 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Confident Machine Reading Comprehension
Jan 20, 2021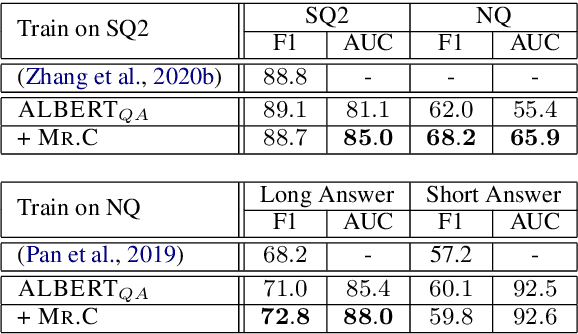
There has been considerable progress on academic benchmarks for the Reading Comprehension (RC) task with State-of-the-Art models closing the gap with human performance on extractive question answering. Datasets such as SQuAD 2.0 & NQ have also introduced an auxiliary task requiring models to predict when a question has no answer in the text. However, in production settings, it is also necessary to provide confidence estimates for the performance of the underlying RC model at both answer extraction and "answerability" detection. We propose a novel post-prediction confidence estimation model, which we call Mr.C (short for Mr. Confident), that can be trained to improve a system's ability to refrain from making incorrect predictions with improvements of up to 4 points as measured by Area Under the Curve (AUC) scores. Mr.C can benefit from a novel white-box feature that leverages the underlying RC model's gradients. Performance prediction is particularly important in cases of domain shift (as measured by training RC models on SQUAD 2.0 and evaluating on NQ), where Mr.C not only improves AUC, but also traditional answerability prediction (as measured by a 5 point improvement in F1).
Multilingual Transfer Learning for QA Using Translation as Data Augmentation
Dec 10, 2020

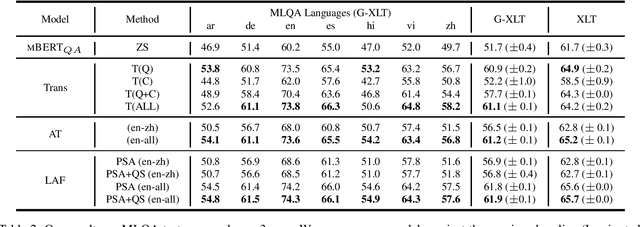
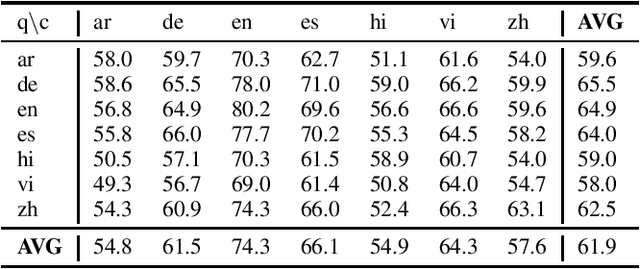
Prior work on multilingual question answering has mostly focused on using large multilingual pre-trained language models (LM) to perform zero-shot language-wise learning: train a QA model on English and test on other languages. In this work, we explore strategies that improve cross-lingual transfer by bringing the multilingual embeddings closer in the semantic space. Our first strategy augments the original English training data with machine translation-generated data. This results in a corpus of multilingual silver-labeled QA pairs that is 14 times larger than the original training set. In addition, we propose two novel strategies, language adversarial training and language arbitration framework, which significantly improve the (zero-resource) cross-lingual transfer performance and result in LM embeddings that are less language-variant. Empirically, we show that the proposed models outperform the previous zero-shot baseline on the recently introduced multilingual MLQA and TyDiQA datasets.
Answer Span Correction in Machine Reading Comprehension
Nov 06, 2020

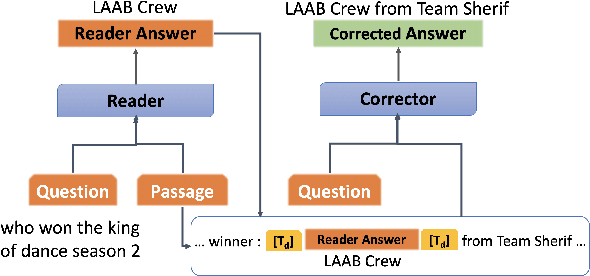

Answer validation in machine reading comprehension (MRC) consists of verifying an extracted answer against an input context and question pair. Previous work has looked at re-assessing the "answerability" of the question given the extracted answer. Here we address a different problem: the tendency of existing MRC systems to produce partially correct answers when presented with answerable questions. We explore the nature of such errors and propose a post-processing correction method that yields statistically significant performance improvements over state-of-the-art MRC systems in both monolingual and multilingual evaluation.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
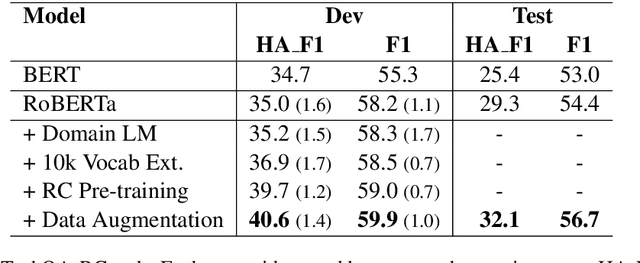
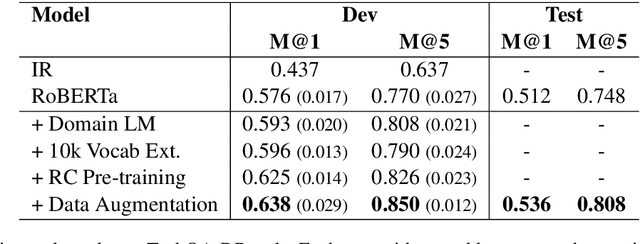
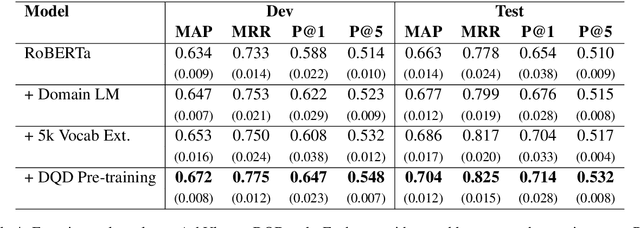
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.
The TechQA Dataset
Nov 08, 2019

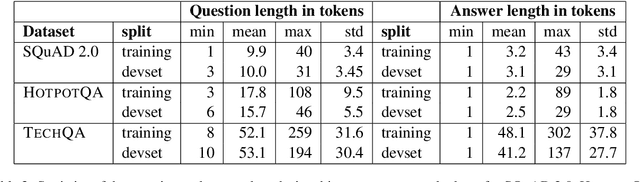
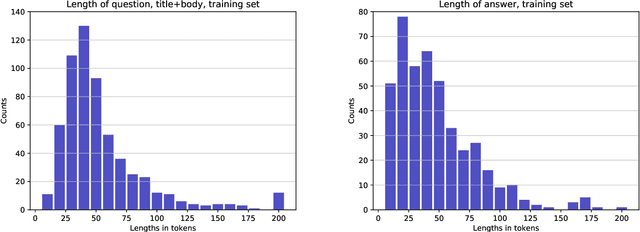
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.
Ensembling Strategies for Answering Natural Questions
Nov 06, 2019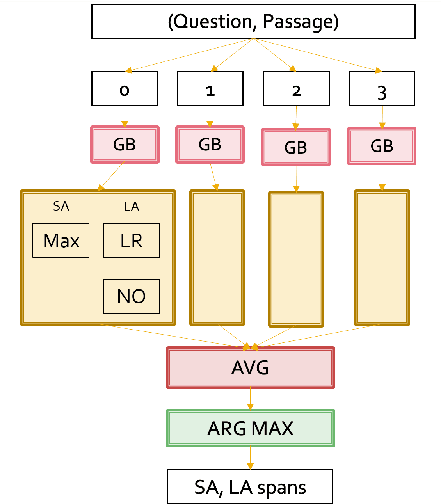

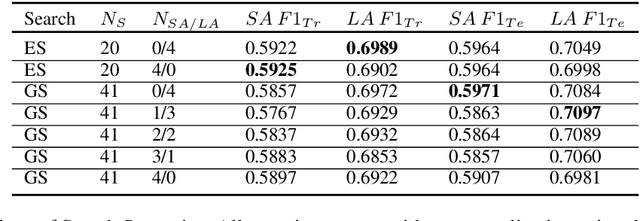
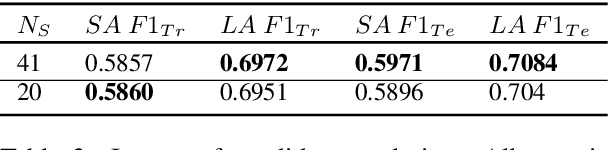
Many of the top question answering systems today utilize ensembling to improve their performance on tasks such as the Stanford Question Answering Dataset (SQuAD) and Natural Questions (NQ) challenges. Unfortunately most of these systems do not publish their ensembling strategies used in their leaderboard submissions. In this work, we investigate a number of ensembling techniques and demonstrate a strategy which improves our F1 score for short answers on the dev set for NQ by 2.3 F1 points over our single model (which outperforms the previous SOTA by 1.9 F1 points).
Frustratingly Easy Natural Question Answering
Sep 11, 2019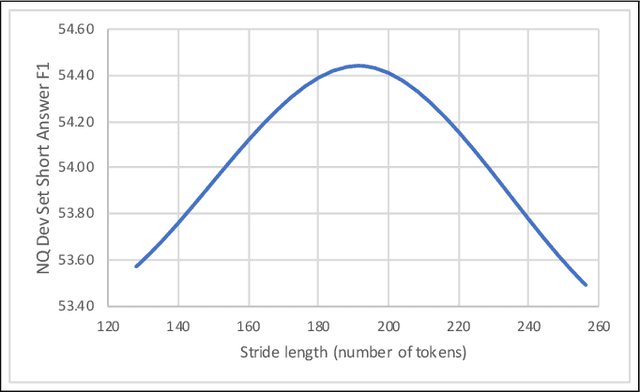
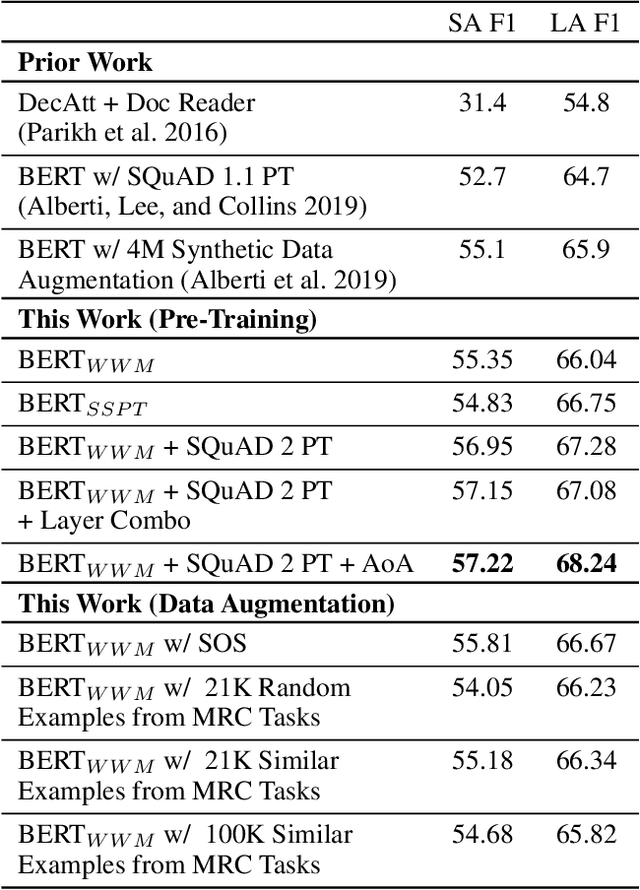
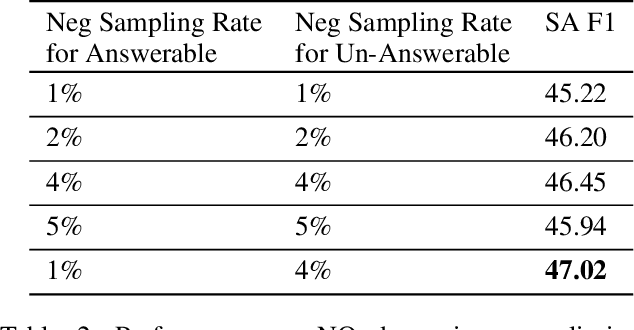
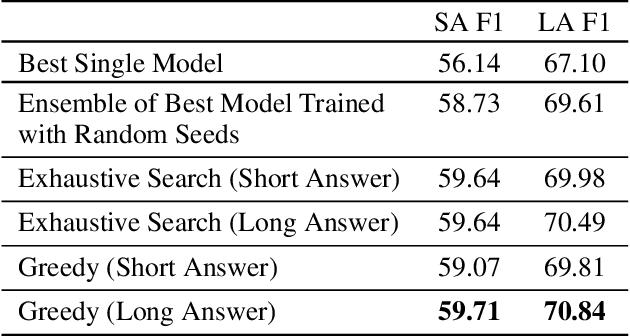
Existing literature on Question Answering (QA) mostly focuses on algorithmic novelty, data augmentation, or increasingly large pre-trained language models like XLNet and RoBERTa. Additionally, a lot of systems on the QA leaderboards do not have associated research documentation in order to successfully replicate their experiments. In this paper, we outline these algorithmic components such as Attention-over-Attention, coupled with data augmentation and ensembling strategies that have shown to yield state-of-the-art results on benchmark datasets like SQuAD, even achieving super-human performance. Contrary to these prior results, when we evaluate on the recently proposed Natural Questions benchmark dataset, we find that an incredibly simple approach of transfer learning from BERT outperforms the previous state-of-the-art system trained on 4 million more examples than ours by 1.9 F1 points. Adding ensembling strategies further improves that number by 2.3 F1 points.
Span Selection Pre-training for Question Answering
Sep 09, 2019
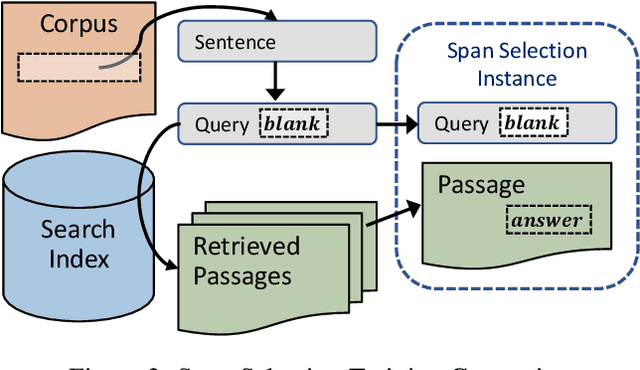

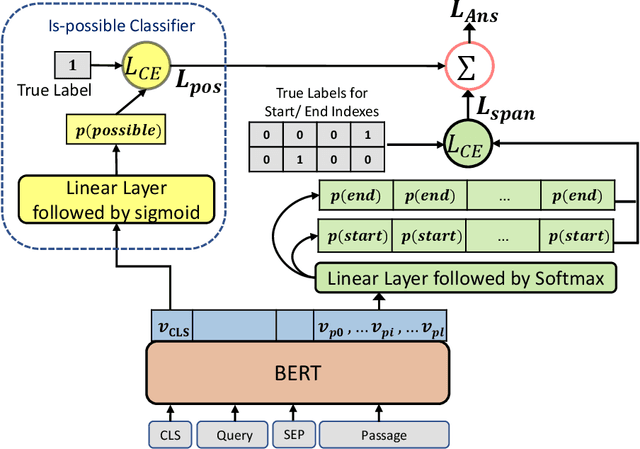
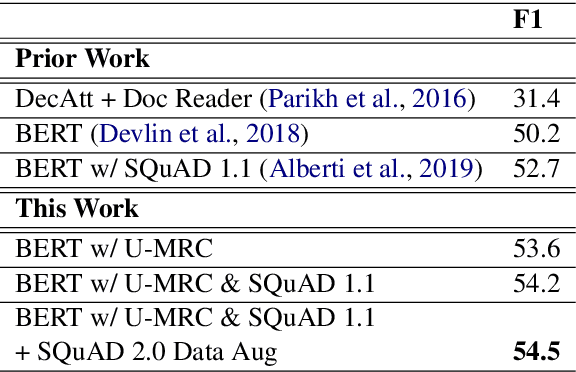
BERT (Bidirectional Encoder Representations from Transformers) and related pre-trained Transformers have provided large gains across many language understanding tasks, achieving a new state-of-the-art (SOTA). BERT is pre-trained on two auxiliary tasks: Masked Language Model and Next Sentence Prediction. In this paper we introduce a new pre-training task inspired by reading comprehension and an effort to avoid encoding general knowledge in the transformer network itself. We find significant and consistent improvements over both BERT-BASE and BERT-LARGE on multiple reading comprehension (MRC) and paraphrasing datasets. Specifically, our proposed model has strong empirical evidence as it obtains SOTA results on Natural Questions, a new benchmark MRC dataset, outperforming BERT-LARGE by 3 F1 points on short answer prediction. We also establish a new SOTA in HotpotQA, improving answer prediction F1 by 4 F1 points and supporting fact prediction by 1 F1 point. Moreover, we show that our pre-training approach is particularly effective when training data is limited, improving the learning curve by a large amount.
CFO: A Framework for Building Production NLP Systems
Aug 30, 2019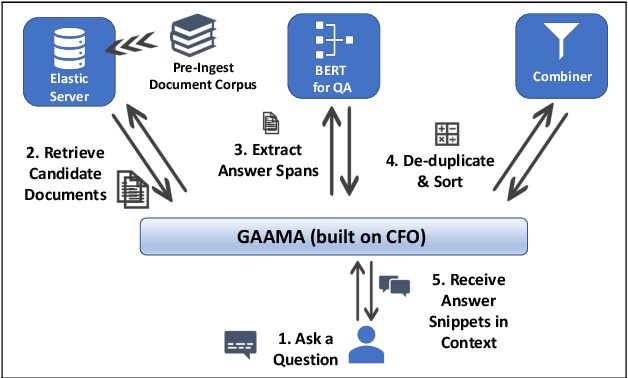
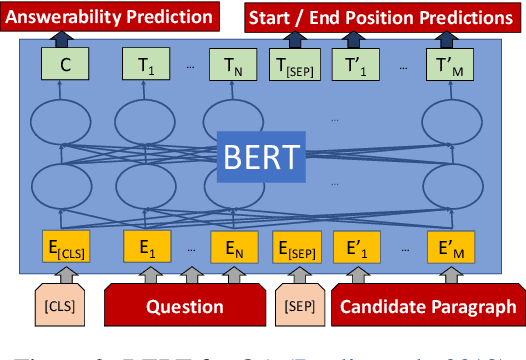

This paper introduces a novel orchestration framework, called CFO (COMPUTATION FLOW ORCHESTRATOR), for building, experimenting with, and deploying interactive NLP (Natural Language Processing) and IR (Information Retrieval) systems to production environments. We then demonstrate a question answering system built using this framework which incorporates state-of-the-art BERT based MRC (Machine Reading Comprehension) with IR components to enable end-to-end answer retrieval. Results from the demo system are shown to be high quality in both academic and industry domain specific settings. Finally, we discuss best practices when (pre-)training BERT based MRC models for production systems.
Neural Cross-Lingual Coreference Resolution and its Application to Entity Linking
Jun 26, 2018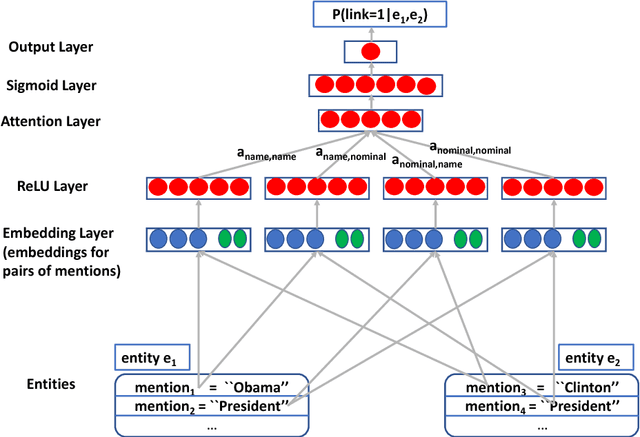
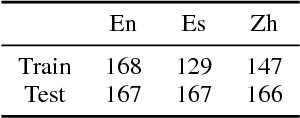
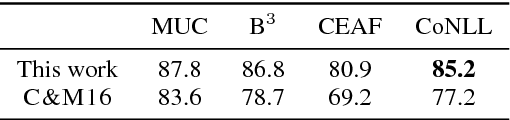
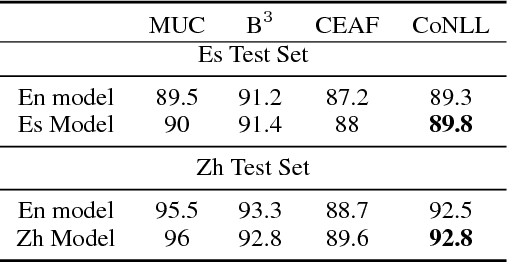
We propose an entity-centric neural cross-lingual coreference model that builds on multi-lingual embeddings and language-independent features. We perform both intrinsic and extrinsic evaluations of our model. In the intrinsic evaluation, we show that our model, when trained on English and tested on Chinese and Spanish, achieves competitive results to the models trained directly on Chinese and Spanish respectively. In the extrinsic evaluation, we show that our English model helps achieve superior entity linking accuracy on Chinese and Spanish test sets than the top 2015 TAC system without using any annotated data from Chinese or Spanish.