 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-agnostic Multilingual Modeling
Apr 20, 2020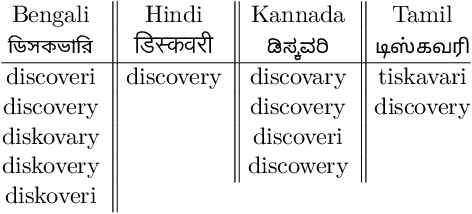
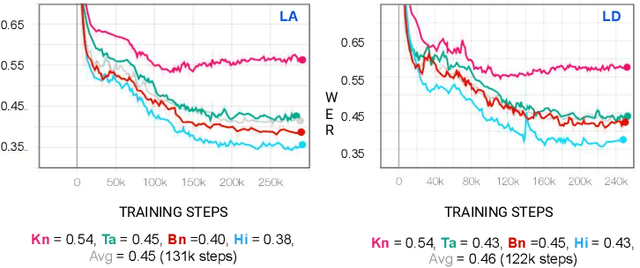
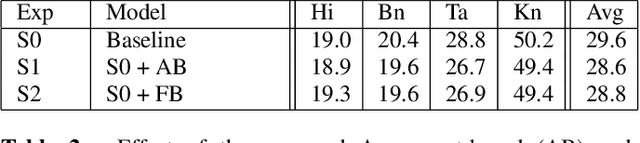
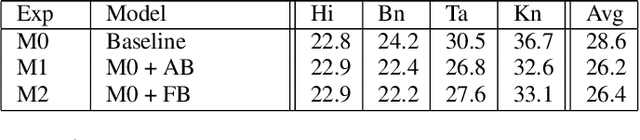
Multilingual Automated Speech Recognition (ASR) systems allow for the joint training of data-rich and data-scarce languages in a single model. This enables data and parameter sharing across languages, which is especially beneficial for the data-scarce languages. However, most state-of-the-art multilingual models require the encoding of language information and therefore are not as flexible or scalable when expanding to newer languages. Language-independent multilingual models help to address this issue, and are also better suited for multicultural societies where several languages are frequently used together (but often rendered with different writing systems). In this paper, we propose a new approach to building a language-agnostic multilingual ASR system which transforms all languages to one writing system through a many-to-one transliteration transducer. Thus, similar sounding acoustics are mapped to a single, canonical target sequence of graphemes, effectively separating the modeling and rendering problems. We show with four Indic languages, namely, Hindi, Bengali, Tamil and Kannada, that the language-agnostic multilingual model achieves up to 10% relative reduction in Word Error Rate (WER) over a language-dependent multilingual model.
Generating diverse and natural text-to-speech samples using a quantized fine-grained VAE and auto-regressive prosody prior
Feb 06, 2020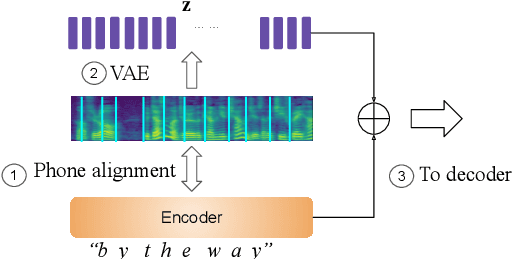
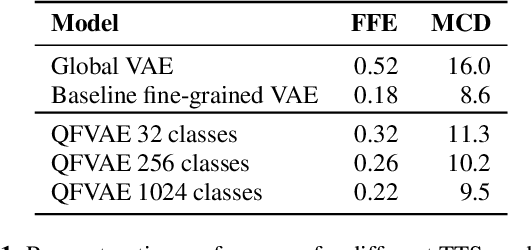
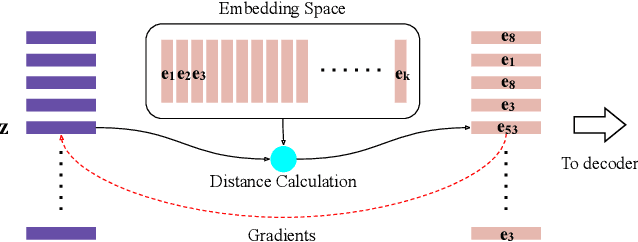
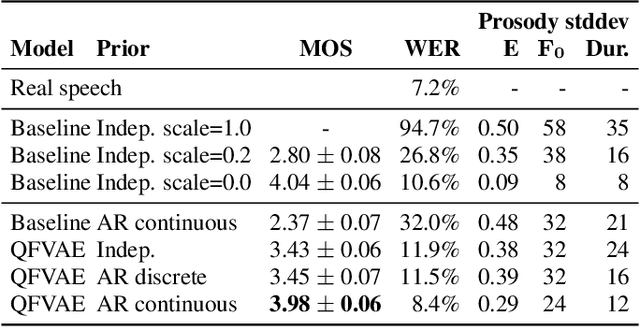
Recent neural text-to-speech (TTS) models with fine-grained latent features enable precise control of the prosody of synthesized speech. Such models typically incorporate a fine-grained variational autoencoder (VAE) structure, extracting latent features at each input token (e.g., phonemes). However, generating samples with the standard VAE prior often results in unnatural and discontinuous speech, with dramatic prosodic variation between tokens. This paper proposes a sequential prior in a discrete latent space which can generate more naturally sounding samples. This is accomplished by discretizing the latent features using vector quantization (VQ), and separately training an autoregressive (AR) prior model over the result. We evaluate the approach using listening tests, objective metrics of automatic speech recognition (ASR) performance, and measurements of prosody attributes. Experimental results show that the proposed model significantly improves the naturalness in random sample generation. Furthermore, initial experiments demonstrate that randomly sampling from the proposed model can be used as data augmentation to improve the ASR performance.
Speech Recognition with Augmented Synthesized Speech
Sep 25, 2019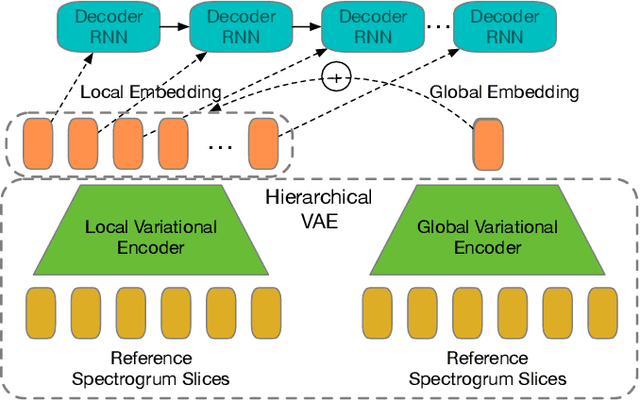
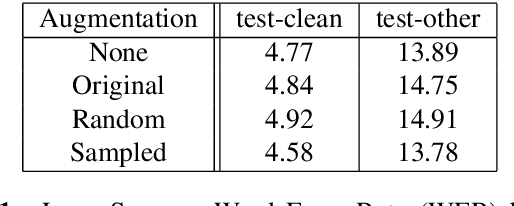
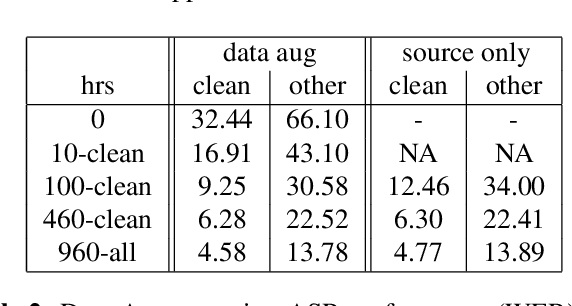
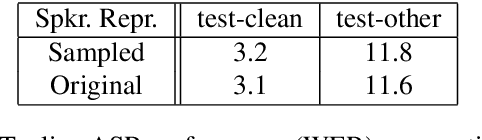
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Sep 11, 2019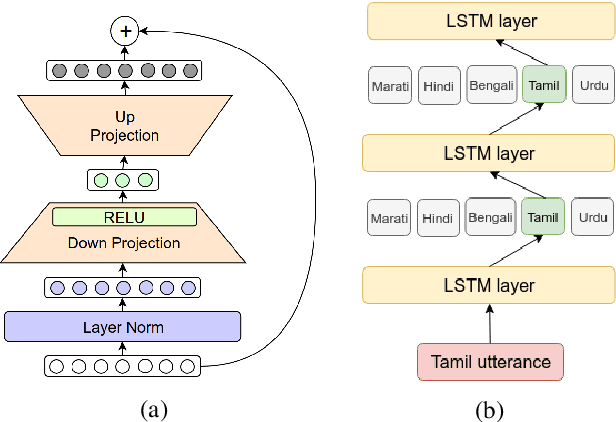
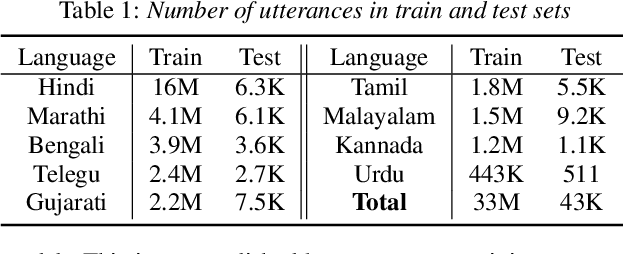
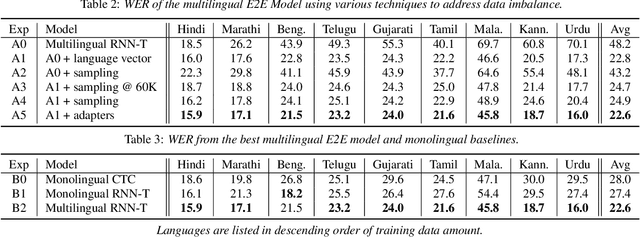
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).
Learning to Speak Fluently in a Foreign Language: Multilingual Speech Synthesis and Cross-Language Voice Cloning
Jul 24, 2019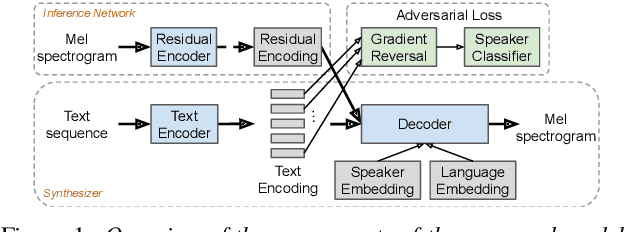
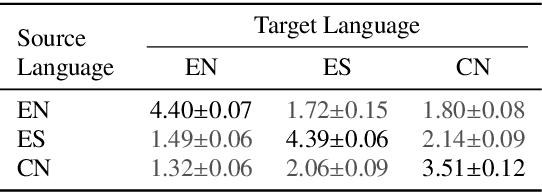
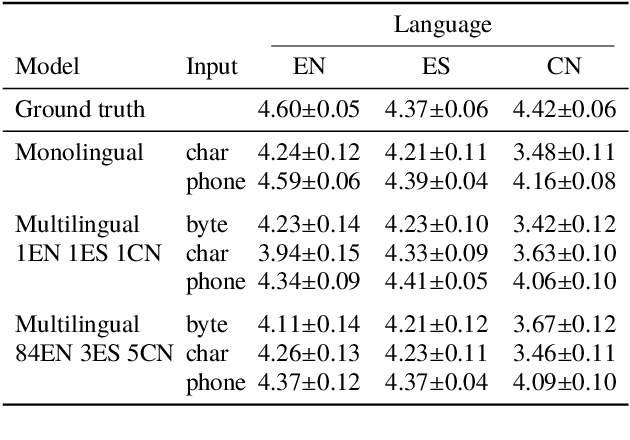
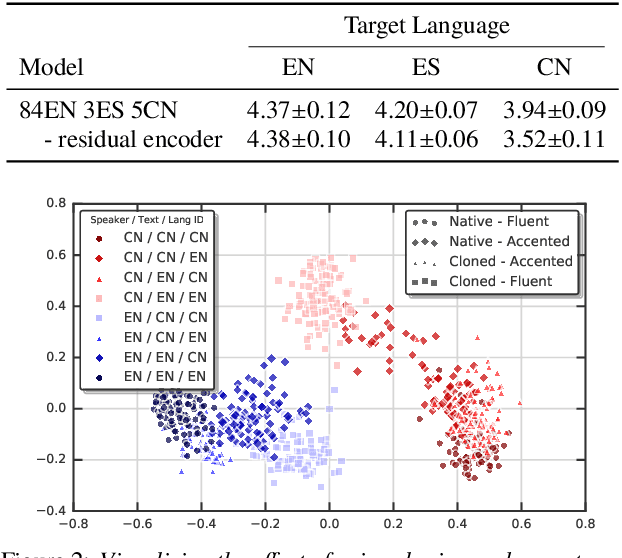
We present a multispeaker, multilingual text-to-speech (TTS) synthesis model based on Tacotron that is able to produce high quality speech in multiple languages. Moreover, the model is able to transfer voices across languages, e.g. synthesize fluent Spanish speech using an English speaker's voice, without training on any bilingual or parallel examples. Such transfer works across distantly related languages, e.g. English and Mandarin. Critical to achieving this result are: 1. using a phonemic input representation to encourage sharing of model capacity across languages, and 2. incorporating an adversarial loss term to encourage the model to disentangle its representation of speaker identity (which is perfectly correlated with language in the training data) from the speech content. Further scaling up the model by training on multiple speakers of each language, and incorporating an autoencoding input to help stabilize attention during training, results in a model which can be used to consistently synthesize intelligible speech for training speakers in all languages seen during training, and in native or foreign accents.
Joint Modeling of Accents and Acoustics for Multi-Accent Speech Recognition
Feb 07, 2018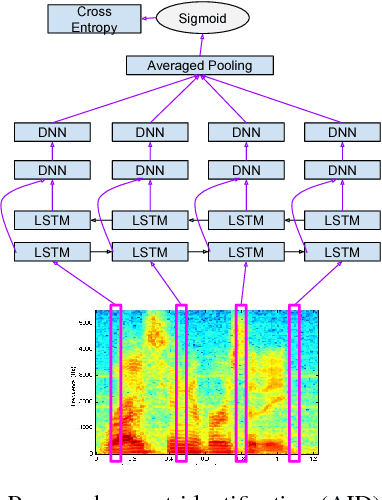
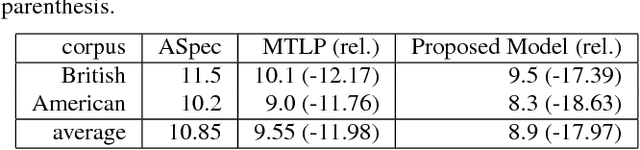

The performance of automatic speech recognition systems degrades with increasing mismatch between the training and testing scenarios. Differences in speaker accents are a significant source of such mismatch. The traditional approach to deal with multiple accents involves pooling data from several accents during training and building a single model in multi-task fashion, where tasks correspond to individual accents. In this paper, we explore an alternate model where we jointly learn an accent classifier and a multi-task acoustic model. Experiments on the American English Wall Street Journal and British English Cambridge corpora demonstrate that our joint model outperforms the strong multi-task acoustic model baseline. We obtain a 5.94% relative improvement in word error rate on British English, and 9.47% relative improvement on American English. This illustrates that jointly modeling with accent information improves acoustic model performance.
Building competitive direct acoustics-to-word models for English conversational speech recognition
Dec 08, 2017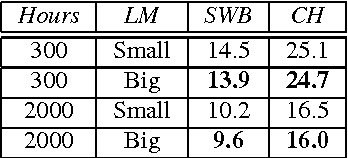
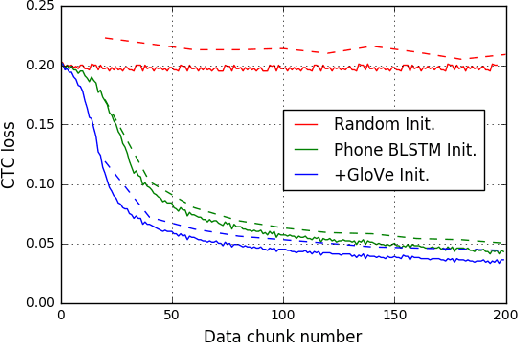
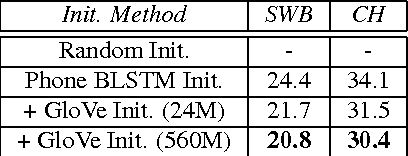
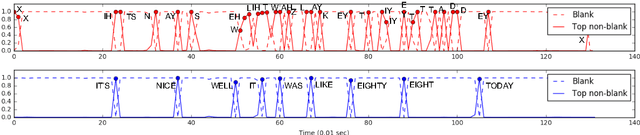
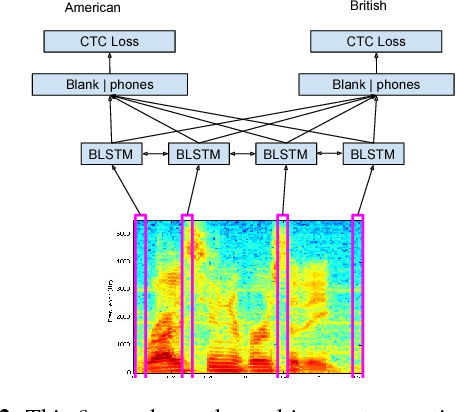
Direct acoustics-to-word (A2W) models in the end-to-end paradigm have received increasing attention compared to conventional sub-word based automatic speech recognition models using phones, characters, or context-dependent hidden Markov model states. This is because A2W models recognize words from speech without any decoder, pronunciation lexicon, or externally-trained language model, making training and decoding with such models simple. Prior work has shown that A2W models require orders of magnitude more training data in order to perform comparably to conventional models. Our work also showed this accuracy gap when using the English Switchboard-Fisher data set. This paper describes a recipe to train an A2W model that closes this gap and is at-par with state-of-the-art sub-word based models. We achieve a word error rate of 8.8%/13.9% on the Hub5-2000 Switchboard/CallHome test sets without any decoder or language model. We find that model initialization, training data order, and regularization have the most impact on the A2W model performance. Next, we present a joint word-character A2W model that learns to first spell the word and then recognize it. This model provides a rich output to the user instead of simple word hypotheses, making it especially useful in the case of words unseen or rarely-seen during training.
Language Modeling with Highway LSTM
Sep 19, 2017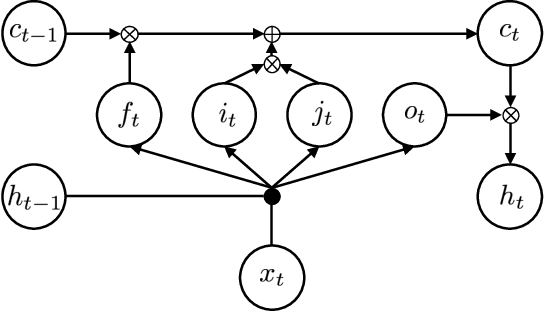

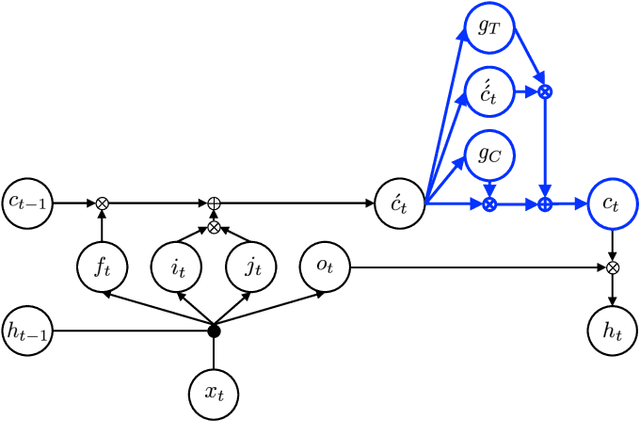
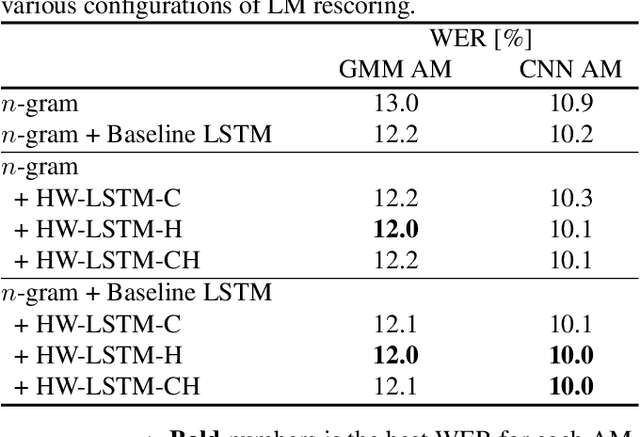
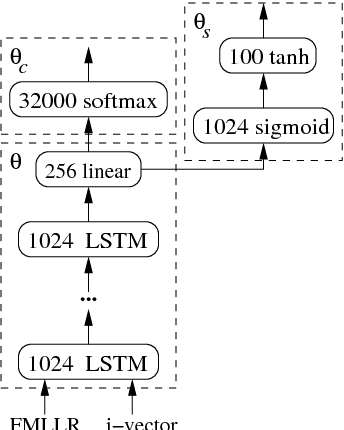
Language models (LMs) based on Long Short Term Memory (LSTM) have shown good gains in many automatic speech recognition tasks. In this paper, we extend an LSTM by adding highway networks inside an LSTM and use the resulting Highway LSTM (HW-LSTM) model for language modeling. The added highway networks increase the depth in the time dimension. Since a typical LSTM has two internal states, a memory cell and a hidden state, we compare various types of HW-LSTM by adding highway networks onto the memory cell and/or the hidden state. Experimental results on English broadcast news and conversational telephone speech recognition show that the proposed HW-LSTM LM improves speech recognition accuracy on top of a strong LSTM LM baseline. We report 5.1% and 9.9% on the Switchboard and CallHome subsets of the Hub5 2000 evaluation, which reaches the best performance numbers reported on these tasks to date.
Direct Acoustics-to-Word Models for English Conversational Speech Recognition
Mar 22, 2017Recent work on end-to-end automatic speech recognition (ASR) has shown that the connectionist temporal classification (CTC) loss can be used to convert acoustics to phone or character sequences. Such systems are used with a dictionary and separately-trained Language Model (LM) to produce word sequences. However, they are not truly end-to-end in the sense of mapping acoustics directly to words without an intermediate phone representation. In this paper, we present the first results employing direct acoustics-to-word CTC models on two well-known public benchmark tasks: Switchboard and CallHome. These models do not require an LM or even a decoder at run-time and hence recognize speech with minimal complexity. However, due to the large number of word output units, CTC word models require orders of magnitude more data to train reliably compared to traditional systems. We present some techniques to mitigate this issue. Our CTC word model achieves a word error rate of 13.0%/18.8% on the Hub5-2000 Switchboard/CallHome test sets without any LM or decoder compared with 9.6%/16.0% for phone-based CTC with a 4-gram LM. We also present rescoring results on CTC word model lattices to quantify the performance benefits of a LM, and contrast the performance of word and phone CTC models.
English Conversational Telephone Speech Recognition by Humans and Machines
Mar 06, 2017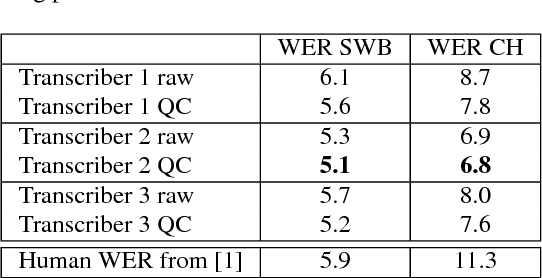
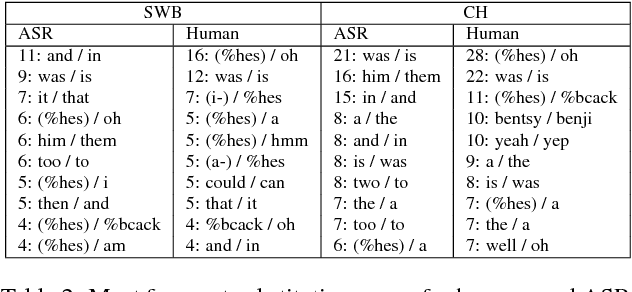
One of the most difficult speech recognition tasks is accurate recognition of human to human communication. Advances in deep learning over the last few years have produced major speech recognition improvements on the representative Switchboard conversational corpus. Word error rates that just a few years ago were 14% have dropped to 8.0%, then 6.6% and most recently 5.8%, and are now believed to be within striking range of human performance. This then raises two issues - what IS human performance, and how far down can we still drive speech recognition error rates? A recent paper by Microsoft suggests that we have already achieved human performance. In trying to verify this statement, we performed an independent set of human performance measurements on two conversational tasks and found that human performance may be considerably better than what was earlier reported, giving the community a significantly harder goal to achieve. We also report on our own efforts in this area, presenting a set of acoustic and language modeling techniques that lowered the word error rate of our own English conversational telephone LVCSR system to the level of 5.5%/10.3% on the Switchboard/CallHome subsets of the Hub5 2000 evaluation, which - at least at the writing of this paper - is a new performance milestone (albeit not at what we measure to be human performance!). On the acoustic side, we use a score fusion of three models: one LSTM with multiple feature inputs, a second LSTM trained with speaker-adversarial multi-task learning and a third residual net (ResNet) with 25 convolutional layers and time-dilated convolutions. On the language modeling side, we use word and character LSTMs and convolutional WaveNet-style language models.