 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Person Image Generation
Jun 15, 2018
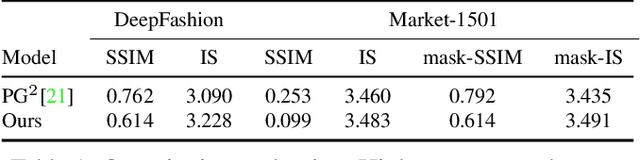
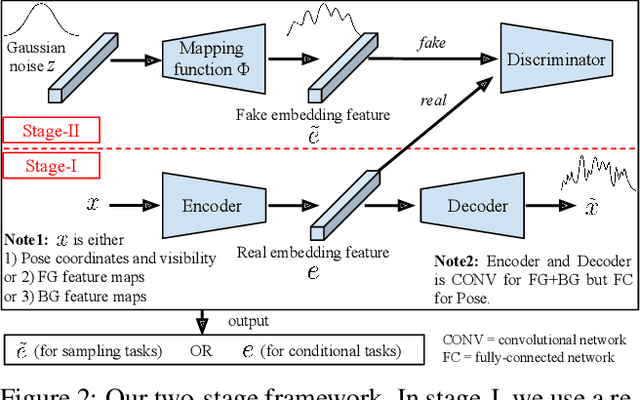
Generating novel, yet realistic, images of persons is a challenging task due to the complex interplay between the different image factors, such as the foreground, background and pose information. In this work, we aim at generating such images based on a novel, two-stage reconstruction pipeline that learns a disentangled representation of the aforementioned image factors and generates novel person images at the same time. First, a multi-branched reconstruction network is proposed to disentangle and encode the three factors into embedding features, which are then combined to re-compose the input image itself. Second, three corresponding mapping functions are learned in an adversarial manner in order to map Gaussian noise to the learned embedding feature space, for each factor respectively. Using the proposed framework, we can manipulate the foreground, background and pose of the input image, and also sample new embedding features to generate such targeted manipulations, that provide more control over the generation process. Experiments on Market-1501 and Deepfashion datasets show that our model does not only generate realistic person images with new foregrounds, backgrounds and poses, but also manipulates the generated factors and interpolates the in-between states. Another set of experiments on Market-1501 shows that our model can also be beneficial for the person re-identification task.
Adversarial Scene Editing: Automatic Object Removal from Weak Supervision
Jun 05, 2018
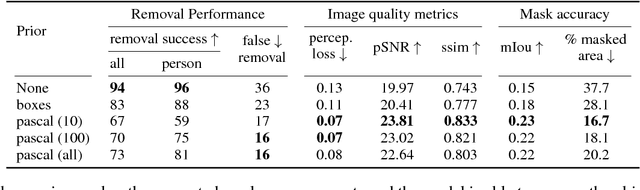
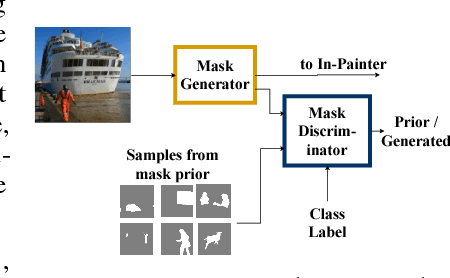
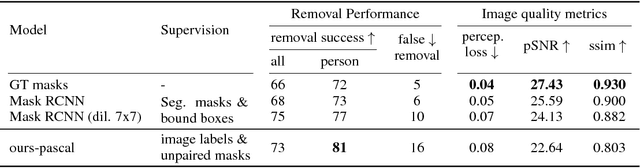
While great progress has been made recently in automatic image manipulation, it has been limited to object centric images like faces or structured scene datasets. In this work, we take a step towards general scene-level image editing by developing an automatic interaction-free object removal model. Our model learns to find and remove objects from general scene images using image-level labels and unpaired data in a generative adversarial network (GAN) framework. We achieve this with two key contributions: a two-stage editor architecture consisting of a mask generator and image in-painter that co-operate to remove objects, and a novel GAN based prior for the mask generator that allows us to flexibly incorporate knowledge about object shapes. We experimentally show on two datasets that our method effectively removes a wide variety of objects using weak supervision only
Understanding and Controlling User Linkability in Decentralized Learning
May 15, 2018

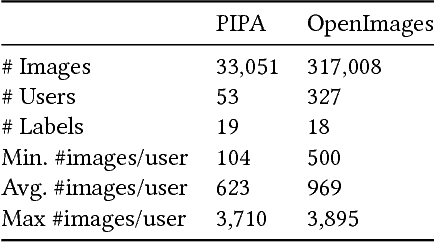

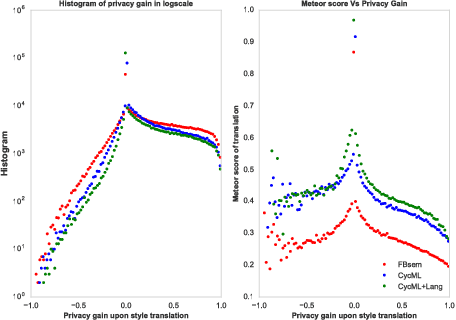
Machine Learning techniques are widely used by online services (e.g. Google, Apple) in order to analyze and make predictions on user data. As many of the provided services are user-centric (e.g. personal photo collections, speech recognition, personal assistance), user data generated on personal devices is key to provide the service. In order to protect the data and the privacy of the user, federated learning techniques have been proposed where the data never leaves the user's device and "only" model updates are communicated back to the server. In our work, we propose a new threat model that is not concerned with learning about the content - but rather is concerned with the linkability of users during such decentralized learning scenarios. We show that model updates are characteristic for users and therefore lend themselves to linkability attacks. We show identification and matching of users across devices in closed and open world scenarios. In our experiments, we find our attacks to be highly effective, achieving 20x-175x chance-level performance. In order to mitigate the risks of linkability attacks, we study various strategies. As adding random noise does not offer convincing operation points, we propose strategies based on using calibrated domain-specific data; we find these strategies offers substantial protection against linkability threats with little effect to utility.
Video Object Segmentation with Language Referring Expressions
May 09, 2018
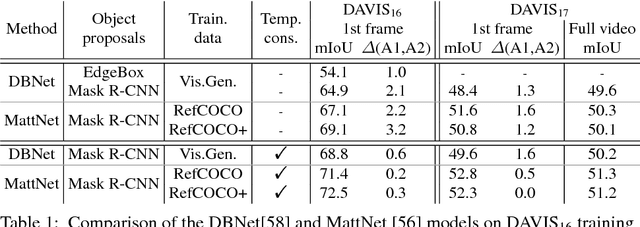
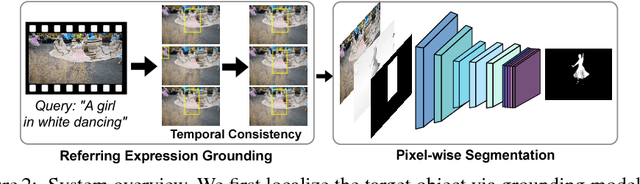
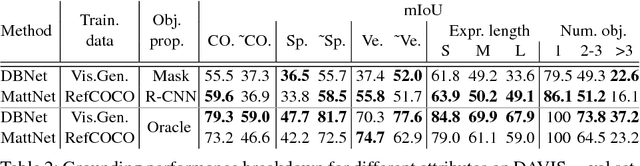
Most state-of-the-art semi-supervised video object segmentation methods rely on a pixel-accurate mask of a target object provided for the first frame of a video. However, obtaining a detailed segmentation mask is expensive and time-consuming. In this work we explore an alternative way of identifying a target object, namely by employing language referring expressions. Besides being a more practical and natural way of pointing out a target object, using language specifications can help to avoid drift as well as make the system more robust to complex dynamics and appearance variations. Leveraging recent advances of language grounding models designed for images, we propose an approach to extend them to video data, ensuring temporally coherent predictions. To evaluate our method we augment the popular video object segmentation benchmarks, DAVIS'16 and DAVIS'17 with language descriptions of target objects. We show that our approach performs on par with the methods which have access to a pixel-level mask of the target object on DAVIS'16 and is competitive to methods using scribbles on the challenging DAVIS'17 dataset.
Learning to Refine Human Pose Estimation
Apr 21, 2018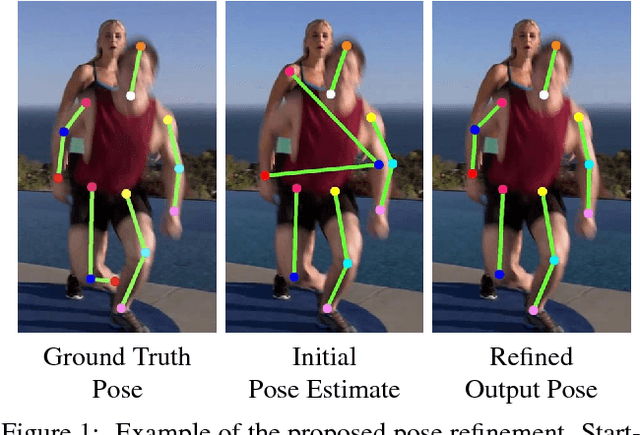
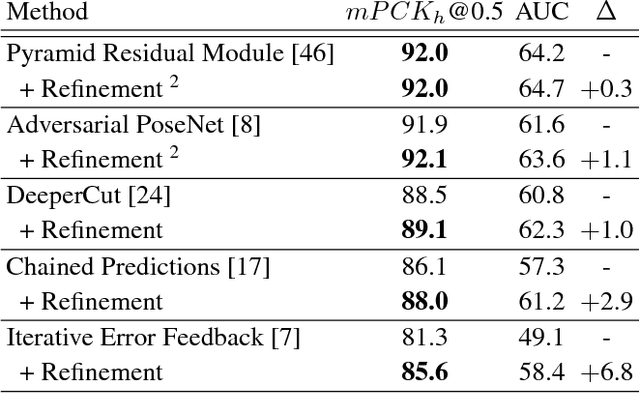
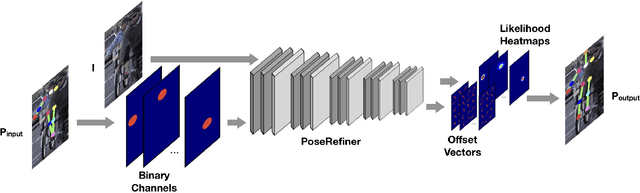
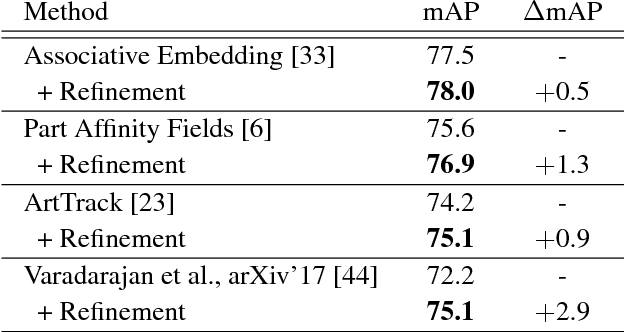
Multi-person pose estimation in images and videos is an important yet challenging task with many applications. Despite the large improvements in human pose estimation enabled by the development of convolutional neural networks, there still exist a lot of difficult cases where even the state-of-the-art models fail to correctly localize all body joints. This motivates the need for an additional refinement step that addresses these challenging cases and can be easily applied on top of any existing method. In this work, we introduce a pose refinement network (PoseRefiner) which takes as input both the image and a given pose estimate and learns to directly predict a refined pose by jointly reasoning about the input-output space. In order for the network to learn to refine incorrect body joint predictions, we employ a novel data augmentation scheme for training, where we model "hard" human pose cases. We evaluate our approach on four popular large-scale pose estimation benchmarks such as MPII Single- and Multi-Person Pose Estimation, PoseTrack Pose Estimation, and PoseTrack Pose Tracking, and report systematic improvement over the state of the art.
Feature Generating Networks for Zero-Shot Learning
Apr 12, 2018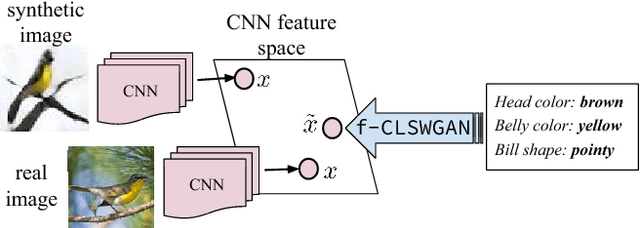
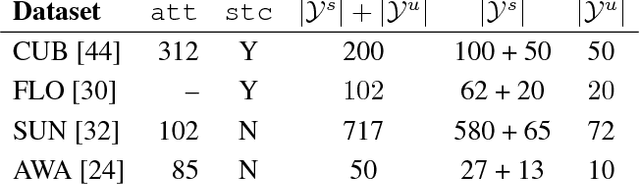
Suffering from the extreme training data imbalance between seen and unseen classes, most of existing state-of-the-art approaches fail to achieve satisfactory results for the challenging generalized zero-shot learning task. To circumvent the need for labeled examples of unseen classes, we propose a novel generative adversarial network (GAN) that synthesizes CNN features conditioned on class-level semantic information, offering a shortcut directly from a semantic descriptor of a class to a class-conditional feature distribution. Our proposed approach, pairing a Wasserstein GAN with a classification loss, is able to generate sufficiently discriminative CNN features to train softmax classifiers or any multimodal embedding method. Our experimental results demonstrate a significant boost in accuracy over the state of the art on five challenging datasets -- CUB, FLO, SUN, AWA and ImageNet -- in both the zero-shot learning and generalized zero-shot learning settings.
PoseTrack: A Benchmark for Human Pose Estimation and Tracking
Apr 10, 2018



Human poses and motions are important cues for analysis of videos with people and there is strong evidence that representations based on body pose are highly effective for a variety of tasks such as activity recognition, content retrieval and social signal processing. In this work, we aim to further advance the state of the art by establishing "PoseTrack", a new large-scale benchmark for video-based human pose estimation and articulated tracking, and bringing together the community of researchers working on visual human analysis. The benchmark encompasses three competition tracks focusing on i) single-frame multi-person pose estimation, ii) multi-person pose estimation in videos, and iii) multi-person articulated tracking. To facilitate the benchmark and challenge we collect, annotate and release a new %large-scale benchmark dataset that features videos with multiple people labeled with person tracks and articulated pose. A centralized evaluation server is provided to allow participants to evaluate on a held-out test set. We envision that the proposed benchmark will stimulate productive research both by providing a large and representative training dataset as well as providing a platform to objectively evaluate and compare the proposed methods. The benchmark is freely accessible at https://posetrack.net.
Natural and Effective Obfuscation by Head Inpainting
Mar 16, 2018
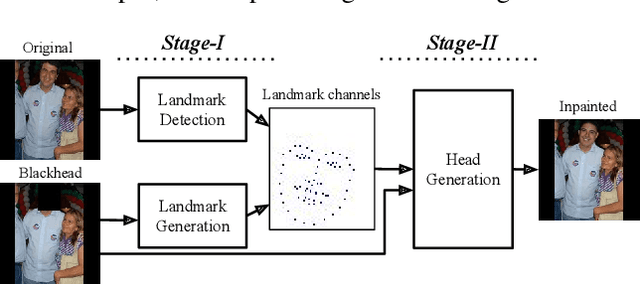
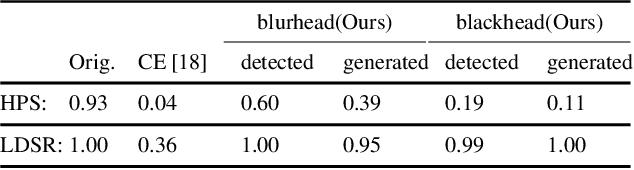
As more and more personal photos are shared online, being able to obfuscate identities in such photos is becoming a necessity for privacy protection. People have largely resorted to blacking out or blurring head regions, but they result in poor user experience while being surprisingly ineffective against state of the art person recognizers. In this work, we propose a novel head inpainting obfuscation technique. Generating a realistic head inpainting in social media photos is challenging because subjects appear in diverse activities and head orientations. We thus split the task into two sub-tasks: (1) facial landmark generation from image context (e.g. body pose) for seamless hypothesis of sensible head pose, and (2) facial landmark conditioned head inpainting. We verify that our inpainting method generates realistic person images, while achieving superior obfuscation performance against automatic person recognizers.
$A^{4}NT$: Author Attribute Anonymity by Adversarial Training of Neural Machine Translation
Feb 19, 2018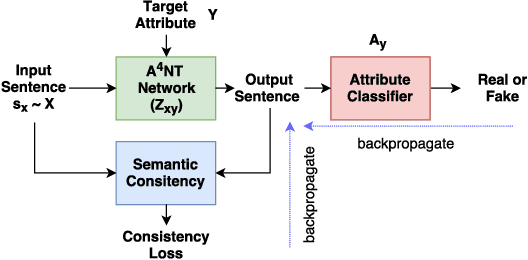
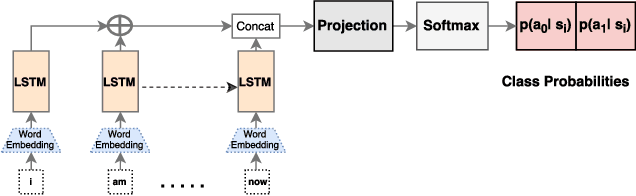
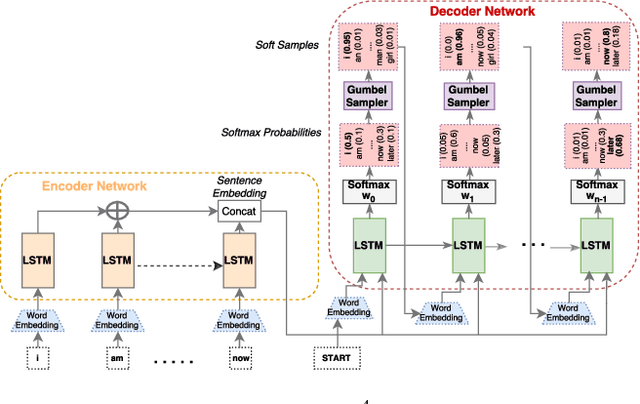
Text-based analysis methods allow to reveal privacy relevant author attributes such as gender, age and identify of the text's author. Such methods can compromise the privacy of an anonymous author even when the author tries to remove privacy sensitive content. In this paper, we propose an automatic method, called Adversarial Author Attribute Anonymity Neural Translation ($A^4NT$), to combat such text-based adversaries. We combine sequence-to-sequence language models used in machine translation and generative adversarial networks to obfuscate author attributes. Unlike machine translation techniques which need paired data, our method can be trained on unpaired corpora of text containing different authors. Importantly, we propose and evaluate techniques to impose constraints on our $A^4NT$ to preserve the semantics of the input text. $A^4NT$ learns to make minimal changes to the input text to successfully fool author attribute classifiers, while aiming to maintain the meaning of the input. We show through experiments on two different datasets and three settings that our proposed method is effective in fooling the author attribute classifiers and thereby improving the anonymity of authors.
Multimodal Explanations: Justifying Decisions and Pointing to the Evidence
Feb 15, 2018
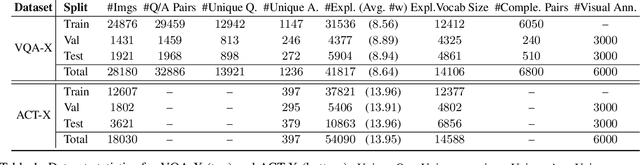

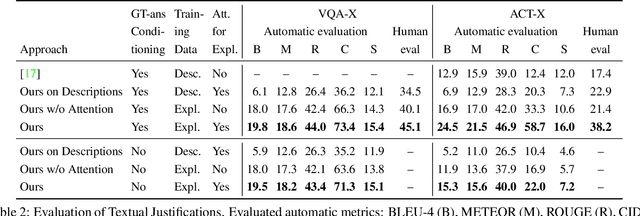
Deep models that are both effective and explainable are desirable in many settings; prior explainable models have been unimodal, offering either image-based visualization of attention weights or text-based generation of post-hoc justifications. We propose a multimodal approach to explanation, and argue that the two modalities provide complementary explanatory strengths. We collect two new datasets to define and evaluate this task, and propose a novel model which can provide joint textual rationale generation and attention visualization. Our datasets define visual and textual justifications of a classification decision for activity recognition tasks (ACT-X) and for visual question answering tasks (VQA-X). We quantitatively show that training with the textual explanations not only yields better textual justification models, but also better localizes the evidence that supports the decision. We also qualitatively show cases where visual explanation is more insightful than textual explanation, and vice versa, supporting our thesis that multimodal explanation models offer significant benefits over unimodal approaches.