 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotoQuilt: Training-Free Arbitrary-Resolution Photomosaics via Bootstrapped Tiled Denoising
Jun 29, 2026Photomosaics are large images whose local regions are seen as independent tiles while their overall arrangement forms a coherent scene. Generating them at high resolution, with every tile convincing in its own right, is computationally expensive, since the canvas must hold many detailed tiles at once. We present PhotoQuilt, a training-free framework that generates photomosaics at arbitrary resolution. Diffusion models struggle to satisfy both scales at once, as direct high-resolution generation is costly and tends toward one smooth image rather than a mosaic, while patch-based tiling keeps local detail but loses global structure. PhotoQuilt resolves this with a bootstrapped tiled denoising procedure. We first produce a global composition at low resolution to fix the layout, then upscale it in latent space and re-inject noise to restore generative capacity. Denoising proceeds within fixed tiles, so each forms its own image while the shared global structure holds them in one layout. Because tile generation is handled separately, PhotoQuilt scales to large canvases without quadratic attention cost. Experiments show that PhotoQuilt outperforms current baselines on both global structure and local realism.
SEGA: Spectral-Energy Guided Attention for Resolution Extrapolation in Diffusion Transformers
May 21, 2026Diffusion transformers (DiTs) have emerged as a dominant architecture for text-to-image generation, yet their performance drops when generating at resolutions beyond their training range. Existing training-free approaches mitigate this by modifying inference-time attention behavior, often through Rotary Position Embeddings (RoPE) extrapolation combined with attention scaling. However, these strategies apply a uniform and content-agnostic scaling across RoPE components with distinct frequency characteristics, inducing a trade-off between preserving global structure and recovering fine detail. We introduce SEGA, a training-free method that dynamically scales attention across RoPE components according to the latent's spatial-frequency structure at each denoising step. This adaptive scaling improves both structural coherence and fine-detail fidelity. Experiments show that SEGA consistently improves high-resolution synthesis across multiple target resolutions, outperforming state-of-the-art training-free baselines.
Puzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
CARE-PD: A Multi-Site Anonymized Clinical Dataset for Parkinson's Disease Gait Assessment
Oct 05, 2025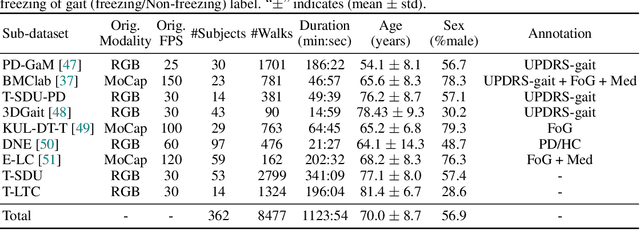
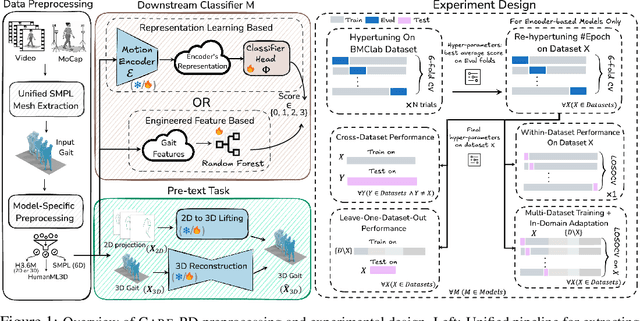
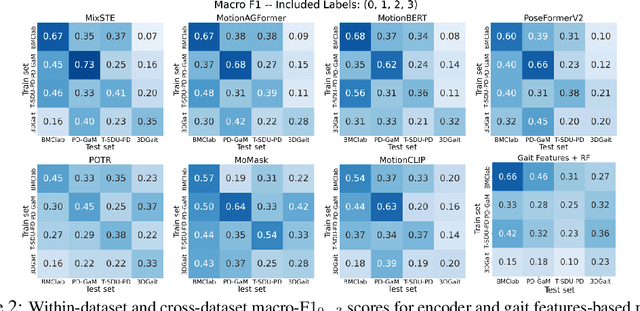
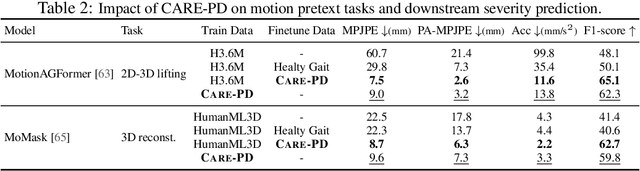
Objective gait assessment in Parkinson's Disease (PD) is limited by the absence of large, diverse, and clinically annotated motion datasets. We introduce CARE-PD, the largest publicly available archive of 3D mesh gait data for PD, and the first multi-site collection spanning 9 cohorts from 8 clinical centers. All recordings (RGB video or motion capture) are converted into anonymized SMPL meshes via a harmonized preprocessing pipeline. CARE-PD supports two key benchmarks: supervised clinical score prediction (estimating Unified Parkinson's Disease Rating Scale, UPDRS, gait scores) and unsupervised motion pretext tasks (2D-to-3D keypoint lifting and full-body 3D reconstruction). Clinical prediction is evaluated under four generalization protocols: within-dataset, cross-dataset, leave-one-dataset-out, and multi-dataset in-domain adaptation. To assess clinical relevance, we compare state-of-the-art motion encoders with a traditional gait-feature baseline, finding that encoders consistently outperform handcrafted features. Pretraining on CARE-PD reduces MPJPE (from 60.8mm to 7.5mm) and boosts PD severity macro-F1 by 17 percentage points, underscoring the value of clinically curated, diverse training data. CARE-PD and all benchmark code are released for non-commercial research at https://neurips2025.care-pd.ca/.
Token Perturbation Guidance for Diffusion Models
Jun 10, 2025Classifier-free guidance (CFG) has become an essential component of modern diffusion models to enhance both generation quality and alignment with input conditions. However, CFG requires specific training procedures and is limited to conditional generation. To address these limitations, we propose Token Perturbation Guidance (TPG), a novel method that applies perturbation matrices directly to intermediate token representations within the diffusion network. TPG employs a norm-preserving shuffling operation to provide effective and stable guidance signals that improve generation quality without architectural changes. As a result, TPG is training-free and agnostic to input conditions, making it readily applicable to both conditional and unconditional generation. We further analyze the guidance term provided by TPG and show that its effect on sampling more closely resembles CFG compared to existing training-free guidance techniques. Extensive experiments on SDXL and Stable Diffusion 2.1 show that TPG achieves nearly a 2$\times$ improvement in FID for unconditional generation over the SDXL baseline, while closely matching CFG in prompt alignment. These results establish TPG as a general, condition-agnostic guidance method that brings CFG-like benefits to a broader class of diffusion models. The code is available at https://github.com/TaatiTeam/Token-Perturbation-Guidance