 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVIS: Adaptive Test-Time Scaling for Vision-Language Models
Jun 10, 2026Modern Vision-Language Models (VLMs) benefit from chain-of-thought prompting and test-time scaling, but these gains often come with prohibitive inference cost due to large visual contexts and long decoding chains. We view this cost through two coupled axes: Visual Context Scaling (VCS), which controls how much visual evidence is passed to the language model, and Visual Reasoning Scaling (VRS), which controls how much inference-time reasoning search is performed. Existing methods typically optimize one axis at a time, leaving the joint allocation of compute across these axes underexplored. We introduce Adaptive Visual Inference Scaling (AVIS), a lightweight policy that adapts both VCS and VRS per query. AVIS realizes VCS through Key Diversity Visual (KDV) pruning, a training-free $O(N)$ key-based rule for removing redundant visual tokens before prefilling, and realizes VRS through adaptive self-consistency, using a learned difficulty predictor to select the number of reasoning rollouts. AVIS is deployment-friendly and compatible with shared-prefill inference, where all rollouts reuse a single prefilling pass and KV cache. Across diverse image and video reasoning benchmarks, AVIS improves the accuracy--compute trade-off relative to VCS-only and VRS-only baselines, and remains effective on top of RL post-trained VLMs while keeping compute and latency low.
Puzzle Curriculum GRPO for Vision-Centric Reasoning
Dec 16, 2025Recent reinforcement learning (RL) approaches like outcome-supervised GRPO have advanced chain-of-thought reasoning in Vision Language Models (VLMs), yet key issues linger: (i) reliance on costly and noisy hand-curated annotations or external verifiers; (ii) flat and sparse reward schemes in GRPO; and (iii) logical inconsistency between a chain's reasoning and its final answer. We present Puzzle Curriculum GRPO (PC-GRPO), a supervision-free recipe for RL with Verifiable Rewards (RLVR) that strengthens visual reasoning in VLMs without annotations or external verifiers. PC-GRPO replaces labels with three self-supervised puzzle environments: PatchFit, Rotation (with binary rewards) and Jigsaw (with graded partial credit mitigating reward sparsity). To counter flat rewards and vanishing group-relative advantages, we introduce a difficulty-aware curriculum that dynamically weights samples and peaks at medium difficulty. We further monitor Reasoning-Answer Consistency (RAC) during post-training: mirroring reports for vanilla GRPO in LLMs, RAC typically rises early then degrades; our curriculum delays this decline, and consistency-enforcing reward schemes further boost RAC. RAC correlates with downstream accuracy. Across diverse benchmarks and on Qwen-7B and Qwen-3B backbones, PC-GRPO improves reasoning quality, training stability, and end-task accuracy, offering a practical path to scalable, verifiable, and interpretable RL post-training for VLMs.
PSENet: Progressive Self-Enhancement Network for Unsupervised Extreme-Light Image Enhancement
Oct 03, 2022
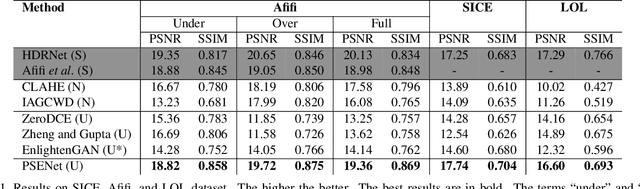
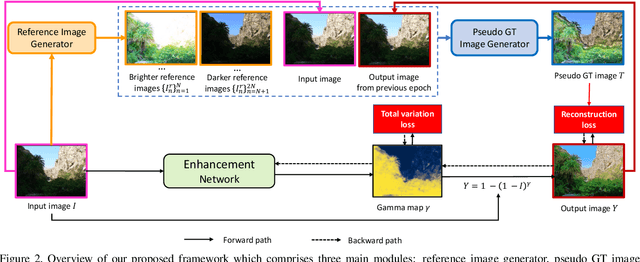

The extremes of lighting (e.g. too much or too little light) usually cause many troubles for machine and human vision. Many recent works have mainly focused on under-exposure cases where images are often captured in low-light conditions (e.g. nighttime) and achieved promising results for enhancing the quality of images. However, they are inferior to handling images under over-exposure. To mitigate this limitation, we propose a novel unsupervised enhancement framework which is robust against various lighting conditions while does not require any well-exposed images to serve as the ground-truths. Our main concept is to construct pseudo-ground-truth images synthesized from multiple source images that simulate all potential exposure scenarios to train the enhancement network. Our extensive experiments show that the proposed approach consistently outperforms the current state-of-the-art unsupervised counterparts in several public datasets in terms of both quantitative metrics and qualitative results. Our code is available at https://github.com/VinAIResearch/PSENet-Image-Enhancement.