 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cramer Distance as a Solution to Biased Wasserstein Gradients
May 30, 2017
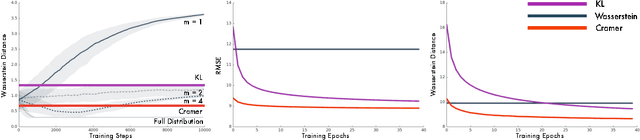

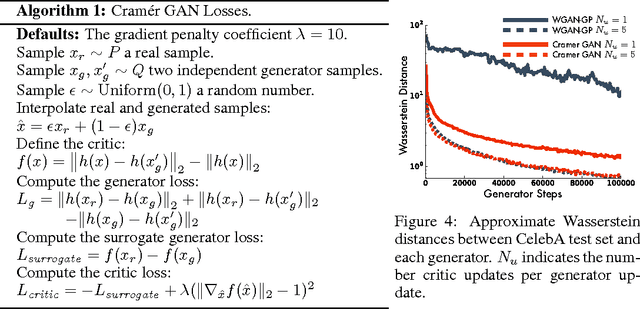
The Wasserstein probability metric has received much attention from the machine learning community. Unlike the Kullback-Leibler divergence, which strictly measures change in probability, the Wasserstein metric reflects the underlying geometry between outcomes. The value of being sensitive to this geometry has been demonstrated, among others, in ordinal regression and generative modelling. In this paper we describe three natural properties of probability divergences that reflect requirements from machine learning: sum invariance, scale sensitivity, and unbiased sample gradients. The Wasserstein metric possesses the first two properties but, unlike the Kullback-Leibler divergence, does not possess the third. We provide empirical evidence suggesting that this is a serious issue in practice. Leveraging insights from probabilistic forecasting we propose an alternative to the Wasserstein metric, the Cram\'er distance. We show that the Cram\'er distance possesses all three desired properties, combining the best of the Wasserstein and Kullback-Leibler divergences. To illustrate the relevance of the Cram\'er distance in practice we design a new algorithm, the Cram\'er Generative Adversarial Network (GAN), and show that it performs significantly better than the related Wasserstein GAN.
Comparison of Maximum Likelihood and GAN-based training of Real NVPs
May 15, 2017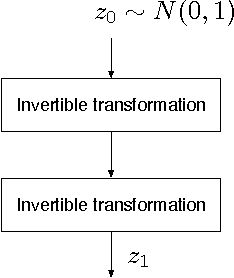


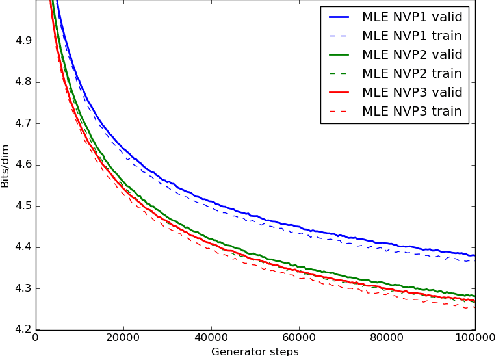
We train a generator by maximum likelihood and we also train the same generator architecture by Wasserstein GAN. We then compare the generated samples, exact log-probability densities and approximate Wasserstein distances. We show that an independent critic trained to approximate Wasserstein distance between the validation set and the generator distribution helps detect overfitting. Finally, we use ideas from the one-shot learning literature to develop a novel fast learning critic.
Learning Deep Nearest Neighbor Representations Using Differentiable Boundary Trees
Feb 28, 2017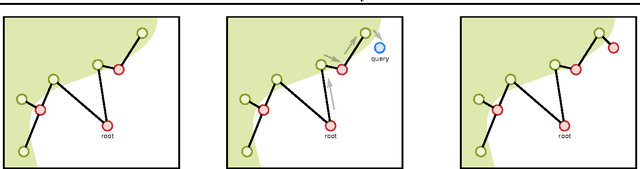
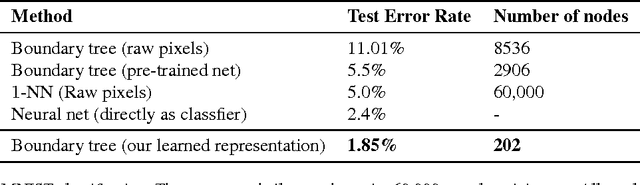
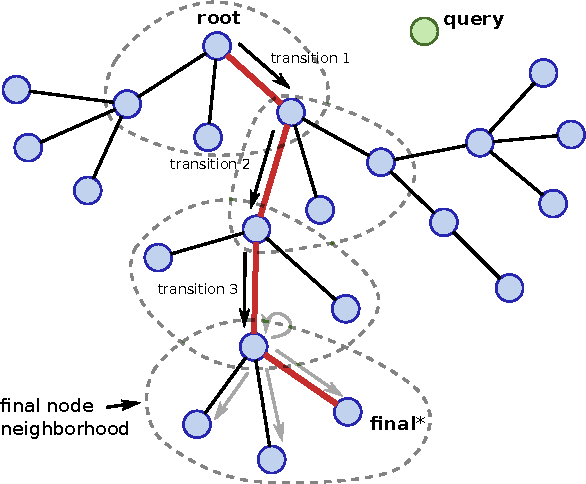
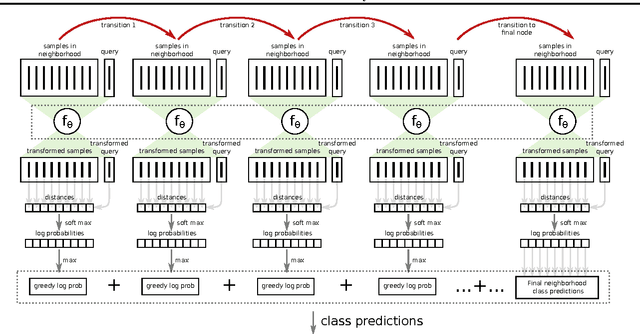
Nearest neighbor (kNN) methods have been gaining popularity in recent years in light of advances in hardware and efficiency of algorithms. There is a plethora of methods to choose from today, each with their own advantages and disadvantages. One requirement shared between all kNN based methods is the need for a good representation and distance measure between samples. We introduce a new method called differentiable boundary tree which allows for learning deep kNN representations. We build on the recently proposed boundary tree algorithm which allows for efficient nearest neighbor classification, regression and retrieval. By modelling traversals in the tree as stochastic events, we are able to form a differentiable cost function which is associated with the tree's predictions. Using a deep neural network to transform the data and back-propagating through the tree allows us to learn good representations for kNN methods. We demonstrate that our method is able to learn suitable representations allowing for very efficient trees with a clearly interpretable structure.
Learning in Implicit Generative Models
Feb 27, 2017
Generative adversarial networks (GANs) provide an algorithmic framework for constructing generative models with several appealing properties: they do not require a likelihood function to be specified, only a generating procedure; they provide samples that are sharp and compelling; and they allow us to harness our knowledge of building highly accurate neural network classifiers. Here, we develop our understanding of GANs with the aim of forming a rich view of this growing area of machine learning---to build connections to the diverse set of statistical thinking on this topic, of which much can be gained by a mutual exchange of ideas. We frame GANs within the wider landscape of algorithms for learning in implicit generative models--models that only specify a stochastic procedure with which to generate data--and relate these ideas to modelling problems in related fields, such as econometrics and approximate Bayesian computation. We develop likelihood-free inference methods and highlight hypothesis testing as a principle for learning in implicit generative models, using which we are able to derive the objective function used by GANs, and many other related objectives. The testing viewpoint directs our focus to the general problem of density ratio estimation. There are four approaches for density ratio estimation, one of which is a solution using classifiers to distinguish real from generated data. Other approaches such as divergence minimisation and moment matching have also been explored in the GAN literature, and we synthesise these views to form an understanding in terms of the relationships between them and the wider literature, highlighting avenues for future exploration and cross-pollination.
The Mondrian Kernel
Jun 16, 2016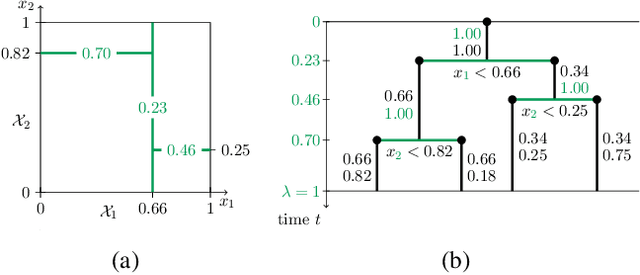
We introduce the Mondrian kernel, a fast random feature approximation to the Laplace kernel. It is suitable for both batch and online learning, and admits a fast kernel-width-selection procedure as the random features can be re-used efficiently for all kernel widths. The features are constructed by sampling trees via a Mondrian process [Roy and Teh, 2009], and we highlight the connection to Mondrian forests [Lakshminarayanan et al., 2014], where trees are also sampled via a Mondrian process, but fit independently. This link provides a new insight into the relationship between kernel methods and random forests.
Mondrian Forests for Large-Scale Regression when Uncertainty Matters
May 27, 2016
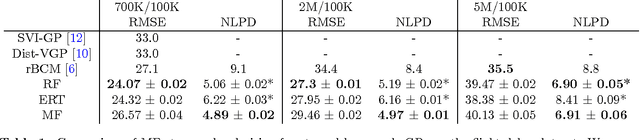
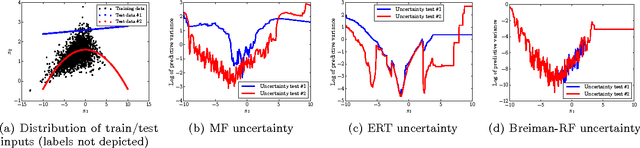
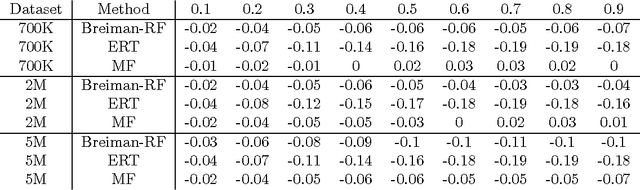
Many real-world regression problems demand a measure of the uncertainty associated with each prediction. Standard decision forests deliver efficient state-of-the-art predictive performance, but high-quality uncertainty estimates are lacking. Gaussian processes (GPs) deliver uncertainty estimates, but scaling GPs to large-scale data sets comes at the cost of approximating the uncertainty estimates. We extend Mondrian forests, first proposed by Lakshminarayanan et al. (2014) for classification problems, to the large-scale non-parametric regression setting. Using a novel hierarchical Gaussian prior that dovetails with the Mondrian forest framework, we obtain principled uncertainty estimates, while still retaining the computational advantages of decision forests. Through a combination of illustrative examples, real-world large-scale datasets, and Bayesian optimization benchmarks, we demonstrate that Mondrian forests outperform approximate GPs on large-scale regression tasks and deliver better-calibrated uncertainty assessments than decision-forest-based methods.
Approximate Inference with the Variational Holder Bound
Jun 19, 2015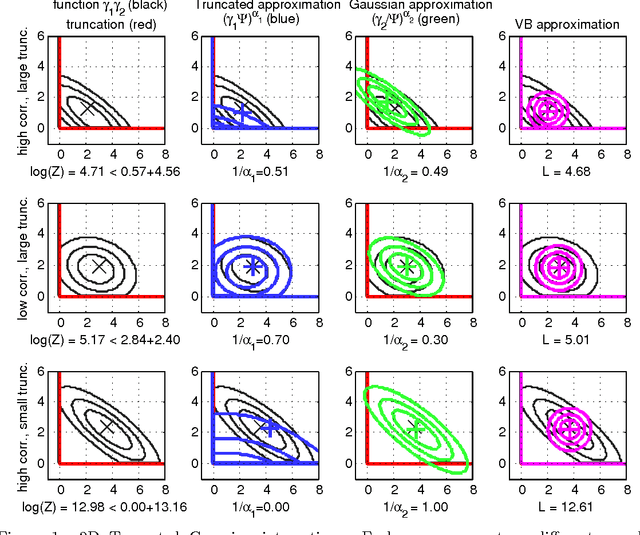

We introduce the Variational Holder (VH) bound as an alternative to Variational Bayes (VB) for approximate Bayesian inference. Unlike VB which typically involves maximization of a non-convex lower bound with respect to the variational parameters, the VH bound involves minimization of a convex upper bound to the intractable integral with respect to the variational parameters. Minimization of the VH bound is a convex optimization problem; hence the VH method can be applied using off-the-shelf convex optimization algorithms and the approximation error of the VH bound can also be analyzed using tools from convex optimization literature. We present experiments on the task of integrating a truncated multivariate Gaussian distribution and compare our method to VB, EP and a state-of-the-art numerical integration method for this problem.
Kernel-Based Just-In-Time Learning for Passing Expectation Propagation Messages
Jun 09, 2015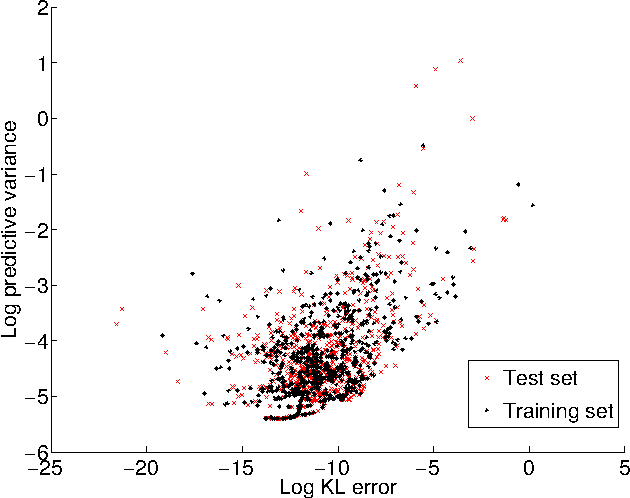
We propose an efficient nonparametric strategy for learning a message operator in expectation propagation (EP), which takes as input the set of incoming messages to a factor node, and produces an outgoing message as output. This learned operator replaces the multivariate integral required in classical EP, which may not have an analytic expression. We use kernel-based regression, which is trained on a set of probability distributions representing the incoming messages, and the associated outgoing messages. The kernel approach has two main advantages: first, it is fast, as it is implemented using a novel two-layer random feature representation of the input message distributions; second, it has principled uncertainty estimates, and can be cheaply updated online, meaning it can request and incorporate new training data when it encounters inputs on which it is uncertain. In experiments, our approach is able to solve learning problems where a single message operator is required for multiple, substantially different data sets (logistic regression for a variety of classification problems), where it is essential to accurately assess uncertainty and to efficiently and robustly update the message operator.
Particle Gibbs for Bayesian Additive Regression Trees
Feb 16, 2015
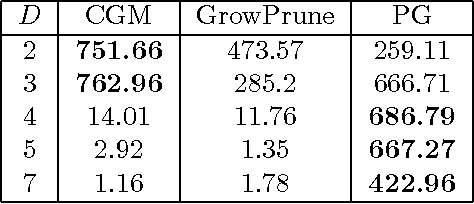
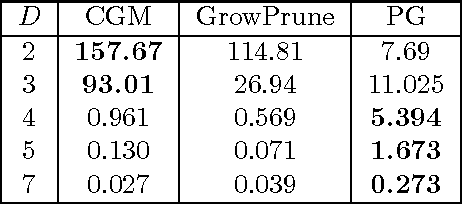
Additive regression trees are flexible non-parametric models and popular off-the-shelf tools for real-world non-linear regression. In application domains, such as bioinformatics, where there is also demand for probabilistic predictions with measures of uncertainty, the Bayesian additive regression trees (BART) model, introduced by Chipman et al. (2010), is increasingly popular. As data sets have grown in size, however, the standard Metropolis-Hastings algorithms used to perform inference in BART are proving inadequate. In particular, these Markov chains make local changes to the trees and suffer from slow mixing when the data are high-dimensional or the best fitting trees are more than a few layers deep. We present a novel sampler for BART based on the Particle Gibbs (PG) algorithm (Andrieu et al., 2010) and a top-down particle filtering algorithm for Bayesian decision trees (Lakshminarayanan et al., 2013). Rather than making local changes to individual trees, the PG sampler proposes a complete tree to fit the residual. Experiments show that the PG sampler outperforms existing samplers in many settings.
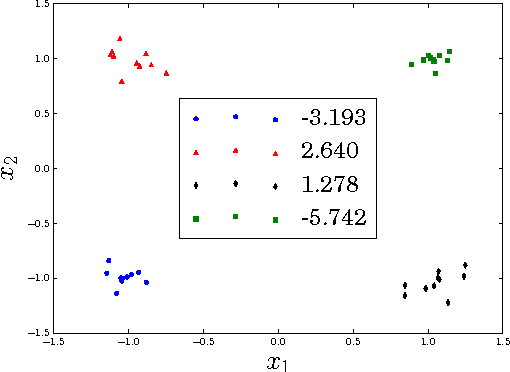
Mondrian Forests: Efficient Online Random Forests
Feb 16, 2015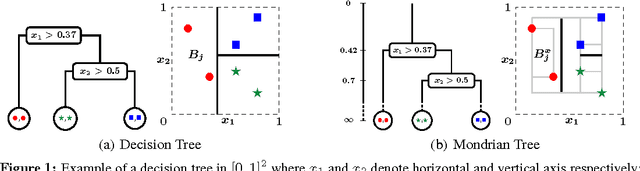
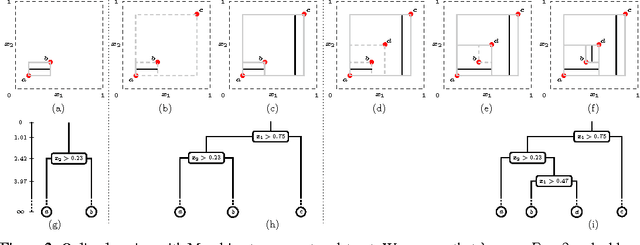
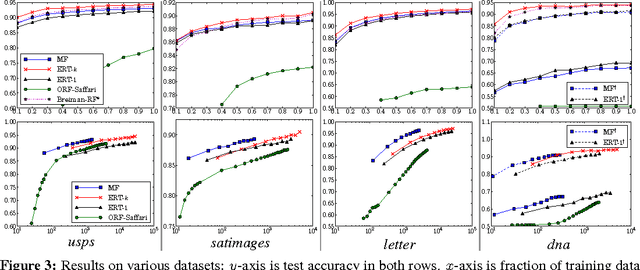
Ensembles of randomized decision trees, usually referred to as random forests, are widely used for classification and regression tasks in machine learning and statistics. Random forests achieve competitive predictive performance and are computationally efficient to train and test, making them excellent candidates for real-world prediction tasks. The most popular random forest variants (such as Breiman's random forest and extremely randomized trees) operate on batches of training data. Online methods are now in greater demand. Existing online random forests, however, require more training data than their batch counterpart to achieve comparable predictive performance. In this work, we use Mondrian processes (Roy and Teh, 2009) to construct ensembles of random decision trees we call Mondrian forests. Mondrian forests can be grown in an incremental/online fashion and remarkably, the distribution of online Mondrian forests is the same as that of batch Mondrian forests. Mondrian forests achieve competitive predictive performance comparable with existing online random forests and periodically re-trained batch random forests, while being more than an order of magnitude faster, thus representing a better computation vs accuracy tradeoff.