 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTB-morph: One-Time Biometrics via Morphing
Feb 17, 2023Cancelable biometrics are a group of techniques to transform the input biometric to an irreversible feature intentionally using a transformation function and usually a key in order to provide security and privacy in biometric recognition systems. This transformation is repeatable enabling subsequent biometric comparisons. This paper is introducing a new idea to exploit as a transformation function for cancelable biometrics aimed at protecting the templates against iterative optimization attacks. Our proposed scheme is based on time-varying keys (random biometrics in our case) and morphing transformations. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.
Human-Centric Multimodal Machine Learning: Recent Advances and Testbed on AI-based Recruitment
Feb 13, 2023The presence of decision-making algorithms in society is rapidly increasing nowadays, while concerns about their transparency and the possibility of these algorithms becoming new sources of discrimination are arising. There is a certain consensus about the need to develop AI applications with a Human-Centric approach. Human-Centric Machine Learning needs to be developed based on four main requirements: (i) utility and social good; (ii) privacy and data ownership; (iii) transparency and accountability; and (iv) fairness in AI-driven decision-making processes. All these four Human-Centric requirements are closely related to each other. With the aim of studying how current multimodal algorithms based on heterogeneous sources of information are affected by sensitive elements and inner biases in the data, we propose a fictitious case study focused on automated recruitment: FairCVtest. We train automatic recruitment algorithms using a set of multimodal synthetic profiles including image, text, and structured data, which are consciously scored with gender and racial biases. FairCVtest shows the capacity of the Artificial Intelligence (AI) behind automatic recruitment tools built this way (a common practice in many other application scenarios beyond recruitment) to extract sensitive information from unstructured data and exploit it in combination to data biases in undesirable (unfair) ways. We present an overview of recent works developing techniques capable of removing sensitive information and biases from the decision-making process of deep learning architectures, as well as commonly used databases for fairness research in AI. We demonstrate how learning approaches developed to guarantee privacy in latent spaces can lead to unbiased and fair automatic decision-making process.
Toward Face Biometric De-identification using Adversarial Examples
Feb 07, 2023The remarkable success of face recognition (FR) has endangered the privacy of internet users particularly in social media. Recently, researchers turned to use adversarial examples as a countermeasure. In this paper, we assess the effectiveness of using two widely known adversarial methods (BIM and ILLC) for de-identifying personal images. We discovered, unlike previous claims in the literature, that it is not easy to get a high protection success rate (suppressing identification rate) with imperceptible adversarial perturbation to the human visual system. Finally, we found out that the transferability of adversarial examples is highly affected by the training parameters of the network with which they are generated.
MATT: Multimodal Attention Level Estimation for e-learning Platforms
Jan 22, 2023



This work presents a new multimodal system for remote attention level estimation based on multimodal face analysis. Our multimodal approach uses different parameters and signals obtained from the behavior and physiological processes that have been related to modeling cognitive load such as faces gestures (e.g., blink rate, facial actions units) and user actions (e.g., head pose, distance to the camera). The multimodal system uses the following modules based on Convolutional Neural Networks (CNNs): Eye blink detection, head pose estimation, facial landmark detection, and facial expression features. First, we individually evaluate the proposed modules in the task of estimating the student's attention level captured during online e-learning sessions. For that we trained binary classifiers (high or low attention) based on Support Vector Machines (SVM) for each module. Secondly, we find out to what extent multimodal score level fusion improves the attention level estimation. The mEBAL database is used in the experimental framework, a public multi-modal database for attention level estimation obtained in an e-learning environment that contains data from 38 users while conducting several e-learning tasks of variable difficulty (creating changes in student cognitive loads).
TypeFormer: Transformers for Mobile Keystroke Biometrics
Dec 26, 2022



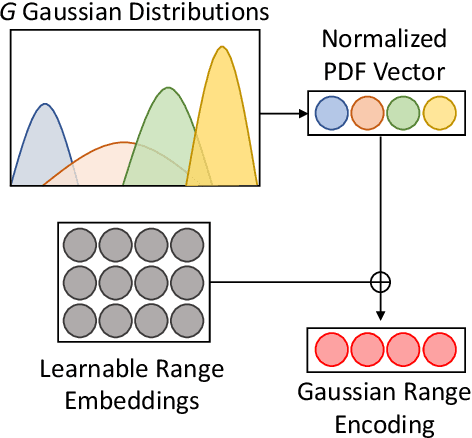
The broad usage of mobile devices nowadays, the sensitiveness of the information contained in them, and the shortcomings of current mobile user authentication methods are calling for novel, secure, and unobtrusive solutions to verify the users' identity. In this article, we propose TypeFormer, a novel Transformer architecture to model free-text keystroke dynamics performed on mobile devices for the purpose of user authentication. The proposed model consists in Temporal and Channel Modules enclosing two Long Short-Term Memory (LSTM) recurrent layers, Gaussian Range Encoding (GRE), a multi-head Self-Attention mechanism, and a Block-Recurrent structure. Experimenting on one of the largest public databases to date, the Aalto mobile keystroke database, TypeFormer outperforms current state-of-the-art systems achieving Equal Error Rate (EER) values of 3.25% using only 5 enrolment sessions of 50 keystrokes each. In such way, we contribute to reducing the traditional performance gap of the challenging mobile free-text scenario with respect to its desktop and fixed-text counterparts. Additionally, we analyse the behaviour of the model with different experimental configurations such as the length of the keystroke sequences and the amount of enrolment sessions, showing margin for improvement with more enrolment data. Finally, a cross-database evaluation is carried out, demonstrating the robustness of the features extracted by TypeFormer in comparison with existing approaches.
edBB-Demo: Biometrics and Behavior Analysis for Online Educational Platforms
Dec 05, 2022

We present edBB-Demo, a demonstrator of an AI-powered research platform for student monitoring in remote education. The edBB platform aims to study the challenges associated to user recognition and behavior understanding in digital platforms. This platform has been developed for data collection, acquiring signals from a variety of sensors including keyboard, mouse, webcam, microphone, smartwatch, and an Electroencephalography band. The information captured from the sensors during the student sessions is modelled in a multimodal learning framework. The demonstrator includes: i) Biometric user authentication in an unsupervised environment; ii) Human action recognition based on remote video analysis; iii) Heart rate estimation from webcam video; and iv) Attention level estimation from facial expression analysis.
AI4Food-NutritionDB: Food Image Database, Nutrition Taxonomy, and Recognition Benchmark
Nov 14, 2022Leading a healthy lifestyle has become one of the most challenging goals in today's society due to our sedentary lifestyle and poor eating habits. As a result, national and international organisms have made numerous efforts to promote healthier food diets and physical activity habits. However, these recommendations are sometimes difficult to follow in our daily life and they are also based on a general population. As a consequence, a new area of research, personalised nutrition, has been conceived focusing on individual solutions through smart devices and Artificial Intelligence (AI) methods. This study presents the AI4Food-NutritionDB database, the first nutrition database that considers food images and a nutrition taxonomy based on recommendations by national and international organisms. In addition, four different categorisation levels are considered following nutrition experts: 6 nutritional levels, 19 main categories (e.g., "Meat"), 73 subcategories (e.g., "White Meat"), and 893 final food products (e.g., "Chicken"). The AI4Food-NutritionDB opens the doors to new food computing approaches in terms of food intake frequency, quality, and categorisation. Also, in addition to the database, we propose a standard experimental protocol and benchmark including three tasks based on the nutrition taxonomy (i.e., category, subcategory, and final product) to be used for the research community. Finally, we also release our Deep Learning models trained with the AI4Food-NutritionDB, which can be used as pre-trained models, achieving accurate recognition results with challenging food image databases.
IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C)
Oct 06, 2022
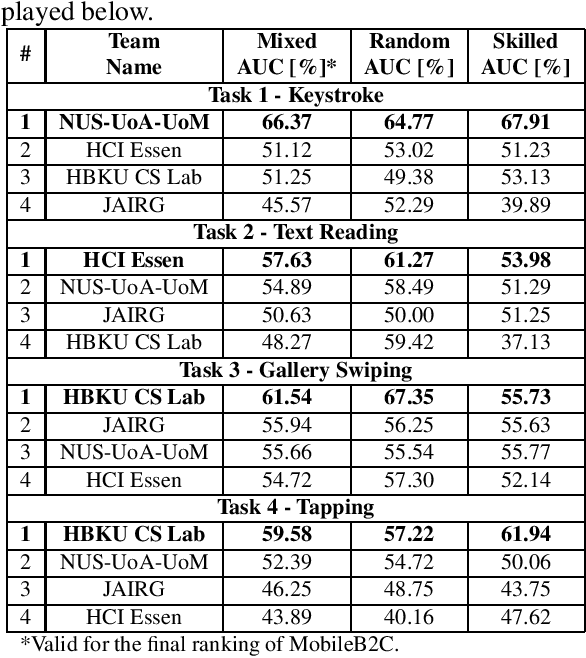
This paper describes the experimental framework and results of the IJCB 2022 Mobile Behavioral Biometrics Competition (MobileB2C). The aim of MobileB2C is benchmarking mobile user authentication systems based on behavioral biometric traits transparently acquired by mobile devices during ordinary Human-Computer Interaction (HCI), using a novel public database, BehavePassDB, and a standard experimental protocol. The competition is divided into four tasks corresponding to typical user activities: keystroke, text reading, gallery swiping, and tapping. The data are composed of touchscreen data and several background sensor data simultaneously acquired. "Random" (different users with different devices) and "skilled" (different user on the same device attempting to imitate the legitimate one) impostor scenarios are considered. The results achieved by the participants show the feasibility of user authentication through behavioral biometrics, although this proves to be a non-trivial challenge. MobileB2C will be established as an on-going competition.
Statistical Keystroke Synthesis for Improved Bot Detection
Jul 28, 2022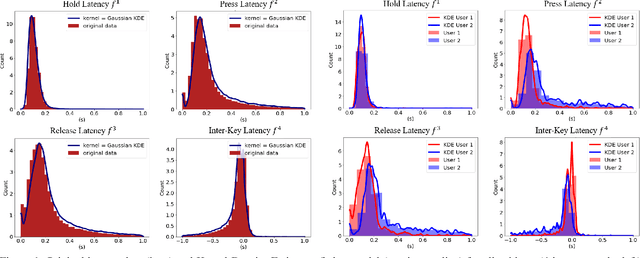
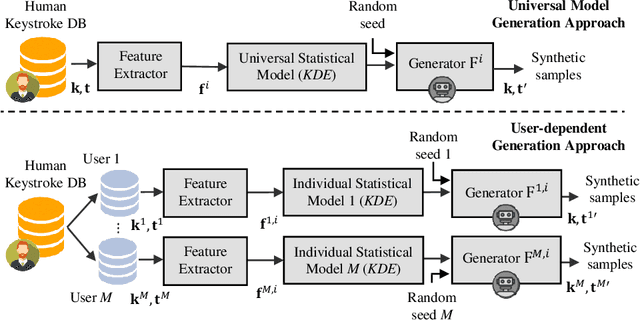
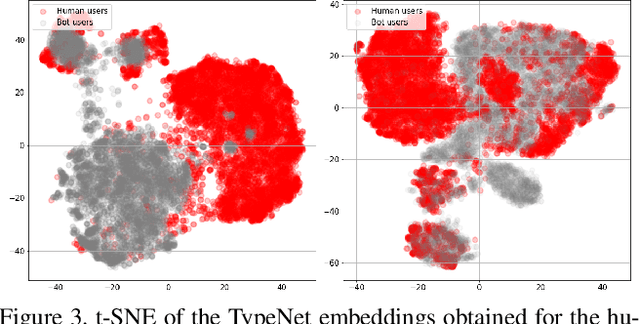
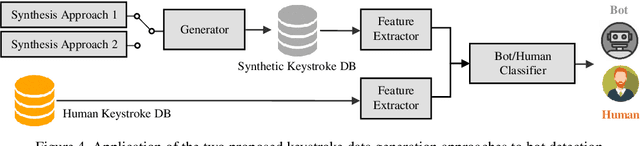
This work proposes two statistical approaches for the synthesis of keystroke biometric data based on Universal and User-dependent Models. Both approaches are validated on the bot detection task, using the keystroke synthetic data to better train the systems. Our experiments include a dataset with 136 million keystroke events from 168,000 subjects. We have analyzed the performance of the two synthesis approaches through qualitative and quantitative experiments. Different bot detectors are considered based on two supervised classifiers (Support Vector Machine and Long Short-Term Memory network) and a learning framework including human and generated samples. Our results prove that the proposed statistical approaches are able to generate realistic human-like synthetic keystroke samples. Also, the classification results suggest that in scenarios with large labeled data, these synthetic samples can be detected with high accuracy. However, in few-shot learning scenarios it represents an important challenge.
Mobile Keystroke Biometrics Using Transformers
Jul 15, 2022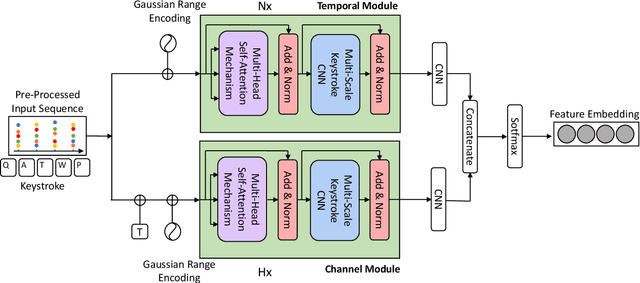
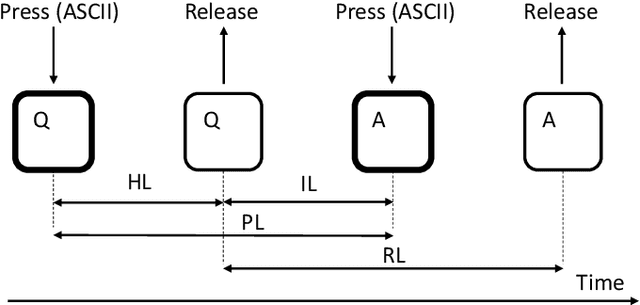
Behavioural biometrics have proven to be effective against identity theft as well as be considered user-friendly authentication methods. One of the most popular traits in the literature is keystroke dynamics due to the large deployment of computers and mobile devices in our society. This paper focuses on improving keystroke biometric systems on the free-text scenario. This scenario is characterised as very challenging due to the uncontrolled text conditions, the influential of the user's emotional and physical state, and the in-use application. To overcome these drawbacks, methods based on deep learning such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) have been proposed in the literature, outperforming traditional machine learning methods. However, these architectures still have aspects that need to be reviewed and improved. To the best of our knowledge, this is the first study that proposes keystroke biometric systems based on Transformers. The proposed Transformer architecture has achieved Equal Error Rate (EER) values of 3.84% in the popular Aalto mobile keystroke database using only 5 enrolment sessions, outperforming in large margin other state-of-the-art approaches in the literature.