 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe TechQA Dataset
Nov 08, 2019

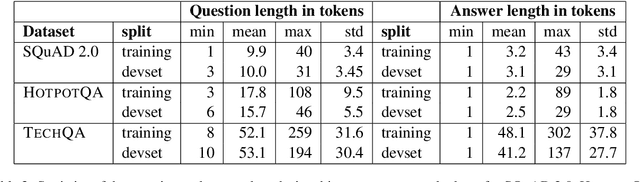
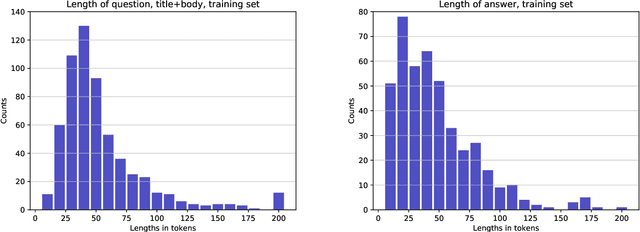
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.
CFO: A Framework for Building Production NLP Systems
Aug 30, 2019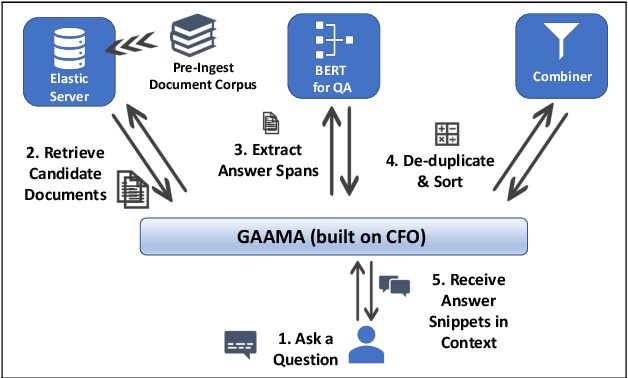
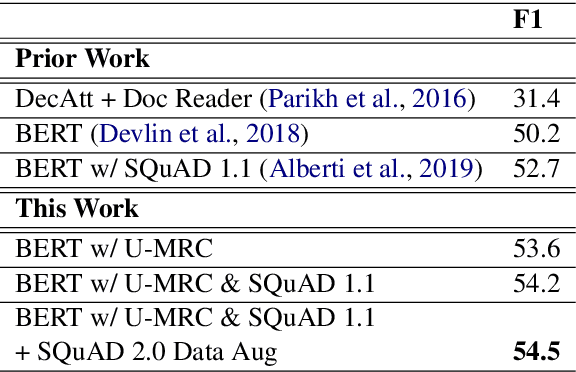
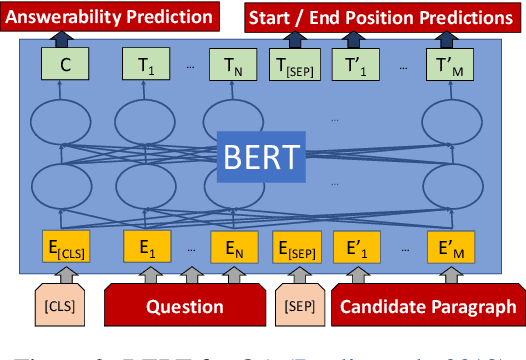

This paper introduces a novel orchestration framework, called CFO (COMPUTATION FLOW ORCHESTRATOR), for building, experimenting with, and deploying interactive NLP (Natural Language Processing) and IR (Information Retrieval) systems to production environments. We then demonstrate a question answering system built using this framework which incorporates state-of-the-art BERT based MRC (Machine Reading Comprehension) with IR components to enable end-to-end answer retrieval. Results from the demo system are shown to be high quality in both academic and industry domain specific settings. Finally, we discuss best practices when (pre-)training BERT based MRC models for production systems.