 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing and Measuring the Geometry of BERT
Jun 06, 2019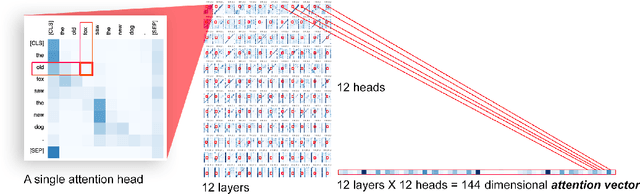
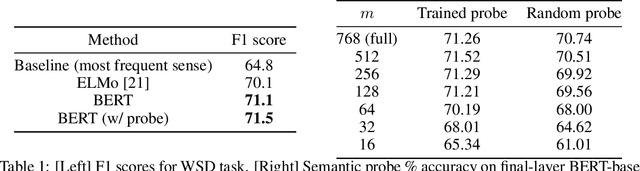
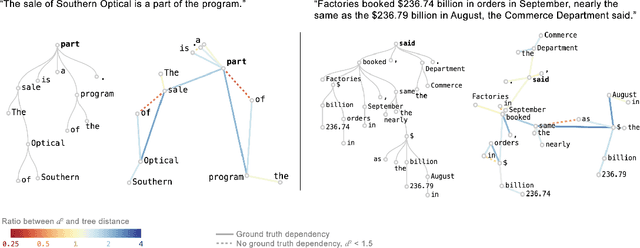
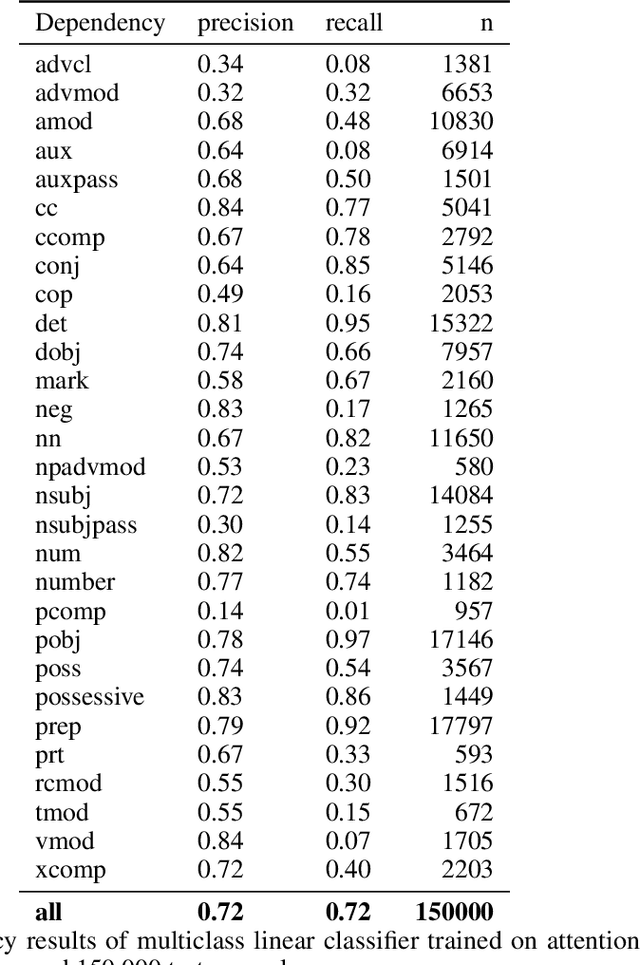
Transformer architectures show significant promise for natural language processing. Given that a single pretrained model can be fine-tuned to perform well on many different tasks, these networks appear to extract generally useful linguistic features. A natural question is how such networks represent this information internally. This paper describes qualitative and quantitative investigations of one particularly effective model, BERT. At a high level, linguistic features seem to be represented in separate semantic and syntactic subspaces. We find evidence of a fine-grained geometric representation of word senses. We also present empirical descriptions of syntactic representations in both attention matrices and individual word embeddings, as well as a mathematical argument to explain the geometry of these representations.
Do Neural Networks Show Gestalt Phenomena? An Exploration of the Law of Closure
Mar 21, 2019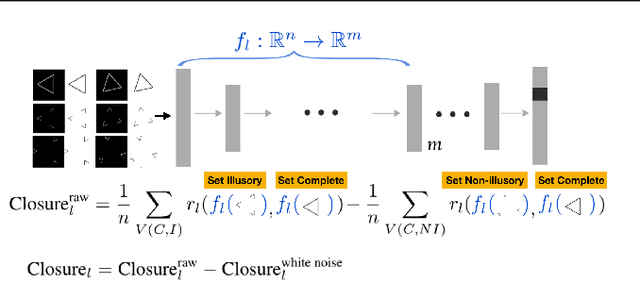
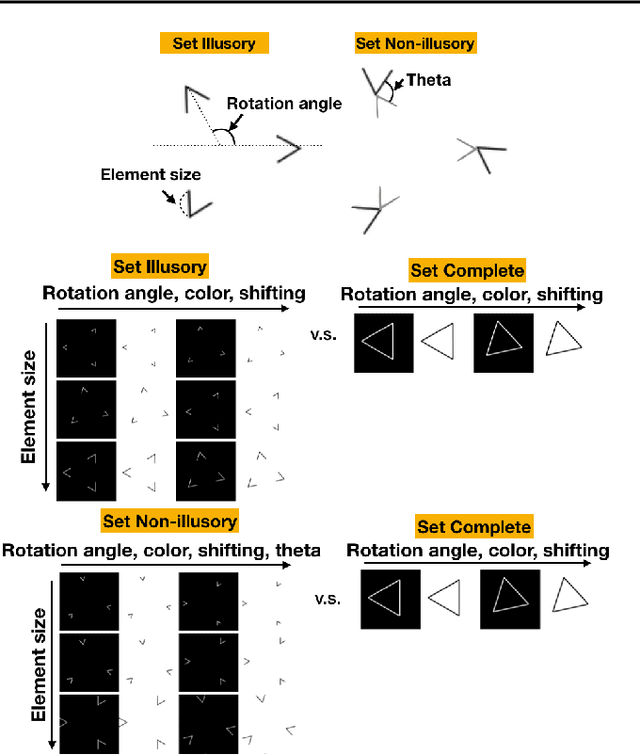
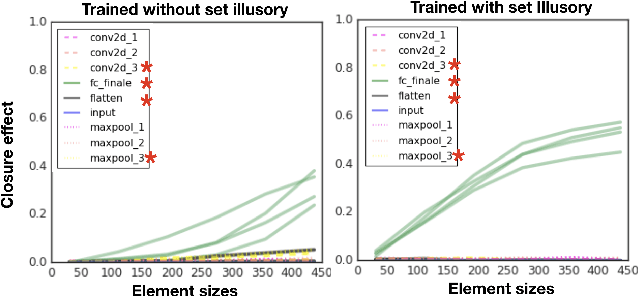
One characteristic of human visual perception is the presence of `Gestalt phenomena,' that is, that the whole is something other than the sum of its parts. A natural question is whether image-recognition networks show similar effects. Our paper investigates one particular type of Gestalt phenomenon, the law of closure, in the context of a feedforward image classification neural network (NN). This is a robust effect in human perception, but experiments typically rely on measurements (e.g., reaction time) that are not available for artificial neural nets. We describe a protocol for identifying closure effect in NNs, and report on the results of experiments with simple visual stimuli. Our findings suggest that NNs trained with natural images do exhibit closure, in contrast to networks with randomized weights or networks that have been trained on visually random data. Furthermore, the closure effect reflects something beyond good feature extraction; it is correlated with the network's higher layer features and ability to generalize.
Automating Interpretability: Discovering and Testing Visual Concepts Learned by Neural Networks
Feb 07, 2019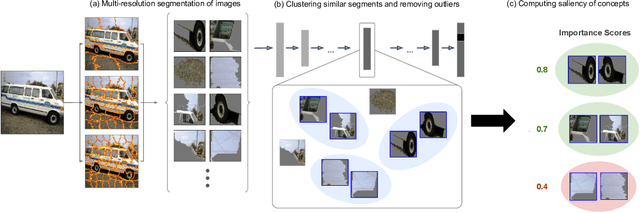


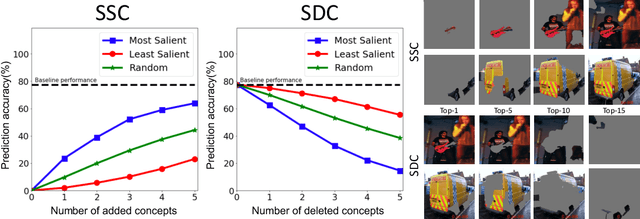
Interpretability has become an important topic of research as more machine learning (ML) models are deployed and widely used to make important decisions. Due to it's complexity, i For high-stakes domains such as medical, providing intuitive explanations that can be consumed by domain experts without ML expertise becomes crucial. To this demand, concept-based methods (e.g., TCAV) were introduced to provide explanations using user-chosen high-level concepts rather than individual input features. While these methods successfully leverage rich representations learned by the networks to reveal how human-defined concepts are related to the prediction, they require users to select concepts of their choice and collect labeled examples of those concepts. In this work, we introduce DTCAV (Discovery TCAV) a global concept-based interpretability method that can automatically discover concepts as image segments, along with each concept's estimated importance for a deep neural network's predictions. We validate that discovered concepts are as coherent to humans as hand-labeled concepts. We also show that the discovered concepts carry significant signal for prediction by analyzing a network's performance with stitched/added/deleted concepts. DTCAV results revealed a number of undesirable correlations (e.g., a basketball player's jersey was a more important concept for predicting the basketball class than the ball itself) and show the potential shallow reasoning of these networks.
An Evaluation of the Human-Interpretability of Explanation
Jan 31, 2019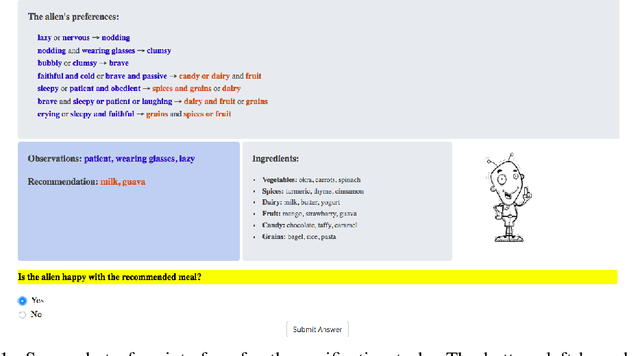
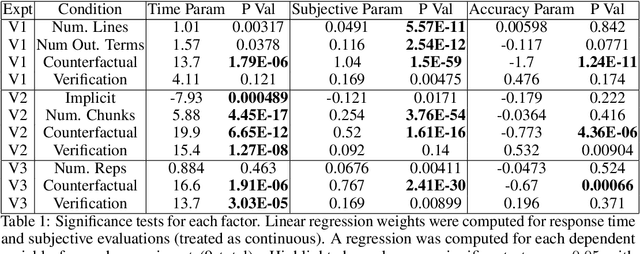
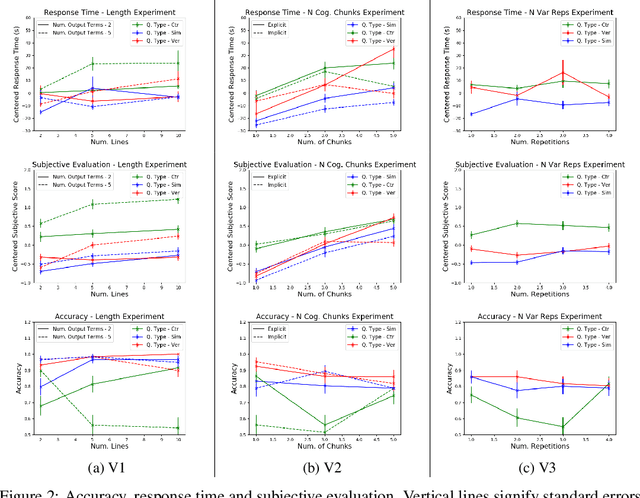
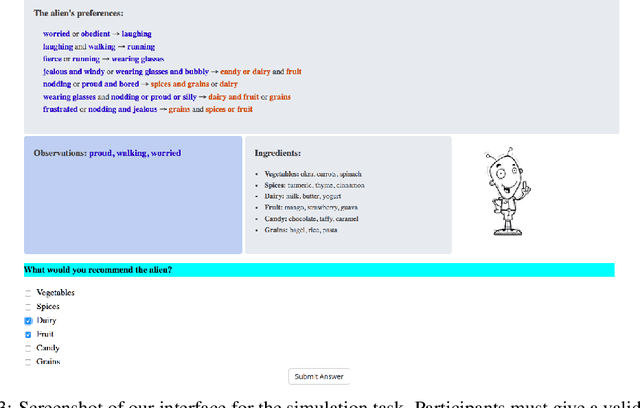
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable under three specific tasks that users may perform with machine learning systems: simulation of the response, verification of a suggested response, and determining whether the correctness of a suggested response changes under a change to the inputs. Through carefully controlled human-subject experiments, we identify regularizers that can be used to optimize for the interpretability of machine learning systems. Our results show that the type of complexity matters: cognitive chunks (newly defined concepts) affect performance more than variable repetitions, and these trends are consistent across tasks and domains. This suggests that there may exist some common design principles for explanation systems.
Human-in-the-Loop Interpretability Prior
Oct 30, 2018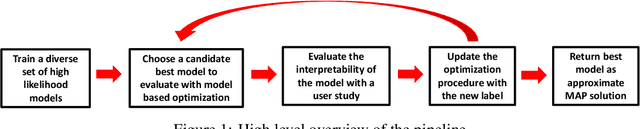
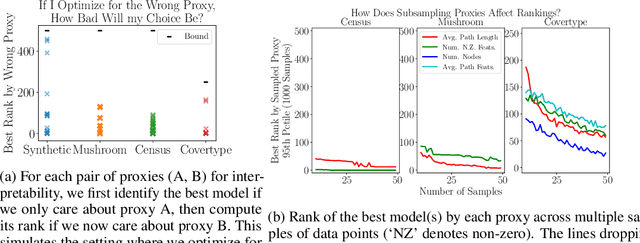
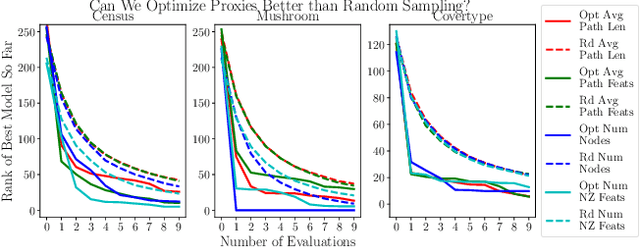
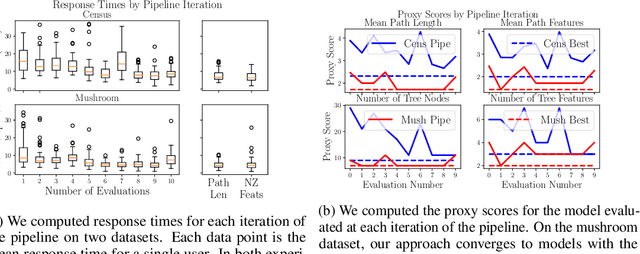
We often desire our models to be interpretable as well as accurate. Prior work on optimizing models for interpretability has relied on easy-to-quantify proxies for interpretability, such as sparsity or the number of operations required. In this work, we optimize for interpretability by directly including humans in the optimization loop. We develop an algorithm that minimizes the number of user studies to find models that are both predictive and interpretable and demonstrate our approach on several data sets. Our human subjects results show trends towards different proxy notions of interpretability on different datasets, which suggests that different proxies are preferred on different tasks.
Sanity Checks for Saliency Maps
Oct 28, 2018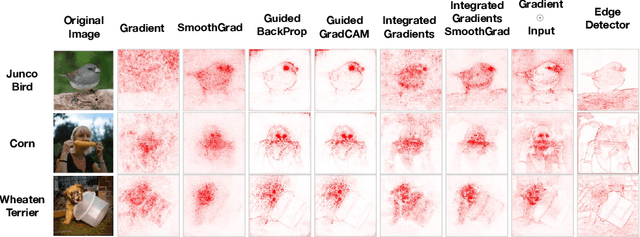
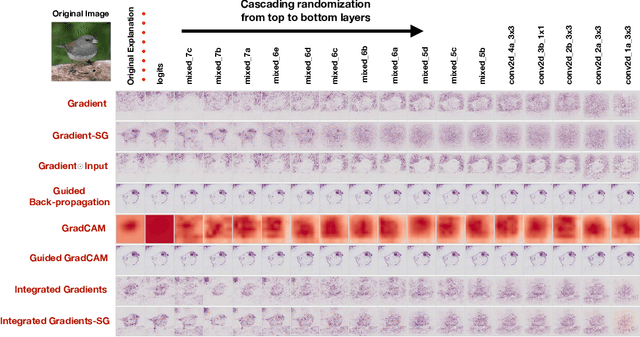
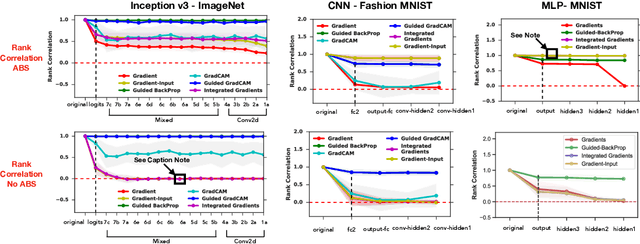
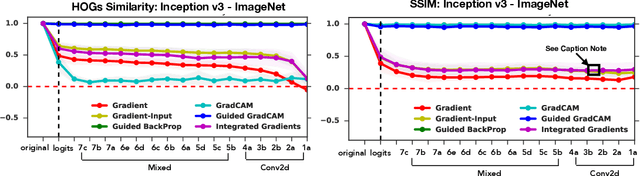
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.
To Trust Or Not To Trust A Classifier
Oct 26, 2018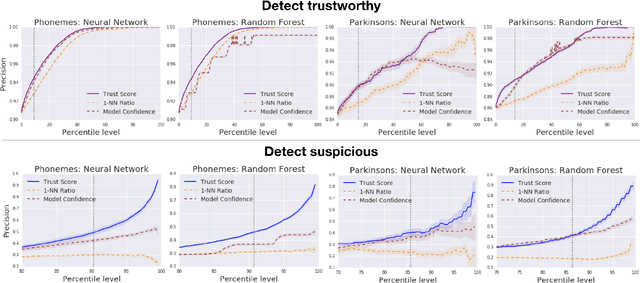
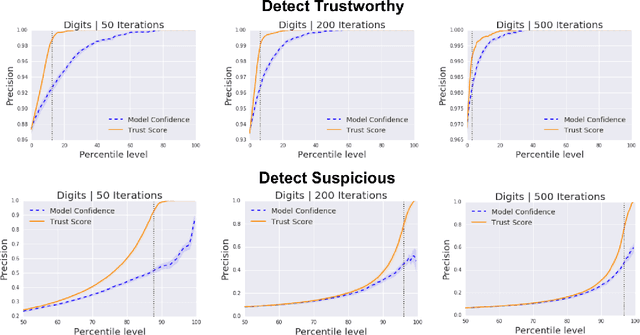
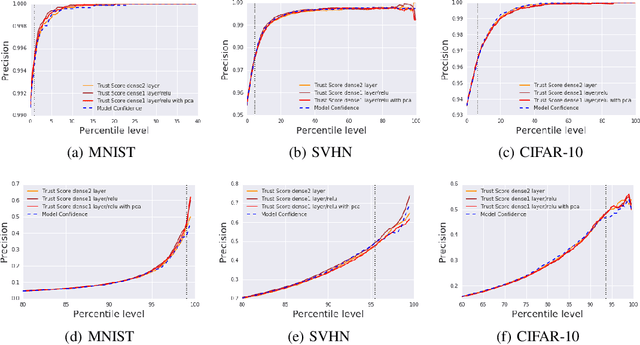
Knowing when a classifier's prediction can be trusted is useful in many applications and critical for safely using AI. While the bulk of the effort in machine learning research has been towards improving classifier performance, understanding when a classifier's predictions should and should not be trusted has received far less attention. The standard approach is to use the classifier's discriminant or confidence score; however, we show there exists an alternative that is more effective in many situations. We propose a new score, called the trust score, which measures the agreement between the classifier and a modified nearest-neighbor classifier on the testing example. We show empirically that high (low) trust scores produce surprisingly high precision at identifying correctly (incorrectly) classified examples, consistently outperforming the classifier's confidence score as well as many other baselines. Further, under some mild distributional assumptions, we show that if the trust score for an example is high (low), the classifier will likely agree (disagree) with the Bayes-optimal classifier. Our guarantees consist of non-asymptotic rates of statistical consistency under various nonparametric settings and build on recent developments in topological data analysis.
Interpreting Black Box Predictions using Fisher Kernels
Oct 23, 2018

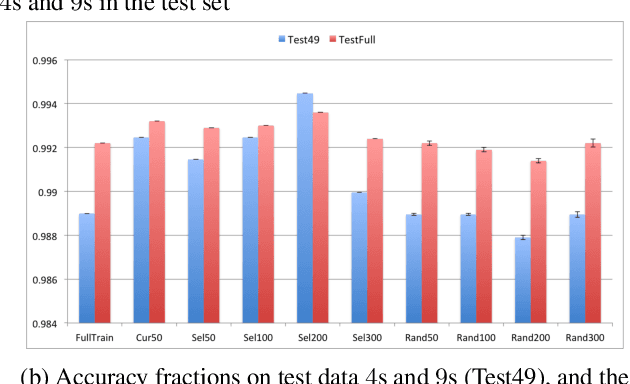
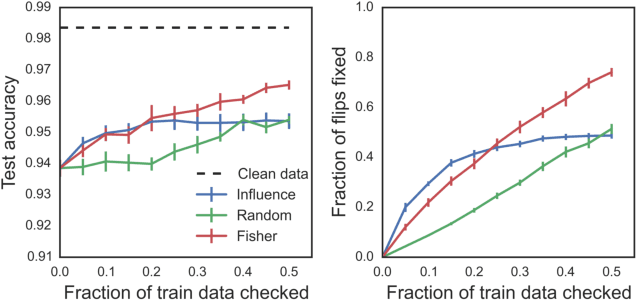
Research in both machine learning and psychology suggests that salient examples can help humans to interpret learning models. To this end, we take a novel look at black box interpretation of test predictions in terms of training examples. Our goal is to ask `which training examples are most responsible for a given set of predictions'? To answer this question, we make use of Fisher kernels as the defining feature embedding of each data point, combined with Sequential Bayesian Quadrature (SBQ) for efficient selection of examples. In contrast to prior work, our method is able to seamlessly handle any sized subset of test predictions in a principled way. We theoretically analyze our approach, providing novel convergence bounds for SBQ over discrete candidate atoms. Our approach recovers the application of influence functions for interpretability as a special case yielding novel insights from this connection. We also present applications of the proposed approach to three use cases: cleaning training data, fixing mislabeled examples and data summarization.
Local Explanation Methods for Deep Neural Networks Lack Sensitivity to Parameter Values
Oct 08, 2018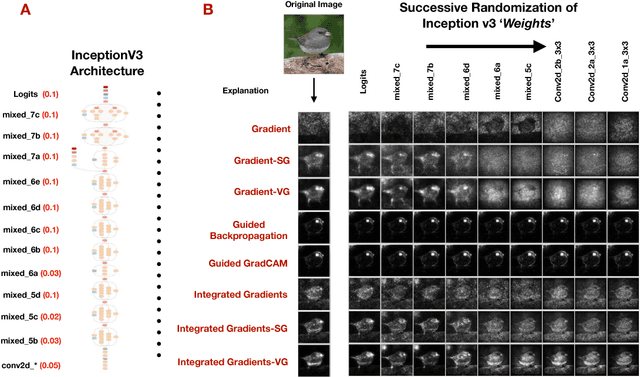
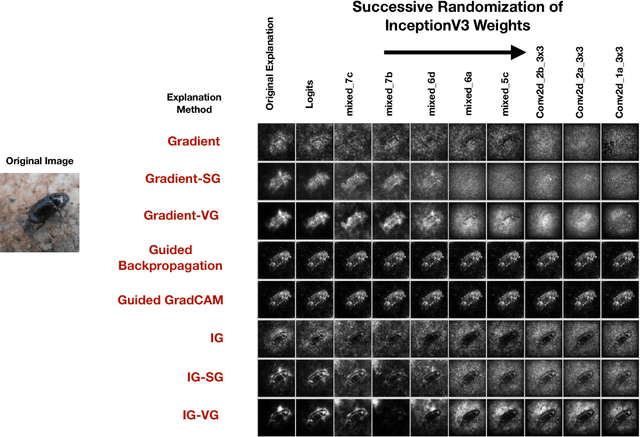
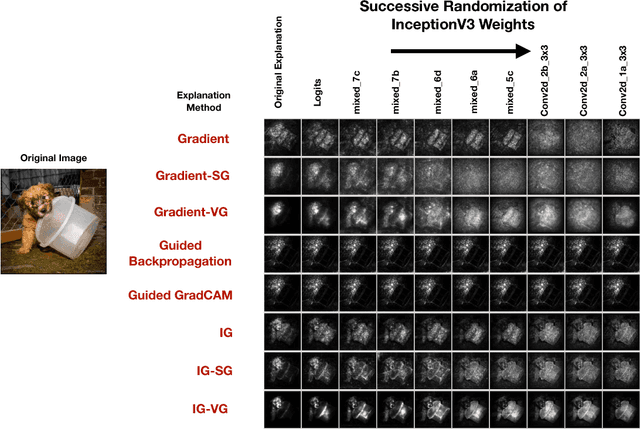
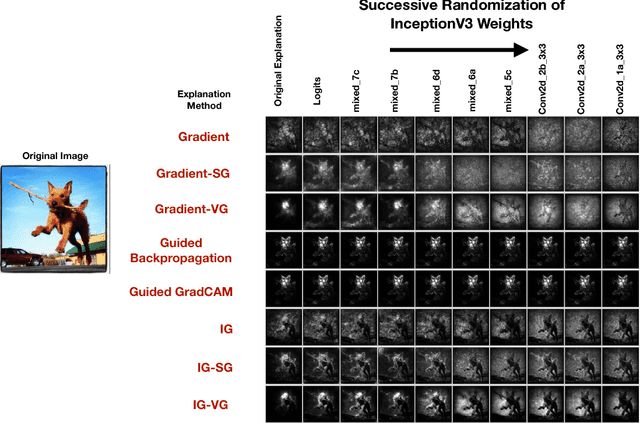
Explaining the output of a complicated machine learning model like a deep neural network (DNN) is a central challenge in machine learning. Several proposed local explanation methods address this issue by identifying what dimensions of a single input are most responsible for a DNN's output. The goal of this work is to assess the sensitivity of local explanations to DNN parameter values. Somewhat surprisingly, we find that DNNs with randomly-initialized weights produce explanations that are both visually and quantitatively similar to those produced by DNNs with learned weights. Our conjecture is that this phenomenon occurs because these explanations are dominated by the lower level features of a DNN, and that a DNN's architecture provides a strong prior which significantly affects the representations learned at these lower layers. NOTE: This work is now subsumed by our recent manuscript, Sanity Checks for Saliency Maps (to appear NIPS 2018), where we expand on findings and address concerns raised in Sundararajan et. al. (2018).
Proceedings of the 2018 ICML Workshop on Human Interpretability in Machine Learning
Jul 03, 2018This is the Proceedings of the 2018 ICML Workshop on Human Interpretability in Machine Learning (WHI 2018), which was held in Stockholm, Sweden, July 14, 2018. Invited speakers were Barbara Engelhardt, Cynthia Rudin, Fernanda Vi\'egas, and Martin Wattenberg.