 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Use Reinforcement Learning to Facilitate Future Electricity Market Design? Part 2: Method and Applications
May 12, 2023This two-part paper develops a paradigmatic theory and detailed methods of the joint electricity market design using reinforcement-learning (RL)-based simulation. In Part 2, this theory is further demonstrated by elaborating detailed methods of designing an electricity spot market (ESM), together with a reserved capacity product (RC) in the ancillary service market (ASM) and a virtual bidding (VB) product in the financial market (FM). Following the theory proposed in Part 1, firstly, market design options in the joint market are specified. Then, the Markov game model is developed, in which we show how to incorporate market design options and uncertain risks in model formulation. A multi-agent policy proximal optimization (MAPPO) algorithm is elaborated, as a practical implementation of the generalized market simulation method developed in Part 1. Finally, the case study demonstrates how to pick the best market design options by using some of the market operation performance indicators proposed in Part 1, based on the simulation results generated by implementing the MAPPO algorithm. The impacts of different market design options on market participants' bidding strategy preference are also discussed.
Fast Event-based Double Integral for Real-time Robotics
May 10, 2023Motion deblurring is a critical ill-posed problem that is important in many vision-based robotics applications. The recently proposed event-based double integral (EDI) provides a theoretical framework for solving the deblurring problem with the event camera and generating clear images at high frame-rate. However, the original EDI is mainly designed for offline computation and does not support real-time requirement in many robotics applications. In this paper, we propose the fast EDI, an efficient implementation of EDI that can achieve real-time online computation on single-core CPU devices, which is common for physical robotic platforms used in practice. In experiments, our method can handle event rates at as high as 13 million event per second in a wide variety of challenging lighting conditions. We demonstrate the benefit on multiple downstream real-time applications, including localization, visual tag detection, and feature matching.
Improving Knowledge Graph Entity Alignment with Graph Augmentation
Apr 28, 2023Entity alignment (EA) which links equivalent entities across different knowledge graphs (KGs) plays a crucial role in knowledge fusion. In recent years, graph neural networks (GNNs) have been successfully applied in many embedding-based EA methods. However, existing GNN-based methods either suffer from the structural heterogeneity issue that especially appears in the real KG distributions or ignore the heterogeneous representation learning for unseen (unlabeled) entities, which would lead the model to overfit on few alignment seeds (i.e., training data) and thus cause unsatisfactory alignment performance. To enhance the EA ability, we propose GAEA, a novel EA approach based on graph augmentation. In this model, we design a simple Entity-Relation (ER) Encoder to generate latent representations for entities via jointly modeling comprehensive structural information and rich relation semantics. Moreover, we use graph augmentation to create two graph views for margin-based alignment learning and contrastive entity representation learning, thus mitigating structural heterogeneity and further improving the model's alignment performance. Extensive experiments conducted on benchmark datasets demonstrate the effectiveness of our method.
RIS-Assisted Self-Interference Mitigation for In-Band Full-Duplex Transceivers
Nov 22, 2022The wireless in-band full-duplex (IBFD) technology can in theory double the system capacity over the conventional frequency division duplex (FDD) or time-division duplex (TDD) alternatives. But the strong self-interference of the IBFD can cause excessive quantization noise in the analog-to-digital converters (ADC), which represents the hurdle for its real implementation. In this paper, we consider employing a reconfigurable intelligent surface (RIS) for IBFD communications. While the BS transmits and receives the signals to and from the users simultaneously on the same frequency band, it can adjust the reflection coefficients of the RIS to configure the wireless channel so that the self-interference of the BS is sufficiently mitigated in the propagation domain. Taking the impact of the quantization noise into account, we propose to jointly design the downlink (DL) precoding matrix and the RIS coefficients to maximize the sum of uplink (UL) and DL rates. The effectiveness of the proposed RIS-assisted in-band full-duplex (RAIBFD) system is verified by simulation studies, even taking into considerations that the phases of the RIS have only finite resolution.
Zero-shot stance detection based on cross-domain feature enhancement by contrastive learning
Oct 07, 2022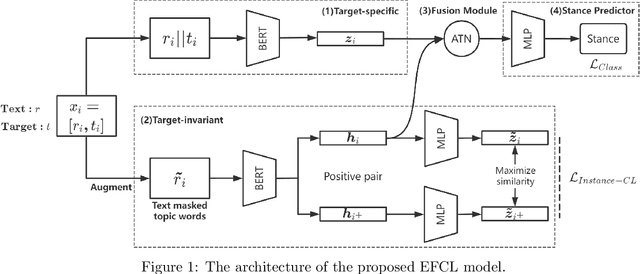
Zero-shot stance detection is challenging because it requires detecting the stance of previously unseen targets in the inference phase. The ability to learn transferable target-invariant features is critical for zero-shot stance detection. In this work, we propose a stance detection approach that can efficiently adapt to unseen targets, the core of which is to capture target-invariant syntactic expression patterns as transferable knowledge. Specifically, we first augment the data by masking the topic words of sentences, and then feed the augmented data to an unsupervised contrastive learning module to capture transferable features. Then, to fit a specific target, we encode the raw texts as target-specific features. Finally, we adopt an attention mechanism, which combines syntactic expression patterns with target-specific features to obtain enhanced features for predicting previously unseen targets. Experiments demonstrate that our model outperforms competitive baselines on four benchmark datasets.
Adversarial Learning-based Stance Classifier for COVID-19-related Health Policies
Sep 13, 2022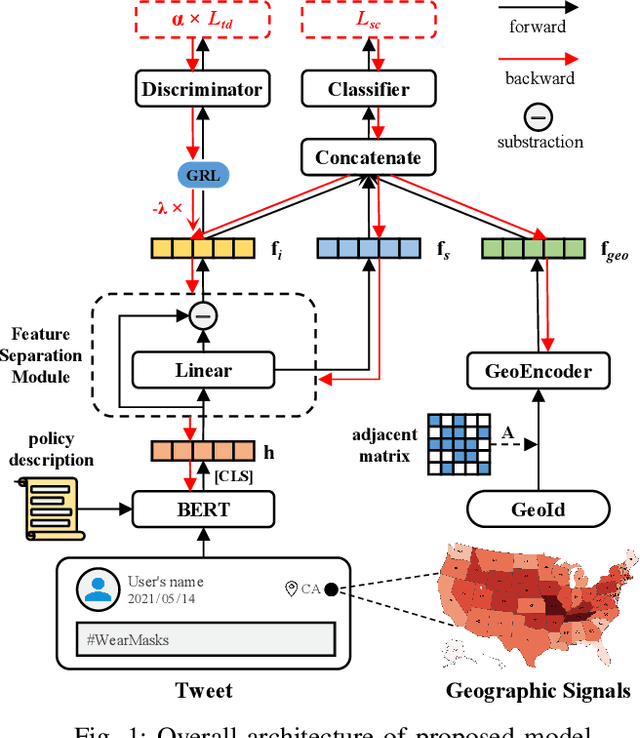
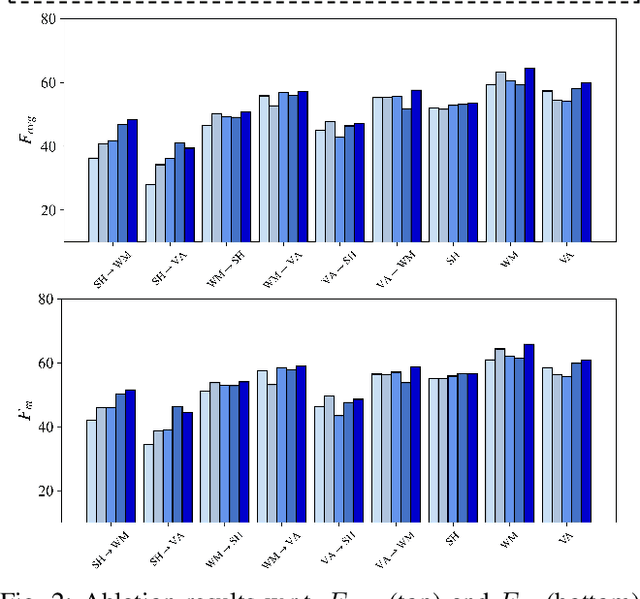
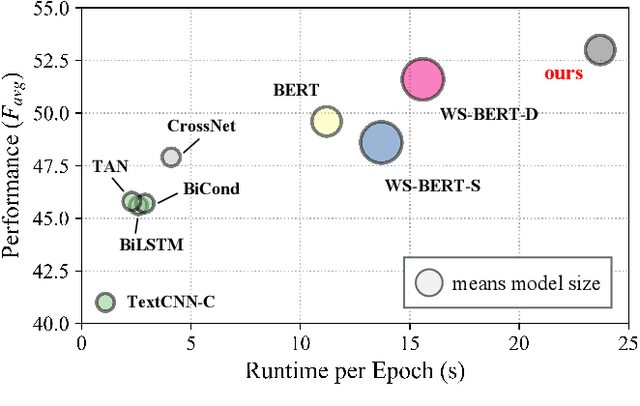
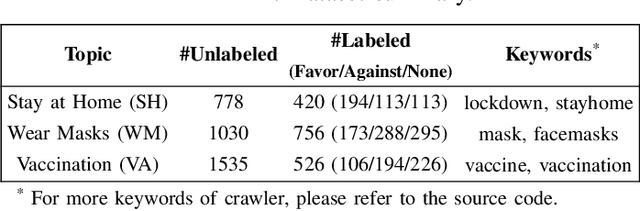
The ongoing COVID-19 pandemic has caused immeasurable losses for people worldwide. To contain the spread of virus and further alleviate the crisis, various health policies (e.g., stay-at-home orders) have been issued which spark heat discussion as users turn to share their attitudes on social media. In this paper, we consider a more realistic scenario on stance detection (i.e., cross-target and zero-shot settings) for the pandemic and propose an adversarial learning-based stance classifier to automatically identify the public attitudes toward COVID-19-related health policies. Specifically, we adopt adversarial learning which allows the model to train on a large amount of labeled data and capture transferable knowledge from source topics, so as to enable generalize to the emerging health policy with sparse labeled data. Meanwhile, a GeoEncoder is designed which encourages model to learn unobserved contextual factors specified by each region and represents them as non-text information to enhance model's deeper understanding. We evaluate the performance of a broad range of baselines in stance detection task for COVID-19-related policies, and experimental results show that our proposed method achieves state-of-the-art performance in both cross-target and zero-shot settings.
EpiGNN: Exploring Spatial Transmission with Graph Neural Network for Regional Epidemic Forecasting
Aug 23, 2022
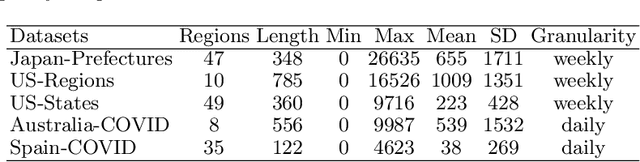
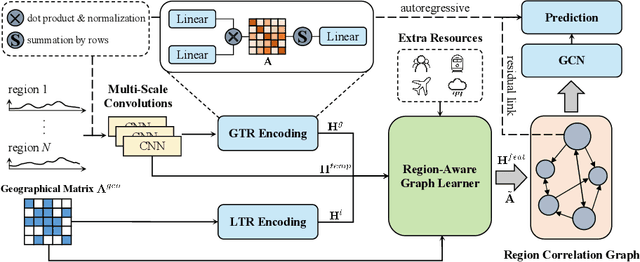
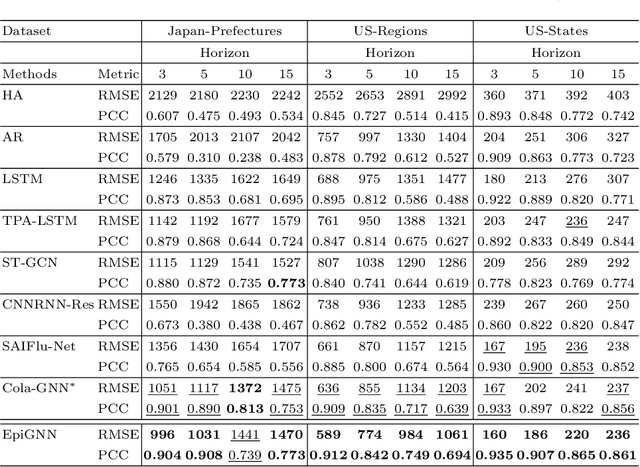
Epidemic forecasting is the key to effective control of epidemic transmission and helps the world mitigate the crisis that threatens public health. To better understand the transmission and evolution of epidemics, we propose EpiGNN, a graph neural network-based model for epidemic forecasting. Specifically, we design a transmission risk encoding module to characterize local and global spatial effects of regions in epidemic processes and incorporate them into the model. Meanwhile, we develop a Region-Aware Graph Learner (RAGL) that takes transmission risk, geographical dependencies, and temporal information into account to better explore spatial-temporal dependencies and makes regions aware of related regions' epidemic situations. The RAGL can also combine with external resources, such as human mobility, to further improve prediction performance. Comprehensive experiments on five real-world epidemic-related datasets (including influenza and COVID-19) demonstrate the effectiveness of our proposed method and show that EpiGNN outperforms state-of-the-art baselines by 9.48% in RMSE.
Inter- and Intra-Series Embeddings Fusion Network for Epidemiological Forecasting
Aug 23, 2022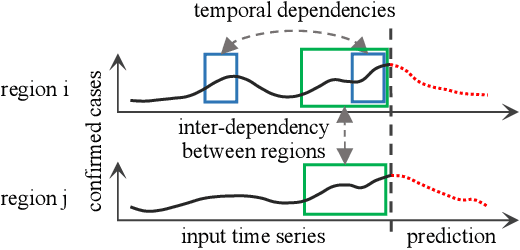
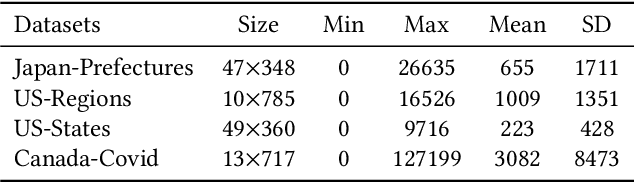
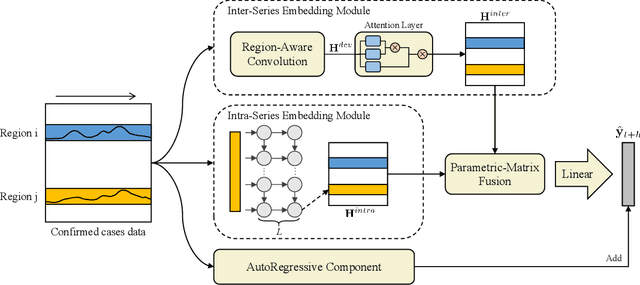
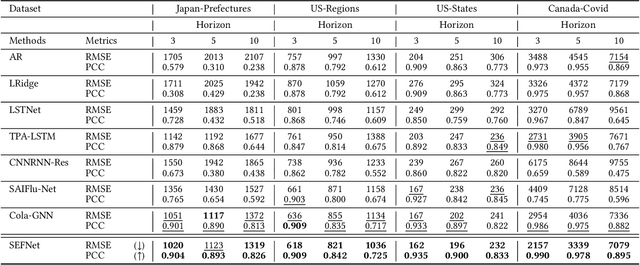
The accurate forecasting of infectious epidemic diseases is the key to effective control of the epidemic situation in a region. Most existing methods ignore potential dynamic dependencies between regions or the importance of temporal dependencies and inter-dependencies between regions for prediction. In this paper, we propose an Inter- and Intra-Series Embeddings Fusion Network (SEFNet) to improve epidemic prediction performance. SEFNet consists of two parallel modules, named Inter-Series Embedding Module and Intra-Series Embedding Module. In Inter-Series Embedding Module, a multi-scale unified convolution component called Region-Aware Convolution is proposed, which cooperates with self-attention to capture dynamic dependencies between time series obtained from multiple regions. The Intra-Series Embedding Module uses Long Short-Term Memory to capture temporal relationships within each time series. Subsequently, we learn the influence degree of two embeddings and fuse them with the parametric-matrix fusion method. To further improve the robustness, SEFNet also integrates a traditional autoregressive component in parallel with nonlinear neural networks. Experiments on four real-world epidemic-related datasets show SEFNet is effective and outperforms state-of-the-art baselines.
Aesthetics Driven Autonomous Time-Lapse Photography Generation by Virtual and Real Robots
Aug 22, 2022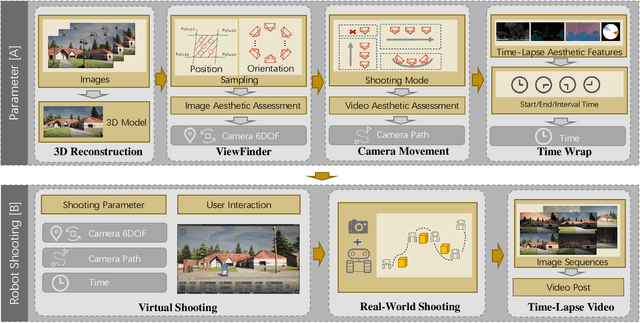
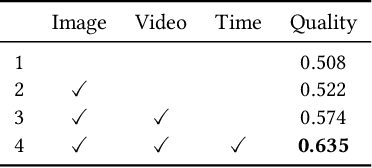

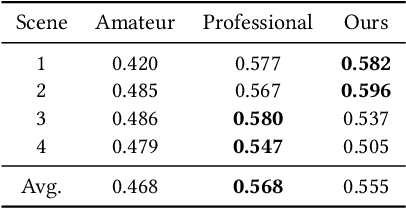
Time-lapse photography is employed in movies and promotional films because it can reflect the passage of time in a short time and strengthen the visual attraction. However, since it takes a long time and requires the stable shooting, it is a great challenge for the photographer. In this article, we propose a time-lapse photography system with virtual and real robots. To help users shoot time-lapse videos efficiently, we first parameterize the time-lapse photography and propose a parameter optimization method. For different parameters, different aesthetic models, including image and video aesthetic quality assessment networks, are used to generate optimal parameters. Then we propose a time-lapse photography interface to facilitate users to view and adjust parameters and use virtual robots to conduct virtual photography in a three-dimensional scene. The system can also export the parameters and provide them to real robots so that the time-lapse videos can be filmed in the real world. In addition, we propose a time-lapse photography aesthetic assessment method that can automatically evaluate the aesthetic quality of time-lapse video. The experimental results show that our method can efficiently obtain the time-lapse videos. We also conduct a user study. The results show that our system has the similar effect as professional photographers and is more efficient.
Applications of Reinforcement Learning in Deregulated Power Market: A Comprehensive Review
May 07, 2022



The increasing penetration of renewable generations, along with the deregulation and marketization of power industry, promotes the transformation of power market operation paradigms. The optimal bidding strategy and dispatching methodology under these new paradigms are prioritized concerns for both market participants and power system operators, with obstacles of uncertain characteristics, computational efficiency, as well as requirements of hyperopic decision-making. To tackle these problems, the Reinforcement Learning (RL), as an emerging machine learning technique with advantages compared with conventional optimization tools, is playing an increasingly significant role in both academia and industry. This paper presents a comprehensive review of RL applications in deregulated power market operation including bidding and dispatching strategy optimization, based on more than 150 carefully selected literatures. For each application, apart from a paradigmatic summary of generalized methodology, in-depth discussions of applicability and obstacles while deploying RL techniques are also provided. Finally, some RL techniques that have great potentiality to be deployed in bidding and dispatching problems are recommended and discussed.