 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Distributional Bias in Multi-Round LLM Generation via KL-Optimized Fine-Tuning
Apr 07, 2026While the real world is inherently stochastic, Large Language Models (LLMs) are predominantly evaluated on single-round inference against fixed ground truths. In this work, we shift the lens to distribution alignment: assessing whether LLMs, when prompted repeatedly, can generate outputs that adhere to a desired target distribution, e.g. reflecting real-world statistics or a uniform distribution. We formulate distribution alignment using the attributes of gender, race, and sentiment within occupational contexts. Our empirical analysis reveals that off-the-shelf LLMs and standard alignment techniques, including prompt engineering and Direct Preference Optimization, fail to reliably control output distributions. To bridge this gap, we propose a novel fine-tuning framework that couples Steering Token Calibration with Semantic Alignment. We introduce a hybrid objective function combining Kullback-Leibler divergence to anchor the probability mass of latent steering tokens and Kahneman-Tversky Optimization to bind these tokens to semantically consistent responses. Experiments across six diverse datasets demonstrate that our approach significantly outperforms baselines, achieving precise distributional control in attribute generation tasks.
A Critical Look at Meta-evaluating Summarisation Evaluation Metrics
Sep 29, 2024Effective summarisation evaluation metrics enable researchers and practitioners to compare different summarisation systems efficiently. Estimating the effectiveness of an automatic evaluation metric, termed meta-evaluation, is a critically important research question. In this position paper, we review recent meta-evaluation practices for summarisation evaluation metrics and find that (1) evaluation metrics are primarily meta-evaluated on datasets consisting of examples from news summarisation datasets, and (2) there has been a noticeable shift in research focus towards evaluating the faithfulness of generated summaries. We argue that the time is ripe to build more diverse benchmarks that enable the development of more robust evaluation metrics and analyze the generalization ability of existing evaluation metrics. In addition, we call for research focusing on user-centric quality dimensions that consider the generated summary's communicative goal and the role of summarisation in the workflow.
COVID-SEE: Scientific Evidence Explorer for COVID-19 Related Research
Aug 18, 2020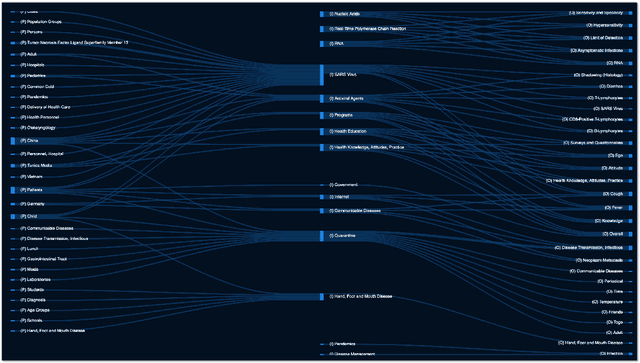
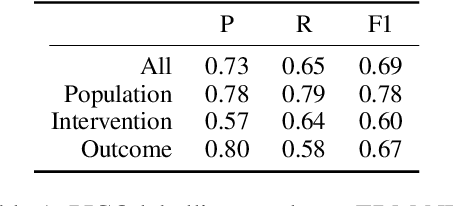

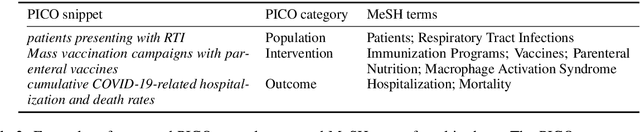
We present COVID-SEE, a system for medical literature discovery based on the concept of information exploration, which builds on several distinct text analysis and natural language processing methods to structure and organise information in publications, and augments search by providing a visual overview supporting exploration of a collection to identify key articles of interest. We developed this system over COVID-19 literature to help medical professionals and researchers explore the literature evidence, and improve findability of relevant information. COVID-SEE is available at http://covid-see.com.