 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025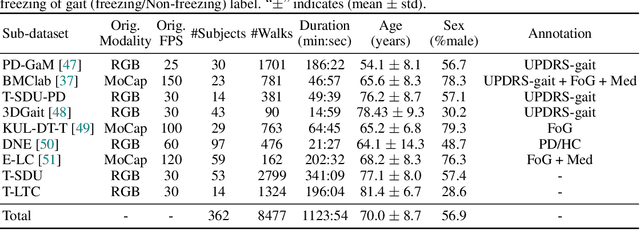
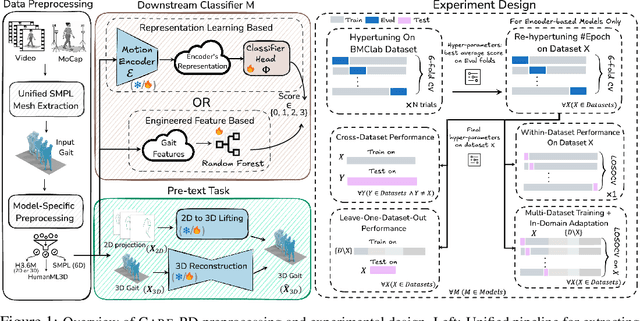
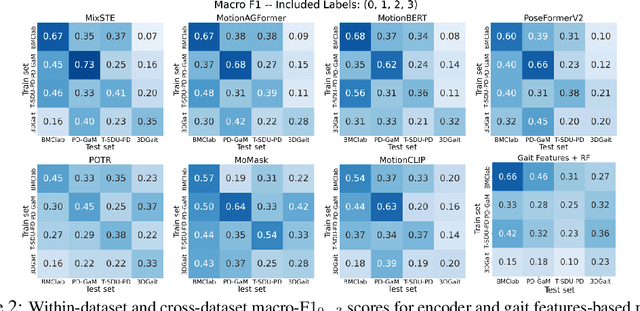
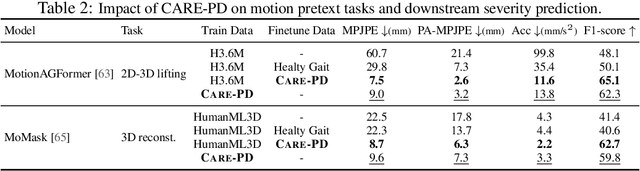
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Mitigating Multi-Sequence 3D Prostate MRI Data Scarcity through Domain Adaptation using Locally-Trained Latent Diffusion Models for Prostate Cancer Detection
Jul 08, 2025Objective: Latent diffusion models (LDMs) could mitigate data scarcity challenges affecting machine learning development for medical image interpretation. The recent CCELLA LDM improved prostate cancer detection performance using synthetic MRI for classifier training but was limited to the axial T2-weighted (AxT2) sequence, did not investigate inter-institutional domain shift, and prioritized radiology over histopathology outcomes. We propose CCELLA++ to address these limitations and improve clinical utility. Methods: CCELLA++ expands CCELLA for simultaneous biparametric prostate MRI (bpMRI) generation, including the AxT2, high b-value diffusion series (HighB) and apparent diffusion coefficient map (ADC). Domain adaptation was investigated by pretraining classifiers on real or LDM-generated synthetic data from an internal institution, followed with fine-tuning on progressively smaller fractions of an out-of-distribution, external dataset. Results: CCELLA++ improved 3D FID for HighB and ADC but not AxT2 (0.013, 0.012, 0.063 respectively) sequences compared to CCELLA (0.060). Classifier pretraining with CCELLA++ bpMRI outperformed real bpMRI in AP and AUC for all domain adaptation scenarios. CCELLA++ pretraining achieved highest classifier performance below 50% (n=665) external dataset volume. Conclusion: Synthetic bpMRI generated by our method can improve downstream classifier generalization and performance beyond real bpMRI or CCELLA-generated AxT2-only images. Future work should seek to quantify medical image sample quality, balance multi-sequence LDM training, and condition the LDM with additional information. Significance: The proposed CCELLA++ LDM can generate synthetic bpMRI that outperforms real data for domain adaptation with a limited target institution dataset. Our code is available at https://github.com/grabkeem/CCELLA-plus-plus
Prompt-Guided Latent Diffusion with Predictive Class Conditioning for 3D Prostate MRI Generation
Jun 11, 2025Latent diffusion models (LDM) could alleviate data scarcity challenges affecting machine learning development for medical imaging. However, medical LDM training typically relies on performance- or scientific accessibility-limiting strategies including a reliance on short-prompt text encoders, the reuse of non-medical LDMs, or a requirement for fine-tuning with large data volumes. We propose a Class-Conditioned Efficient Large Language model Adapter (CCELLA) to address these limitations. CCELLA is a novel dual-head conditioning approach that simultaneously conditions the LDM U-Net with non-medical large language model-encoded text features through cross-attention and with pathology classification through the timestep embedding. We also propose a joint loss function and a data-efficient LDM training framework. In combination, these strategies enable pathology-conditioned LDM training for high-quality medical image synthesis given limited data volume and human data annotation, improving LDM performance and scientific accessibility. Our method achieves a 3D FID score of 0.025 on a size-limited prostate MRI dataset, significantly outperforming a recent foundation model with FID 0.071. When training a classifier for prostate cancer prediction, adding synthetic images generated by our method to the training dataset improves classifier accuracy from 69% to 74%. Training a classifier solely on our method's synthetic images achieved comparable performance to training on real images alone.
Token Perturbation Guidance for Diffusion Models
Jun 10, 2025Classifier-free guidance (CFG) has become an essential component of modern diffusion models to enhance both generation quality and alignment with input conditions. However, CFG requires specific training procedures and is limited to conditional generation. To address these limitations, we propose Token Perturbation Guidance (TPG), a novel method that applies perturbation matrices directly to intermediate token representations within the diffusion network. TPG employs a norm-preserving shuffling operation to provide effective and stable guidance signals that improve generation quality without architectural changes. As a result, TPG is training-free and agnostic to input conditions, making it readily applicable to both conditional and unconditional generation. We further analyze the guidance term provided by TPG and show that its effect on sampling more closely resembles CFG compared to existing training-free guidance techniques. Extensive experiments on SDXL and Stable Diffusion 2.1 show that TPG achieves nearly a 2$\times$ improvement in FID for unconditional generation over the SDXL baseline, while closely matching CFG in prompt alignment. These results establish TPG as a general, condition-agnostic guidance method that brings CFG-like benefits to a broader class of diffusion models. The code is available at https://github.com/TaatiTeam/Token-Perturbation-Guidance
Red Teaming Large Language Models for Healthcare
May 01, 2025We present the design process and findings of the pre-conference workshop at the Machine Learning for Healthcare Conference (2024) entitled Red Teaming Large Language Models for Healthcare, which took place on August 15, 2024. Conference participants, comprising a mix of computational and clinical expertise, attempted to discover vulnerabilities -- realistic clinical prompts for which a large language model (LLM) outputs a response that could cause clinical harm. Red-teaming with clinicians enables the identification of LLM vulnerabilities that may not be recognised by LLM developers lacking clinical expertise. We report the vulnerabilities found, categorise them, and present the results of a replication study assessing the vulnerabilities across all LLMs provided.
LIFT: Latent Implicit Functions for Task- and Data-Agnostic Encoding
Mar 19, 2025Implicit Neural Representations (INRs) are proving to be a powerful paradigm in unifying task modeling across diverse data domains, offering key advantages such as memory efficiency and resolution independence. Conventional deep learning models are typically modality-dependent, often requiring custom architectures and objectives for different types of signals. However, existing INR frameworks frequently rely on global latent vectors or exhibit computational inefficiencies that limit their broader applicability. We introduce LIFT, a novel, high-performance framework that addresses these challenges by capturing multiscale information through meta-learning. LIFT leverages multiple parallel localized implicit functions alongside a hierarchical latent generator to produce unified latent representations that span local, intermediate, and global features. This architecture facilitates smooth transitions across local regions, enhancing expressivity while maintaining inference efficiency. Additionally, we introduce ReLIFT, an enhanced variant of LIFT that incorporates residual connections and expressive frequency encodings. With this straightforward approach, ReLIFT effectively addresses the convergence-capacity gap found in comparable methods, providing an efficient yet powerful solution to improve capacity and speed up convergence. Empirical results show that LIFT achieves state-of-the-art (SOTA) performance in generative modeling and classification tasks, with notable reductions in computational costs. Moreover, in single-task settings, the streamlined ReLIFT architecture proves effective in signal representations and inverse problem tasks.
Similarity-Aware Token Pruning: Your VLM but Faster
Mar 14, 2025The computational demands of Vision Transformers (ViTs) and Vision-Language Models (VLMs) remain a significant challenge due to the quadratic complexity of self-attention. While token pruning offers a promising solution, existing methods often introduce training overhead or fail to adapt dynamically across layers. We present SAINT, a training-free token pruning framework that leverages token similarity and a graph-based formulation to dynamically optimize pruning rates and redundancy thresholds. Through systematic analysis, we identify a universal three-stage token evolution process (aligner-explorer-aggregator) in transformers, enabling aggressive pruning in early stages without sacrificing critical information. For ViTs, SAINT doubles the throughput of ViT-H/14 at 224px with only 0.6% accuracy loss on ImageNet-1K, surpassing the closest competitor by 0.8%. For VLMs, we apply SAINT in three modes: ViT-only, LLM-only, and hybrid. SAINT reduces LLaVA-13B's tokens by 75%, achieving latency comparable to LLaVA-7B with less than 1% performance loss across benchmarks. Our work establishes a unified, practical framework for efficient inference in ViTs and VLMs.
STAF: Sinusoidal Trainable Activation Functions for Implicit Neural Representation
Feb 02, 2025Implicit Neural Representations (INRs) have emerged as a powerful framework for modeling continuous signals. The spectral bias of ReLU-based networks is a well-established limitation, restricting their ability to capture fine-grained details in target signals. While previous works have attempted to mitigate this issue through frequency-based encodings or architectural modifications, these approaches often introduce additional complexity and do not fully address the underlying challenge of learning high-frequency components efficiently. We introduce Sinusoidal Trainable Activation Functions (STAF), designed to directly tackle this limitation by enabling networks to adaptively learn and represent complex signals with higher precision and efficiency. STAF inherently modulates its frequency components, allowing for self-adaptive spectral learning. This capability significantly improves convergence speed and expressivity, making STAF highly effective for both signal representations and inverse problems. Through extensive evaluations, we demonstrate that STAF outperforms state-of-the-art (SOTA) methods in accuracy and reconstruction fidelity with superior Peak Signal-to-Noise Ratio (PSNR). These results establish STAF as a robust solution for overcoming spectral bias and the capacity-convergence gap, making it valuable for computer graphics and related fields. Our codebase is publicly accessible on the https://github.com/AlirezaMorsali/STAF.
STARS: Self-supervised Tuning for 3D Action Recognition in Skeleton Sequences
Jul 15, 2024



Self-supervised pretraining methods with masked prediction demonstrate remarkable within-dataset performance in skeleton-based action recognition. However, we show that, unlike contrastive learning approaches, they do not produce well-separated clusters. Additionally, these methods struggle with generalization in few-shot settings. To address these issues, we propose Self-supervised Tuning for 3D Action Recognition in Skeleton sequences (STARS). Specifically, STARS first uses a masked prediction stage using an encoder-decoder architecture. It then employs nearest-neighbor contrastive learning to partially tune the weights of the encoder, enhancing the formation of semantic clusters for different actions. By tuning the encoder for a few epochs, and without using hand-crafted data augmentations, STARS achieves state-of-the-art self-supervised results in various benchmarks, including NTU-60, NTU-120, and PKU-MMD. In addition, STARS exhibits significantly better results than masked prediction models in few-shot settings, where the model has not seen the actions throughout pretraining. Project page: https://soroushmehraban.github.io/stars/