 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Regularization for Generative Adversarial Networks
Oct 26, 2019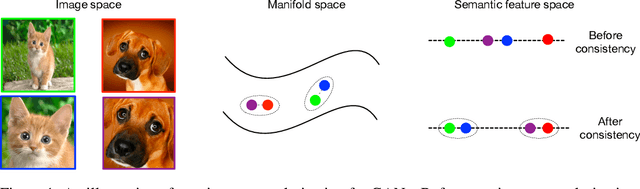

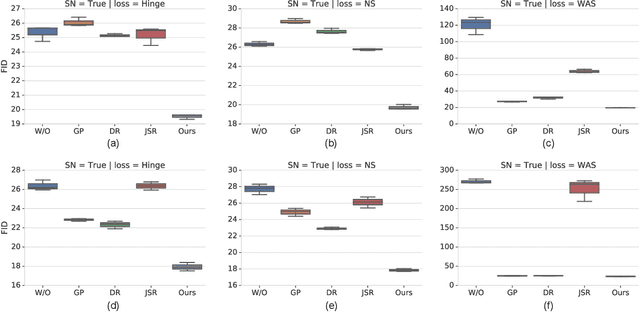

Generative Adversarial Networks (GANs) are known to be difficult to train, despite considerable research effort. Several regularization techniques for stabilizing training have been proposed, but they introduce non-trivial computational overheads and interact poorly with existing techniques like spectral normalization. In this work, we propose a simple, effective training stabilizer based on the notion of consistency regularization---a popular technique in the semi-supervised learning literature. In particular, we augment data passing into the GAN discriminator and penalize the sensitivity of the discriminator to these augmentations. We conduct a series of experiments to demonstrate that consistency regularization works effectively with spectral normalization and various GAN architectures, loss functions and optimizer settings. Our method achieves the best FID scores for unconditional image generation compared to other regularization methods on CIFAR-10 and CelebA. Moreover, Our consistency regularized GAN (CR-GAN) improves state-of-the-art FID scores for conditional generation from 14.73 to 11.67 on CIFAR-10 and from 8.73 to 6.66 on ImageNet-2012.
Improving Differentially Private Models with Active Learning
Oct 02, 2019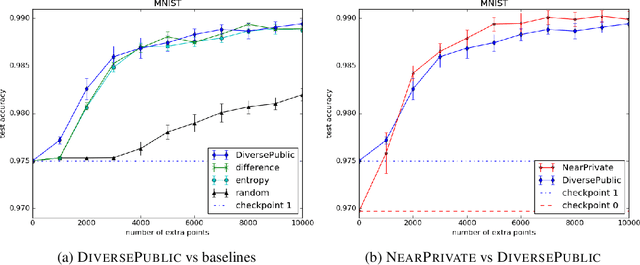
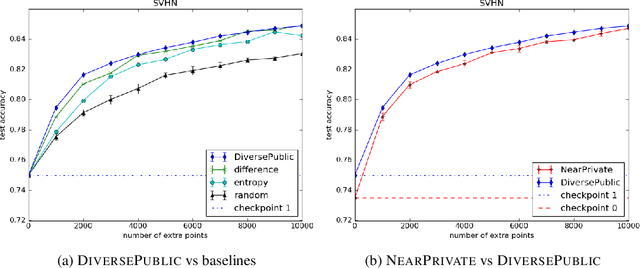
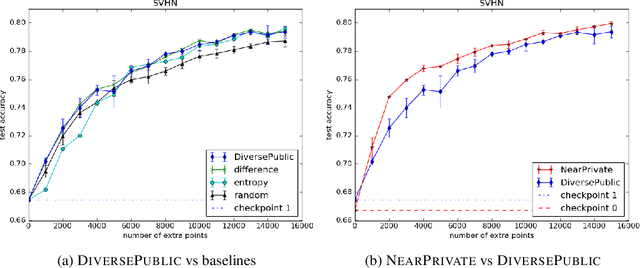
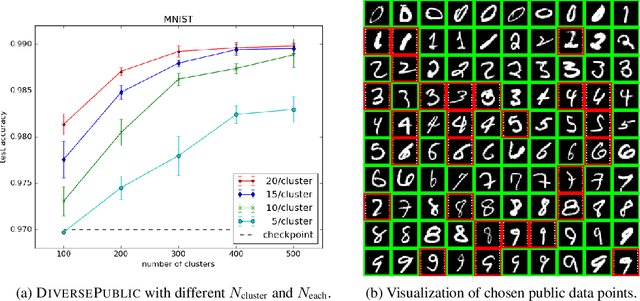
Broad adoption of machine learning techniques has increased privacy concerns for models trained on sensitive data such as medical records. Existing techniques for training differentially private (DP) models give rigorous privacy guarantees, but applying these techniques to neural networks can severely degrade model performance. This performance reduction is an obstacle to deploying private models in the real world. In this work, we improve the performance of DP models by fine-tuning them through active learning on public data. We introduce two new techniques - DIVERSEPUBLIC and NEARPRIVATE - for doing this fine-tuning in a privacy-aware way. For the MNIST and SVHN datasets, these techniques improve state-of-the-art accuracy for DP models while retaining privacy guarantees.
Realistic Evaluation of Deep Semi-Supervised Learning Algorithms
Oct 26, 2018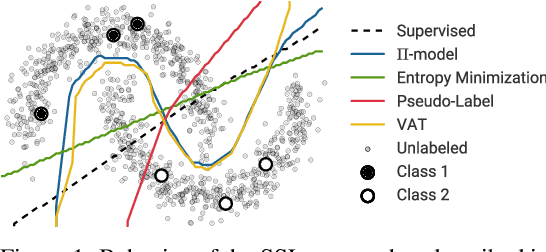

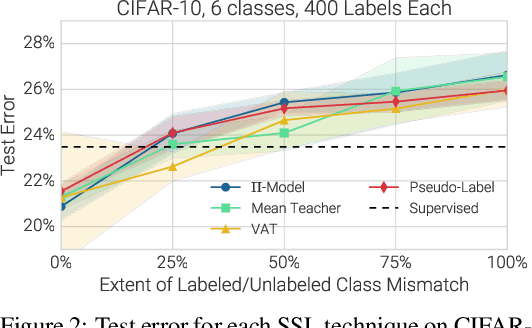

Semi-supervised learning (SSL) provides a powerful framework for leveraging unlabeled data when labels are limited or expensive to obtain. SSL algorithms based on deep neural networks have recently proven successful on standard benchmark tasks. However, we argue that these benchmarks fail to address many issues that these algorithms would face in real-world applications. After creating a unified reimplementation of various widely-used SSL techniques, we test them in a suite of experiments designed to address these issues. We find that the performance of simple baselines which do not use unlabeled data is often underreported, that SSL methods differ in sensitivity to the amount of labeled and unlabeled data, and that performance can degrade substantially when the unlabeled dataset contains out-of-class examples. To help guide SSL research towards real-world applicability, we make our unified reimplemention and evaluation platform publicly available.
Discriminator Rejection Sampling
Oct 18, 2018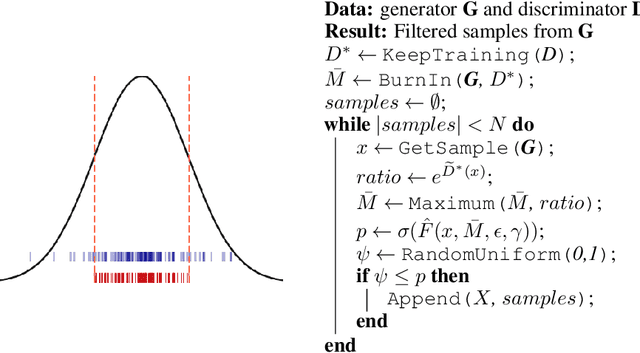

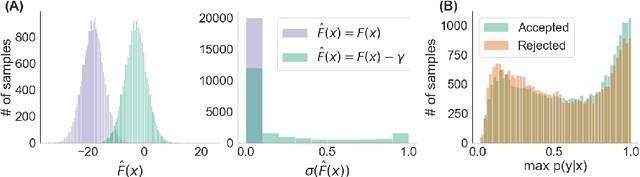

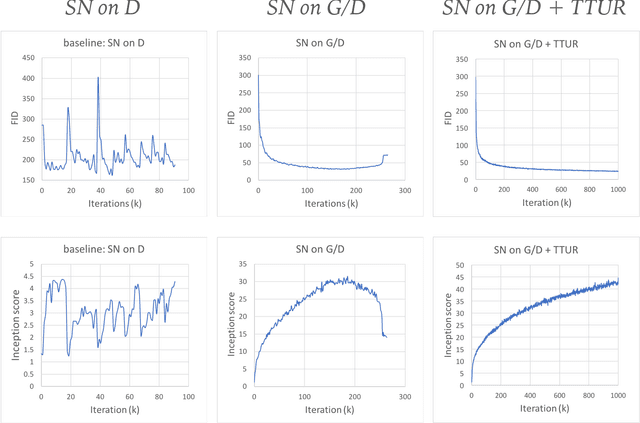
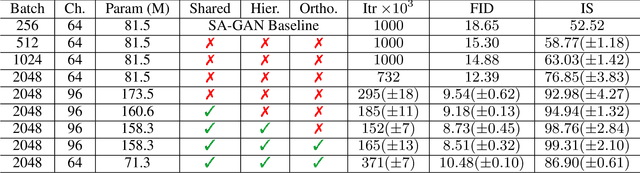
We propose a rejection sampling scheme using the discriminator of a GAN to approximately correct errors in the GAN generator distribution. We show that under quite strict assumptions, this will allow us to recover the data distribution exactly. We then examine where those strict assumptions break down and design a practical algorithm - called Discriminator Rejection Sampling (DRS) - that can be used on real data-sets. Finally, we demonstrate the efficacy of DRS on a mixture of Gaussians and on the SAGAN model, state-of-the-art in the image generation task at the time of developing this work. On ImageNet, we train an improved baseline that increases the Inception Score from 52.52 to 62.36 and reduces the Frechet Inception Distance from 18.65 to 14.79. We then use DRS to further improve on this baseline, improving the Inception Score to 76.08 and the FID to 13.75.
Skill Rating for Generative Models
Aug 14, 2018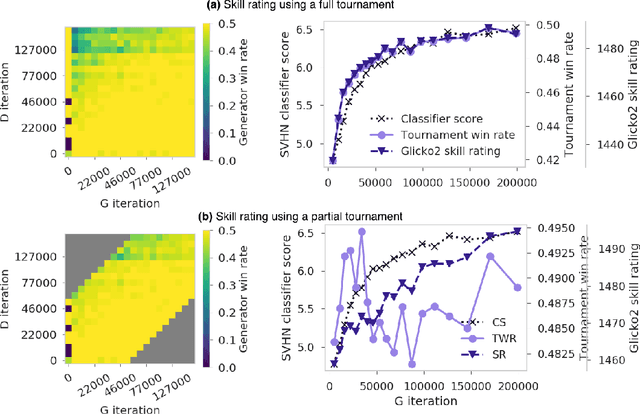
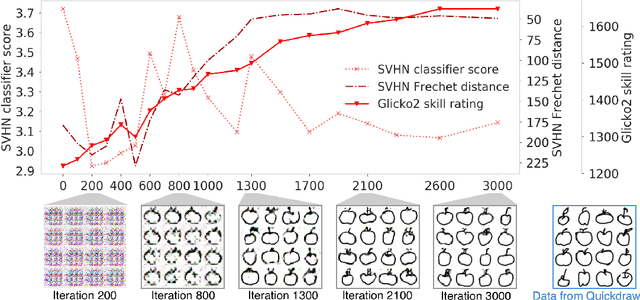
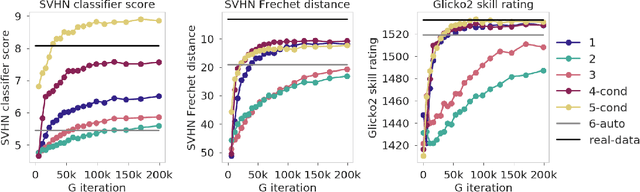

We explore a new way to evaluate generative models using insights from evaluation of competitive games between human players. We show experimentally that tournaments between generators and discriminators provide an effective way to evaluate generative models. We introduce two methods for summarizing tournament outcomes: tournament win rate and skill rating. Evaluations are useful in different contexts, including monitoring the progress of a single model as it learns during the training process, and comparing the capabilities of two different fully trained models. We show that a tournament consisting of a single model playing against past and future versions of itself produces a useful measure of training progress. A tournament containing multiple separate models (using different seeds, hyperparameters, and architectures) provides a useful relative comparison between different trained GANs. Tournament-based rating methods are conceptually distinct from numerous previous categories of approaches to evaluation of generative models, and have complementary advantages and disadvantages.
TensorFuzz: Debugging Neural Networks with Coverage-Guided Fuzzing
Jul 28, 2018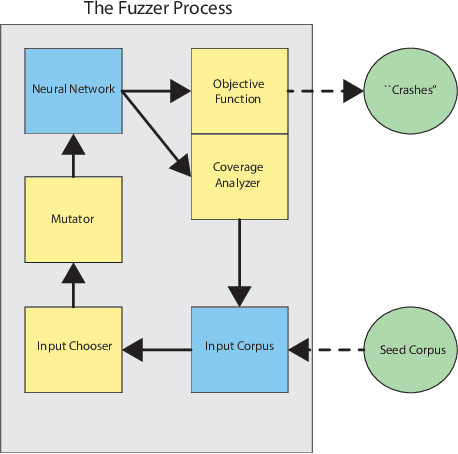
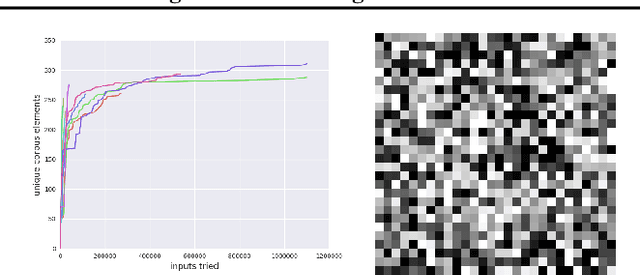
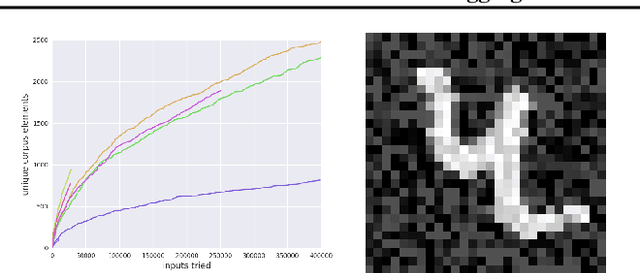
Machine learning models are notoriously difficult to interpret and debug. This is particularly true of neural networks. In this work, we introduce automated software testing techniques for neural networks that are well-suited to discovering errors which occur only for rare inputs. Specifically, we develop coverage-guided fuzzing (CGF) methods for neural networks. In CGF, random mutations of inputs to a neural network are guided by a coverage metric toward the goal of satisfying user-specified constraints. We describe how fast approximate nearest neighbor algorithms can provide this coverage metric. We then discuss the application of CGF to the following goals: finding numerical errors in trained neural networks, generating disagreements between neural networks and quantized versions of those networks, and surfacing undesirable behavior in character level language models. Finally, we release an open source library called TensorFuzz that implements the described techniques.
Is Generator Conditioning Causally Related to GAN Performance?
Jun 19, 2018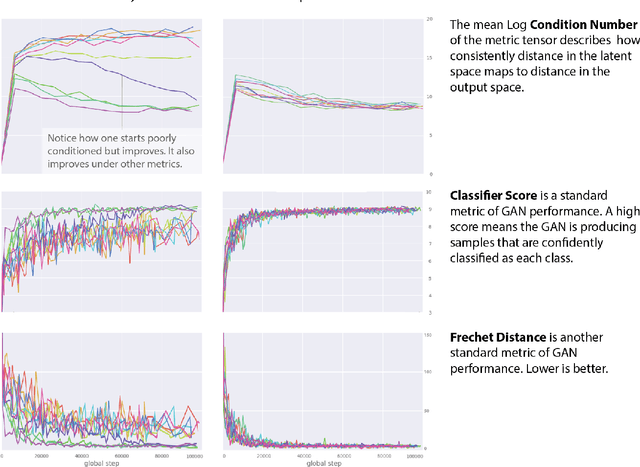
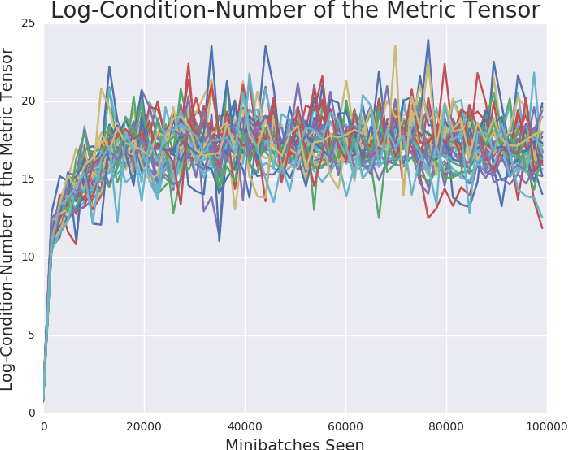
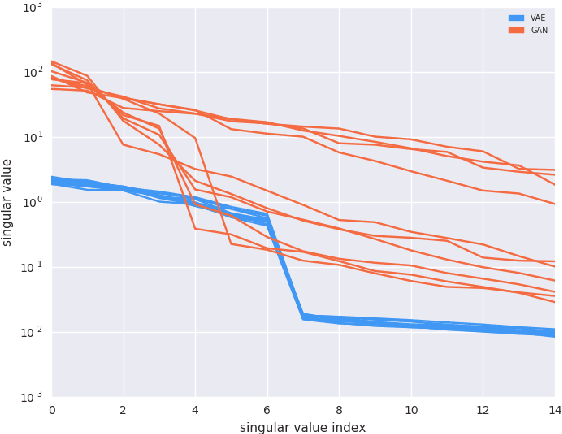
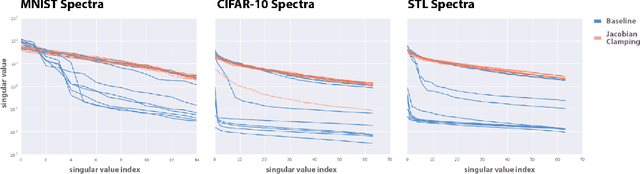
Recent work (Pennington et al, 2017) suggests that controlling the entire distribution of Jacobian singular values is an important design consideration in deep learning. Motivated by this, we study the distribution of singular values of the Jacobian of the generator in Generative Adversarial Networks (GANs). We find that this Jacobian generally becomes ill-conditioned at the beginning of training. Moreover, we find that the average (with z from p(z)) conditioning of the generator is highly predictive of two other ad-hoc metrics for measuring the 'quality' of trained GANs: the Inception Score and the Frechet Inception Distance (FID). We test the hypothesis that this relationship is causal by proposing a 'regularization' technique (called Jacobian Clamping) that softly penalizes the condition number of the generator Jacobian. Jacobian Clamping improves the mean Inception Score and the mean FID for GANs trained on several datasets. It also greatly reduces inter-run variance of the aforementioned scores, addressing (at least partially) one of the main criticisms of GANs.
Self-Attention Generative Adversarial Networks
May 21, 2018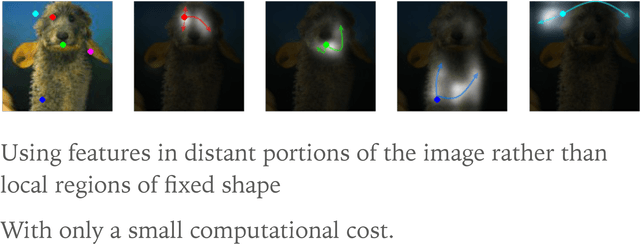

In this paper, we propose the Self-Attention Generative Adversarial Network (SAGAN) which allows attention-driven, long-range dependency modeling for image generation tasks. Traditional convolutional GANs generate high-resolution details as a function of only spatially local points in lower-resolution feature maps. In SAGAN, details can be generated using cues from all feature locations. Moreover, the discriminator can check that highly detailed features in distant portions of the image are consistent with each other. Furthermore, recent work has shown that generator conditioning affects GAN performance. Leveraging this insight, we apply spectral normalization to the GAN generator and find that this improves training dynamics. The proposed SAGAN achieves the state-of-the-art results, boosting the best published Inception score from 36.8 to 52.52 and reducing Frechet Inception distance from 27.62 to 18.65 on the challenging ImageNet dataset. Visualization of the attention layers shows that the generator leverages neighborhoods that correspond to object shapes rather than local regions of fixed shape.
Conditional Image Synthesis With Auxiliary Classifier GANs
Jul 20, 2017
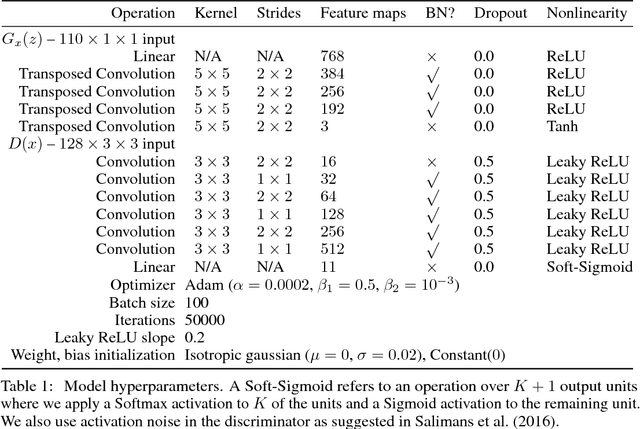
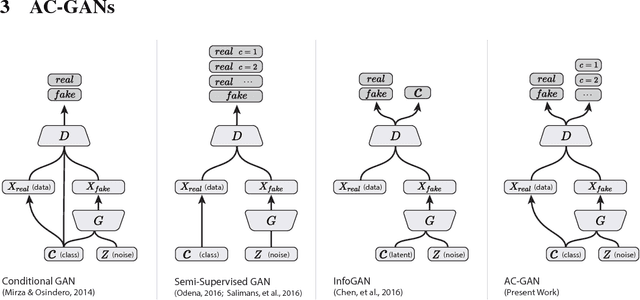
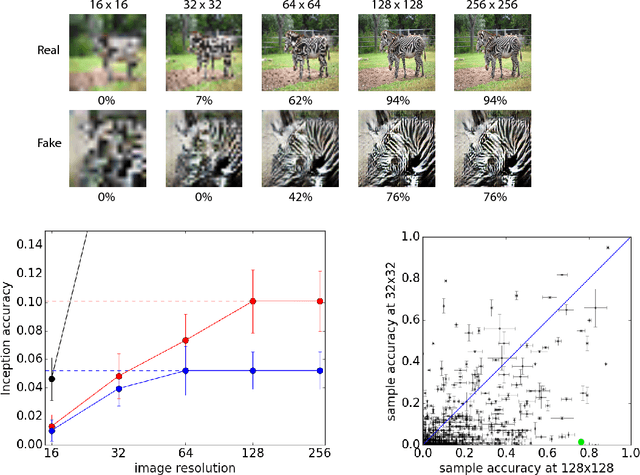
Synthesizing high resolution photorealistic images has been a long-standing challenge in machine learning. In this paper we introduce new methods for the improved training of generative adversarial networks (GANs) for image synthesis. We construct a variant of GANs employing label conditioning that results in 128x128 resolution image samples exhibiting global coherence. We expand on previous work for image quality assessment to provide two new analyses for assessing the discriminability and diversity of samples from class-conditional image synthesis models. These analyses demonstrate that high resolution samples provide class information not present in low resolution samples. Across 1000 ImageNet classes, 128x128 samples are more than twice as discriminable as artificially resized 32x32 samples. In addition, 84.7% of the classes have samples exhibiting diversity comparable to real ImageNet data.
Changing Model Behavior at Test-Time Using Reinforcement Learning
Feb 24, 2017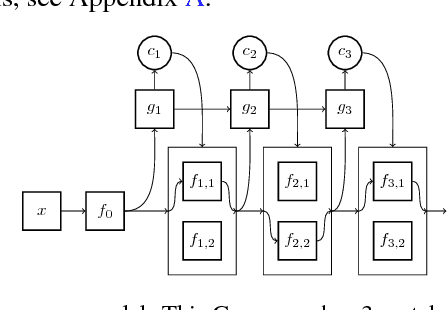
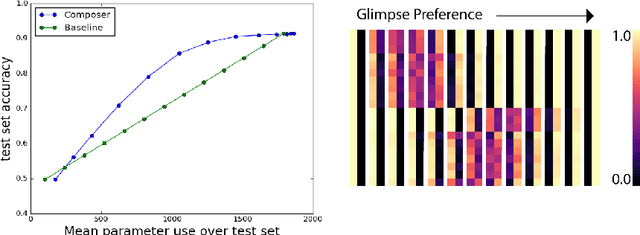

Machine learning models are often used at test-time subject to constraints and trade-offs not present at training-time. For example, a computer vision model operating on an embedded device may need to perform real-time inference, or a translation model operating on a cell phone may wish to bound its average compute time in order to be power-efficient. In this work we describe a mixture-of-experts model and show how to change its test-time resource-usage on a per-input basis using reinforcement learning. We test our method on a small MNIST-based example.