 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADS: Reinforcement Learning-Based Sample Selection Improves Transfer Learning in Low-resource and Imbalanced Clinical Settings
Apr 22, 2026A common strategy in transfer learning is few shot fine-tuning, but its success is highly dependent on the quality of samples selected as training examples. Active learning methods such as uncertainty sampling and diversity sampling can select useful samples. However, under extremely low-resource and class-imbalanced conditions, they often favor outliers rather than truly informative samples, resulting in degraded performance. In this paper, we introduce RADS (Reinforcement Adaptive Domain Sampling), a robust sample selection strategy using reinforcement learning (RL) to identify the most informative samples. Experimental evaluations on several real world clinical datasets show our sample selection strategy enhances model transferability while maintaining robust performance under extreme class imbalance compared to traditional methods.
Automated Neuron Labelling Enables Generative Steering and Interpretability in Protein Language Models
Jul 08, 2025Protein language models (PLMs) encode rich biological information, yet their internal neuron representations are poorly understood. We introduce the first automated framework for labeling every neuron in a PLM with biologically grounded natural language descriptions. Unlike prior approaches relying on sparse autoencoders or manual annotation, our method scales to hundreds of thousands of neurons, revealing individual neurons are selectively sensitive to diverse biochemical and structural properties. We then develop a novel neuron activation-guided steering method to generate proteins with desired traits, enabling convergence to target biochemical properties like molecular weight and instability index as well as secondary and tertiary structural motifs, including alpha helices and canonical Zinc Fingers. We finally show that analysis of labeled neurons in different model sizes reveals PLM scaling laws and a structured neuron space distribution.
Monocular Simultaneous Localization and Mapping using Ground Textures
Mar 10, 2023



Recent work has shown impressive localization performance using only images of ground textures taken with a downward facing monocular camera. This provides a reliable navigation method that is robust to feature sparse environments and challenging lighting conditions. However, these localization methods require an existing map for comparison. Our work aims to relax the need for a map by introducing a full simultaneous localization and mapping (SLAM) system. By not requiring an existing map, setup times are minimized and the system is more robust to changing environments. This SLAM system uses a combination of several techniques to accomplish this. Image keypoints are identified and projected into the ground plane. These keypoints, visual bags of words, and several threshold parameters are then used to identify overlapping images and revisited areas. The system then uses robust M-estimators to estimate the transform between robot poses with overlapping images and revisited areas. These optimized estimates make up the map used for navigation. We show, through experimental data, that this system performs reliably on many ground textures, but not all.
Impact of detecting clinical trial elements in exploration of COVID-19 literature
May 25, 2021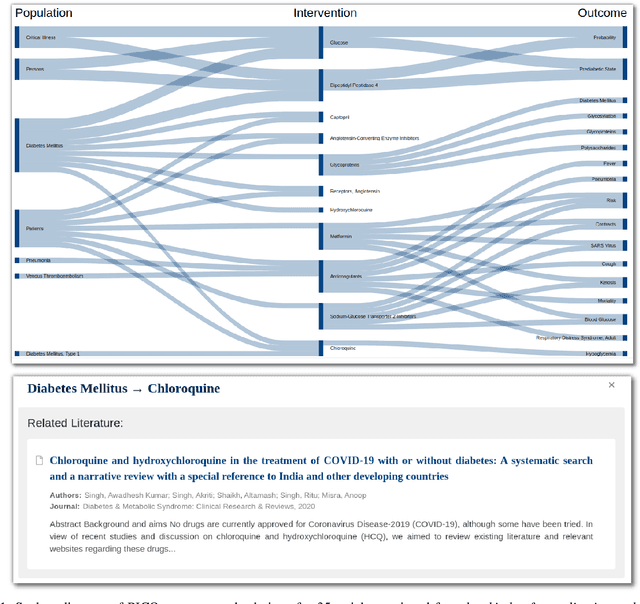
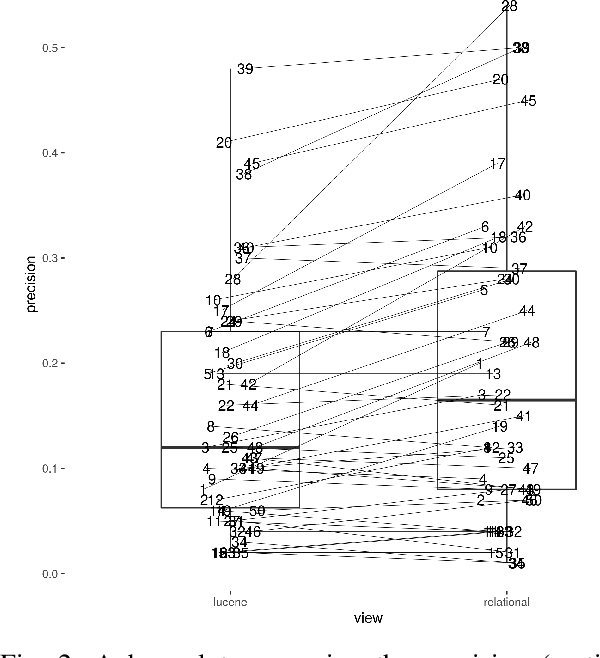
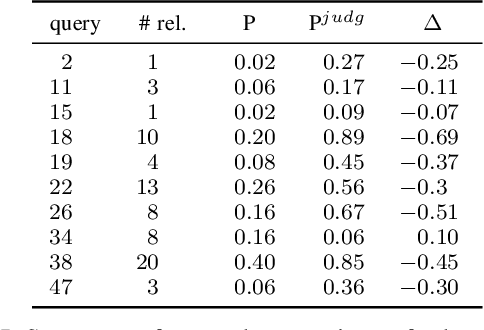

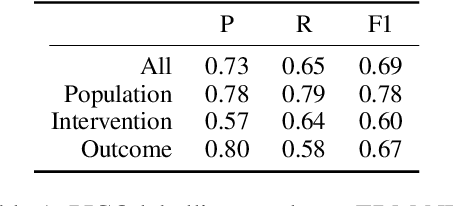
The COVID-19 pandemic has driven ever-greater demand for tools which enable efficient exploration of biomedical literature. Although semi-structured information resulting from concept recognition and detection of the defining elements of clinical trials (e.g. PICO criteria) has been commonly used to support literature search, the contributions of this abstraction remain poorly understood, especially in relation to text-based retrieval. In this study, we compare the results retrieved by a standard search engine with those filtered using clinically-relevant concepts and their relations. With analysis based on the annotations from the TREC-COVID shared task, we obtain quantitative as well as qualitative insights into characteristics of relational and concept-based literature exploration. Most importantly, we find that the relational concept selection filters the original retrieved collection in a way that decreases the proportion of unjudged documents and increases the precision, which means that the user is likely to be exposed to a larger number of relevant documents.
Robustness and Transferability of Universal Attacks on Compressed Models
Dec 10, 2020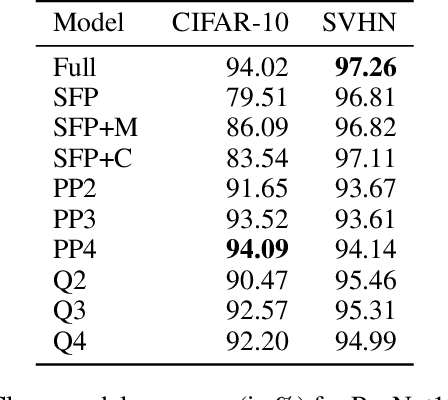
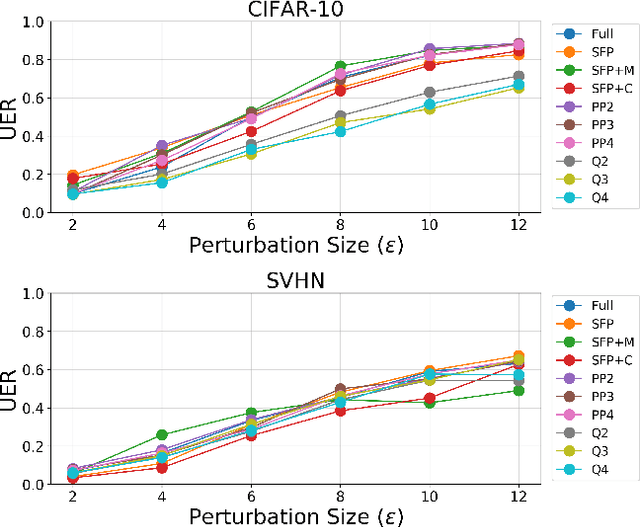
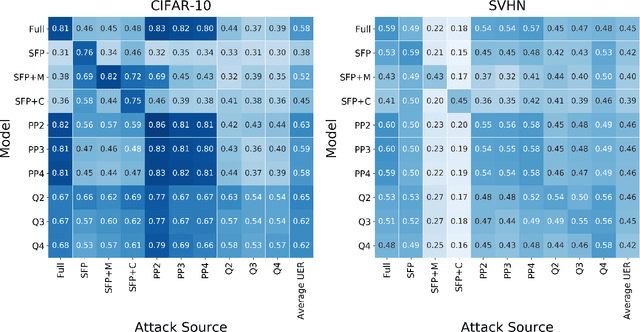
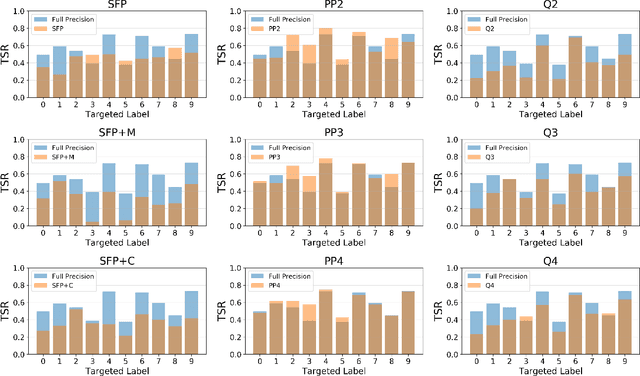
Neural network compression methods like pruning and quantization are very effective at efficiently deploying Deep Neural Networks (DNNs) on edge devices. However, DNNs remain vulnerable to adversarial examples-inconspicuous inputs that are specifically designed to fool these models. In particular, Universal Adversarial Perturbations (UAPs), are a powerful class of adversarial attacks which create adversarial perturbations that can generalize across a large set of inputs. In this work, we analyze the effect of various compression techniques to UAP attacks, including different forms of pruning and quantization. We test the robustness of compressed models to white-box and transfer attacks, comparing them with their uncompressed counterparts on CIFAR-10 and SVHN datasets. Our evaluations reveal clear differences between pruning methods, including Soft Filter and Post-training Pruning. We observe that UAP transfer attacks between pruned and full models are limited, suggesting that the systemic vulnerabilities across these models are different. This finding has practical implications as using different compression techniques can blunt the effectiveness of black-box transfer attacks. We show that, in some scenarios, quantization can produce gradient-masking, giving a false sense of security. Finally, our results suggest that conclusions about the robustness of compressed models to UAP attacks is application dependent, observing different phenomena in the two datasets used in our experiments.
COVID-SEE: Scientific Evidence Explorer for COVID-19 Related Research
Aug 18, 2020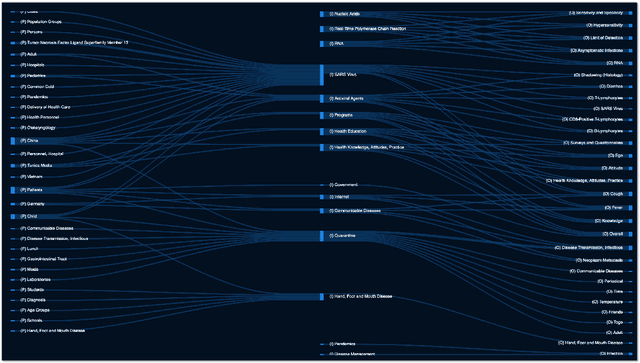

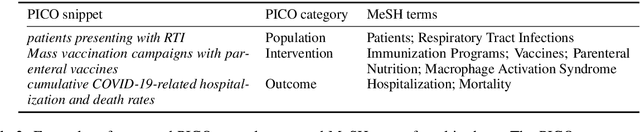
We present COVID-SEE, a system for medical literature discovery based on the concept of information exploration, which builds on several distinct text analysis and natural language processing methods to structure and organise information in publications, and augments search by providing a visual overview supporting exploration of a collection to identify key articles of interest. We developed this system over COVID-19 literature to help medical professionals and researchers explore the literature evidence, and improve findability of relevant information. COVID-SEE is available at http://covid-see.com.
AI Enabling Technologies: A Survey
May 08, 2019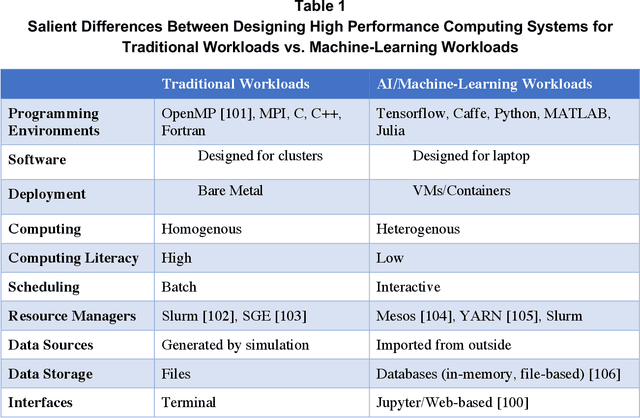
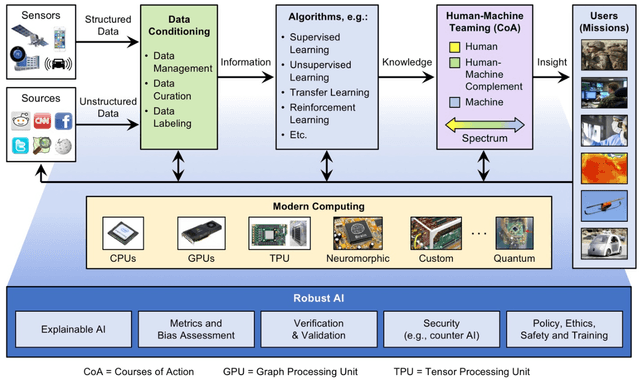

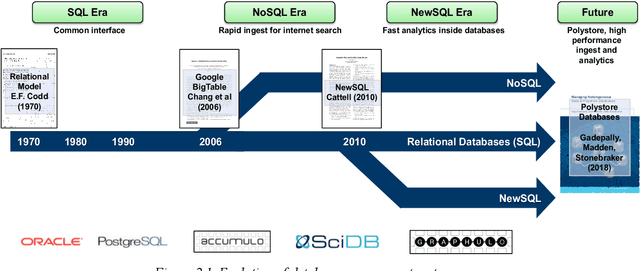
Artificial Intelligence (AI) has the opportunity to revolutionize the way the United States Department of Defense (DoD) and Intelligence Community (IC) address the challenges of evolving threats, data deluge, and rapid courses of action. Developing an end-to-end artificial intelligence system involves parallel development of different pieces that must work together in order to provide capabilities that can be used by decision makers, warfighters and analysts. These pieces include data collection, data conditioning, algorithms, computing, robust artificial intelligence, and human-machine teaming. While much of the popular press today surrounds advances in algorithms and computing, most modern AI systems leverage advances across numerous different fields. Further, while certain components may not be as visible to end-users as others, our experience has shown that each of these interrelated components play a major role in the success or failure of an AI system. This article is meant to highlight many of these technologies that are involved in an end-to-end AI system. The goal of this article is to provide readers with an overview of terminology, technical details and recent highlights from academia, industry and government. Where possible, we indicate relevant resources that can be used for further reading and understanding.
The Basque task: did systems perform in the upperbound?
Apr 12, 2002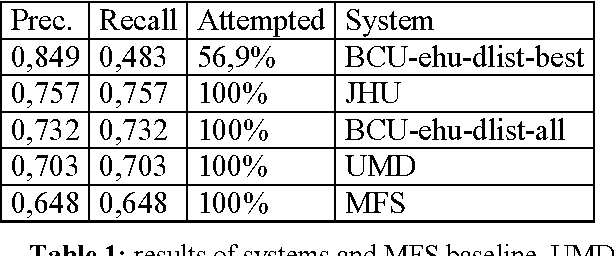
In this paper we describe the Senseval 2 Basque lexical-sample task. The task comprised 40 words (15 nouns, 15 verbs and 10 adjectives) selected from Euskal Hiztegia, the main Basque dictionary. Most examples were taken from the Egunkaria newspaper. The method used to hand-tag the examples produced low inter-tagger agreement (75%) before arbitration. The four competing systems attained results well above the most frequent baseline and the best system scored 75% precision at 100% coverage. The paper includes an analysis of the tagging procedure used, as well as the performance of the competing systems. In particular, we argue that inter-tagger agreement is not a real upperbound for the Basque WSD task.
* 4 pages
Decision Lists for English and Basque
Apr 12, 2002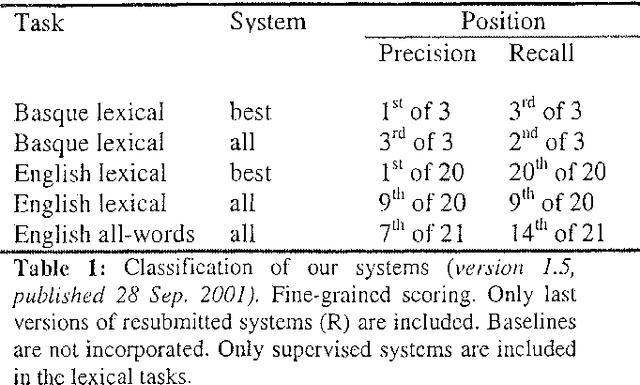
In this paper we describe the systems we developed for the English (lexical and all-words) and Basque tasks. They were all supervised systems based on Yarowsky's Decision Lists. We used Semcor for training in the English all-words task. We defined different feature sets for each language. For Basque, in order to extract all the information from the text, we defined features that have not been used before in the literature, using a morphological analyzer. We also implemented systems that selected automatically good features and were able to obtain a prefixed precision (85%) at the cost of coverage. The systems that used all the features were identified as BCU-ehu-dlist-all and the systems that selected some features as BCU-ehu-dlist-best.
* 4 pages
Integrating selectional preferences in WordNet
Apr 11, 2002
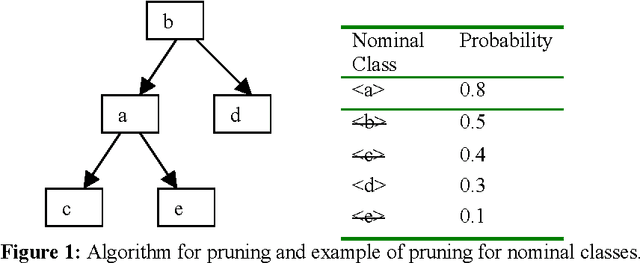

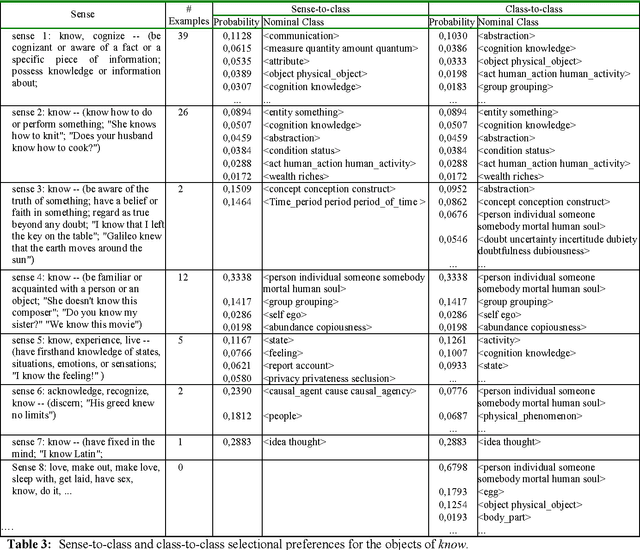
Selectional preference learning methods have usually focused on word-to-class relations, e.g., a verb selects as its subject a given nominal class. This paper extends previous statistical models to class-to-class preferences, and presents a model that learns selectional preferences for classes of verbs, together with an algorithm to integrate the learned preferences in WordNet. The theoretical motivation is twofold: different senses of a verb may have different preferences, and classes of verbs may share preferences. On the practical side, class-to-class selectional preferences can be learned from untagged corpora (the same as word-to-class), they provide selectional preferences for less frequent word senses via inheritance, and more important, they allow for easy integration in WordNet. The model is trained on subject-verb and object-verb relationships extracted from a small corpus disambiguated with WordNet senses. Examples are provided illustrating that the theoretical motivations are well founded, and showing that the approach is feasible. Experimental results on a word sense disambiguation task are also provided.
* 9 pages