 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalizing Flows with Multi-Scale Autoregressive Priors
Apr 08, 2020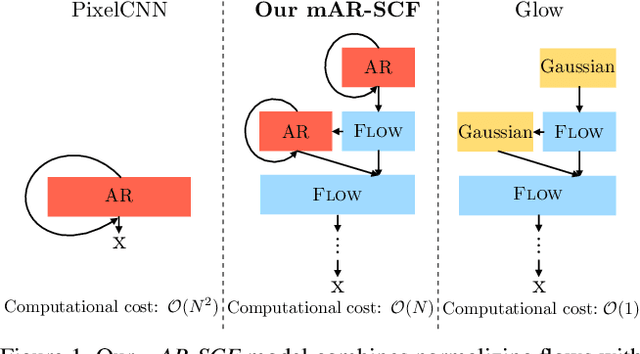
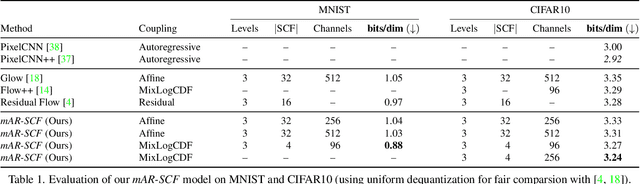
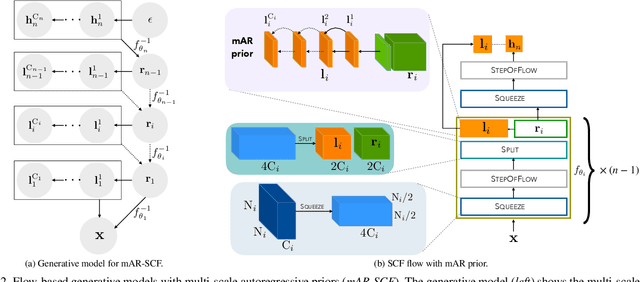
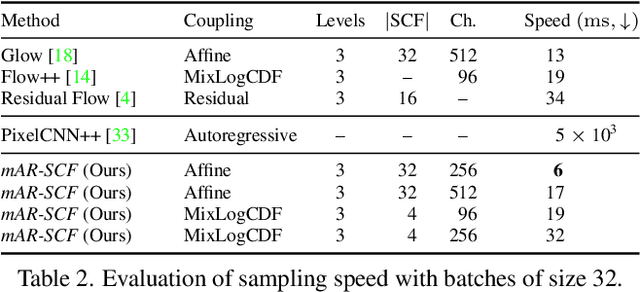
Flow-based generative models are an important class of exact inference models that admit efficient inference and sampling for image synthesis. Owing to the efficiency constraints on the design of the flow layers, e.g. split coupling flow layers in which approximately half the pixels do not undergo further transformations, they have limited expressiveness for modeling long-range data dependencies compared to autoregressive models that rely on conditional pixel-wise generation. In this work, we improve the representational power of flow-based models by introducing channel-wise dependencies in their latent space through multi-scale autoregressive priors (mAR). Our mAR prior for models with split coupling flow layers (mAR-SCF) can better capture dependencies in complex multimodal data. The resulting model achieves state-of-the-art density estimation results on MNIST, CIFAR-10, and ImageNet. Furthermore, we show that mAR-SCF allows for improved image generation quality, with gains in FID and Inception scores compared to state-of-the-art flow-based models.
Long-Tailed Recognition Using Class-Balanced Experts
Apr 07, 2020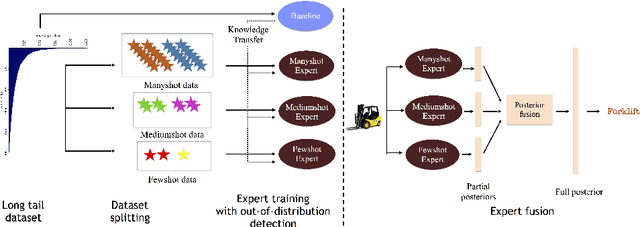
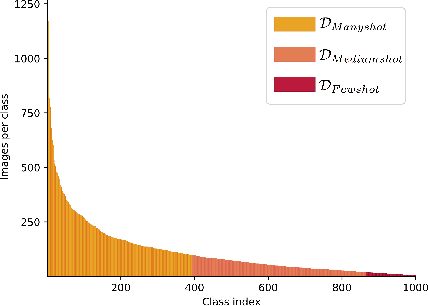

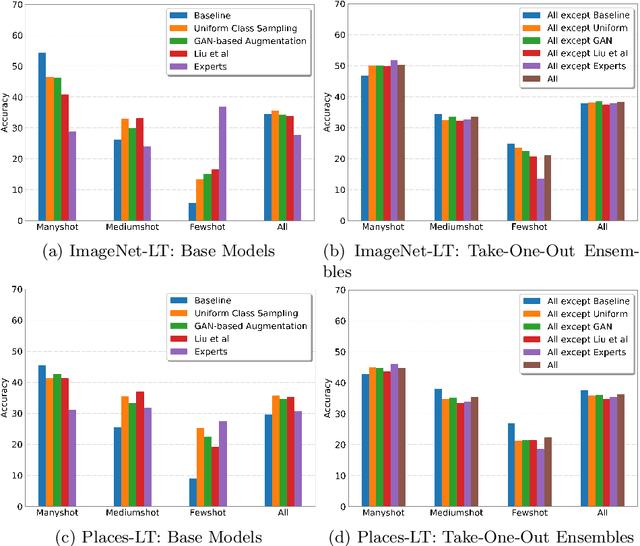
Classic deep learning methods achieve impressive results in image recognition over large-scale artificially-balanced datasets. However, real-world datasets exhibit highly class-imbalanced distributions. In this work we address the problem of long tail recognition wherein the training set is highly imbalanced and the test set is kept balanced. The key challenges faced by any long tail recognition technique are relative imbalance amongst the classes and data scarcity or unseen concepts for mediumshot or fewshot classes. Existing techniques rely on data-resampling, cost sensitive learning, online hard example mining, reshaping the loss objective and complex memory based models to address this problem. We instead propose an ensemble of experts technique that decomposes the imbalanced problem into multiple balanced classification problems which are more tractable. Our ensemble of experts reaches close to state-of-the-art results and an extended ensemble establishes new state-of-the-art on two benchmarks for long tail recognition. We conduct numerous experiments to analyse the performance of the ensemble, and show that in modern datasets relative imbalance is a harder problem than data scarcity.
A U-Net Based Discriminator for Generative Adversarial Networks
Feb 28, 2020
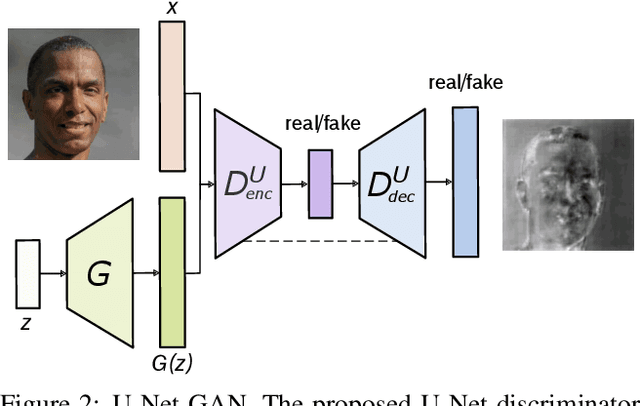


Among the major remaining challenges for generative adversarial networks (GANs) is the capacity to synthesize globally and locally coherent images with object shapes and textures indistinguishable from real images. To target this issue we propose an alternative U-Net based discriminator architecture, borrowing the insights from the segmentation literature. The proposed U-Net based architecture allows to provide detailed per-pixel feedback to the generator while maintaining the global coherence of synthesized images, by providing the global image feedback as well. Empowered by the per-pixel response of the discriminator, we further propose a per-pixel consistency regularization technique based on the CutMix data augmentation, encouraging the U-Net discriminator to focus more on semantic and structural changes between real and fake images. This improves the U-Net discriminator training, further enhancing the quality of generated samples. The novel discriminator improves over the state of the art in terms of the standard distribution and image quality metrics, enabling the generator to synthesize images with varying structure, appearance and levels of detail, maintaining global and local realism. Compared to the BigGAN baseline, we achieve an average improvement of 2.7 FID points across FFHQ, CelebA, and the newly introduced COCO-Animals dataset.
Mnemonics Training: Multi-Class Incremental Learning without Forgetting
Feb 26, 2020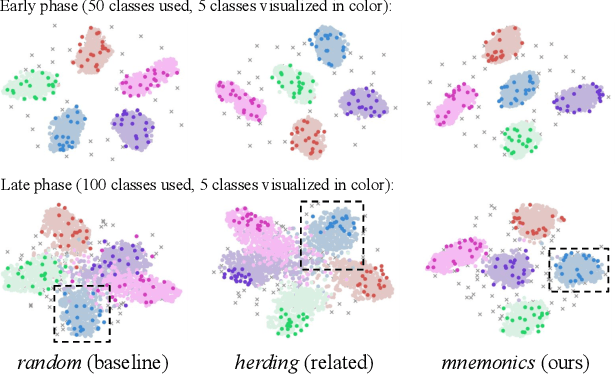
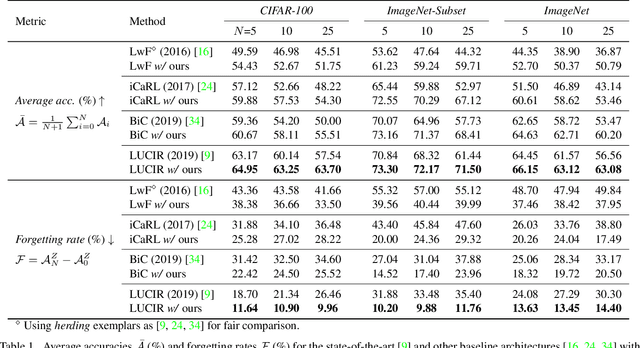
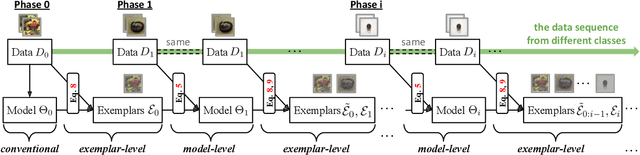
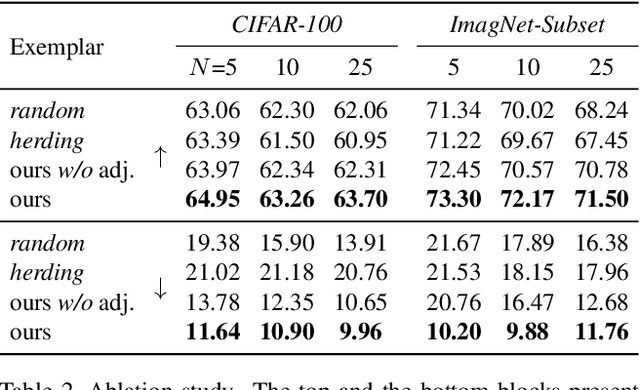
Multi-Class Incremental Learning (MCIL) aims to learn new concepts by incrementally updating a model trained on previous concepts. However, there is an inherent trade-off to effectively learning new concepts without catastrophic forgetting of previous ones. To alleviate this issue, it has been proposed to keep around a few examples of the previous concepts but the effectiveness of this approach heavily depends on the representativeness of these examples. This paper proposes a novel and automatic framework we call mnemonics, where we parameterize exemplars and make them optimizable in an end-to-end manner. We train the framework through bilevel optimizations, i.e., model-level and exemplar-level. We conduct extensive experiments on three MCIL benchmarks, CIFAR-100, ImageNet-Subset and ImageNet, and show that using mnemonics exemplars can surpass the state-of-the-art by a large margin. Interestingly and quite intriguingly, the mnemonics exemplars tend to be on the boundaries between classes.
Analyzing the Dependency of ConvNets on Spatial Information
Feb 05, 2020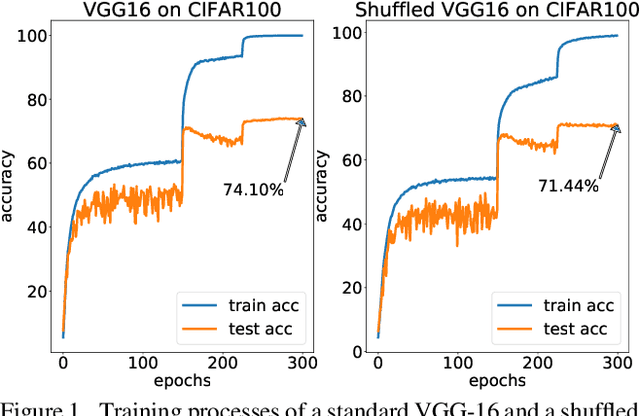
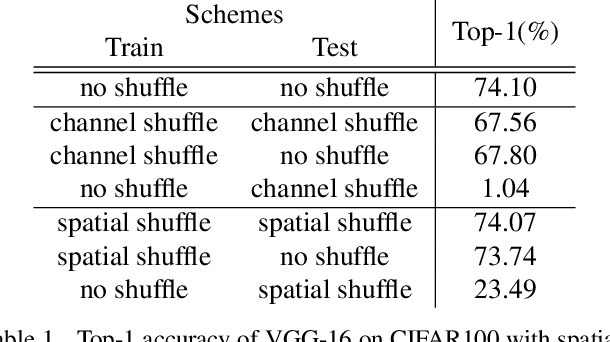
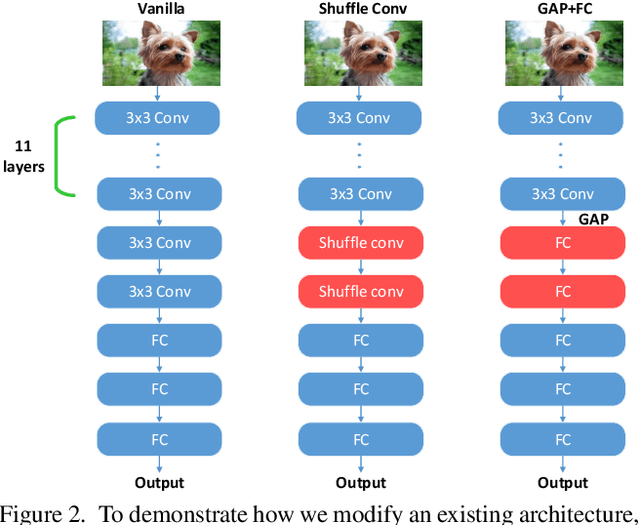
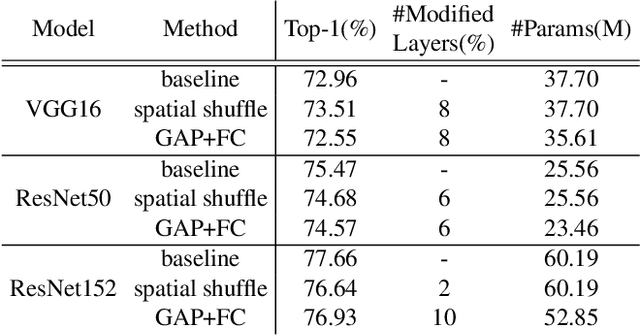
Intuitively, image classification should profit from using spatial information. Recent work, however, suggests that this might be overrated in standard CNNs. In this paper, we are pushing the envelope and aim to further investigate the reliance on spatial information. We propose spatial shuffling and GAP+FC to destroy spatial information during both training and testing phases. Interestingly, we observe that spatial information can be deleted from later layers with small performance drops, which indicates spatial information at later layers is not necessary for good performance. For example, test accuracy of VGG-16 only drops by 0.03% and 2.66% with spatial information completely removed from the last 30% and 53% layers on CIFAR100, respectively. Evaluation on several object recognition datasets (CIFAR100, Small-ImageNet, ImageNet) with a wide range of CNN architectures (VGG16, ResNet50, ResNet152) shows an overall consistent pattern.
Segmentations-Leak: Membership Inference Attacks and Defenses in Semantic Image Segmentation
Dec 20, 2019

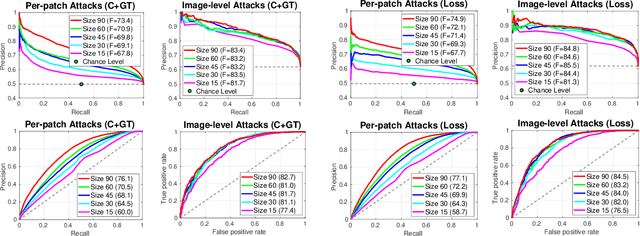
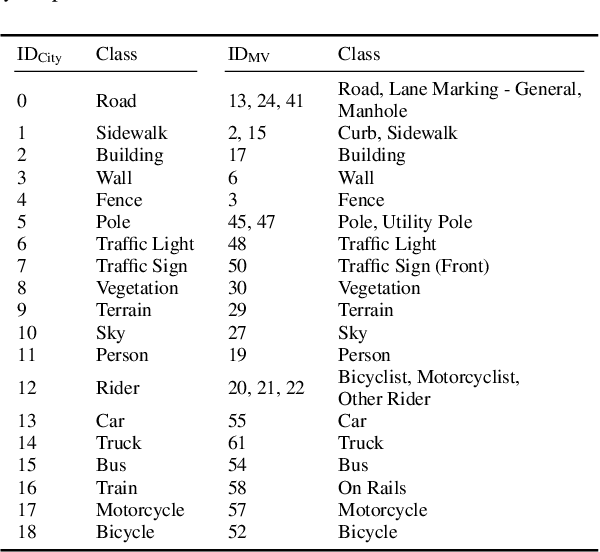
Today's success of state of the art methods for semantic segmentation is driven by large datasets. Data is considered an important asset that needs to be protected, as the collection and annotation of such datasets comes at significant efforts and associated costs. In addition, visual data might contain private or sensitive information, that makes it equally unsuited for public release. Unfortunately, recent work on membership inference in the broader area of adversarial machine learning and inference attacks on machine learning models has shown that even black box classifiers leak information on the dataset that they were trained on. We present the first attacks and defenses for complex, state of the art models for semantic segmentation. In order to mitigate the associated risks, we also study a series of defenses against such membership inference attacks and find effective counter measures against the existing risks. Finally, we extensively evaluate our attacks and defenses on a range of relevant real-world datasets: Cityscapes, BDD100K, and Mapillary Vistas.
Confidence-Calibrated Adversarial Training and Detection: More Robust Models Generalizing Beyond the Attack Used During Training
Nov 25, 2019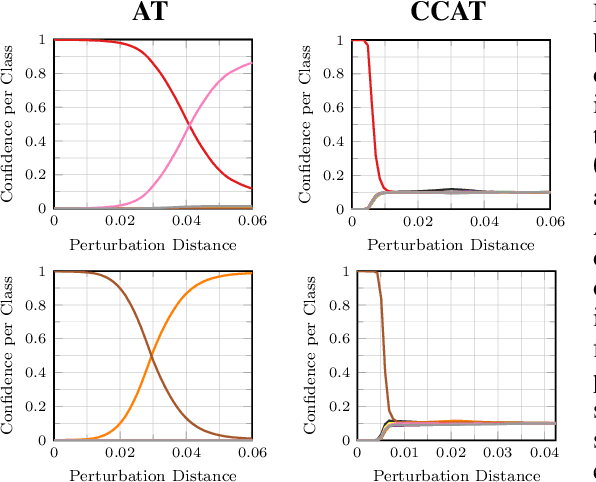
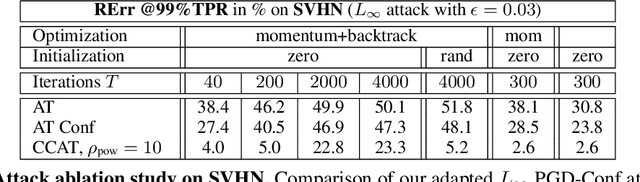
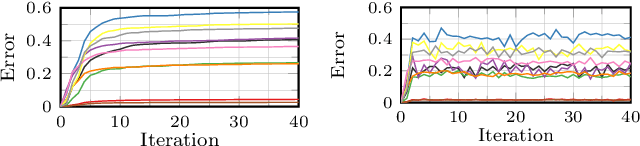
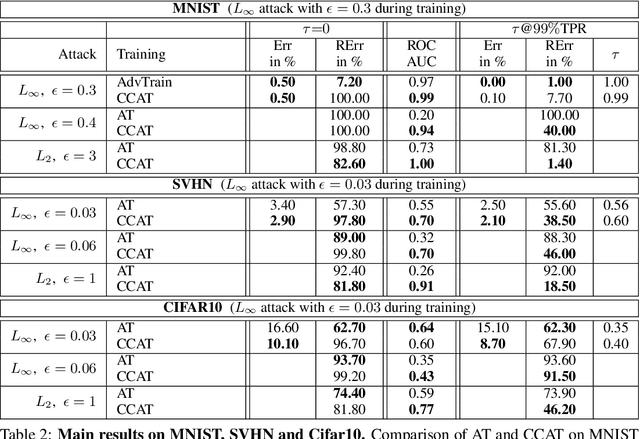
Adversarial training is the standard to train models robust against adversarial examples. However, especially for complex datasets, adversarial training incurs a significant loss in accuracy and is known to generalize poorly to stronger attacks, e.g., larger perturbations or other threat models. In this paper, we introduce confidence-calibrated adversarial training (CCAT) where the key idea is to enforce that the confidence on adversarial examples decays with their distance to the attacked examples. We show that CCAT preserves better the accuracy of normal training while robustness against adversarial examples is achieved via confidence thresholding, i.e., detecting adversarial examples based on their confidence. Most importantly, in strong contrast to adversarial training, the robustness of CCAT generalizes to larger perturbations and other threat models, not encountered during training. For evaluation, we extend the commonly used robust test error to our detection setting, present an adaptive attack with backtracking and allow the attacker to select, per test example, the worst-case adversarial example from multiple black- and white-box attacks. We present experimental results using $L_\infty$, $L_2$, $L_1$ and $L_0$ attacks on MNIST, SVHN and Cifar10.
Meta-Transfer Learning through Hard Tasks
Oct 07, 2019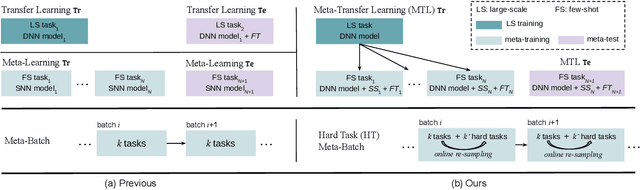
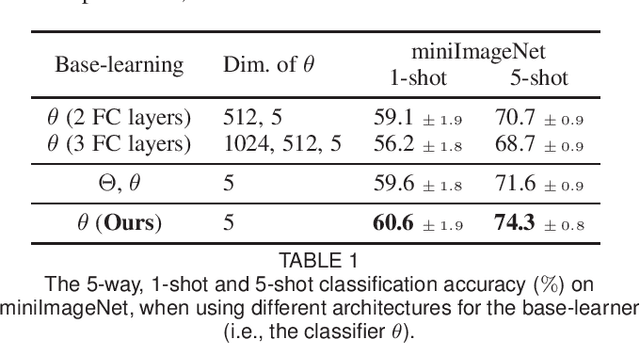

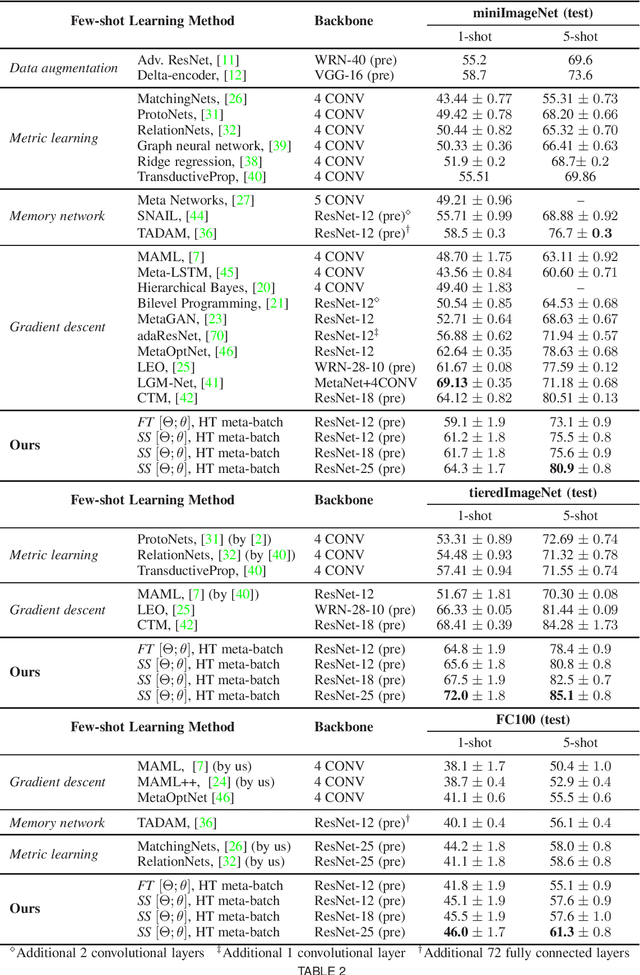
Meta-learning has been proposed as a framework to address the challenging few-shot learning setting. The key idea is to leverage a large number of similar few-shot tasks in order to learn how to adapt a base-learner to a new task for which only a few labeled samples are available. As deep neural networks (DNNs) tend to overfit using a few samples only, typical meta-learning models use shallow neural networks, thus limiting its effectiveness. In order to achieve top performance, some recent works tried to use the DNNs pre-trained on large-scale datasets but mostly in straight-forward manners, e.g., (1) taking their weights as a warm start of meta-training, and (2) freezing their convolutional layers as the feature extractor of base-learners. In this paper, we propose a novel approach called meta-transfer learning (MTL) which learns to transfer the weights of a deep NN for few-shot learning tasks. Specifically, meta refers to training multiple tasks, and transfer is achieved by learning scaling and shifting functions of DNN weights for each task. In addition, we introduce the hard task (HT) meta-batch scheme as an effective learning curriculum that further boosts the learning efficiency of MTL. We conduct few-shot learning experiments and report top performance for five-class few-shot recognition tasks on three challenging benchmarks: miniImageNet, tieredImageNet and Fewshot-CIFAR100 (FC100). Extensive comparisons to related works validate that our MTL approach trained with the proposed HT meta-batch scheme achieves top performance. An ablation study also shows that both components contribute to fast convergence and high accuracy.
"Best-of-Many-Samples" Distribution Matching
Sep 27, 2019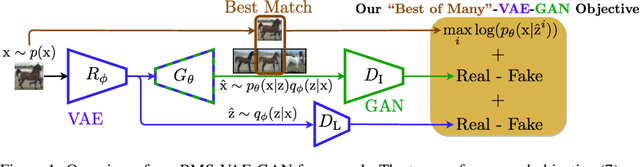
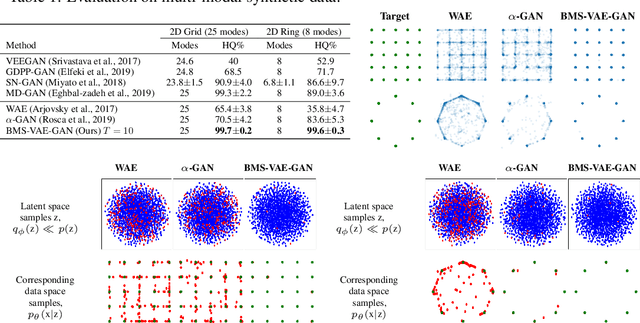


Generative Adversarial Networks (GANs) can achieve state-of-the-art sample quality in generative modelling tasks but suffer from the mode collapse problem. Variational Autoencoders (VAE) on the other hand explicitly maximize a reconstruction-based data log-likelihood forcing it to cover all modes, but suffer from poorer sample quality. Recent works have proposed hybrid VAE-GAN frameworks which integrate a GAN-based synthetic likelihood to the VAE objective to address both the mode collapse and sample quality issues, with limited success. This is because the VAE objective forces a trade-off between the data log-likelihood and divergence to the latent prior. The synthetic likelihood ratio term also shows instability during training. We propose a novel objective with a "Best-of-Many-Samples" reconstruction cost and a stable direct estimate of the synthetic likelihood. This enables our hybrid VAE-GAN framework to achieve high data log-likelihood and low divergence to the latent prior at the same time and shows significant improvement over both hybrid VAE-GANS and plain GANs in mode coverage and quality.
Conditional Flow Variational Autoencoders for Structured Sequence Prediction
Aug 24, 2019


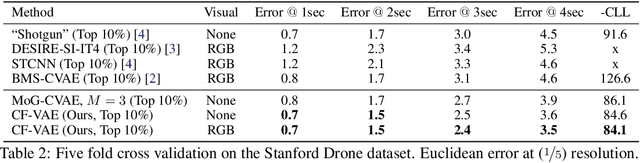
Prediction of future states of the environment and interacting agents is a key competence required for autonomous agents to operate successfully in the real world. Prior work for structured sequence prediction based on latent variable models imposes a uni-modal standard Gaussian prior on the latent variables. This induces a strong model bias which makes it challenging to fully capture the multi-modality of the distribution of the future states. In this work, we introduce Conditional Flow Variational Autoencoders which uses our novel conditional normalizing flow based prior. We show that using our novel complex multi-modal conditional prior we can capture complex multi-modal conditional distributions. Furthermore, we study for the first time latent variable collapse with normalizing flows and propose solutions to prevent such failure cases. Our experiments on three multi-modal structured sequence prediction datasets -- MNIST Sequences, Stanford Drone and HighD -- show that the proposed method obtains state of art results across different evaluation metrics.