 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepABM: Scalable, efficient and differentiable agent-based simulations via graph neural networks
Oct 09, 2021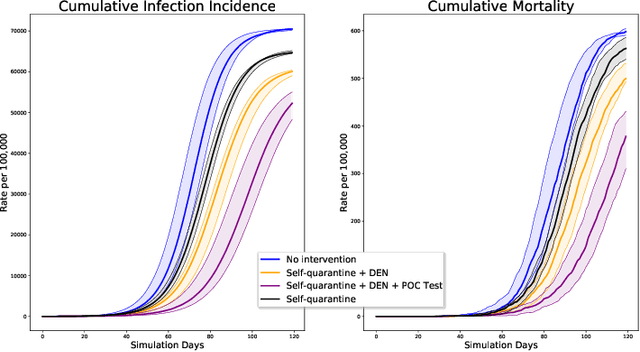

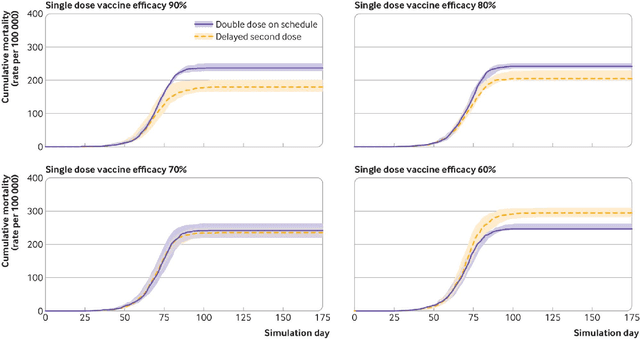
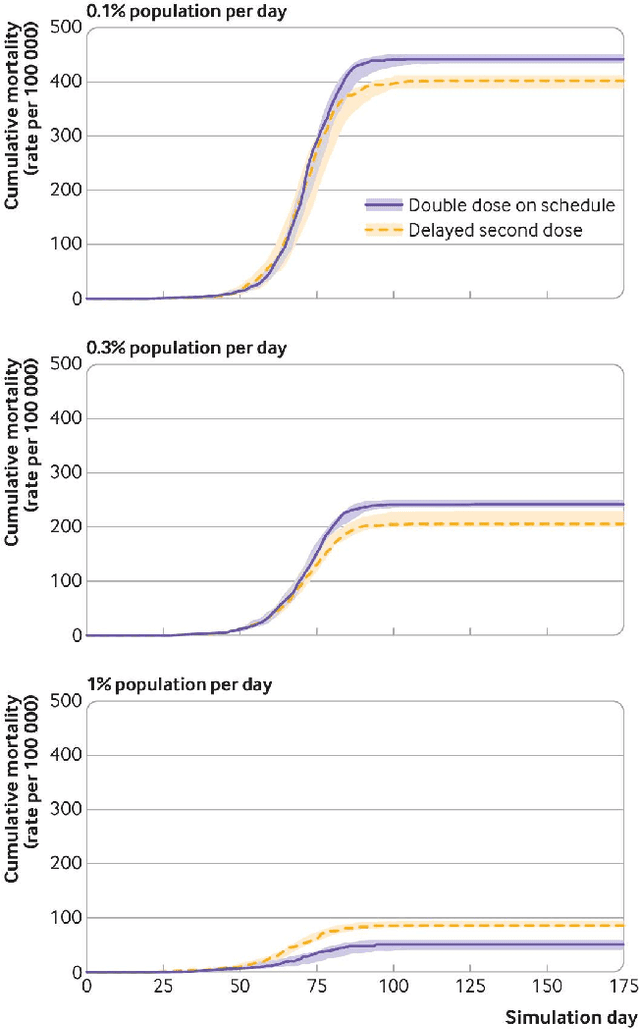
We introduce DeepABM, a framework for agent-based modeling that leverages geometric message passing of graph neural networks for simulating action and interactions over large agent populations. Using DeepABM allows scaling simulations to large agent populations in real-time and running them efficiently on GPU architectures. To demonstrate the effectiveness of DeepABM, we build DeepABM-COVID simulator to provide support for various non-pharmaceutical interventions (quarantine, exposure notification, vaccination, testing) for the COVID-19 pandemic, and can scale to populations of representative size in real-time on a GPU. Specifically, DeepABM-COVID can model 200 million interactions (over 100,000 agents across 180 time-steps) in 90 seconds, and is made available online to help researchers with modeling and analysis of various interventions. We explain various components of the framework and discuss results from one research study to evaluate the impact of delaying the second dose of the COVID-19 vaccine in collaboration with clinical and public health experts. While we simulate COVID-19 spread, the ideas introduced in the paper are generic and can be easily extend to other forms of agent-based simulations. Furthermore, while beyond scope of this document, DeepABM enables inverse agent-based simulations which can be used to learn physical parameters in the (micro) simulations using gradient-based optimization with large-scale real-world (macro) data. We are optimistic that the current work can have interesting implications for bringing ABM and AI communities closer.
ZFlow: Gated Appearance Flow-based Virtual Try-on with 3D Priors
Sep 14, 2021
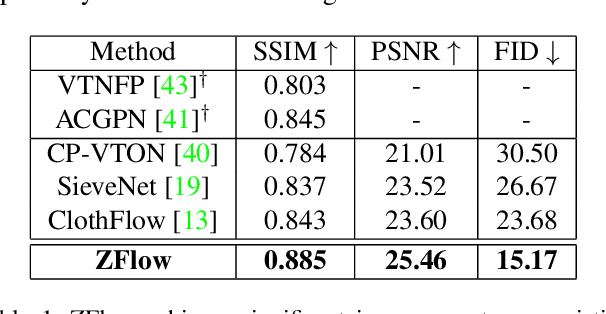
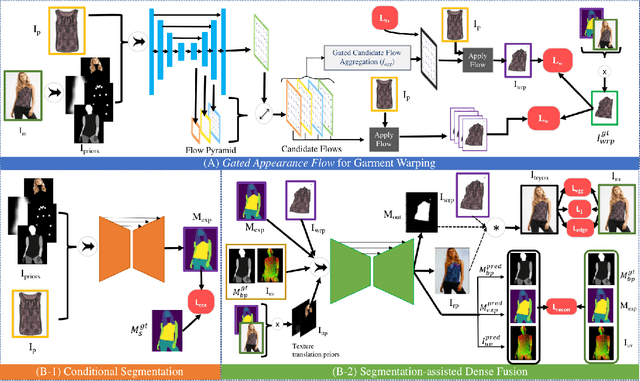
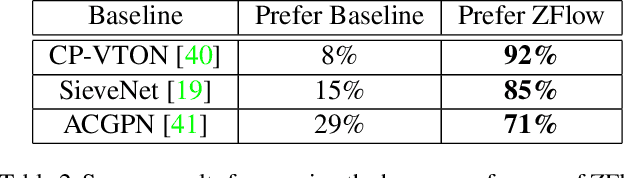
Image-based virtual try-on involves synthesizing perceptually convincing images of a model wearing a particular garment and has garnered significant research interest due to its immense practical applicability. Recent methods involve a two stage process: i) warping of the garment to align with the model ii) texture fusion of the warped garment and target model to generate the try-on output. Issues arise due to the non-rigid nature of garments and the lack of geometric information about the model or the garment. It often results in improper rendering of granular details. We propose ZFlow, an end-to-end framework, which seeks to alleviate these concerns regarding geometric and textural integrity (such as pose, depth-ordering, skin and neckline reproduction) through a combination of gated aggregation of hierarchical flow estimates termed Gated Appearance Flow, and dense structural priors at various stage of the network. ZFlow achieves state-of-the-art results as observed qualitatively, and on quantitative benchmarks of image quality (PSNR, SSIM, and FID). The paper presents extensive comparisons with other existing solutions including a detailed user study and ablation studies to gauge the effect of each of our contributions on multiple datasets.
COVID-19 Outbreak Prediction and Analysis using Self Reported Symptoms
Dec 21, 2020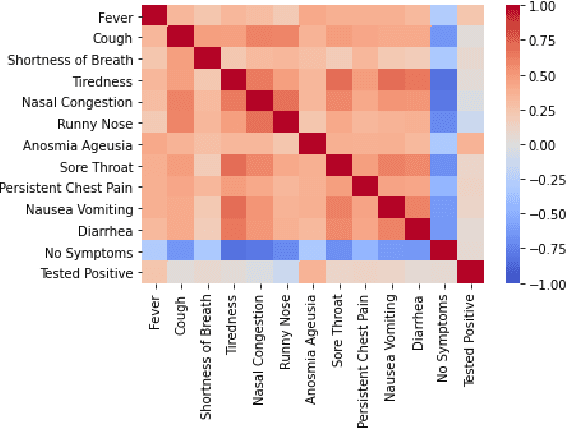
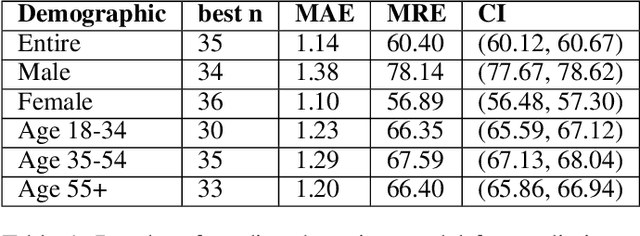
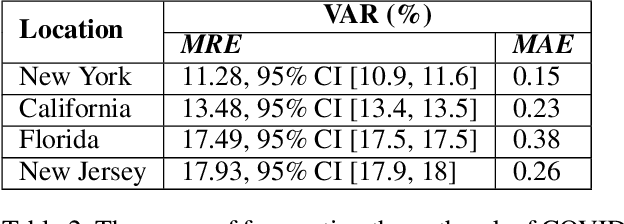
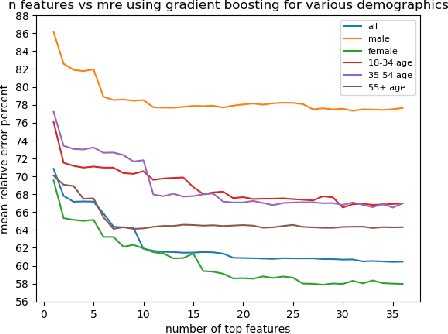
The COVID-19 pandemic has challenged scientists and policy-makers internationally to develop novel approaches to public health policy. Furthermore, it has also been observed that the prevalence and spread of COVID-19 vary across different spatial, temporal, and demographics. Despite ramping up testing, we still are not at the required level in most parts of the globe. Therefore, we utilize self-reported symptoms survey data to understand trends in the spread of COVID-19. The aim of this study is to segment populations that are highly susceptible. In order to understand such populations, we perform exploratory data analysis, outbreak prediction, and time-series forecasting using public health and policy datasets. From our studies, we try to predict the likely % of the population that tested positive for COVID-19 based on self-reported symptoms. Our findings reaffirm the predictive value of symptoms, such as anosmia and ageusia. And we forecast that % of the population having COVID-19-like illness (CLI) and those tested positive as 0.15% and 1.14% absolute error respectively. These findings could help aid faster development of the public health policy, particularly in areas with low levels of testing and having a greater reliance on self-reported symptoms. Our analysis sheds light on identifying clinical attributes of interest across different demographics. We also provide insights into the effects of various policy enactments on COVID-19 prevalence.
DISCO: Dynamic and Invariant Sensitive Channel Obfuscation for deep neural networks
Dec 20, 2020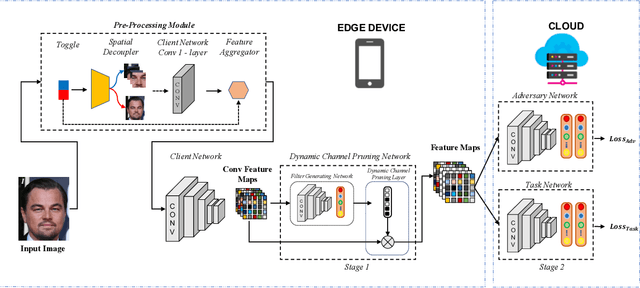
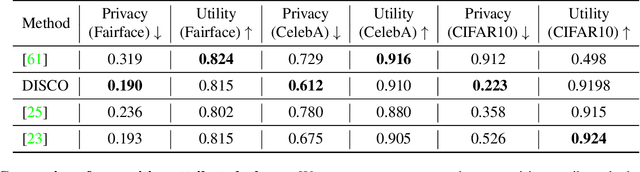

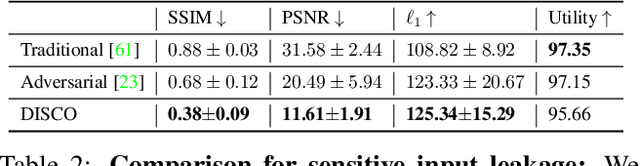
Recent deep learning models have shown remarkable performance in image classification. While these deep learning systems are getting closer to practical deployment, the common assumption made about data is that it does not carry any sensitive information. This assumption may not hold for many practical cases, especially in the domain where an individual's personal information is involved, like healthcare and facial recognition systems. We posit that selectively removing features in this latent space can protect the sensitive information and provide a better privacy-utility trade-off. Consequently, we propose DISCO which learns a dynamic and data driven pruning filter to selectively obfuscate sensitive information in the feature space. We propose diverse attack schemes for sensitive inputs \& attributes and demonstrate the effectiveness of DISCO against state-of-the-art methods through quantitative and qualitative evaluation. Finally, we also release an evaluation benchmark dataset of 1 million sensitive representations to encourage rigorous exploration of novel attack schemes.
Proximity Sensing for Contact Tracing
Sep 04, 2020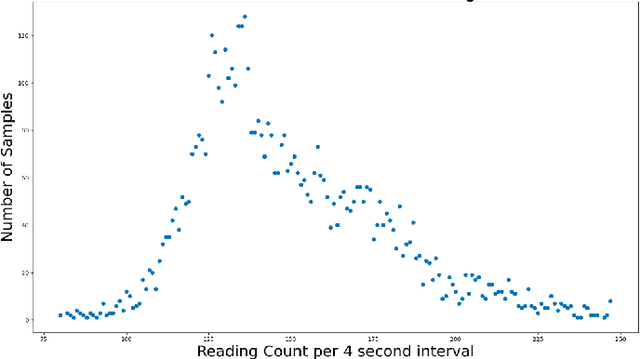
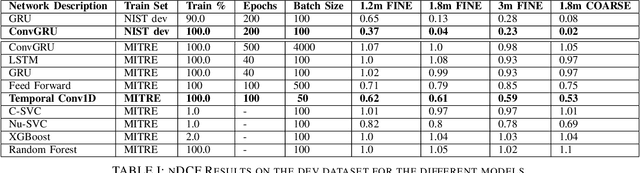
The TC4TL (Too Close For Too Long) challenge is aimed towards designing an effective proximity sensing algorithm that can accurately provide exposure notifications. In this paper, we describe our approach to model sensor and other device-level data to estimate the distance between two phones. We also present our research and data analysis on the TC4TL challenge and discuss various limitations associated with the task, and the dataset used for this purpose.
MixBoost: Synthetic Oversampling with Boosted Mixup for Handling Extreme Imbalance
Sep 03, 2020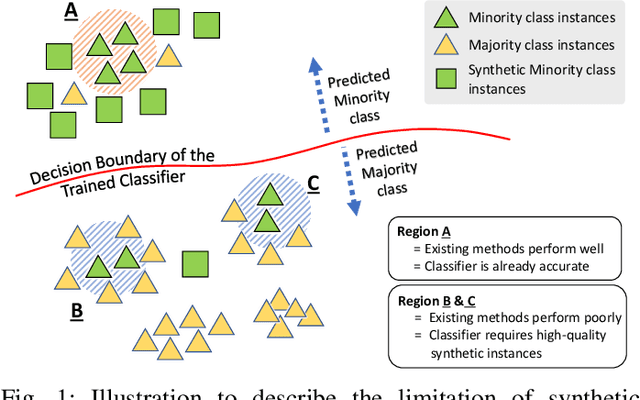
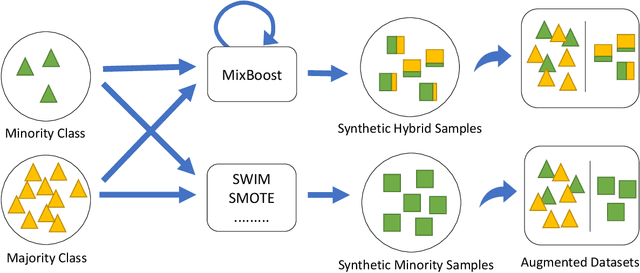
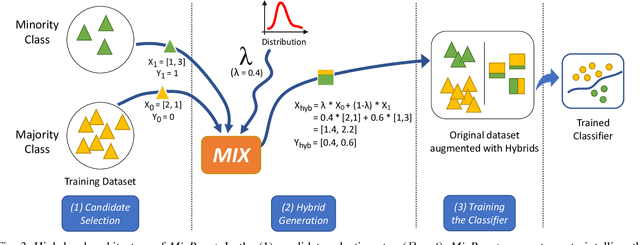
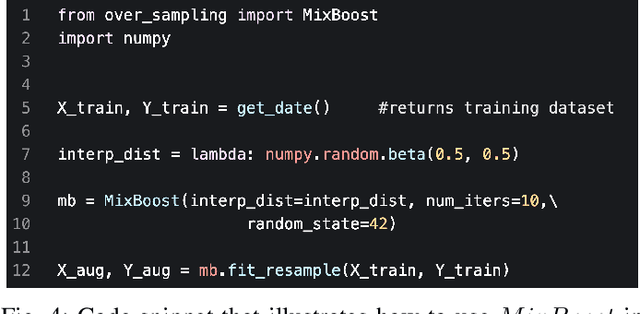
Training a classification model on a dataset where the instances of one class outnumber those of the other class is a challenging problem. Such imbalanced datasets are standard in real-world situations such as fraud detection, medical diagnosis, and computational advertising. We propose an iterative data augmentation method, MixBoost, which intelligently selects (Boost) and then combines (Mix) instances from the majority and minority classes to generate synthetic hybrid instances that have characteristics of both classes. We evaluate MixBoost on 20 benchmark datasets, show that it outperforms existing approaches, and test its efficacy through significance testing. We also present ablation studies to analyze the impact of the different components of MixBoost.
TRACE: Transform Aggregate and Compose Visiolinguistic Representations for Image Search with Text Feedback
Sep 03, 2020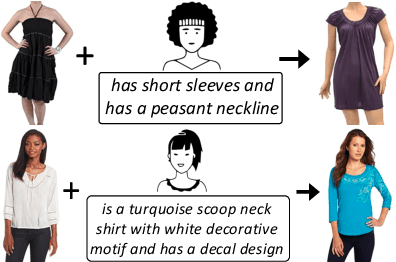
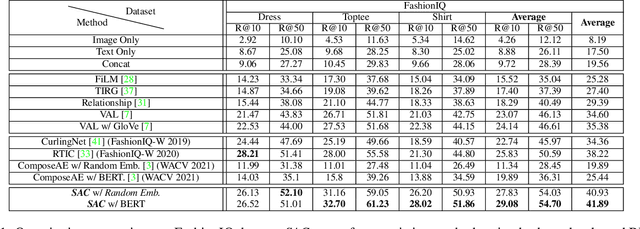
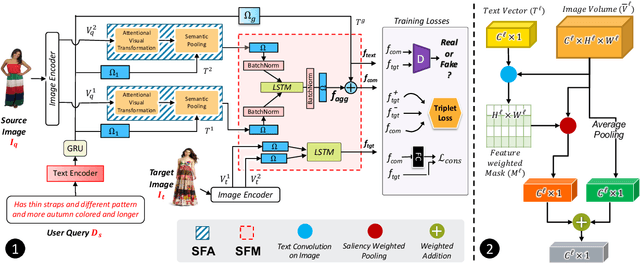
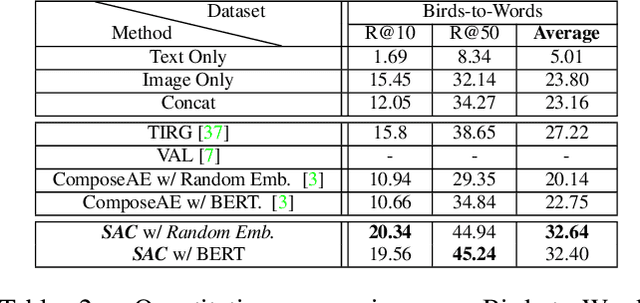
The ability to efficiently search for images over an indexed database is the cornerstone for several user experiences. Incorporating user feedback, through multi-modal inputs provide flexible and interaction to serve fine-grained specificity in requirements. We specifically focus on text feedback, through descriptive natural language queries. Given a reference image and textual user feedback, our goal is to retrieve images that satisfy constraints specified by both of these input modalities. The task is challenging as it requires understanding the textual semantics from the text feedback and then applying these changes to the visual representation. To address these challenges, we propose a novel architecture TRACE which contains a hierarchical feature aggregation module to learn the composite visio-linguistic representations. TRACE achieves the SOTA performance on 3 benchmark datasets: FashionIQ, Shoes, and Birds-to-Words, with an average improvement of at least ~5.7%, ~3%, and ~5% respectively in R@K metric. Our extensive experiments and ablation studies show that TRACE consistently outperforms the existing techniques by significant margins both quantitatively and qualitatively.
Retrospective Loss: Looking Back to Improve Training of Deep Neural Networks
Jun 24, 2020
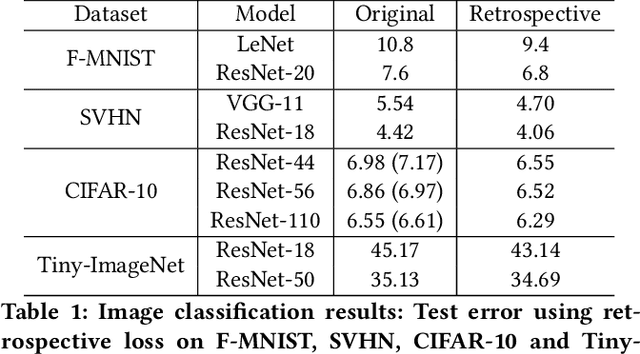
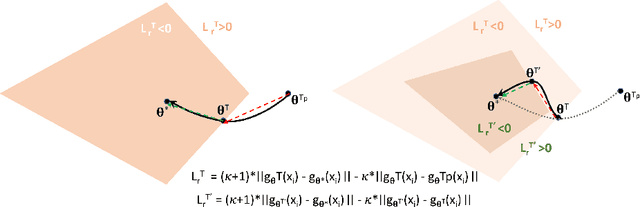
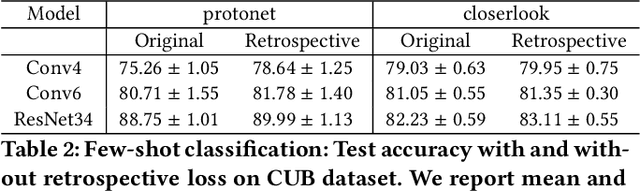
Deep neural networks (DNNs) are powerful learning machines that have enabled breakthroughs in several domains. In this work, we introduce a new retrospective loss to improve the training of deep neural network models by utilizing the prior experience available in past model states during training. Minimizing the retrospective loss, along with the task-specific loss, pushes the parameter state at the current training step towards the optimal parameter state while pulling it away from the parameter state at a previous training step. Although a simple idea, we analyze the method as well as to conduct comprehensive sets of experiments across domains - images, speech, text, and graphs - to show that the proposed loss results in improved performance across input domains, tasks, and architectures.
SimPropNet: Improved Similarity Propagation for Few-shot Image Segmentation
May 02, 2020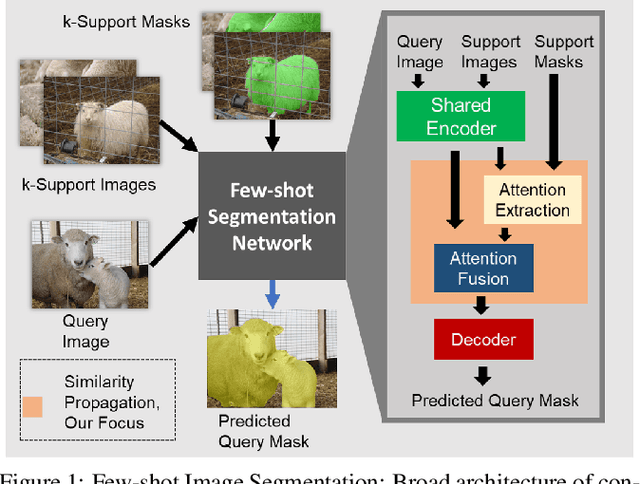

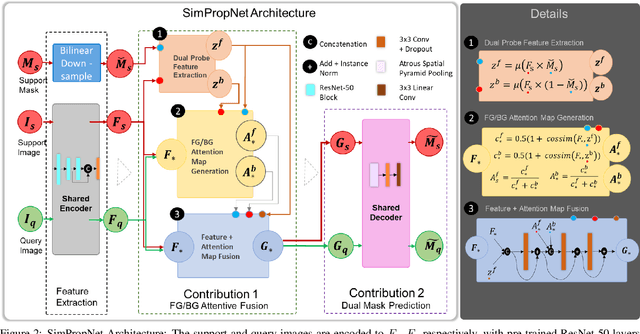
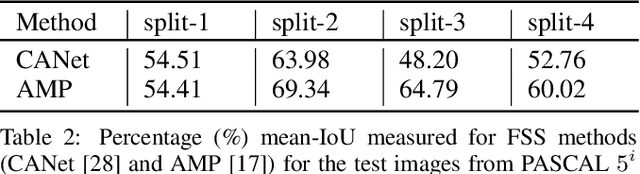
Few-shot segmentation (FSS) methods perform image segmentation for a particular object class in a target (query) image, using a small set of (support) image-mask pairs. Recent deep neural network based FSS methods leverage high-dimensional feature similarity between the foreground features of the support images and the query image features. In this work, we demonstrate gaps in the utilization of this similarity information in existing methods, and present a framework - SimPropNet, to bridge those gaps. We propose to jointly predict the support and query masks to force the support features to share characteristics with the query features. We also propose to utilize similarities in the background regions of the query and support images using a novel foreground-background attentive fusion mechanism. Our method achieves state-of-the-art results for one-shot and five-shot segmentation on the PASCAL-5i dataset. The paper includes detailed analysis and ablation studies for the proposed improvements and quantitative comparisons with contemporary methods.
SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On
Jan 17, 2020
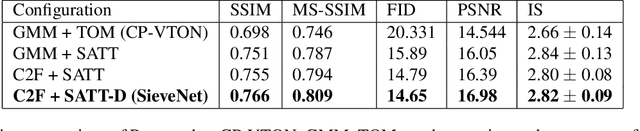
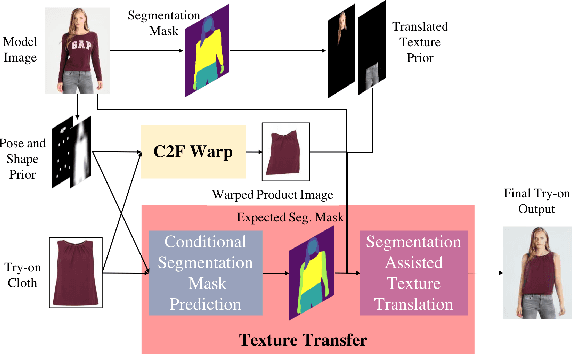
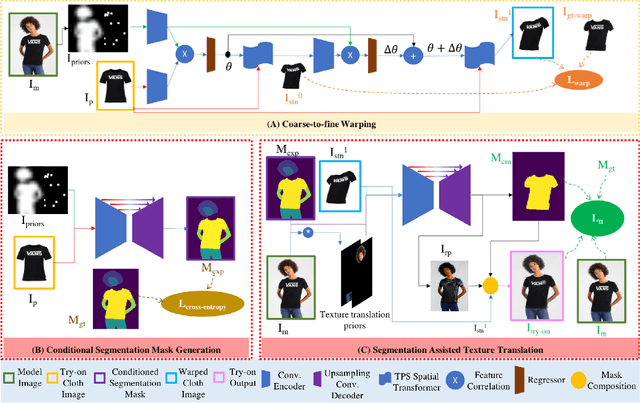
Image-based virtual try-on for fashion has gained considerable attention recently. The task requires trying on a clothing item on a target model image. An efficient framework for this is composed of two stages: (1) warping (transforming) the try-on cloth to align with the pose and shape of the target model, and (2) a texture transfer module to seamlessly integrate the warped try-on cloth onto the target model image. Existing methods suffer from artifacts and distortions in their try-on output. In this work, we present SieveNet, a framework for robust image-based virtual try-on. Firstly, we introduce a multi-stage coarse-to-fine warping network to better model fine-grained intricacies (while transforming the try-on cloth) and train it with a novel perceptual geometric matching loss. Next, we introduce a try-on cloth conditioned segmentation mask prior to improve the texture transfer network. Finally, we also introduce a dueling triplet loss strategy for training the texture translation network which further improves the quality of the generated try-on results. We present extensive qualitative and quantitative evaluations of each component of the proposed pipeline and show significant performance improvements against the current state-of-the-art method.