
Surrogate modeling for Bayesian optimization beyond a single Gaussian process
May 27, 2022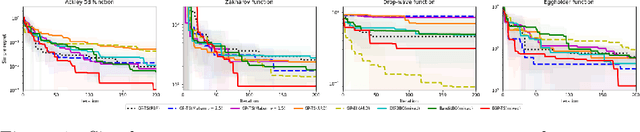

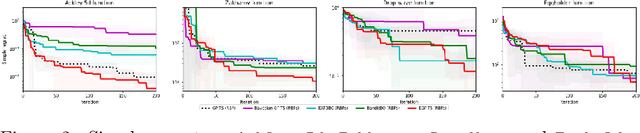
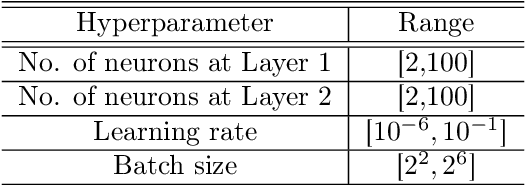
Bayesian optimization (BO) has well-documented merits for optimizing black-box functions with an expensive evaluation cost. Such functions emerge in applications as diverse as hyperparameter tuning, drug discovery, and robotics. BO hinges on a Bayesian surrogate model to sequentially select query points so as to balance exploration with exploitation of the search space. Most existing works rely on a single Gaussian process (GP) based surrogate model, where the kernel function form is typically preselected using domain knowledge. To bypass such a design process, this paper leverages an ensemble (E) of GPs to adaptively select the surrogate model fit on-the-fly, yielding a GP mixture posterior with enhanced expressiveness for the sought function. Acquisition of the next evaluation input using this EGP-based function posterior is then enabled by Thompson sampling (TS) that requires no additional design parameters. To endow function sampling with scalability, random feature-based kernel approximation is leveraged per GP model. The novel EGP-TS readily accommodates parallel operation. To further establish convergence of the proposed EGP-TS to the global optimum, analysis is conducted based on the notion of Bayesian regret for both sequential and parallel settings. Tests on synthetic functions and real-world applications showcase the merits of the proposed method.
Distributionally Robust Semi-Supervised Learning Over Graphs
Oct 20, 2021
Semi-supervised learning (SSL) over graph-structured data emerges in many network science applications. To efficiently manage learning over graphs, variants of graph neural networks (GNNs) have been developed recently. By succinctly encoding local graph structures and features of nodes, state-of-the-art GNNs can scale linearly with the size of graph. Despite their success in practice, most of existing methods are unable to handle graphs with uncertain nodal attributes. Specifically whenever mismatches between training and testing data distribution exists, these models fail in practice. Challenges also arise due to distributional uncertainties associated with data acquired by noisy measurements. In this context, a distributionally robust learning framework is developed, where the objective is to train models that exhibit quantifiable robustness against perturbations. The data distribution is considered unknown, but lies within a Wasserstein ball centered around empirical data distribution. A robust model is obtained by minimizing the worst expected loss over this ball. However, solving the emerging functional optimization problem is challenging, if not impossible. Advocating a strong duality condition, we develop a principled method that renders the problem tractable and efficiently solvable. Experiments assess the performance of the proposed method.
Heavy Ball Momentum for Conditional Gradient
Oct 08, 2021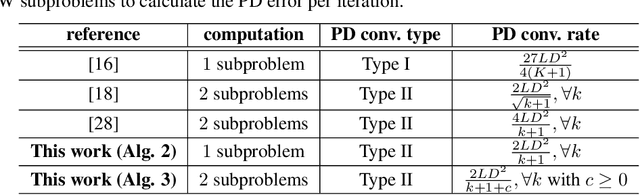
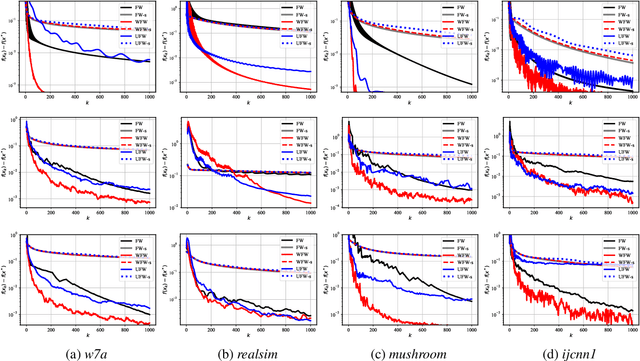
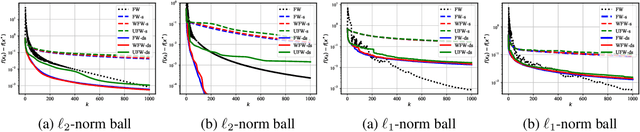
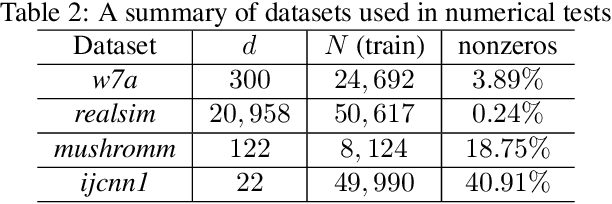
Conditional gradient, aka Frank Wolfe (FW) algorithms, have well-documented merits in machine learning and signal processing applications. Unlike projection-based methods, momentum cannot improve the convergence rate of FW, in general. This limitation motivates the present work, which deals with heavy ball momentum, and its impact to FW. Specifically, it is established that heavy ball offers a unifying perspective on the primal-dual (PD) convergence, and enjoys a tighter per iteration PD error rate, for multiple choices of step sizes, where PD error can serve as the stopping criterion in practice. In addition, it is asserted that restart, a scheme typically employed jointly with Nesterov's momentum, can further tighten this PD error bound. Numerical results demonstrate the usefulness of heavy ball momentum in FW iterations.
PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Table Image Recognition to Latex
May 05, 2021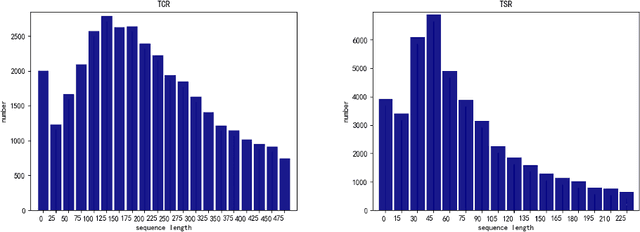
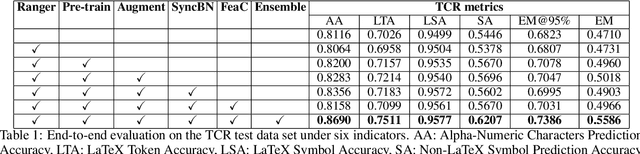
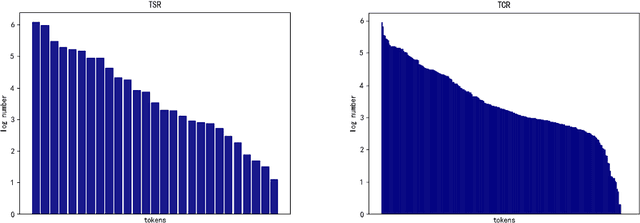
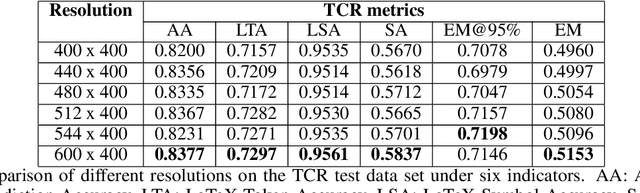
This paper presents our solution for the ICDAR 2021 Competition on Scientific Table Image Recognition to LaTeX. This competition has two sub-tasks: Table Structure Reconstruction (TSR) and Table Content Reconstruction (TCR). We treat both sub-tasks as two individual image-to-sequence recognition problems. We leverage our previously proposed algorithm MASTER \cite{lu2019master}, which is originally proposed for scene text recognition. We optimize the MASTER model from several perspectives: network structure, optimizer, normalization method, pre-trained model, resolution of input image, data augmentation, and model ensemble. Our method achieves 0.7444 Exact Match and 0.8765 Exact Match @95\% on the TSR task, and obtains 0.5586 Exact Match and 0.7386 Exact Match 95\% on the TCR task.
Adversarial Linear Contextual Bandits with Graph-Structured Side Observations
Dec 28, 2020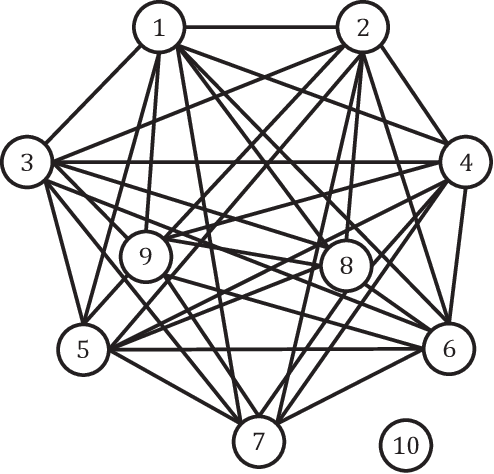
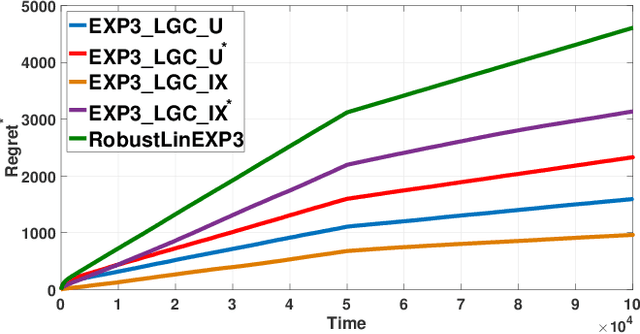
This paper studies the adversarial graphical contextual bandits, a variant of adversarial multi-armed bandits that leverage two categories of the most common side information: \emph{contexts} and \emph{side observations}. In this setting, a learning agent repeatedly chooses from a set of $K$ actions after being presented with a $d$-dimensional context vector. The agent not only incurs and observes the loss of the chosen action, but also observes the losses of its neighboring actions in the observation structures, which are encoded as a series of feedback graphs. This setting models a variety of applications in social networks, where both contexts and graph-structured side observations are available. Two efficient algorithms are developed based on \texttt{EXP3}. Under mild conditions, our analysis shows that for undirected feedback graphs the first algorithm, \texttt{EXP3-LGC-U}, achieves the regret of order $\mathcal{O}(\sqrt{(K+\alpha(G)d)T\log{K}})$ over the time horizon $T$, where $\alpha(G)$ is the average \emph{independence number} of the feedback graphs. A slightly weaker result is presented for the directed graph setting as well. The second algorithm, \texttt{EXP3-LGC-IX}, is developed for a special class of problems, for which the regret is reduced to $\mathcal{O}(\sqrt{\alpha(G)dT\log{K}\log(KT)})$ for both directed as well as undirected feedback graphs. Numerical tests corroborate the efficiency of proposed algorithms.
Enhancing Parameter-Free Frank Wolfe with an Extra Subproblem
Dec 09, 2020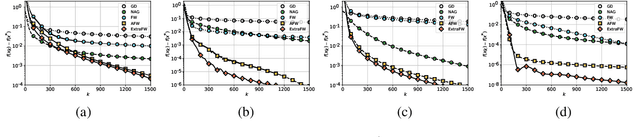

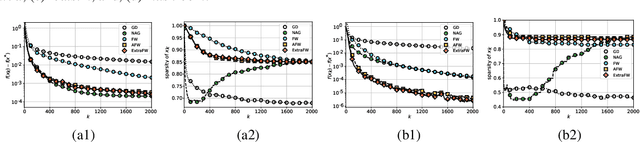
Aiming at convex optimization under structural constraints, this work introduces and analyzes a variant of the Frank Wolfe (FW) algorithm termed ExtraFW. The distinct feature of ExtraFW is the pair of gradients leveraged per iteration, thanks to which the decision variable is updated in a prediction-correction (PC) format. Relying on no problem dependent parameters in the step sizes, the convergence rate of ExtraFW for general convex problems is shown to be ${\cal O}(\frac{1}{k})$, which is optimal in the sense of matching the lower bound on the number of solved FW subproblems. However, the merit of ExtraFW is its faster rate ${\cal O}\big(\frac{1}{k^2} \big)$ on a class of machine learning problems. Compared with other parameter-free FW variants that have faster rates on the same problems, ExtraFW has improved rates and fine-grained analysis thanks to its PC update. Numerical tests on binary classification with different sparsity-promoting constraints demonstrate that the empirical performance of ExtraFW is significantly better than FW, and even faster than Nesterov's accelerated gradient on certain datasets. For matrix completion, ExtraFW enjoys smaller optimality gap, and lower rank than FW.
Confusable Learning for Large-class Few-Shot Classification
Nov 06, 2020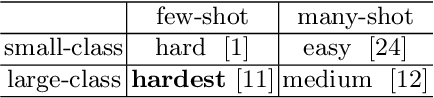
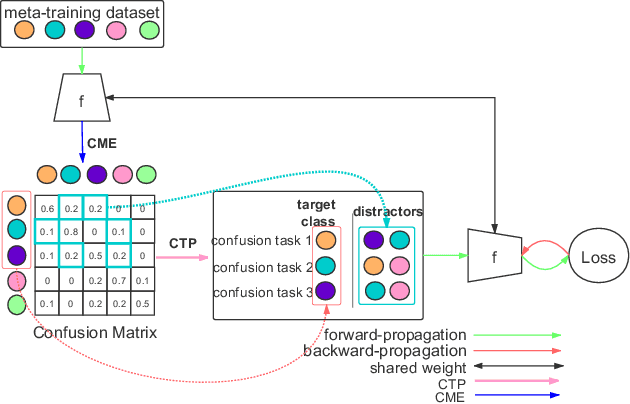
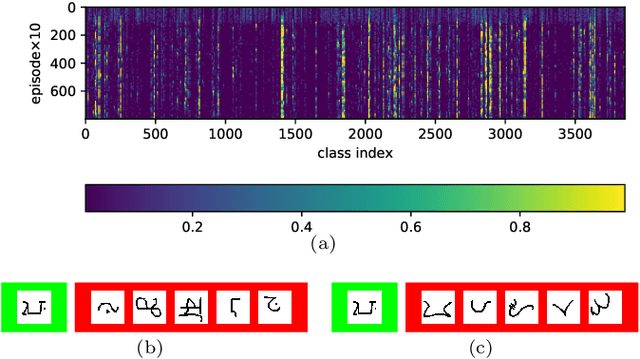
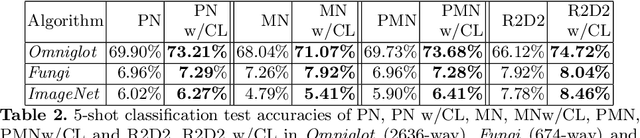
Few-shot image classification is challenging due to the lack of ample samples in each class. Such a challenge becomes even tougher when the number of classes is very large, i.e., the large-class few-shot scenario. In this novel scenario, existing approaches do not perform well because they ignore confusable classes, namely similar classes that are difficult to distinguish from each other. These classes carry more information. In this paper, we propose a biased learning paradigm called Confusable Learning, which focuses more on confusable classes. Our method can be applied to mainstream meta-learning algorithms. Specifically, our method maintains a dynamically updating confusion matrix, which analyzes confusable classes in the dataset. Such a confusion matrix helps meta learners to emphasize on confusable classes. Comprehensive experiments on Omniglot, Fungi, and ImageNet demonstrate the efficacy of our method over state-of-the-art baselines.