 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-based Pre-trained Model for Personality and Interpersonal Reactivity Prediction
Mar 23, 2022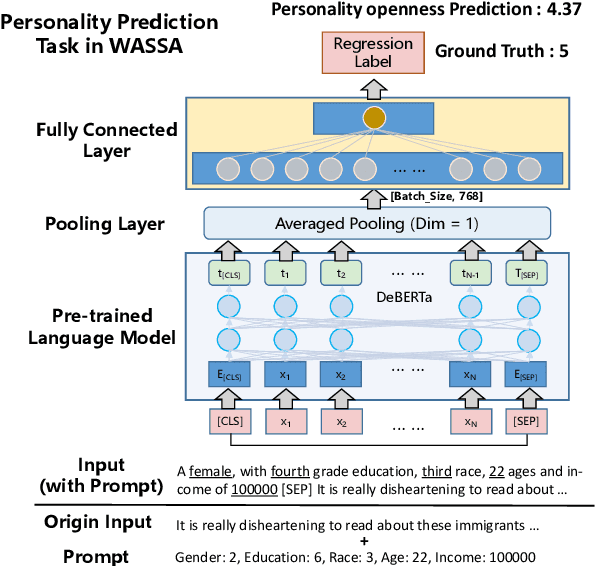
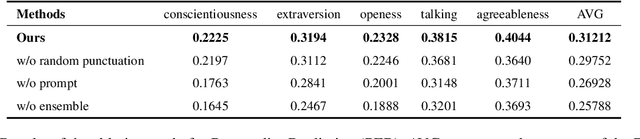
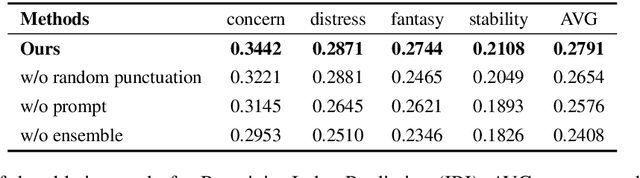

This paper describes the LingJing team's method to the Workshop on Computational Approaches to Subjectivity, Sentiment & Social Media Analysis (WASSA) 2022 shared task on Personality Prediction (PER) and Reactivity Index Prediction (IRI). In this paper, we adopt the prompt-based method with the pre-trained language model to accomplish these tasks. Specifically, the prompt is designed to provide the extra knowledge for enhancing the pre-trained model. Data augmentation and model ensemble are adopted for obtaining better results. Extensive experiments are performed, which shows the effectiveness of the proposed method. On the final submission, our system achieves a Pearson Correlation Coefficient of 0.2301 and 0.2546 on Track 3 and Track 4 respectively. We ranked Top-1 on both sub-tasks.
Hybrid Pixel-Unshuffled Network for Lightweight Image Super-Resolution
Mar 16, 2022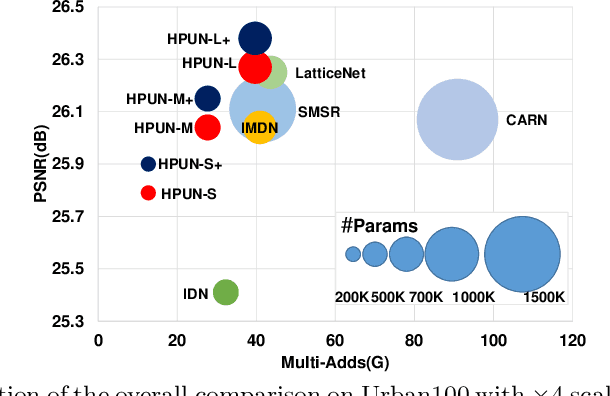
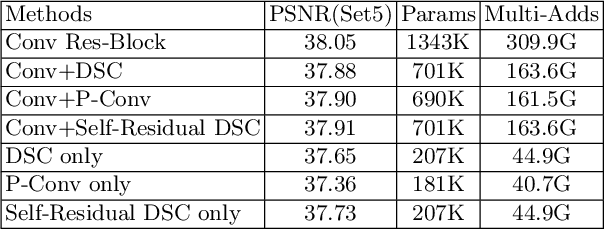

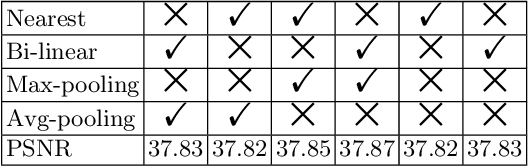
Convolutional neural network (CNN) has achieved great success on image super-resolution (SR). However, most deep CNN-based SR models take massive computations to obtain high performance. Downsampling features for multi-resolution fusion is an efficient and effective way to improve the performance of visual recognition. Still, it is counter-intuitive in the SR task, which needs to project a low-resolution input to high-resolution. In this paper, we propose a novel Hybrid Pixel-Unshuffled Network (HPUN) by introducing an efficient and effective downsampling module into the SR task. The network contains pixel-unshuffled downsampling and Self-Residual Depthwise Separable Convolutions. Specifically, we utilize pixel-unshuffle operation to downsample the input features and use grouped convolution to reduce the channels. Besides, we enhance the depthwise convolution's performance by adding the input feature to its output. Experiments on benchmark datasets show that our HPUN achieves and surpasses the state-of-the-art reconstruction performance with fewer parameters and computation costs.
PSG: Prompt-based Sequence Generation for Acronym Extraction
Dec 09, 2021
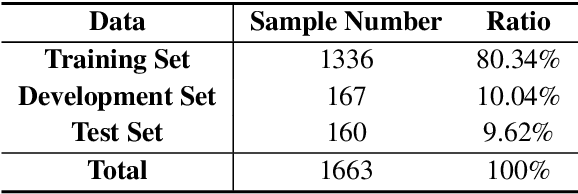
Acronym extraction aims to find acronyms (i.e., short-forms) and their meanings (i.e., long-forms) from the documents, which is important for scientific document understanding (SDU@AAAI-22) tasks. Previous works are devoted to modeling this task as a paragraph-level sequence labeling problem. However, it lacks the effective use of the external knowledge, especially when the datasets are in a low-resource setting. Recently, the prompt-based method with the vast pre-trained language model can significantly enhance the performance of the low-resourced downstream tasks. In this paper, we propose a Prompt-based Sequence Generation (PSG) method for the acronym extraction task. Specifically, we design a template for prompting the extracted acronym texts with auto-regression. A position extraction algorithm is designed for extracting the position of the generated answers. The results on the acronym extraction of Vietnamese and Persian in a low-resource setting show that the proposed method outperforms all other competitive state-of-the-art (SOTA) methods.
SimCLAD: A Simple Framework for Contrastive Learning of Acronym Disambiguation
Dec 09, 2021
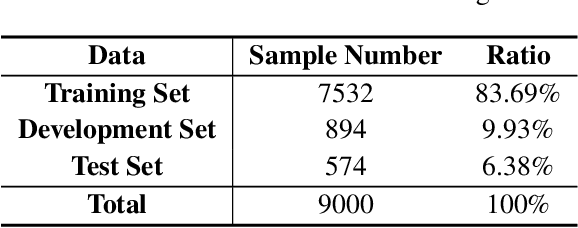
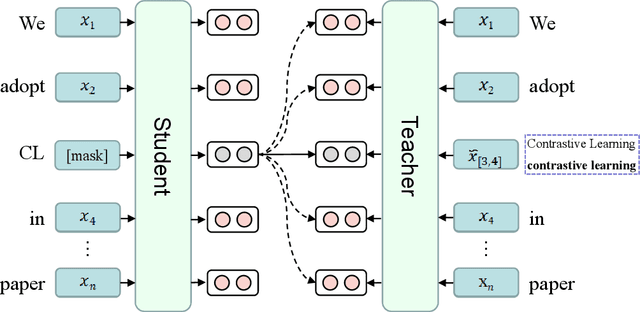
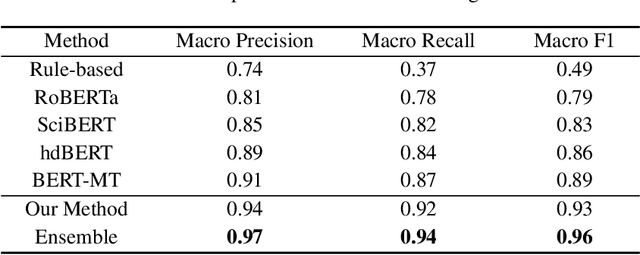
Acronym disambiguation means finding the correct meaning of an ambiguous acronym from the dictionary in a given sentence, which is one of the key points for scientific document understanding (SDU@AAAI-22). Recently, many attempts have tried to solve this problem via fine-tuning the pre-trained masked language models (MLMs) in order to obtain a better acronym representation. However, the acronym meaning is varied under different contexts, whose corresponding phrase representation mapped in different directions lacks discrimination in the entire vector space. Thus, the original representations of the pre-trained MLMs are not ideal for the acronym disambiguation task. In this paper, we propose a Simple framework for Contrastive Learning of Acronym Disambiguation (SimCLAD) method to better understand the acronym meanings. Specifically, we design a continual contrastive pre-training method that enhances the pre-trained model's generalization ability by learning the phrase-level contrastive distributions between true meaning and ambiguous phrases. The results on the acronym disambiguation of the scientific domain in English show that the proposed method outperforms all other competitive state-of-the-art (SOTA) methods.
Hybrid Mutimodal Fusion for Dimensional Emotion Recognition
Oct 16, 2021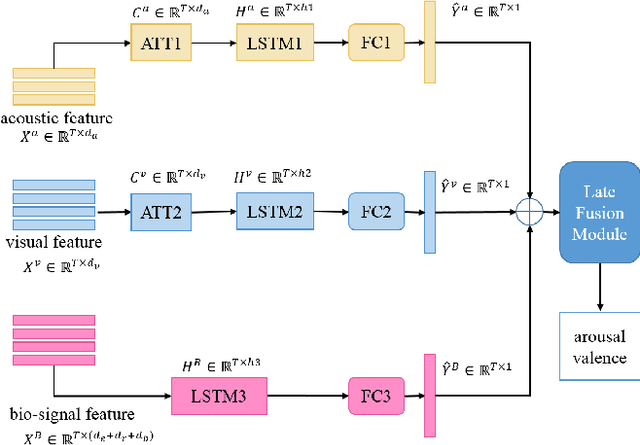
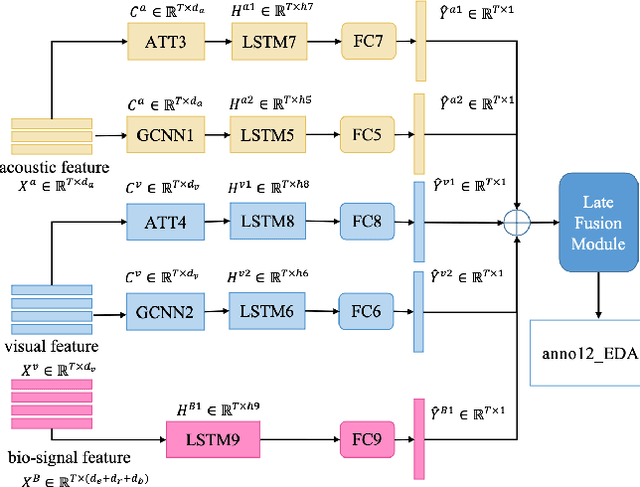
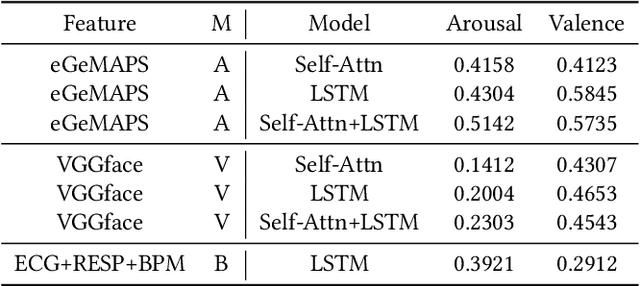
In this paper, we extensively present our solutions for the MuSe-Stress sub-challenge and the MuSe-Physio sub-challenge of Multimodal Sentiment Challenge (MuSe) 2021. The goal of MuSe-Stress sub-challenge is to predict the level of emotional arousal and valence in a time-continuous manner from audio-visual recordings and the goal of MuSe-Physio sub-challenge is to predict the level of psycho-physiological arousal from a) human annotations fused with b) galvanic skin response (also known as Electrodermal Activity (EDA)) signals from the stressed people. The Ulm-TSST dataset which is a novel subset of the audio-visual textual Ulm-Trier Social Stress dataset that features German speakers in a Trier Social Stress Test (TSST) induced stress situation is used in both sub-challenges. For the MuSe-Stress sub-challenge, we highlight our solutions in three aspects: 1) the audio-visual features and the bio-signal features are used for emotional state recognition. 2) the Long Short-Term Memory (LSTM) with the self-attention mechanism is utilized to capture complex temporal dependencies within the feature sequences. 3) the late fusion strategy is adopted to further boost the model's recognition performance by exploiting complementary information scattered across multimodal sequences. Our proposed model achieves CCC of 0.6159 and 0.4609 for valence and arousal respectively on the test set, which both rank in the top 3. For the MuSe-Physio sub-challenge, we first extract the audio-visual features and the bio-signal features from multiple modalities. Then, the LSTM module with the self-attention mechanism, and the Gated Convolutional Neural Networks (GCNN) as well as the LSTM network are utilized for modeling the complex temporal dependencies in the sequence. Finally, the late fusion strategy is used. Our proposed method also achieves CCC of 0.5412 on the test set, which ranks in the top 3.
Sign Language Recognition via Skeleton-Aware Multi-Model Ensemble
Oct 12, 2021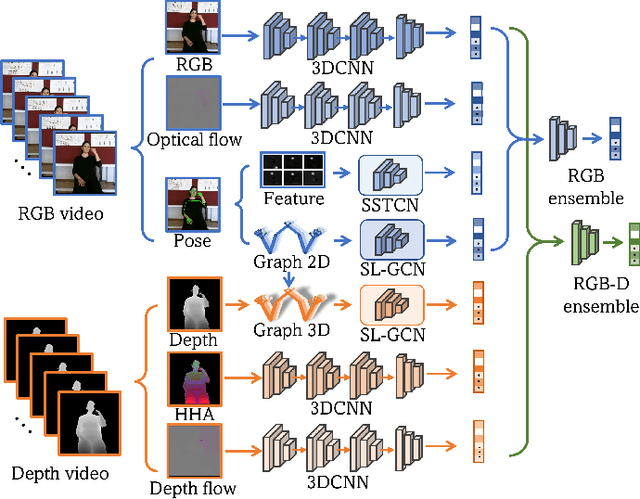
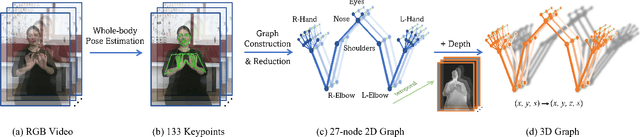
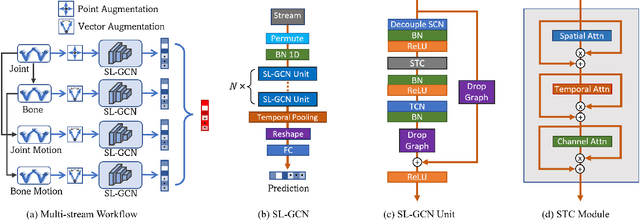
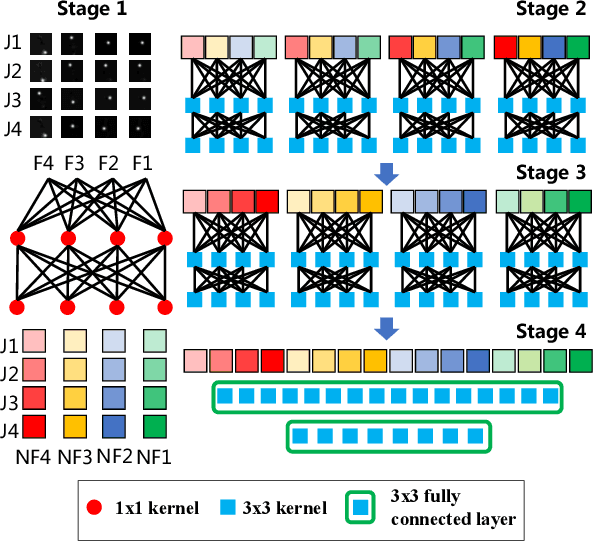
Sign language is commonly used by deaf or mute people to communicate but requires extensive effort to master. It is usually performed with the fast yet delicate movement of hand gestures, body posture, and even facial expressions. Current Sign Language Recognition (SLR) methods usually extract features via deep neural networks and suffer overfitting due to limited and noisy data. Recently, skeleton-based action recognition has attracted increasing attention due to its subject-invariant and background-invariant nature, whereas skeleton-based SLR is still under exploration due to the lack of hand annotations. Some researchers have tried to use off-line hand pose trackers to obtain hand keypoints and aid in recognizing sign language via recurrent neural networks. Nevertheless, none of them outperforms RGB-based approaches yet. To this end, we propose a novel Skeleton Aware Multi-modal Framework with a Global Ensemble Model (GEM) for isolated SLR (SAM-SLR-v2) to learn and fuse multi-modal feature representations towards a higher recognition rate. Specifically, we propose a Sign Language Graph Convolution Network (SL-GCN) to model the embedded dynamics of skeleton keypoints and a Separable Spatial-Temporal Convolution Network (SSTCN) to exploit skeleton features. The skeleton-based predictions are fused with other RGB and depth based modalities by the proposed late-fusion GEM to provide global information and make a faithful SLR prediction. Experiments on three isolated SLR datasets demonstrate that our proposed SAM-SLR-v2 framework is exceedingly effective and achieves state-of-the-art performance with significant margins. Our code will be available at https://github.com/jackyjsy/SAM-SLR-v2
Grassmannian Graph-attentional Landmark Selection for Domain Adaptation
Sep 07, 2021


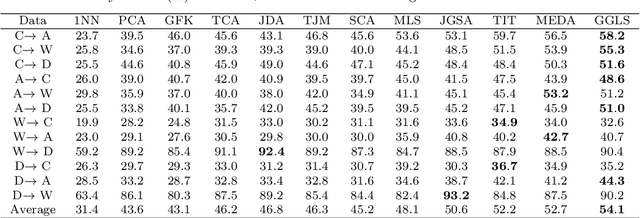
Domain adaptation aims to leverage information from the source domain to improve the classification performance in the target domain. It mainly utilizes two schemes: sample reweighting and feature matching. While the first scheme allocates different weights to individual samples, the second scheme matches the feature of two domains using global structural statistics. The two schemes are complementary with each other, which are expected to jointly work for robust domain adaptation. Several methods combine the two schemes, but the underlying relationship of samples is insufficiently analyzed due to the neglect of the hierarchy of samples and the geometric properties between samples. To better combine the advantages of the two schemes, we propose a Grassmannian graph-attentional landmark selection (GGLS) framework for domain adaptation. GGLS presents a landmark selection scheme using attention-induced neighbors of the graphical structure of samples and performs distribution adaptation and knowledge adaptation over Grassmann manifold. the former treats the landmarks of each sample differently, and the latter avoids feature distortion and achieves better geometric properties. Experimental results on different real-world cross-domain visual recognition tasks demonstrate that GGLS provides better classification accuracies compared with state-of-the-art domain adaptation methods.
More but Correct: Generating Diversified and Entity-revised Medical Response
Aug 19, 2021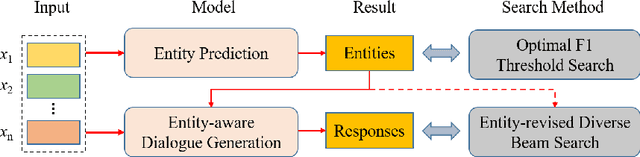
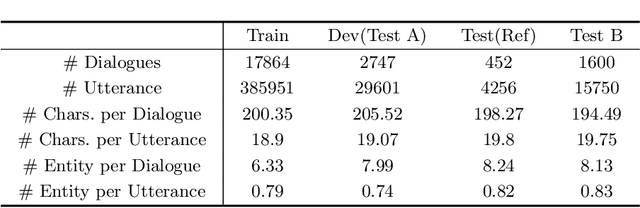
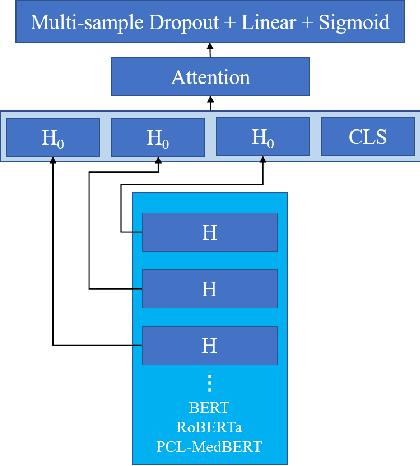
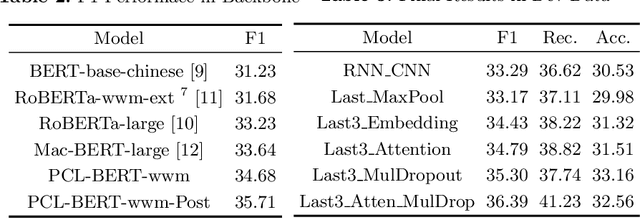
Medical Dialogue Generation (MDG) is intended to build a medical dialogue system for intelligent consultation, which can communicate with patients in real-time, thereby improving the efficiency of clinical diagnosis with broad application prospects. This paper presents our proposed framework for the Chinese MDG organized by the 2021 China conference on knowledge graph and semantic computing (CCKS) competition, which requires generating context-consistent and medically meaningful responses conditioned on the dialogue history. In our framework, we propose a pipeline system composed of entity prediction and entity-aware dialogue generation, by adding predicted entities to the dialogue model with a fusion mechanism, thereby utilizing information from different sources. At the decoding stage, we propose a new decoding mechanism named Entity-revised Diverse Beam Search (EDBS) to improve entity correctness and promote the length and quality of the final response. The proposed method wins both the CCKS and the International Conference on Learning Representations (ICLR) 2021 Workshop Machine Learning for Preventing and Combating Pandemics (MLPCP) Track 1 Entity-aware MED competitions, which demonstrate the practicality and effectiveness of our method.
Bilateral Personalized Dialogue Generation with Dynamic Persona-Aware Fusion
Jun 15, 2021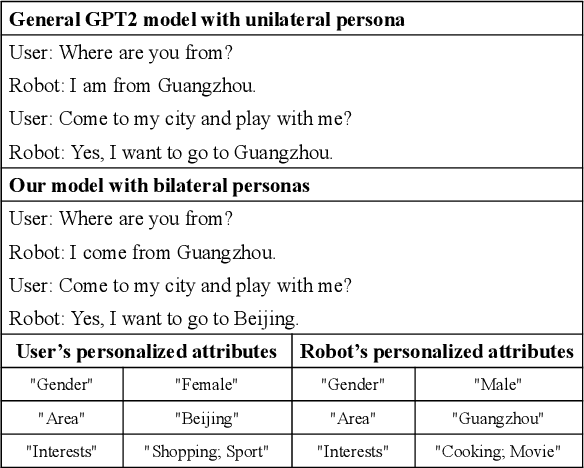
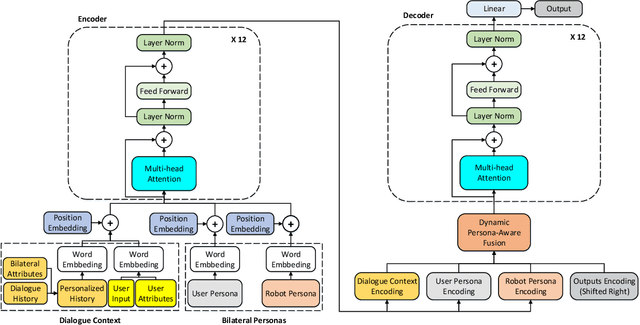
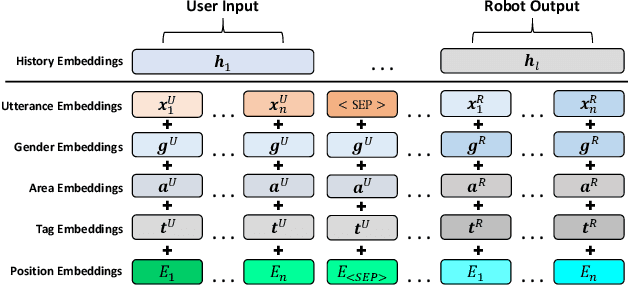
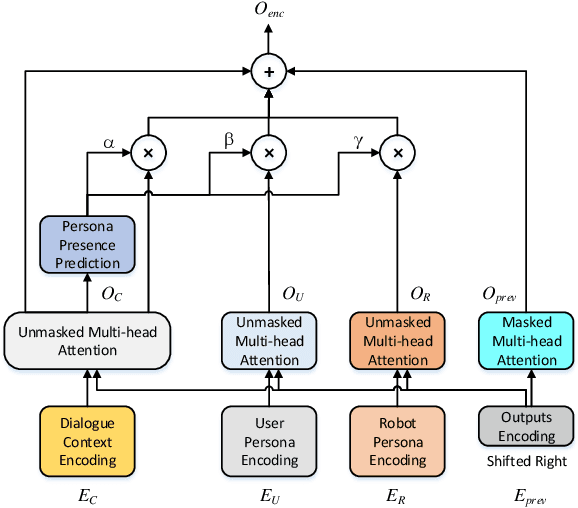
Generating personalized responses is one of the major challenges in natural human-robot interaction. Current researches in this field mainly focus on generating responses consistent with the robot's pre-assigned persona, while ignoring the user's persona. Such responses may be inappropriate or even offensive, which may lead to the bad user experience. Therefore, we propose a bilateral personalized dialogue generation (BPDG) method with dynamic persona-aware fusion via multi-task transfer learning to generate responses consistent with both personas. The proposed method aims to accomplish three learning tasks: 1) an encoder is trained with dialogue utterances added with corresponded personalized attributes and relative position (language model task), 2) a dynamic persona-aware fusion module predicts the persona presence to adaptively fuse the contextual and bilateral personas encodings (persona prediction task) and 3) a decoder generates natural, fluent and personalized responses (dialogue generation task). To make the generated responses more personalized and bilateral persona-consistent, the Conditional Mutual Information Maximum (CMIM) criterion is adopted to select the final response from the generated candidates. The experimental results show that the proposed method outperforms several state-of-the-art methods in terms of both automatic and manual evaluations.
Generating Relevant and Coherent Dialogue Responses using Self-separated Conditional Variational AutoEncoders
Jun 07, 2021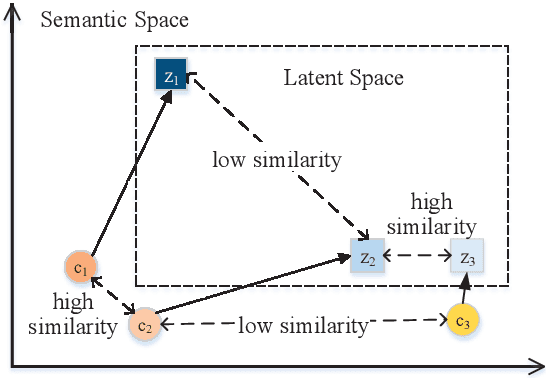
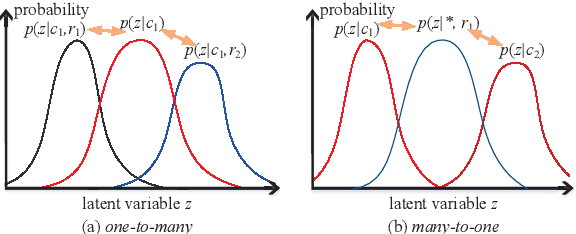
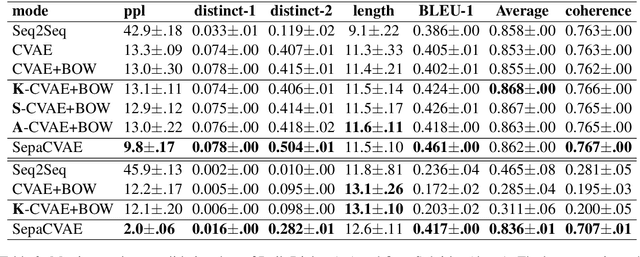
Conditional Variational AutoEncoder (CVAE) effectively increases the diversity and informativeness of responses in open-ended dialogue generation tasks through enriching the context vector with sampled latent variables. However, due to the inherent one-to-many and many-to-one phenomena in human dialogues, the sampled latent variables may not correctly reflect the contexts' semantics, leading to irrelevant and incoherent generated responses. To resolve this problem, we propose Self-separated Conditional Variational AutoEncoder (abbreviated as SepaCVAE) that introduces group information to regularize the latent variables, which enhances CVAE by improving the responses' relevance and coherence while maintaining their diversity and informativeness. SepaCVAE actively divides the input data into groups, and then widens the absolute difference between data pairs from distinct groups, while narrowing the relative distance between data pairs in the same group. Empirical results from automatic evaluation and detailed analysis demonstrate that SepaCVAE can significantly boost responses in well-established open-domain dialogue datasets.