 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Apr 10, 2025



Children can acquire language from less than 100 million words of input. Large language models are far less data-efficient: they typically require 3 or 4 orders of magnitude more data and still do not perform as well as humans on many evaluations. These intensive resource demands limit the ability of researchers to train new models and use existing models as developmentally plausible cognitive models. The BabyLM Challenge is a communal effort in which participants compete to optimize language model training on a fixed data budget. Submissions are compared on various evaluation tasks targeting grammatical ability, downstream task performance, and generalization. Participants can submit to up to three tracks with progressively looser data restrictions. From over 30 submissions, we extract concrete recommendations on how best to train data-efficient language models, and on where future efforts should (and perhaps should not) focus. The winning submissions using the LTG-BERT architecture (Samuel et al., 2023) outperformed models trained on trillions of words. Other submissions achieved strong results through training on shorter input sequences or training a student model on a pretrained teacher. Curriculum learning attempts, which accounted for a large number of submissions, were largely unsuccessful, though some showed modest improvements.
* Published in Proceedings of BabyLM. Please cite the published version on ACL anthology: http://aclanthology.org/2023.conll-babylm.1/
Optimizing Pretraining Data Mixtures with LLM-Estimated Utility
Jan 20, 2025Large Language Models improve with increasing amounts of high-quality training data. However, leveraging larger datasets requires balancing quality, quantity, and diversity across sources. After evaluating nine baseline methods under both compute- and data-constrained scenarios, we find token-count heuristics outperform manual and learned mixes, indicating that simple approaches accounting for dataset size and diversity are surprisingly effective. Building on this insight, we propose two complementary approaches: UtiliMax, which extends token-based heuristics by incorporating utility estimates from reduced-scale ablations, achieving up to a 10.6x speedup over manual baselines; and Model Estimated Data Utility (MEDU), which leverages LLMs to estimate data utility from small samples, matching ablation-based performance while reducing computational requirements by $\sim$200x. Together, these approaches establish a new framework for automated, compute-efficient data mixing that is robust across training regimes.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Husky: A Unified, Open-Source Language Agent for Multi-Step Reasoning
Jun 10, 2024Language agents perform complex tasks by using tools to execute each step precisely. However, most existing agents are based on proprietary models or designed to target specific tasks, such as mathematics or multi-hop question answering. We introduce Husky, a holistic, open-source language agent that learns to reason over a unified action space to address a diverse set of complex tasks involving numerical, tabular, and knowledge-based reasoning. Husky iterates between two stages: 1) generating the next action to take towards solving a given task and 2) executing the action using expert models and updating the current solution state. We identify a thorough ontology of actions for addressing complex tasks and curate high-quality data to train expert models for executing these actions. Our experiments show that Husky outperforms prior language agents across 14 evaluation datasets. Moreover, we introduce HuskyQA, a new evaluation set which stress tests language agents for mixed-tool reasoning, with a focus on retrieving missing knowledge and performing numerical reasoning. Despite using 7B models, Husky matches or even exceeds frontier LMs such as GPT-4 on these tasks, showcasing the efficacy of our holistic approach in addressing complex reasoning problems. Our code and models are available at https://github.com/agent-husky/Husky-v1.
Measuring and Improving Attentiveness to Partial Inputs with Counterfactuals
Nov 16, 2023The inevitable appearance of spurious correlations in training datasets hurts the generalization of NLP models on unseen data. Previous work has found that datasets with paired inputs are prone to correlations between a specific part of the input (e.g., the hypothesis in NLI) and the label; consequently, models trained only on those outperform chance. Are these correlations picked up by models trained on the full input data? To address this question, we propose a new evaluation method, Counterfactual Attentiveness Test (CAT). CAT uses counterfactuals by replacing part of the input with its counterpart from a different example (subject to some restrictions), expecting an attentive model to change its prediction. Using CAT, we systematically investigate established supervised and in-context learning models on ten datasets spanning four tasks: natural language inference, reading comprehension, paraphrase detection, and visual & language reasoning. CAT reveals that reliance on such correlations is mainly data-dependent. Surprisingly, we find that GPT3 becomes less attentive with an increased number of demonstrations, while its accuracy on the test data improves. Our results demonstrate that augmenting training or demonstration data with counterfactuals is effective in improving models' attentiveness. We show that models' attentiveness measured by CAT reveals different conclusions from solely measuring correlations in data.
PuMer: Pruning and Merging Tokens for Efficient Vision Language Models
May 27, 2023



Large-scale vision language (VL) models use Transformers to perform cross-modal interactions between the input text and image. These cross-modal interactions are computationally expensive and memory-intensive due to the quadratic complexity of processing the input image and text. We present PuMer: a token reduction framework that uses text-informed Pruning and modality-aware Merging strategies to progressively reduce the tokens of input image and text, improving model inference speed and reducing memory footprint. PuMer learns to keep salient image tokens related to the input text and merges similar textual and visual tokens by adding lightweight token reducer modules at several cross-modal layers in the VL model. Training PuMer is mostly the same as finetuning the original VL model but faster. Our evaluation for two vision language models on four downstream VL tasks shows PuMer increases inference throughput by up to 2x and reduces memory footprint by over 50% while incurring less than a 1% accuracy drop.
ART: Automatic multi-step reasoning and tool-use for large language models
Mar 16, 2023



Large language models (LLMs) can perform complex reasoning in few- and zero-shot settings by generating intermediate chain of thought (CoT) reasoning steps. Further, each reasoning step can rely on external tools to support computation beyond the core LLM capabilities (e.g. search/running code). Prior work on CoT prompting and tool use typically requires hand-crafting task-specific demonstrations and carefully scripted interleaving of model generations with tool use. We introduce Automatic Reasoning and Tool-use (ART), a framework that uses frozen LLMs to automatically generate intermediate reasoning steps as a program. Given a new task to solve, ART selects demonstrations of multi-step reasoning and tool use from a task library. At test time, ART seamlessly pauses generation whenever external tools are called, and integrates their output before resuming generation. ART achieves a substantial improvement over few-shot prompting and automatic CoT on unseen tasks in the BigBench and MMLU benchmarks, and matches performance of hand-crafted CoT prompts on a majority of these tasks. ART is also extensible, and makes it easy for humans to improve performance by correcting errors in task-specific programs or incorporating new tools, which we demonstrate by drastically improving performance on select tasks with minimal human intervention.
AGRO: Adversarial Discovery of Error-prone groups for Robust Optimization
Dec 08, 2022Models trained via empirical risk minimization (ERM) are known to rely on spurious correlations between labels and task-independent input features, resulting in poor generalization to distributional shifts. Group distributionally robust optimization (G-DRO) can alleviate this problem by minimizing the worst-case loss over a set of pre-defined groups over training data. G-DRO successfully improves performance of the worst-group, where the correlation does not hold. However, G-DRO assumes that the spurious correlations and associated worst groups are known in advance, making it challenging to apply it to new tasks with potentially multiple unknown spurious correlations. We propose AGRO -- Adversarial Group discovery for Distributionally Robust Optimization -- an end-to-end approach that jointly identifies error-prone groups and improves accuracy on them. AGRO equips G-DRO with an adversarial slicing model to find a group assignment for training examples which maximizes worst-case loss over the discovered groups. On the WILDS benchmark, AGRO results in 8% higher model performance on average on known worst-groups, compared to prior group discovery approaches used with G-DRO. AGRO also improves out-of-distribution performance on SST2, QQP, and MS-COCO -- datasets where potential spurious correlations are as yet uncharacterized. Human evaluation of ARGO groups shows that they contain well-defined, yet previously unstudied spurious correlations that lead to model errors.
CORE: A Retrieve-then-Edit Framework for Counterfactual Data Generation
Oct 10, 2022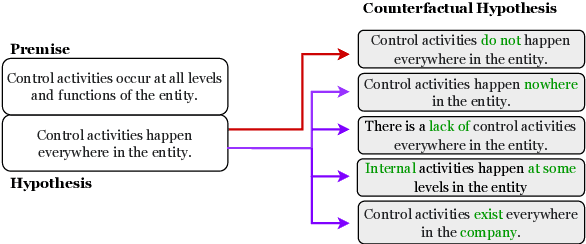

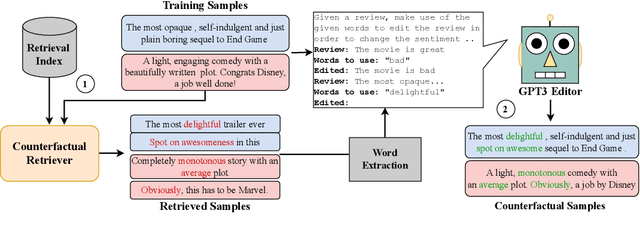
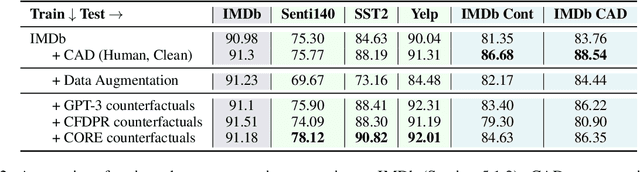
Counterfactual data augmentation (CDA) -- i.e., adding minimally perturbed inputs during training -- helps reduce model reliance on spurious correlations and improves generalization to out-of-distribution (OOD) data. Prior work on generating counterfactuals only considered restricted classes of perturbations, limiting their effectiveness. We present COunterfactual Generation via Retrieval and Editing (CORE), a retrieval-augmented generation framework for creating diverse counterfactual perturbations for CDA. For each training example, CORE first performs a dense retrieval over a task-related unlabeled text corpus using a learned bi-encoder and extracts relevant counterfactual excerpts. CORE then incorporates these into prompts to a large language model with few-shot learning capabilities, for counterfactual editing. Conditioning language model edits on naturally occurring data results in diverse perturbations. Experiments on natural language inference and sentiment analysis benchmarks show that CORE counterfactuals are more effective at improving generalization to OOD data compared to other DA approaches. We also show that the CORE retrieval framework can be used to encourage diversity in manually authored perturbations