 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVQA 2.0: Introducing Adversarial Samples into Fact-based Visual Question Answering
Mar 19, 2023The widely used Fact-based Visual Question Answering (FVQA) dataset contains visually-grounded questions that require information retrieval using common sense knowledge graphs to answer. It has been observed that the original dataset is highly imbalanced and concentrated on a small portion of its associated knowledge graph. We introduce FVQA 2.0 which contains adversarial variants of test questions to address this imbalance. We show that systems trained with the original FVQA train sets can be vulnerable to adversarial samples and we demonstrate an augmentation scheme to reduce this vulnerability without human annotations.
Schema-Guided Semantic Accuracy: Faithfulness in Task-Oriented Dialogue Response Generation
Jan 29, 2023Ensuring that generated utterances are faithful to dialogue actions is crucial for Task-Oriented Dialogue Response Generation. Slot Error Rate (SER) only partially measures generation quality in that it solely assesses utterances generated from non-categorical slots whose values are expected to be reproduced exactly. Utterances generated from categorical slots, which are more variable, are not assessed by SER. We propose Schema-Guided Semantic Accuracy (SGSAcc) to evaluate utterances generated from both categorical and non-categorical slots by recognizing textual entailment. We show that SGSAcc can be applied to evaluate utterances generated from a wide range of dialogue actions in the Schema Guided Dialogue (SGD) dataset with good agreement with human judgment. We also identify a previously overlooked weakness in generating faithful utterances from categorical slots in unseen domains. We show that prefix tuning applied to T5 generation can address this problem. We further build an ensemble of prefix-tuning and fine-tuning models that achieves the lowest SER reported and high SGSAcc on the SGD dataset.
Retrieval Augmented Visual Question Answering with Outside Knowledge
Oct 07, 2022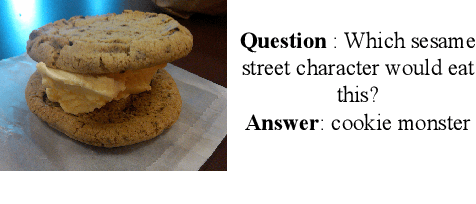
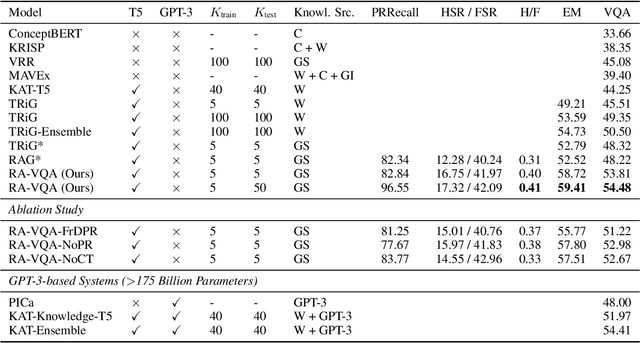
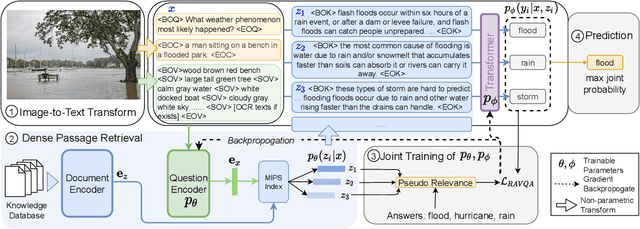

Outside-Knowledge Visual Question Answering (OK-VQA) is a challenging VQA task that requires retrieval of external knowledge to answer questions about images. Recent OK-VQA systems use Dense Passage Retrieval (DPR) to retrieve documents from external knowledge bases, such as Wikipedia, but with DPR trained separately from answer generation, introducing a potential limit on the overall system performance. Instead, we propose a joint training scheme which includes differentiable DPR integrated with answer generation so that the system can be trained in an end-to-end fashion. Our experiments show that our scheme outperforms recent OK-VQA systems with strong DPR for retrieval. We also introduce new diagnostic metrics to analyze how retrieval and generation interact. The strong retrieval ability of our model significantly reduces the number of retrieved documents needed in training, yielding significant benefits in answer quality and computation required for training.
Low-Resource Dense Retrieval for Open-Domain Question Answering: A Comprehensive Survey
Aug 05, 2022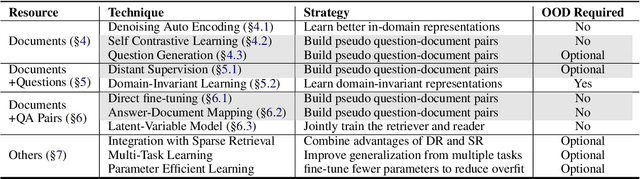
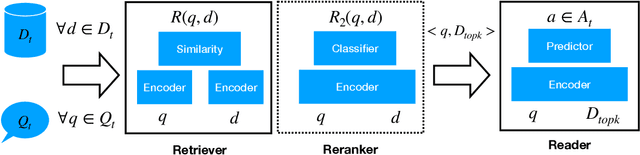

Dense retrieval (DR) approaches based on powerful pre-trained language models (PLMs) achieved significant advances and have become a key component for modern open-domain question-answering systems. However, they require large amounts of manual annotations to perform competitively, which is infeasible to scale. To address this, a growing body of research works have recently focused on improving DR performance under low-resource scenarios. These works differ in what resources they require for training and employ a diverse set of techniques. Understanding such differences is crucial for choosing the right technique under a specific low-resource scenario. To facilitate this understanding, we provide a thorough structured overview of mainstream techniques for low-resource DR. Based on their required resources, we divide the techniques into three main categories: (1) only documents are needed; (2) documents and questions are needed; and (3) documents and question-answer pairs are needed. For every technique, we introduce its general-form algorithm, highlight the open issues and pros and cons. Promising directions are outlined for future research.
The Devil is in the Details: On the Pitfalls of Vocabulary Selection in Neural Machine Translation
May 13, 2022
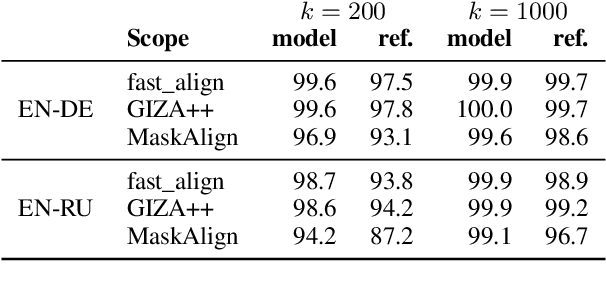
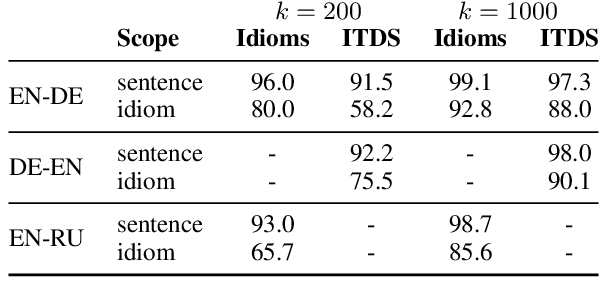
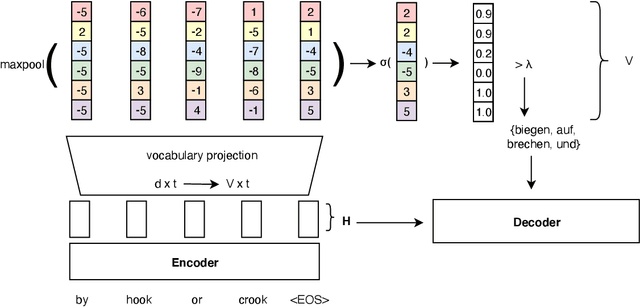
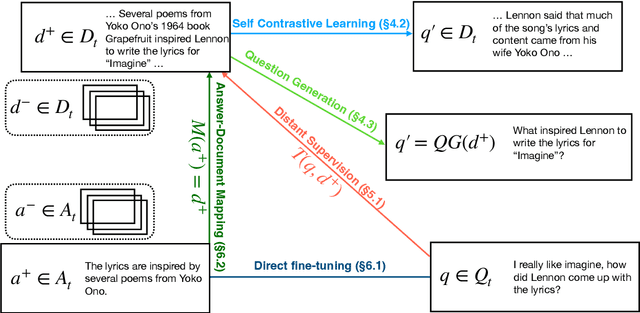
Vocabulary selection, or lexical shortlisting, is a well-known technique to improve latency of Neural Machine Translation models by constraining the set of allowed output words during inference. The chosen set is typically determined by separately trained alignment model parameters, independent of the source-sentence context at inference time. While vocabulary selection appears competitive with respect to automatic quality metrics in prior work, we show that it can fail to select the right set of output words, particularly for semantically non-compositional linguistic phenomena such as idiomatic expressions, leading to reduced translation quality as perceived by humans. Trading off latency for quality by increasing the size of the allowed set is often not an option in real-world scenarios. We propose a model of vocabulary selection, integrated into the neural translation model, that predicts the set of allowed output words from contextualized encoder representations. This restores translation quality of an unconstrained system, as measured by human evaluations on WMT newstest2020 and idiomatic expressions, at an inference latency competitive with alignment-based selection using aggressive thresholds, thereby removing the dependency on separately trained alignment models.
From Rewriting to Remembering: Common Ground for Conversational QA Models
Apr 08, 2022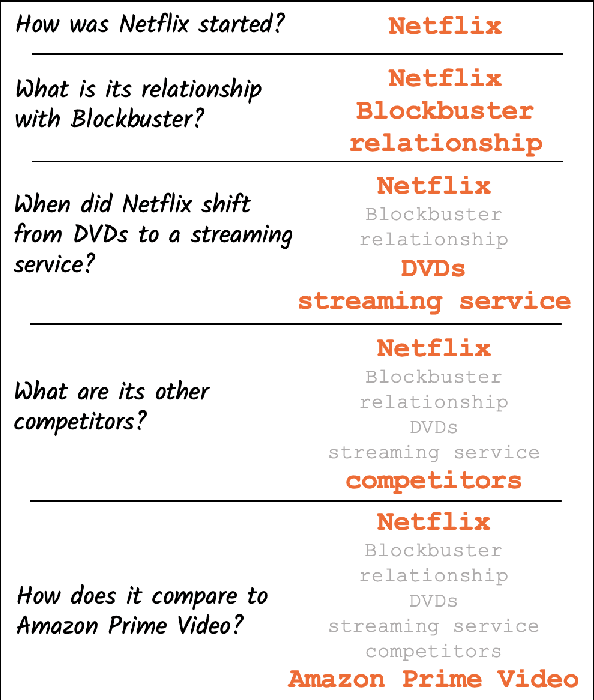
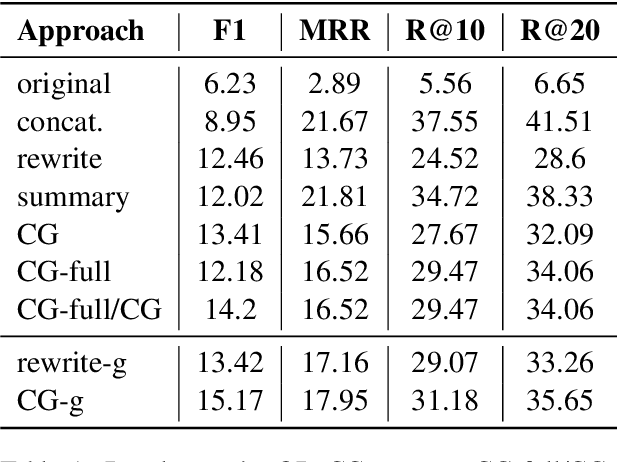


In conversational QA, models have to leverage information in previous turns to answer upcoming questions. Current approaches, such as Question Rewriting, struggle to extract relevant information as the conversation unwinds. We introduce the Common Ground (CG), an approach to accumulate conversational information as it emerges and select the relevant information at every turn. We show that CG offers a more efficient and human-like way to exploit conversational information compared to existing approaches, leading to improvements on Open Domain Conversational QA.
Transformer-Empowered Content-Aware Collaborative Filtering
Apr 02, 2022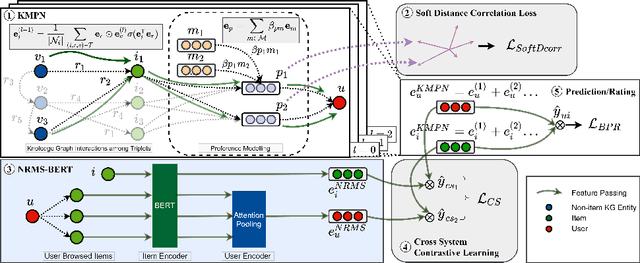
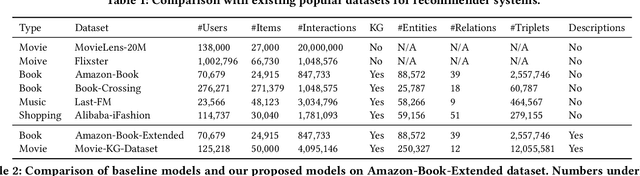
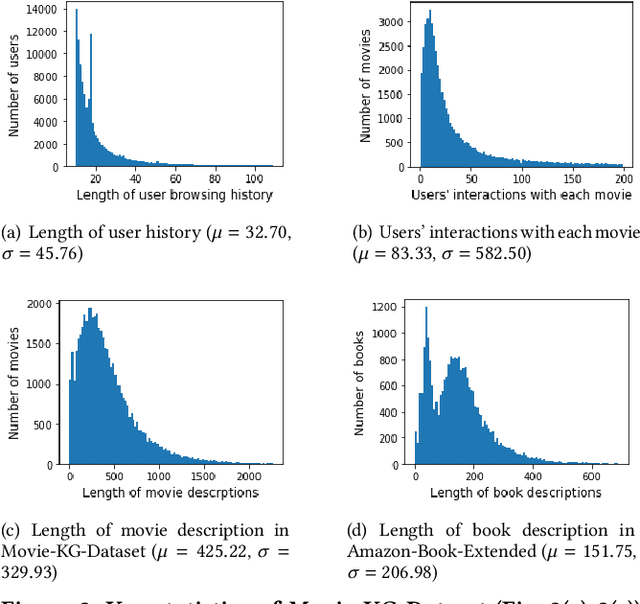
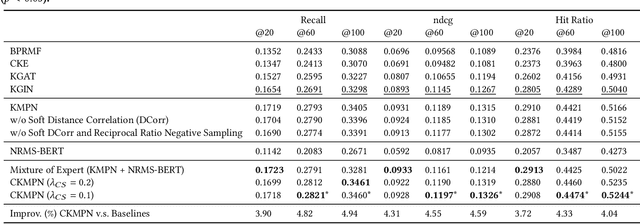
Knowledge graph (KG) based Collaborative Filtering is an effective approach to personalizing recommendation systems for relatively static domains such as movies and books, by leveraging structured information from KG to enrich both item and user representations. Motivated by the use of Transformers for understanding rich text in content-based filtering recommender systems, we propose Content-aware KG-enhanced Meta-preference Networks as a way to enhance collaborative filtering recommendation based on both structured information from KG as well as unstructured content features based on Transformer-empowered content-based filtering. To achieve this, we employ a novel training scheme, Cross-System Contrastive Learning, to address the inconsistency of the two very different systems and propose a powerful collaborative filtering model and a variant of the well-known NRMS system within this modeling framework. We also contribute to public domain resources through the creation of a large-scale movie-knowledge-graph dataset and an extension of the already public Amazon-Book dataset through incorporation of text descriptions crawled from external sources. We present experimental results showing that enhancing collaborative filtering with Transformer-based features derived from content-based filtering outperforms strong baseline systems, improving the ability of knowledge-graph-based collaborative filtering systems to exploit item content information.
Transferable Dialogue Systems and User Simulators
Jul 25, 2021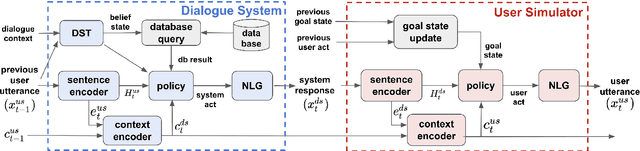
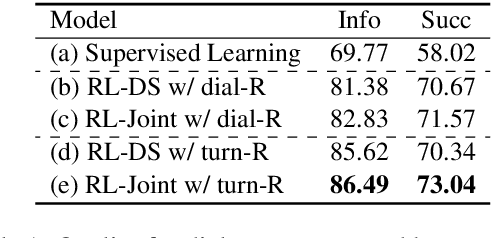
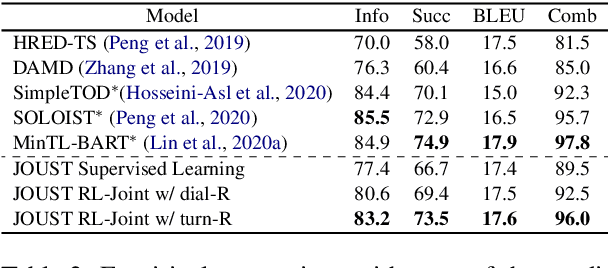
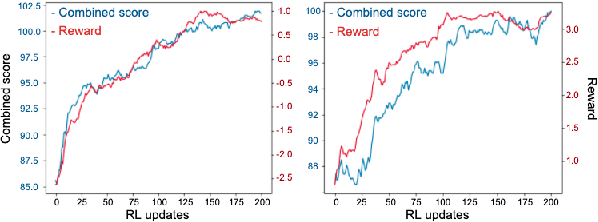
One of the difficulties in training dialogue systems is the lack of training data. We explore the possibility of creating dialogue data through the interaction between a dialogue system and a user simulator. Our goal is to develop a modelling framework that can incorporate new dialogue scenarios through self-play between the two agents. In this framework, we first pre-train the two agents on a collection of source domain dialogues, which equips the agents to converse with each other via natural language. With further fine-tuning on a small amount of target domain data, the agents continue to interact with the aim of improving their behaviors using reinforcement learning with structured reward functions. In experiments on the MultiWOZ dataset, two practical transfer learning problems are investigated: 1) domain adaptation and 2) single-to-multiple domain transfer. We demonstrate that the proposed framework is highly effective in bootstrapping the performance of the two agents in transfer learning. We also show that our method leads to improvements in dialogue system performance on complete datasets.
First the worst: Finding better gender translations during beam search
Apr 15, 2021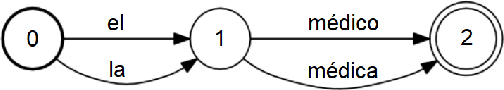
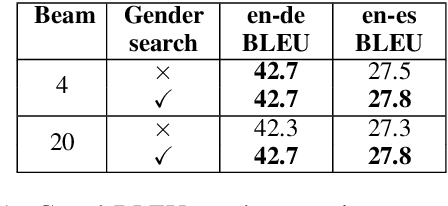


Neural machine translation inference procedures like beam search generate the most likely output under the model. This can exacerbate any demographic biases exhibited by the model. We focus on gender bias resulting from systematic errors in grammatical gender translation, which can lead to human referents being misrepresented or misgendered. Most approaches to this problem adjust the training data or the model. By contrast, we experiment with simply adjusting the inference procedure. We experiment with reranking nbest lists using gender features obtained automatically from the source sentence, and applying gender constraints while decoding to improve nbest list gender diversity. We find that a combination of these techniques allows large gains in WinoMT accuracy without requiring additional bilingual data or an additional NMT model.
Knowledge-Aware Graph-Enhanced GPT-2 for Dialogue State Tracking
Apr 09, 2021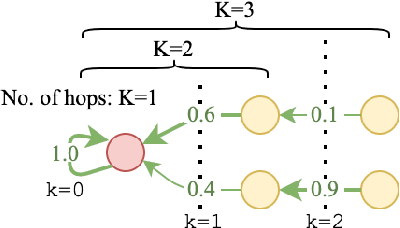
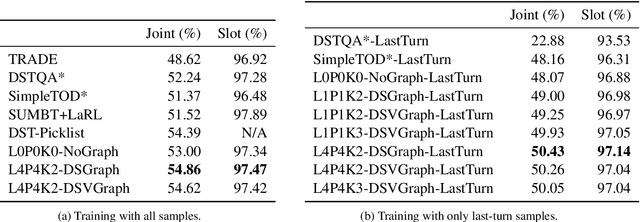
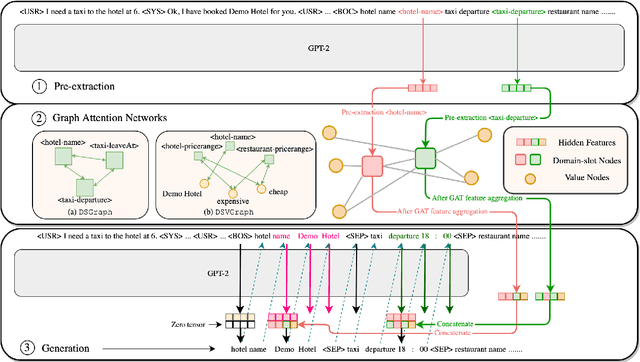

Dialogue State Tracking is a crucial part of multi-domain task-oriented dialogue systems, responsible for extracting information from user utterances. We present a novel architecture that utilizes the powerful generative model GPT-2 to generate slot values one by one causally, and at the same time utilizes Graph Attention Networks to enable inter-slot information exchanges, which exploits the inter-slot relations such as correlations. Our model achieves $54.86\%$ joint accuracy in MultiWOZ 2.0, and it retains a performance of up to $50.43\%$ in sparse supervision training, where only session-level annotations ($14.3\%$ of the full training set) are used. We conduct detailed analyses to demonstrate the significance of using graph models in this task, and show by experiments that the proposed graph modules indeed help to capture more inter-slot relations.