 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-Calibrated Adversarial Training and Detection: More Robust Models Generalizing Beyond the Attack Used During Training
Paper and Code
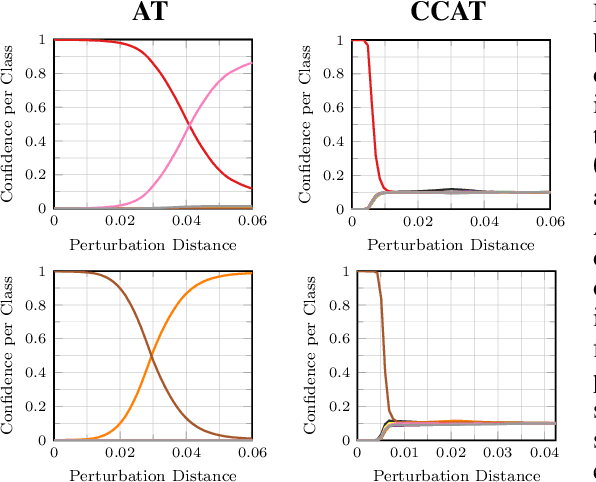
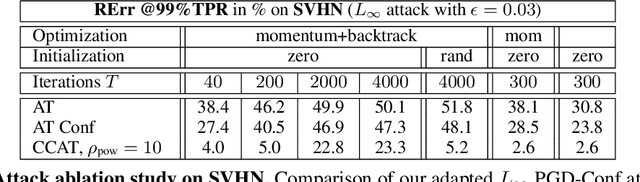
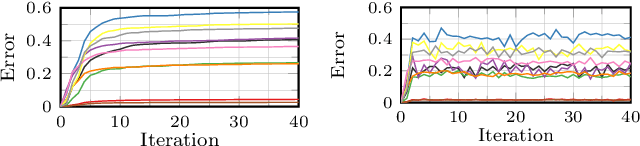
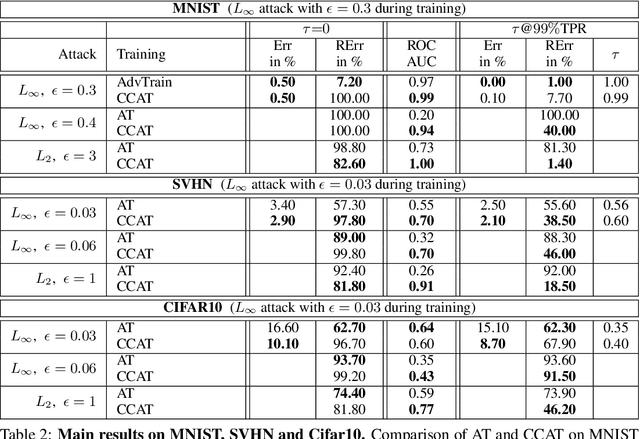
Adversarial training is the standard to train models robust against adversarial examples. However, especially for complex datasets, adversarial training incurs a significant loss in accuracy and is known to generalize poorly to stronger attacks, e.g., larger perturbations or other threat models. In this paper, we introduce confidence-calibrated adversarial training (CCAT) where the key idea is to enforce that the confidence on adversarial examples decays with their distance to the attacked examples. We show that CCAT preserves better the accuracy of normal training while robustness against adversarial examples is achieved via confidence thresholding, i.e., detecting adversarial examples based on their confidence. Most importantly, in strong contrast to adversarial training, the robustness of CCAT generalizes to larger perturbations and other threat models, not encountered during training. For evaluation, we extend the commonly used robust test error to our detection setting, present an adaptive attack with backtracking and allow the attacker to select, per test example, the worst-case adversarial example from multiple black- and white-box attacks. We present experimental results using $L_\infty$, $L_2$, $L_1$ and $L_0$ attacks on MNIST, SVHN and Cifar10.