 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngular Triplet-Center Loss for Multi-view 3D Shape Retrieval
Nov 21, 2018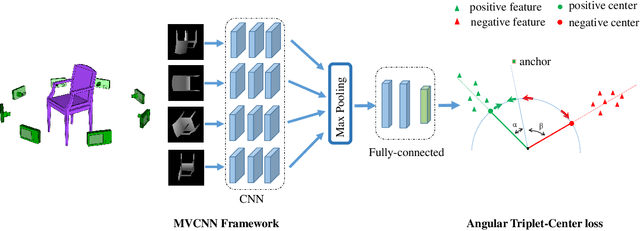
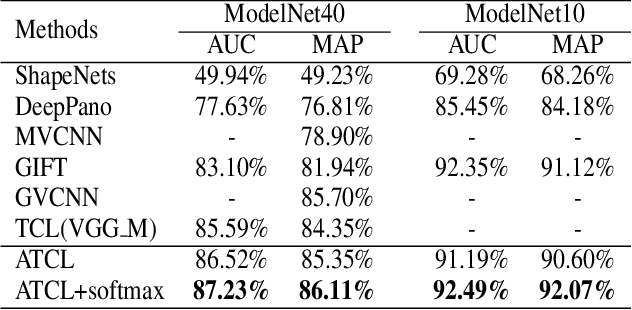
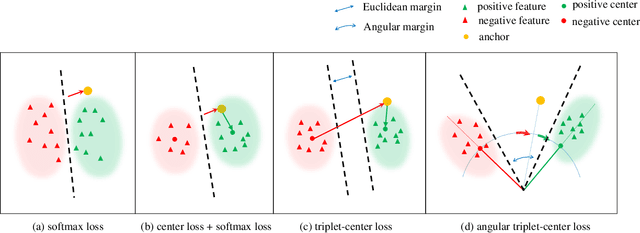
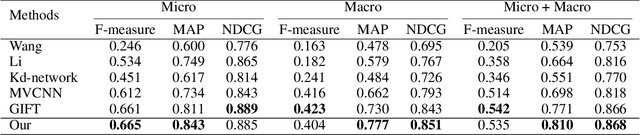
How to obtain the desirable representation of a 3D shape, which is discriminative across categories and polymerized within classes, is a significant challenge in 3D shape retrieval. Most existing 3D shape retrieval methods focus on capturing strong discriminative shape representation with softmax loss for the classification task, while the shape feature learning with metric loss is neglected for 3D shape retrieval. In this paper, we address this problem based on the intuition that the cosine distance of shape embeddings should be close enough within the same class and far away across categories. Since most of 3D shape retrieval tasks use cosine distance of shape features for measuring shape similarity, we propose a novel metric loss named angular triplet-center loss, which directly optimizes the cosine distances between the features. It inherits the triplet-center loss property to achieve larger inter-class distance and smaller intra-class distance simultaneously. Unlike previous metric loss utilized in 3D shape retrieval methods, where Euclidean distance is adopted and the margin design is difficult, the proposed method is more convenient to train feature embeddings and more suitable for 3D shape retrieval. Moreover, the angle margin is adopted to replace the cosine margin in order to provide more explicit discriminative constraints on an embedding space. Extensive experimental results on two popular 3D object retrieval benchmarks, ModelNet40 and ShapeNetCore 55, demonstrate the effectiveness of our proposed loss, and our method has achieved state-of-the-art results on various 3D shape datasets.
Learning Discriminative 3D Shape Representations by View Discerning Networks
Aug 20, 2018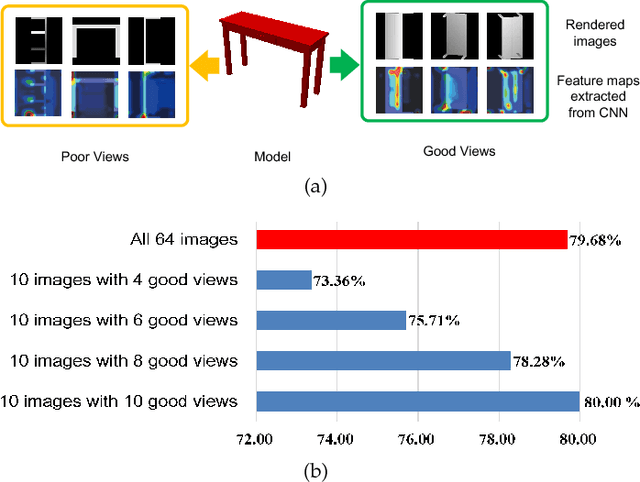
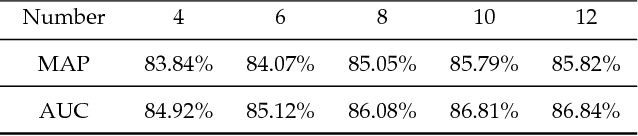
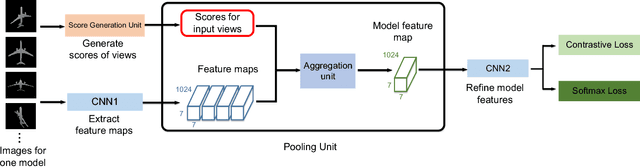
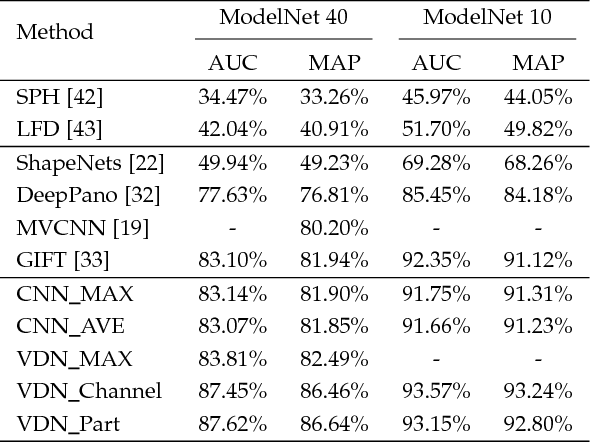
In view-based 3D shape recognition, extracting discriminative visual representation of 3D shapes from projected images is considered the core problem. Projections with low discriminative ability can adversely influence the final 3D shape representation. Especially under the real situations with background clutter and object occlusion, the adverse effect is even more severe. To resolve this problem, we propose a novel deep neural network, View Discerning Network, which learns to judge the quality of views and adjust their contributions to the representation of shapes. In this network, a Score Generation Unit is devised to evaluate the quality of each projected image with score vectors. These score vectors are used to weight the image features and the weighted features perform much better than original features in 3D shape recognition task. In particular, we introduce two structures of Score Generation Unit, Channel-wise Score Unit and Part-wise Score Unit, to assess the quality of feature maps from different perspectives. Our network aggregates features and scores in an end-to-end framework, so that final shape descriptors are directly obtained from its output. Our experiments on ModelNet and ShapeNet Core55 show that View Discerning Network outperforms the state-of-the-arts in terms of the retrieval task, with excellent robustness against background clutter and object occlusion.
* Accepted by IEEE Transactions on Visualization and Computer Graphics. Corresponding Author: Kai Xu (kevin.kai.xu@gmail.com)
Beyond Trade-off: Accelerate FCN-based Face Detector with Higher Accuracy
Jun 02, 2018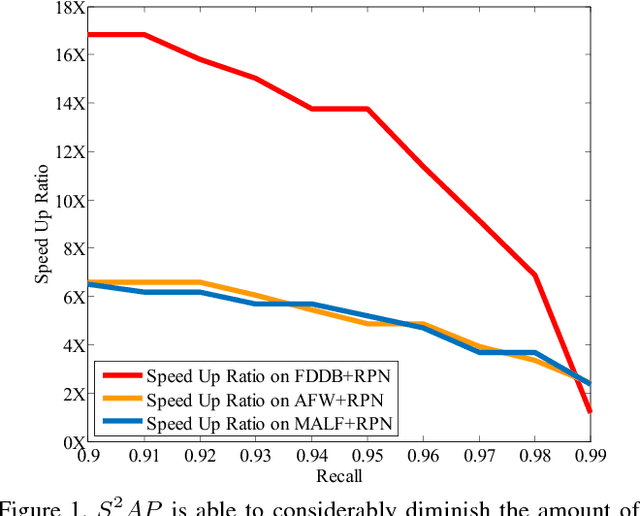

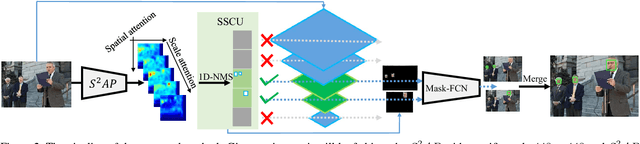
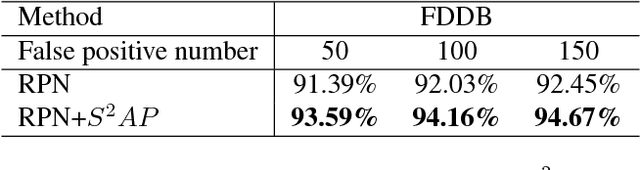
Fully convolutional neural network (FCN) has been dominating the game of face detection task for a few years with its congenital capability of sliding-window-searching with shared kernels, which boiled down all the redundant calculation, and most recent state-of-the-art methods such as Faster-RCNN, SSD, YOLO and FPN use FCN as their backbone. So here comes one question: Can we find a universal strategy to further accelerate FCN with higher accuracy, so could accelerate all the recent FCN-based methods? To analyze this, we decompose the face searching space into two orthogonal directions, `scale' and `spatial'. Only a few coordinates in the space expanded by the two base vectors indicate foreground. So if FCN could ignore most of the other points, the searching space and false alarm should be significantly boiled down. Based on this philosophy, a novel method named scale estimation and spatial attention proposal ($S^2AP$) is proposed to pay attention to some specific scales and valid locations in the image pyramid. Furthermore, we adopt a masked-convolution operation based on the attention result to accelerate FCN calculation. Experiments show that FCN-based method RPN can be accelerated by about $4\times$ with the help of $S^2AP$ and masked-FCN and at the same time it can also achieve the state-of-the-art on FDDB, AFW and MALF face detection benchmarks as well.
Region-based Quality Estimation Network for Large-scale Person Re-identification
Dec 21, 2017
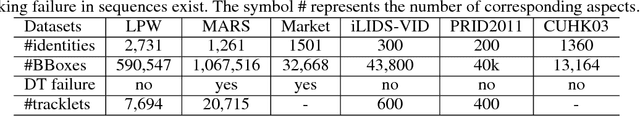
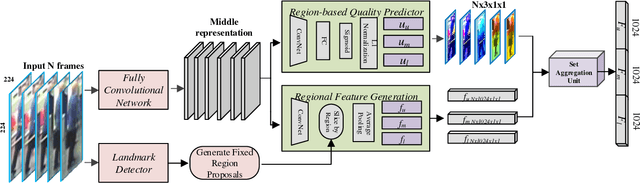
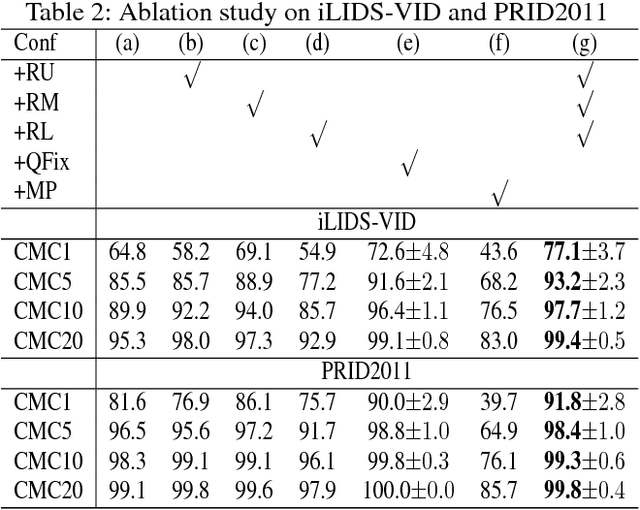
One of the major restrictions on the performance of video-based person re-id is partial noise caused by occlusion, blur and illumination. Since different spatial regions of a single frame have various quality, and the quality of the same region also varies across frames in a tracklet, a good way to address the problem is to effectively aggregate complementary information from all frames in a sequence, using better regions from other frames to compensate the influence of an image region with poor quality. To achieve this, we propose a novel Region-based Quality Estimation Network (RQEN), in which an ingenious training mechanism enables the effective learning to extract the complementary region-based information between different frames. Compared with other feature extraction methods, we achieved comparable results of 92.4%, 76.1% and 77.83% on the PRID 2011, iLIDS-VID and MARS, respectively. In addition, to alleviate the lack of clean large-scale person re-id datasets for the community, this paper also contributes a new high-quality dataset, named "Labeled Pedestrian in the Wild (LPW)" which contains 7,694 tracklets with over 590,000 images. Despite its relatively large scale, the annotations also possess high cleanliness. Moreover, it's more challenging in the following aspects: the age of characters varies from childhood to elderhood; the postures of people are diverse, including running and cycling in addition to the normal walking state.
Weakly-supervised Learning of Mid-level Features for Pedestrian Attribute Recognition and Localization
Nov 17, 2016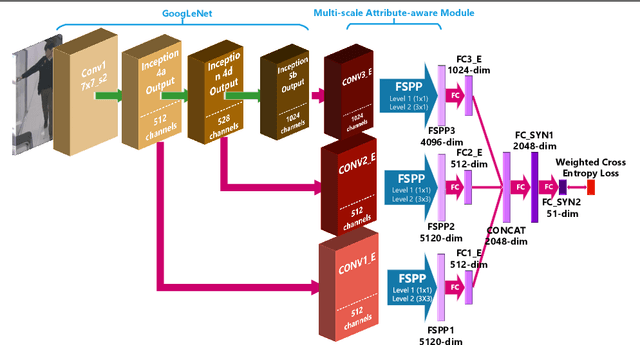
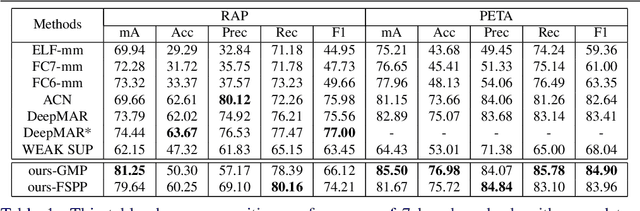
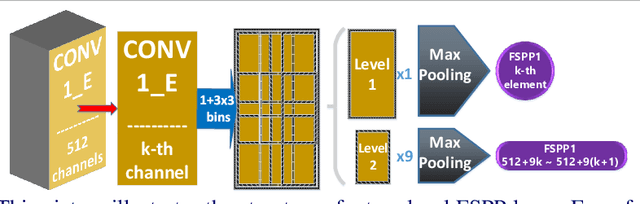
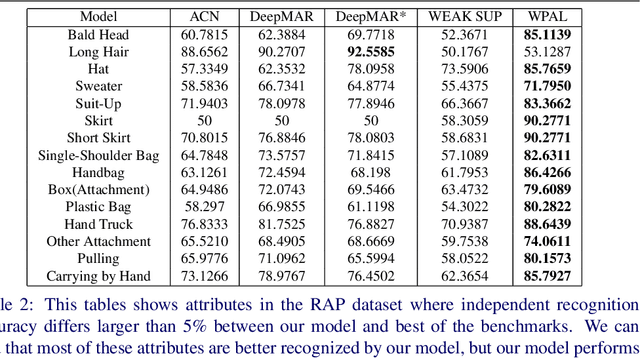
State-of-the-art methods treat pedestrian attribute recognition as a multi-label image classification problem. The location information of person attributes is usually eliminated or simply encoded in the rigid splitting of whole body in previous work. In this paper, we formulate the task in a weakly-supervised attribute localization framework. Based on GoogLeNet, firstly, a set of mid-level attribute features are discovered by novelly designed detection layers, where a max-pooling based weakly-supervised object detection technique is used to train these layers with only image-level labels without the need of bounding box annotations of pedestrian attributes. Secondly, attribute labels are predicted by regression of the detection response magnitudes. Finally, the locations and rough shapes of pedestrian attributes can be inferred by performing clustering on a fusion of activation maps of the detection layers, where the fusion weights are estimated as the correlation strengths between each attribute and its relevant mid-level features. Extensive experiments are performed on the two currently largest pedestrian attribute datasets, i.e. the PETA dataset and the RAP dataset. Results show that the proposed method has achieved competitive performance on attribute recognition, compared to other state-of-the-art methods. Moreover, the results of attribute localization are visualized to understand the characteristics of the proposed method.