 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Ambiguous Questions through Generative Evidence Fusion and Round-Trip Prediction
Nov 26, 2020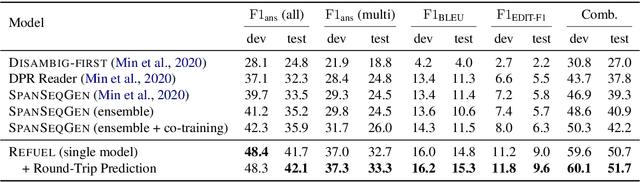
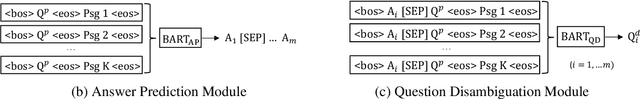
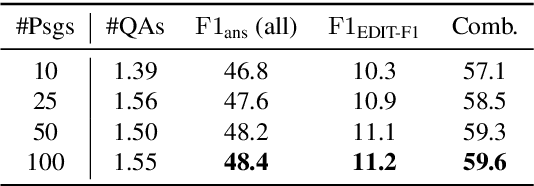

In open-domain question answering, questions are highly likely to be ambiguous because users may not know the scope of relevant topics when formulating them. Therefore, a system needs to find every possible interpretation of the question, and propose a set of disambiguated question-answer pairs. In this paper, we present a model that aggregates and combines evidence from multiple passages to generate question-answer pairs. Particularly, our model reads a large number of passages to find as many interpretations as possible. In addition, we propose a novel round-trip prediction approach to generate additional interpretations that our model fails to find in the first pass, and then verify and filter out the incorrect question-answer pairs to arrive at the final disambiguated output. On the recently introduced AmbigQA open-domain question answering dataset, our model, named Refuel, achieves a new state-of-the-art, outperforming the previous best model by a large margin. We also conduct comprehensive analyses to validate the effectiveness of our proposed round-trip prediction.
End-to-End Synthetic Data Generation for Domain Adaptation of Question Answering Systems
Oct 12, 2020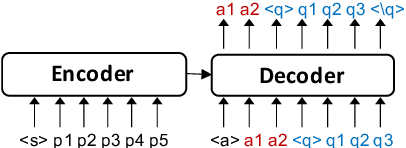

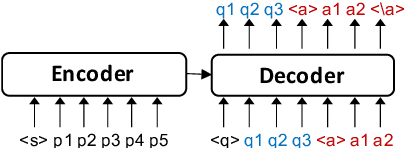
We propose an end-to-end approach for synthetic QA data generation. Our model comprises a single transformer-based encoder-decoder network that is trained end-to-end to generate both answers and questions. In a nutshell, we feed a passage to the encoder and ask the decoder to generate a question and an answer token-by-token. The likelihood produced in the generation process is used as a filtering score, which avoids the need for a separate filtering model. Our generator is trained by fine-tuning a pretrained LM using maximum likelihood estimation. The experimental results indicate significant improvements in the domain adaptation of QA models outperforming current state-of-the-art methods.
Beyond [CLS] through Ranking by Generation
Oct 06, 2020![Figure 1 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for Beyond [CLS] through Ranking by Generation](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2F8c21b1df7ac375742e412251cb37f10966bb3bfa%2F4-Table3-1.png&w=640&q=75)
Generative models for Information Retrieval, where ranking of documents is viewed as the task of generating a query from a document's language model, were very successful in various IR tasks in the past. However, with the advent of modern deep neural networks, attention has shifted to discriminative ranking functions that model the semantic similarity of documents and queries instead. Recently, deep generative models such as GPT2 and BART have been shown to be excellent text generators, but their effectiveness as rankers have not been demonstrated yet. In this work, we revisit the generative framework for information retrieval and show that our generative approaches are as effective as state-of-the-art semantic similarity-based discriminative models for the answer selection task. Additionally, we demonstrate the effectiveness of unlikelihood losses for IR.
Improve Transformer Models with Better Relative Position Embeddings
Sep 28, 2020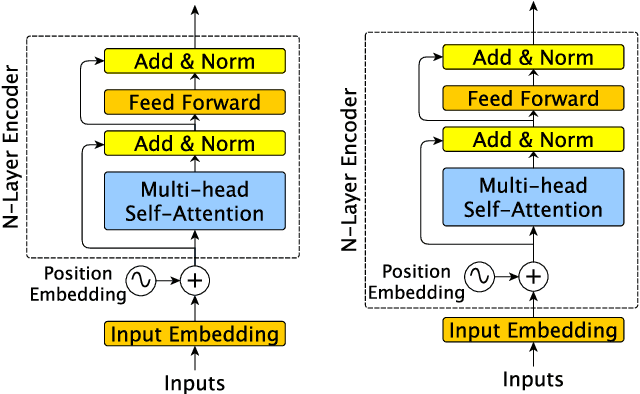
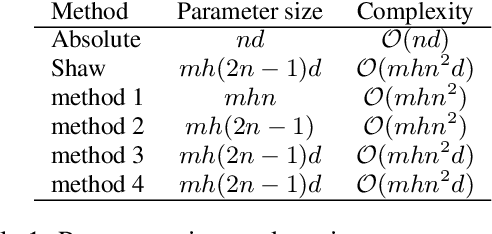
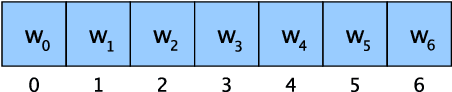
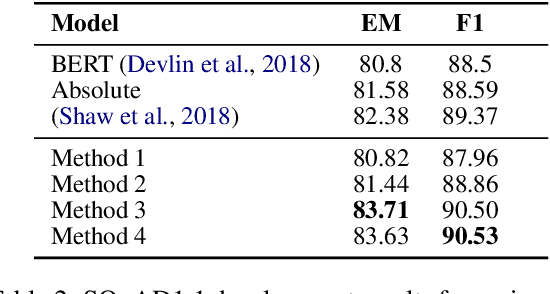
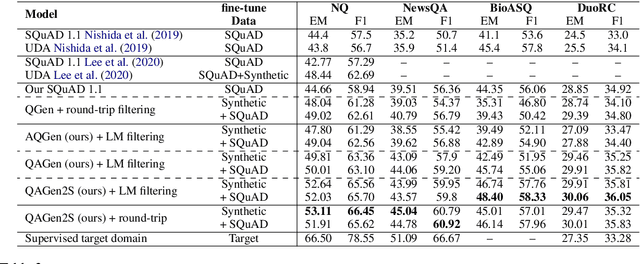
Transformer architectures rely on explicit position encodings in order to preserve a notion of word order. In this paper, we argue that existing work does not fully utilize position information. For example, the initial proposal of a sinusoid embedding is fixed and not learnable. In this paper, we first review absolute position embeddings and existing methods for relative position embeddings. We then propose new techniques that encourage increased interaction between query, key and relative position embeddings in the self-attention mechanism. Our most promising approach is a generalization of the absolute position embedding, improving results on SQuAD1.1 compared to previous position embeddings approaches. In addition, we address the inductive property of whether a position embedding can be robust enough to handle long sequences. We demonstrate empirically that our relative position embedding method is reasonably generalized and robust from the inductive perspective. Finally, we show that our proposed method can be adopted as a near drop-in replacement for improving the accuracy of large models with a small computational budget.
Augmented Natural Language for Generative Sequence Labeling
Sep 15, 2020
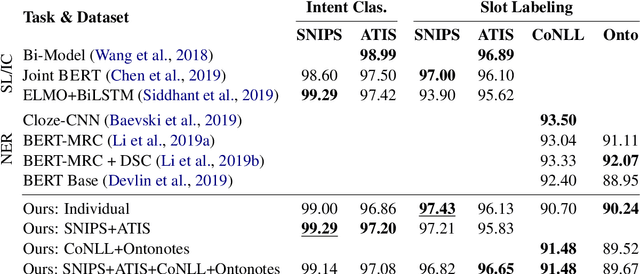
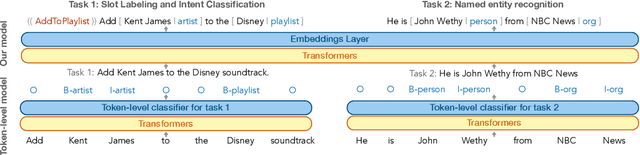
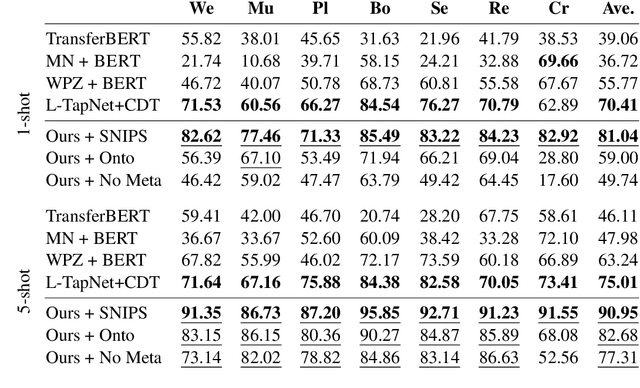
We propose a generative framework for joint sequence labeling and sentence-level classification. Our model performs multiple sequence labeling tasks at once using a single, shared natural language output space. Unlike prior discriminative methods, our model naturally incorporates label semantics and shares knowledge across tasks. Our framework is general purpose, performing well on few-shot, low-resource, and high-resource tasks. We demonstrate these advantages on popular named entity recognition, slot labeling, and intent classification benchmarks. We set a new state-of-the-art for few-shot slot labeling, improving substantially upon the previous 5-shot ($75.0\% \rightarrow 90.9\%$) and 1-shot ($70.4\% \rightarrow 81.0\%$) state-of-the-art results. Furthermore, our model generates large improvements ($46.27\% \rightarrow 63.83\%$) in low-resource slot labeling over a BERT baseline by incorporating label semantics. We also maintain competitive results on high-resource tasks, performing within two points of the state-of-the-art on all tasks and setting a new state-of-the-art on the SNIPS dataset.
Template-Based Question Generation from Retrieved Sentences for Improved Unsupervised Question Answering
Apr 24, 2020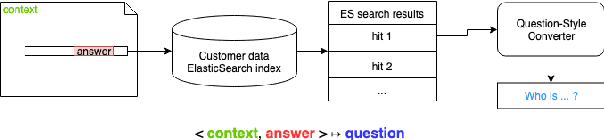


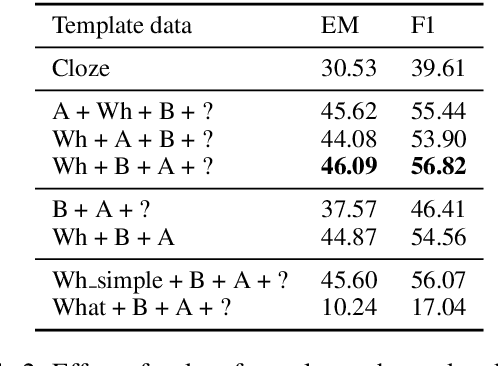
Question Answering (QA) is in increasing demand as the amount of information available online and the desire for quick access to this content grows. A common approach to QA has been to fine-tune a pretrained language model on a task-specific labeled dataset. This paradigm, however, relies on scarce, and costly to obtain, large-scale human-labeled data. We propose an unsupervised approach to training QA models with generated pseudo-training data. We show that generating questions for QA training by applying a simple template on a related, retrieved sentence rather than the original context sentence improves downstream QA performance by allowing the model to learn more complex context-question relationships. Training a QA model on this data gives a relative improvement over a previous unsupervised model in F1 score on the SQuAD dataset by about 14%, and 20% when the answer is a named entity, achieving state-of-the-art performance on SQuAD for unsupervised QA.
TRANS-BLSTM: Transformer with Bidirectional LSTM for Language Understanding
Mar 16, 2020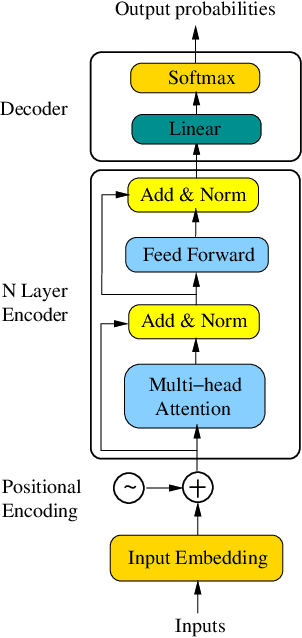

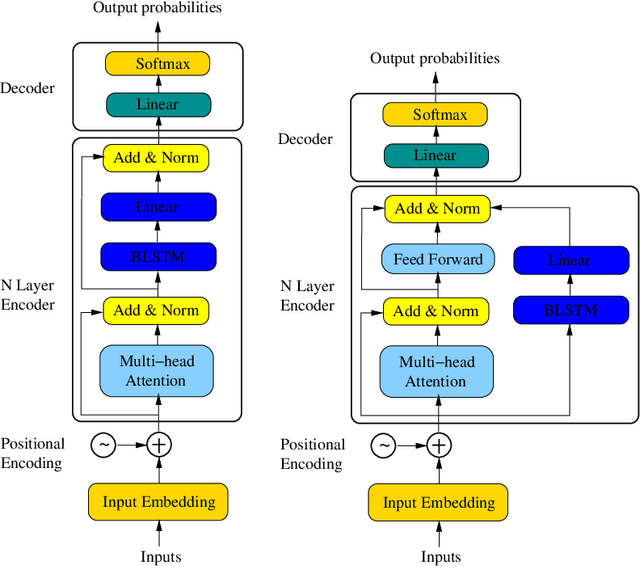

Bidirectional Encoder Representations from Transformers (BERT) has recently achieved state-of-the-art performance on a broad range of NLP tasks including sentence classification, machine translation, and question answering. The BERT model architecture is derived primarily from the transformer. Prior to the transformer era, bidirectional Long Short-Term Memory (BLSTM) has been the dominant modeling architecture for neural machine translation and question answering. In this paper, we investigate how these two modeling techniques can be combined to create a more powerful model architecture. We propose a new architecture denoted as Transformer with BLSTM (TRANS-BLSTM) which has a BLSTM layer integrated to each transformer block, leading to a joint modeling framework for transformer and BLSTM. We show that TRANS-BLSTM models consistently lead to improvements in accuracy compared to BERT baselines in GLUE and SQuAD 1.1 experiments. Our TRANS-BLSTM model obtains an F1 score of 94.01% on the SQuAD 1.1 development dataset, which is comparable to the state-of-the-art result.
Who did They Respond to? Conversation Structure Modeling using Masked Hierarchical Transformer
Nov 25, 2019
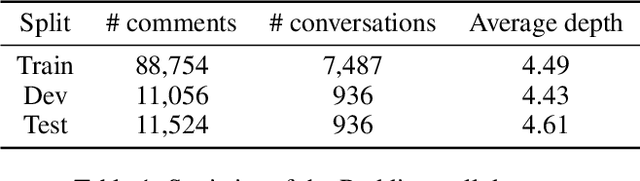
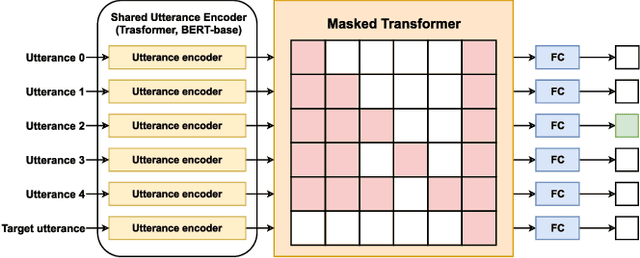
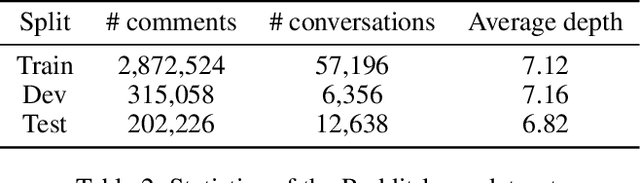
Conversation structure is useful for both understanding the nature of conversation dynamics and for providing features for many downstream applications such as summarization of conversations. In this work, we define the problem of conversation structure modeling as identifying the parent utterance(s) to which each utterance in the conversation responds to. Previous work usually took a pair of utterances to decide whether one utterance is the parent of the other. We believe the entire ancestral history is a very important information source to make accurate prediction. Therefore, we design a novel masking mechanism to guide the ancestor flow, and leverage the transformer model to aggregate all ancestors to predict parent utterances. Our experiments are performed on the Reddit dataset (Zhang, Culbertson, and Paritosh 2017) and the Ubuntu IRC dataset (Kummerfeld et al. 2019). In addition, we also report experiments on a new larger corpus from the Reddit platform and release this dataset. We show that the proposed model, that takes into account the ancestral history of the conversation, significantly outperforms several strong baselines including the BERT model on all datasets
Universal Text Representation from BERT: An Empirical Study
Oct 23, 2019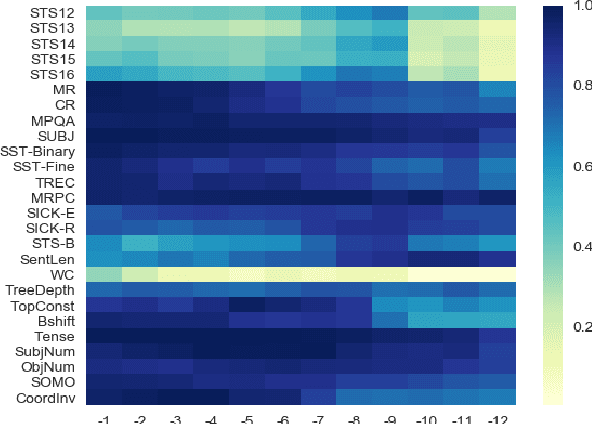
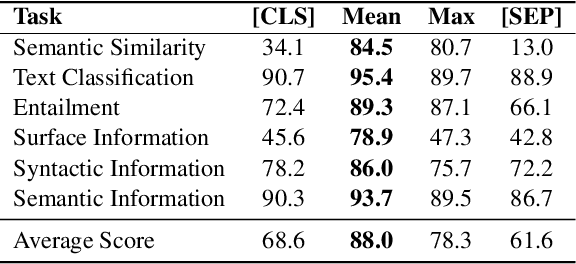
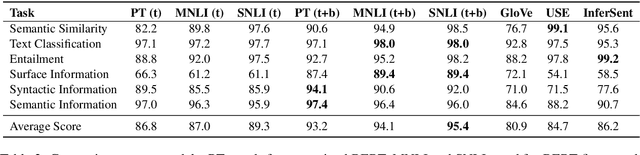
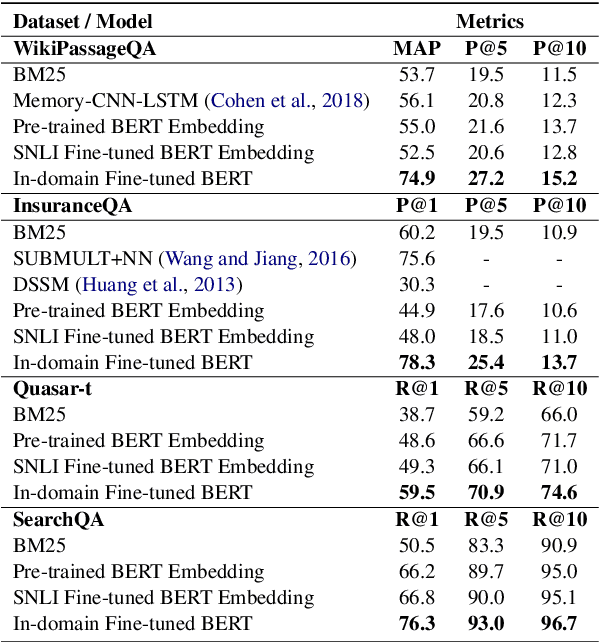
We present a systematic investigation of layer-wise BERT activations for general-purpose text representations to understand what linguistic information they capture and how transferable they are across different tasks. Sentence-level embeddings are evaluated against two state-of-the-art models on downstream and probing tasks from SentEval, while passage-level embeddings are evaluated on four question-answering (QA) datasets under a learning-to-rank problem setting. Embeddings from the pre-trained BERT model perform poorly in semantic similarity and sentence surface information probing tasks. Fine-tuning BERT on natural language inference data greatly improves the quality of the embeddings. Combining embeddings from different BERT layers can further boost performance. BERT embeddings outperform BM25 baseline significantly on factoid QA datasets at the passage level, but fail to perform better than BM25 on non-factoid datasets. For all QA datasets, there is a gap between embedding-based method and in-domain fine-tuned BERT (we report new state-of-the-art results on two datasets), which suggests deep interactions between question and answer pairs are critical for those hard tasks.
Multi-passage BERT: A Globally Normalized BERT Model for Open-domain Question Answering
Oct 02, 2019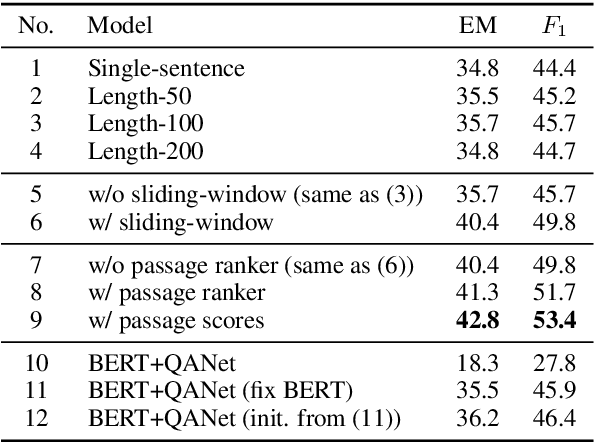
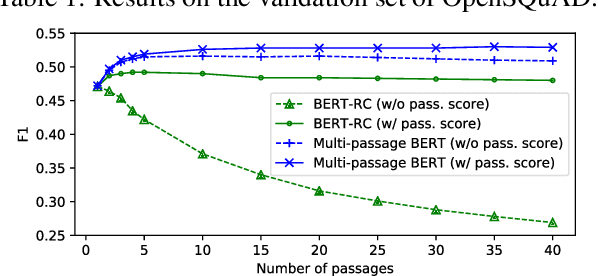
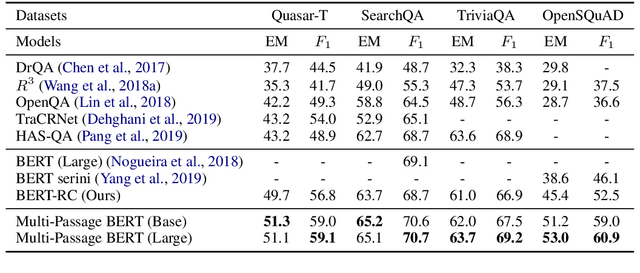
BERT model has been successfully applied to open-domain QA tasks. However, previous work trains BERT by viewing passages corresponding to the same question as independent training instances, which may cause incomparable scores for answers from different passages. To tackle this issue, we propose a multi-passage BERT model to globally normalize answer scores across all passages of the same question, and this change enables our QA model find better answers by utilizing more passages. In addition, we find that splitting articles into passages with the length of 100 words by sliding window improves performance by 4%. By leveraging a passage ranker to select high-quality passages, multi-passage BERT gains additional 2%. Experiments on four standard benchmarks showed that our multi-passage BERT outperforms all state-of-the-art models on all benchmarks. In particular, on the OpenSQuAD dataset, our model gains 21.4% EM and 21.5% $F_1$ over all non-BERT models, and 5.8% EM and 6.5% $F_1$ over BERT-based models.