 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Adaptation Redux for Large Models
Apr 23, 2026Low-rank adaptation (LoRA) has emerged as the de facto standard for parameter-efficient fine-tuning (PEFT) of foundation models, enabling the adaptation of billion-parameter networks with minimal computational and memory overhead. Despite its empirical success and rapid proliferation of variants, it remains elusive which architectural choices, optimization techniques, and deployment constraints should guide practical method selection. This overview revisits LoRA through the lens of signal processing (SP), bridging modern adapter designs with classical low-rank modeling tools and inverse problems, as well as highlighting how SP principles can inform principled advances of fine-tuning approaches. Rather than providing a comprehensive enumeration and empirical comparisons of LoRA variants, emphasis is placed on the technical mechanisms underpinning these approaches to justify their effectiveness. These advances are categorized into three complementary axes: architectural design, efficient optimization, and pertinent applications. The first axis builds on singular value decomposition (SVD)-based factorization, rank-augmentation constructions, and cross-layer tensorization, while the second axis deals with initialization, alternating solvers, gauge-invariant optimization, and parameterization-aware methods. Beyond fine-tuning, emerging applications of LoRA are accounted across the entire lifecycle of large models, ranging from pre- and post-training to serving/deployment. Finally, open research directions are outlined at the confluence of SP and deep learning to catalyze a bidirectional frontier: classical SP tools provide a principled vocabulary for designing principled PEFT methods, while the unique challenges facing modern deep learning, especially the overwhelming scale and prohibitive overhead, also offer new research lines benefiting the SP community in return.
Binomial Gradient-Based Meta-Learning for Enhanced Meta-Gradient Estimation
Apr 14, 2026Meta-learning offers a principled framework leveraging \emph{task-invariant} priors from related tasks, with which \emph{task-specific} models can be fine-tuned on downstream tasks, even with limited data records. Gradient-based meta-learning (GBML) relies on gradient descent (GD) to adapt the prior to a new task. Albeit effective, these methods incur high computational overhead that scales linearly with the number of GD steps. To enhance efficiency and scalability, existing methods approximate the gradient of prior parameters (meta-gradient) via truncated backpropagation, yet suffer large approximation errors. Targeting accurate approximation, this work puts forth binomial GBML (BinomGBML), which relies on a truncated binomial expansion for meta-gradient estimation. This novel expansion endows more information in the meta-gradient estimation via efficient parallel computation. As a running paradigm applied to model-agnostic meta-learning (MAML), the resultant BinomMAML provably enjoys error bounds that not only improve upon existing approaches, but also decay super-exponentially under mild conditions. Numerical tests corroborate the theoretical analysis and showcase boosted performance with slightly increased computational overhead.
ANCRe: Adaptive Neural Connection Reassignment for Efficient Depth Scaling
Feb 09, 2026Scaling network depth has been a central driver behind the success of modern foundation models, yet recent investigations suggest that deep layers are often underutilized. This paper revisits the default mechanism for deepening neural networks, namely residual connections, from an optimization perspective. Rigorous analysis proves that the layout of residual connections can fundamentally shape convergence behavior, and even induces an exponential gap in convergence rates. Prompted by this insight, we introduce adaptive neural connection reassignment (ANCRe), a principled and lightweight framework that parameterizes and learns residual connectivities from the data. ANCRe adaptively reassigns residual connections with negligible computational and memory overhead ($<1\%$), while enabling more effective utilization of network depth. Extensive numerical tests across pre-training of large language models, diffusion models, and deep ResNets demonstrate consistently accelerated convergence, boosted performance, and enhanced depth efficiency over conventional residual connections.
CIS-BA: Continuous Interaction Space Based Backdoor Attack for Object Detection in the Real-World
Dec 16, 2025Object detection models deployed in real-world applications such as autonomous driving face serious threats from backdoor attacks. Despite their practical effectiveness,existing methods are inherently limited in both capability and robustness due to their dependence on single-trigger-single-object mappings and fragile pixel-level cues. We propose CIS-BA, a novel backdoor attack paradigm that redefines trigger design by shifting from static object features to continuous inter-object interaction patterns that describe how objects co-occur and interact in a scene. By modeling these patterns as a continuous interaction space, CIS-BA introduces space triggers that, for the first time, enable a multi-trigger-multi-object attack mechanism while achieving robustness through invariant geometric relations. To implement this paradigm, we design CIS-Frame, which constructs space triggers via interaction analysis, formalizes them as class-geometry constraints for sample poisoning, and embeds the backdoor during detector training. CIS-Frame supports both single-object attacks (object misclassification and disappearance) and multi-object simultaneous attacks, enabling complex and coordinated effects across diverse interaction states. Experiments on MS-COCO and real-world videos show that CIS-BA achieves over 97% attack success under complex environments and maintains over 95% effectiveness under dynamic multi-trigger conditions, while evading three state-of-the-art defenses. In summary, CIS-BA extends the landscape of backdoor attacks in interaction-intensive scenarios and provides new insights into the security of object detection systems.
RefLoRA: Refactored Low-Rank Adaptation for Efficient Fine-Tuning of Large Models
May 24, 2025Low-Rank Adaptation (LoRA) lowers the computational and memory overhead of fine-tuning large models by updating a low-dimensional subspace of the pre-trained weight matrix. Albeit efficient, LoRA exhibits suboptimal convergence and noticeable performance degradation, due to inconsistent and imbalanced weight updates induced by its nonunique low-rank factorizations. To overcome these limitations, this article identifies the optimal low-rank factorization per step that minimizes an upper bound on the loss. The resultant refactored low-rank adaptation (RefLoRA) method promotes a flatter loss landscape, along with consistent and balanced weight updates, thus speeding up stable convergence. Extensive experiments evaluate RefLoRA on natural language understanding, and commonsense reasoning tasks with popular large language models including DeBERTaV3, LLaMA-7B, LLaMA2-7B and LLaMA3-8B. The numerical tests corroborate that RefLoRA converges faster, outperforms various benchmarks, and enjoys negligible computational overhead compared to state-of-the-art LoRA variants.
Preconditioned Sharpness-Aware Minimization: Unifying Analysis and a Novel Learning Algorithm
Jan 11, 2025



Targeting solutions over `flat' regions of the loss landscape, sharpness-aware minimization (SAM) has emerged as a powerful tool to improve generalizability of deep neural network based learning. While several SAM variants have been developed to this end, a unifying approach that also guides principled algorithm design has been elusive. This contribution leverages preconditioning (pre) to unify SAM variants and provide not only unifying convergence analysis, but also valuable insights. Building upon preSAM, a novel algorithm termed infoSAM is introduced to address the so-called adversarial model degradation issue in SAM by adjusting gradients depending on noise estimates. Extensive numerical tests demonstrate the superiority of infoSAM across various benchmarks.
Meta-Learning with Versatile Loss Geometries for Fast Adaptation Using Mirror Descent
Dec 20, 2023


Utilizing task-invariant prior knowledge extracted from related tasks, meta-learning is a principled framework that empowers learning a new task especially when data records are limited. A fundamental challenge in meta-learning is how to quickly "adapt" the extracted prior in order to train a task-specific model within a few optimization steps. Existing approaches deal with this challenge using a preconditioner that enhances convergence of the per-task training process. Though effective in representing locally a quadratic training loss, these simple linear preconditioners can hardly capture complex loss geometries. The present contribution addresses this limitation by learning a nonlinear mirror map, which induces a versatile distance metric to enable capturing and optimizing a wide range of loss geometries, hence facilitating the per-task training. Numerical tests on few-shot learning datasets demonstrate the superior expressiveness and convergence of the advocated approach.
Scalable Bayesian Meta-Learning through Generalized Implicit Gradients
Mar 31, 2023



Meta-learning owns unique effectiveness and swiftness in tackling emerging tasks with limited data. Its broad applicability is revealed by viewing it as a bi-level optimization problem. The resultant algorithmic viewpoint however, faces scalability issues when the inner-level optimization relies on gradient-based iterations. Implicit differentiation has been considered to alleviate this challenge, but it is restricted to an isotropic Gaussian prior, and only favors deterministic meta-learning approaches. This work markedly mitigates the scalability bottleneck by cross-fertilizing the benefits of implicit differentiation to probabilistic Bayesian meta-learning. The novel implicit Bayesian meta-learning (iBaML) method not only broadens the scope of learnable priors, but also quantifies the associated uncertainty. Furthermore, the ultimate complexity is well controlled regardless of the inner-level optimization trajectory. Analytical error bounds are established to demonstrate the precision and efficiency of the generalized implicit gradient over the explicit one. Extensive numerical tests are also carried out to empirically validate the performance of the proposed method.
Dense Color Constancy with Effective Edge Augmentation
Nov 17, 2019
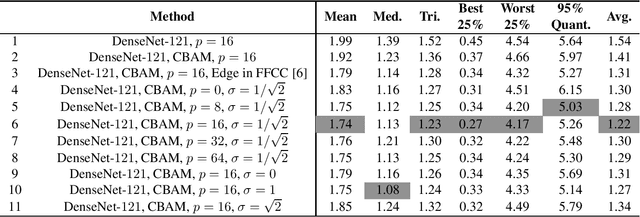
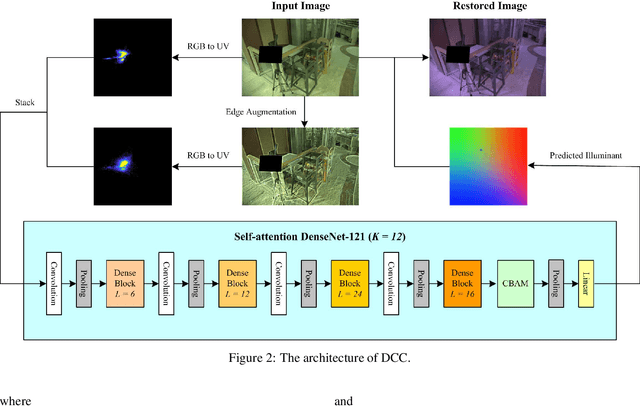
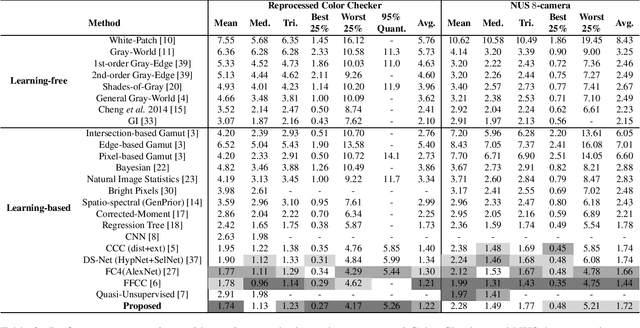
Recently, computational color constancy via convolutional neural networks (CNNs) has received much attention. In this paper, we propose a color constancy algorithm called the Dense Color Constancy (DCC), which employs a self-attention DenseNet to estimate the illuminant based on the $2$D $\log$-chrominance histograms of input images and their augmented edges. The augmented edges help to tell apart the edge and non-edge pixels in the $\log$-histogram, which largely contribute to the feature extraction and color ambiguity elimination, thereby improving the accuracy of illuminant estimation. Experiments on benchmark datasets show that the DCC algorithm is very effective for illuminant estimation compared to the state-of-the-art methods.