 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Deep Visual Representations via Network Dissection
Jun 26, 2018



The success of recent deep convolutional neural networks (CNNs) depends on learning hidden representations that can summarize the important factors of variation behind the data. However, CNNs often criticized as being black boxes that lack interpretability, since they have millions of unexplained model parameters. In this work, we describe Network Dissection, a method that interprets networks by providing labels for the units of their deep visual representations. The proposed method quantifies the interpretability of CNN representations by evaluating the alignment between individual hidden units and a set of visual semantic concepts. By identifying the best alignments, units are given human interpretable labels across a range of objects, parts, scenes, textures, materials, and colors. The method reveals that deep representations are more transparent and interpretable than expected: we find that representations are significantly more interpretable than they would be under a random equivalently powerful basis. We apply the method to interpret and compare the latent representations of various network architectures trained to solve different supervised and self-supervised training tasks. We then examine factors affecting the network interpretability such as the number of the training iterations, regularizations, different initializations, and the network depth and width. Finally we show that the interpreted units can be used to provide explicit explanations of a prediction given by a CNN for an image. Our results highlight that interpretability is an important property of deep neural networks that provides new insights into their hierarchical structure.
Moments in Time Dataset: one million videos for event understanding
Jan 09, 2018
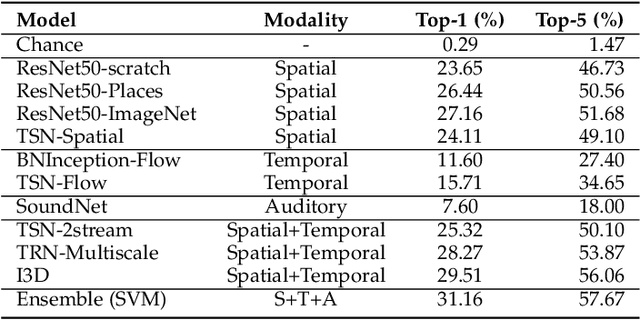

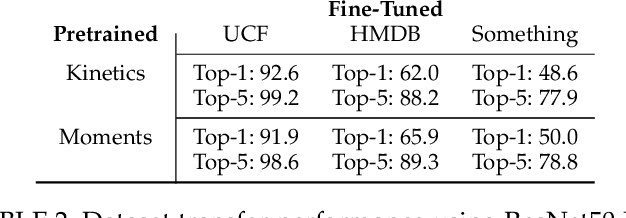
We present the Moments in Time Dataset, a large-scale human-annotated collection of one million short videos corresponding to dynamic events unfolding within three seconds. Modeling the spatial-audio-temporal dynamics even for actions occurring in 3 second videos poses many challenges: meaningful events do not include only people, but also objects, animals, and natural phenomena; visual and auditory events can be symmetrical or not in time ("opening" means "closing" in reverse order), and transient or sustained. We describe the annotation process of our dataset (each video is tagged with one action or activity label among 339 different classes), analyze its scale and diversity in comparison to other large-scale video datasets for action recognition, and report results of several baseline models addressing separately and jointly three modalities: spatial, temporal and auditory. The Moments in Time dataset designed to have a large coverage and diversity of events in both visual and auditory modalities, can serve as a new challenge to develop models that scale to the level of complexity and abstract reasoning that a human processes on a daily basis.
Understanding Infographics through Textual and Visual Tag Prediction
Sep 26, 2017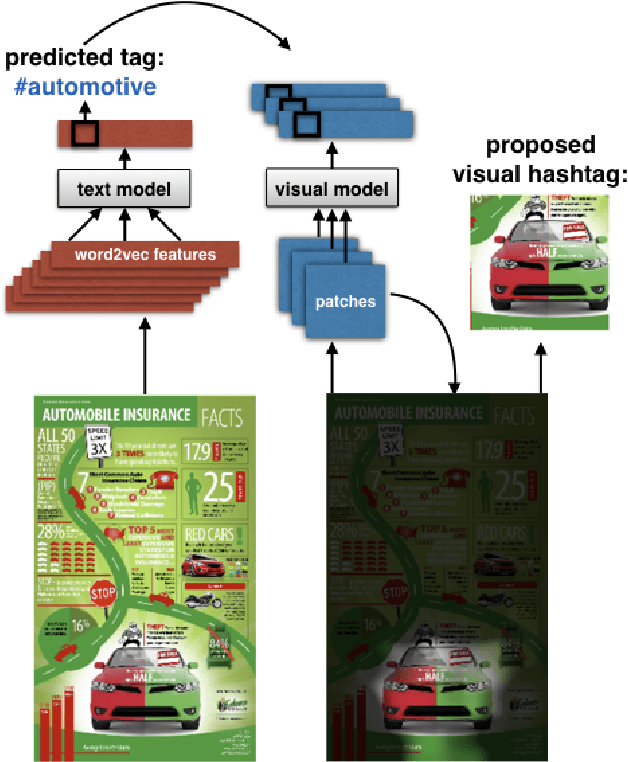


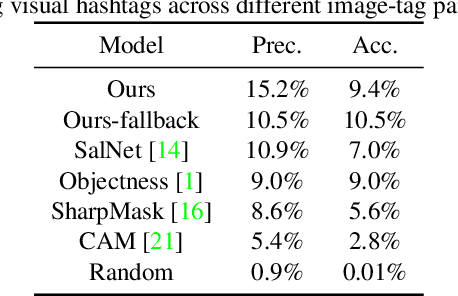
We introduce the problem of visual hashtag discovery for infographics: extracting visual elements from an infographic that are diagnostic of its topic. Given an infographic as input, our computational approach automatically outputs textual and visual elements predicted to be representative of the infographic content. Concretely, from a curated dataset of 29K large infographic images sampled across 26 categories and 391 tags, we present an automated two step approach. First, we extract the text from an infographic and use it to predict text tags indicative of the infographic content. And second, we use these predicted text tags as a supervisory signal to localize the most diagnostic visual elements from within the infographic i.e. visual hashtags. We report performances on a categorization and multi-label tag prediction problem and compare our proposed visual hashtags to human annotations.
BubbleView: an interface for crowdsourcing image importance maps and tracking visual attention
Aug 09, 2017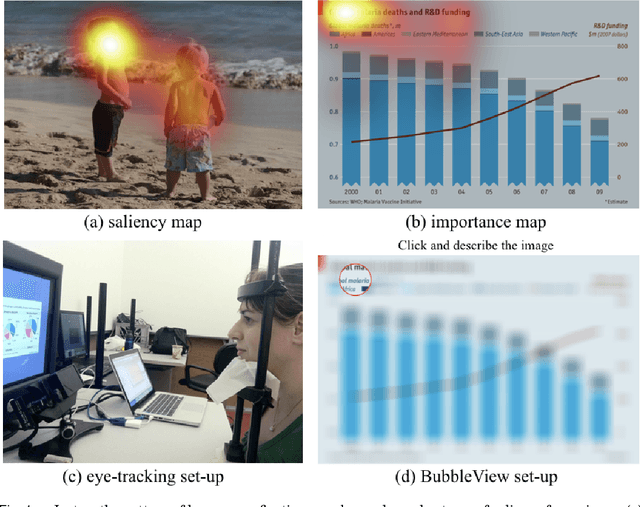
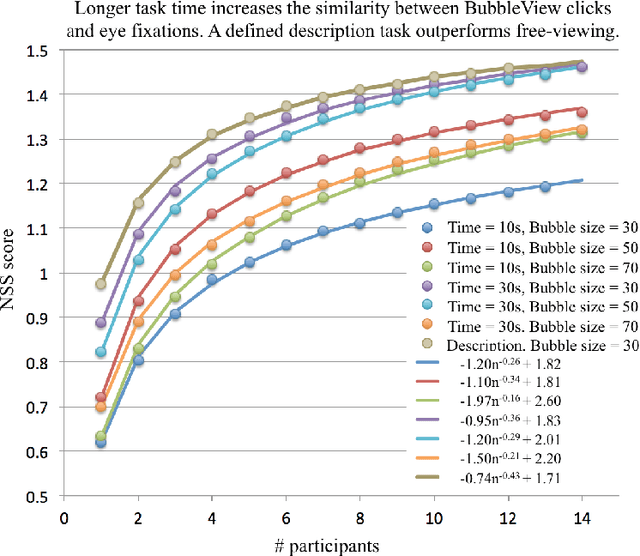

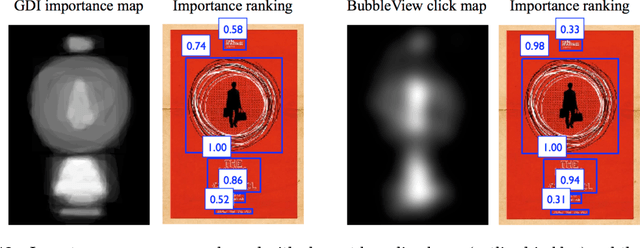
In this paper, we present BubbleView, an alternative methodology for eye tracking using discrete mouse clicks to measure which information people consciously choose to examine. BubbleView is a mouse-contingent, moving-window interface in which participants are presented with a series of blurred images and click to reveal "bubbles" - small, circular areas of the image at original resolution, similar to having a confined area of focus like the eye fovea. Across 10 experiments with 28 different parameter combinations, we evaluated BubbleView on a variety of image types: information visualizations, natural images, static webpages, and graphic designs, and compared the clicks to eye fixations collected with eye-trackers in controlled lab settings. We found that BubbleView clicks can both (i) successfully approximate eye fixations on different images, and (ii) be used to rank image and design elements by importance. BubbleView is designed to collect clicks on static images, and works best for defined tasks such as describing the content of an information visualization or measuring image importance. BubbleView data is cleaner and more consistent than related methodologies that use continuous mouse movements. Our analyses validate the use of mouse-contingent, moving-window methodologies as approximating eye fixations for different image and task types.
Network Dissection: Quantifying Interpretability of Deep Visual Representations
Apr 19, 2017



We propose a general framework called Network Dissection for quantifying the interpretability of latent representations of CNNs by evaluating the alignment between individual hidden units and a set of semantic concepts. Given any CNN model, the proposed method draws on a broad data set of visual concepts to score the semantics of hidden units at each intermediate convolutional layer. The units with semantics are given labels across a range of objects, parts, scenes, textures, materials, and colors. We use the proposed method to test the hypothesis that interpretability of units is equivalent to random linear combinations of units, then we apply our method to compare the latent representations of various networks when trained to solve different supervised and self-supervised training tasks. We further analyze the effect of training iterations, compare networks trained with different initializations, examine the impact of network depth and width, and measure the effect of dropout and batch normalization on the interpretability of deep visual representations. We demonstrate that the proposed method can shed light on characteristics of CNN models and training methods that go beyond measurements of their discriminative power.
What do different evaluation metrics tell us about saliency models?
Apr 06, 2017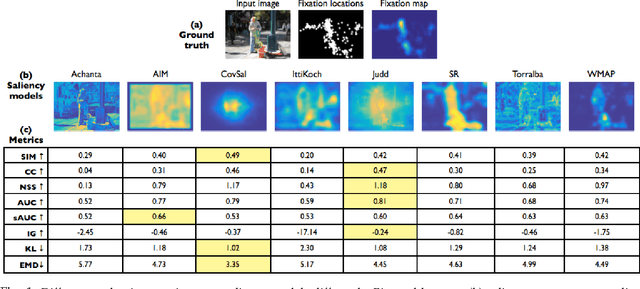

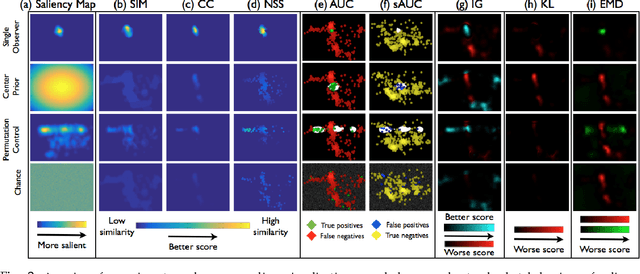
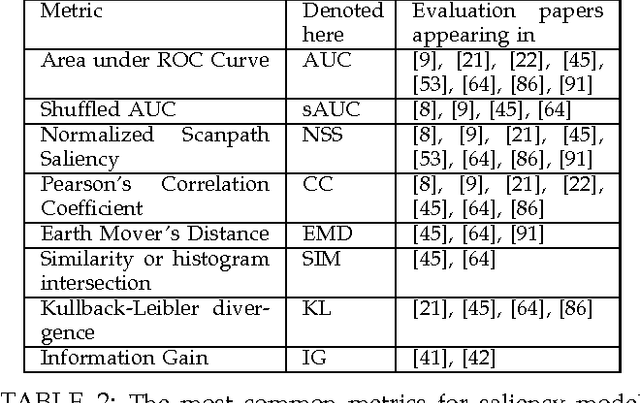
How best to evaluate a saliency model's ability to predict where humans look in images is an open research question. The choice of evaluation metric depends on how saliency is defined and how the ground truth is represented. Metrics differ in how they rank saliency models, and this results from how false positives and false negatives are treated, whether viewing biases are accounted for, whether spatial deviations are factored in, and how the saliency maps are pre-processed. In this paper, we provide an analysis of 8 different evaluation metrics and their properties. With the help of systematic experiments and visualizations of metric computations, we add interpretability to saliency scores and more transparency to the evaluation of saliency models. Building off the differences in metric properties and behaviors, we make recommendations for metric selections under specific assumptions and for specific applications.
Places: An Image Database for Deep Scene Understanding
Oct 06, 2016
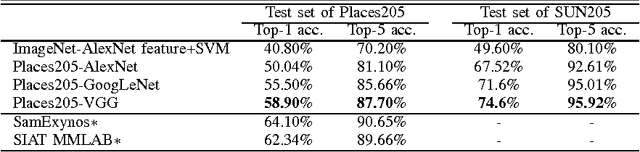

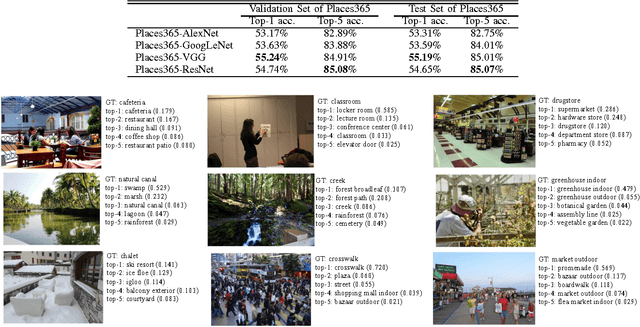
The rise of multi-million-item dataset initiatives has enabled data-hungry machine learning algorithms to reach near-human semantic classification at tasks such as object and scene recognition. Here we describe the Places Database, a repository of 10 million scene photographs, labeled with scene semantic categories and attributes, comprising a quasi-exhaustive list of the types of environments encountered in the world. Using state of the art Convolutional Neural Networks, we provide impressive baseline performances at scene classification. With its high-coverage and high-diversity of exemplars, the Places Database offers an ecosystem to guide future progress on currently intractable visual recognition problems.
Deep Neural Networks predict Hierarchical Spatio-temporal Cortical Dynamics of Human Visual Object Recognition
Jan 12, 2016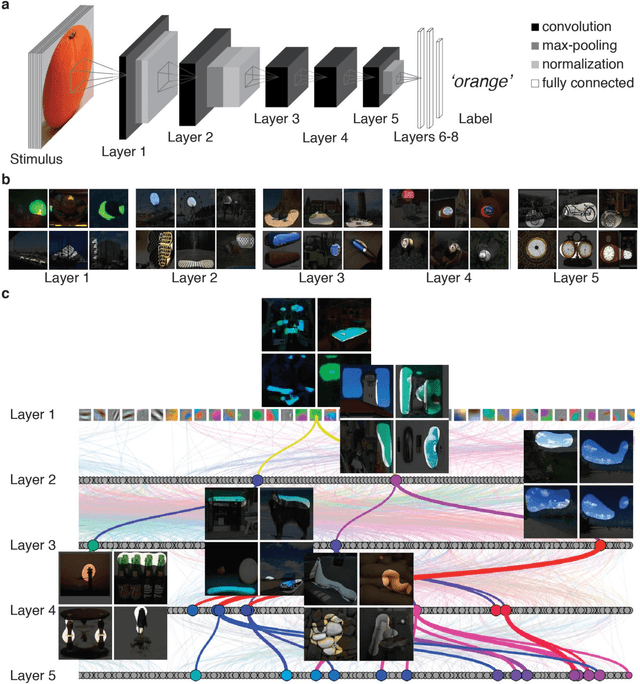
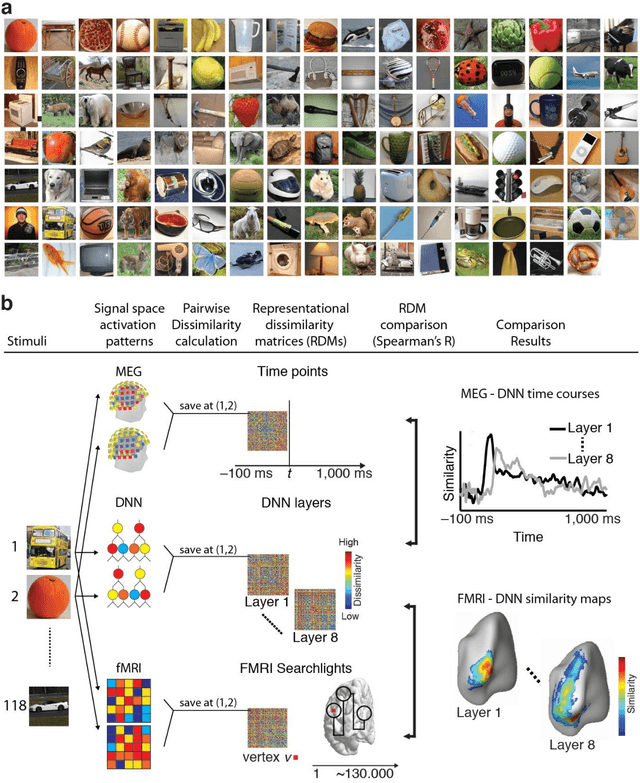
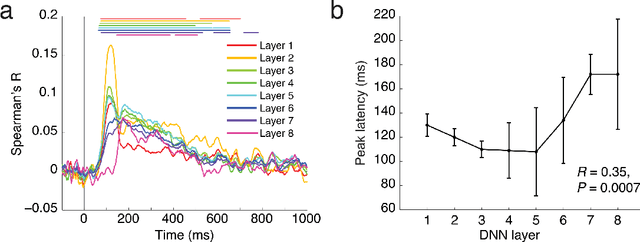
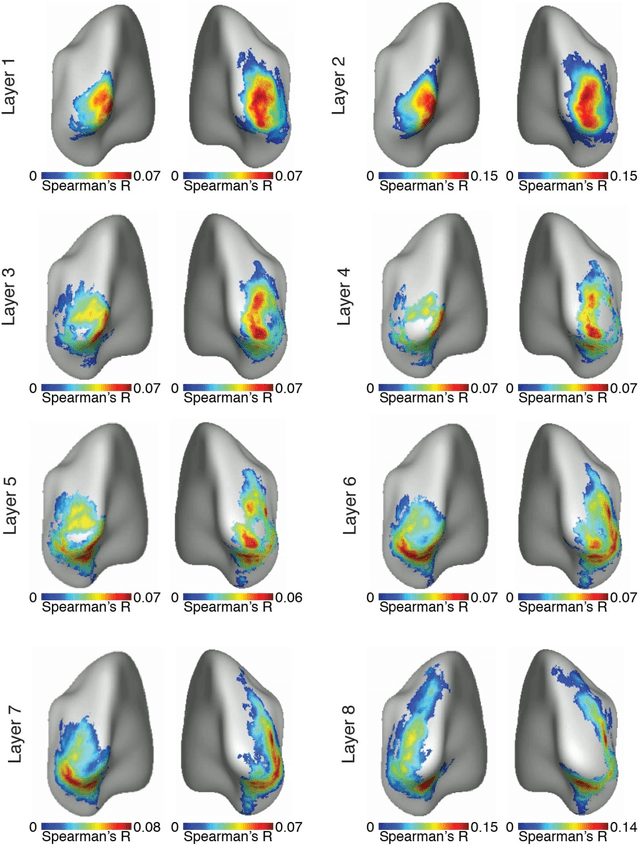
The complex multi-stage architecture of cortical visual pathways provides the neural basis for efficient visual object recognition in humans. However, the stage-wise computations therein remain poorly understood. Here, we compared temporal (magnetoencephalography) and spatial (functional MRI) visual brain representations with representations in an artificial deep neural network (DNN) tuned to the statistics of real-world visual recognition. We showed that the DNN captured the stages of human visual processing in both time and space from early visual areas towards the dorsal and ventral streams. Further investigation of crucial DNN parameters revealed that while model architecture was important, training on real-world categorization was necessary to enforce spatio-temporal hierarchical relationships with the brain. Together our results provide an algorithmically informed view on the spatio-temporal dynamics of visual object recognition in the human visual brain.
Learning Deep Features for Discriminative Localization
Dec 14, 2015



In this work, we revisit the global average pooling layer proposed in [13], and shed light on how it explicitly enables the convolutional neural network to have remarkable localization ability despite being trained on image-level labels. While this technique was previously proposed as a means for regularizing training, we find that it actually builds a generic localizable deep representation that can be applied to a variety of tasks. Despite the apparent simplicity of global average pooling, we are able to achieve 37.1% top-5 error for object localization on ILSVRC 2014, which is remarkably close to the 34.2% top-5 error achieved by a fully supervised CNN approach. We demonstrate that our network is able to localize the discriminative image regions on a variety of tasks despite not being trained for them
Learning visual biases from human imagination
Nov 16, 2015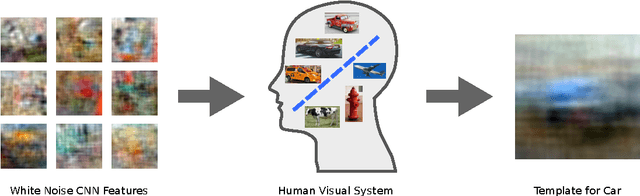


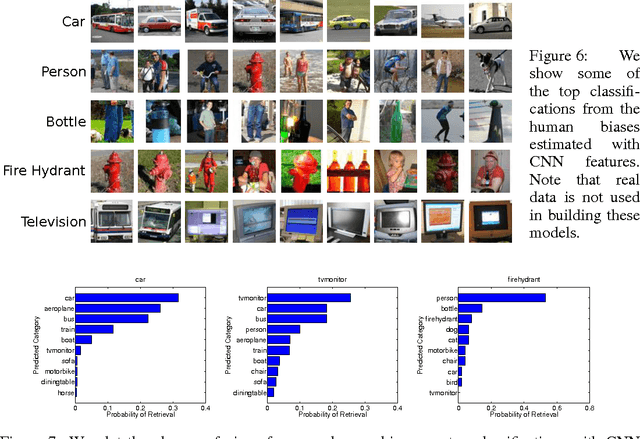
Although the human visual system can recognize many concepts under challenging conditions, it still has some biases. In this paper, we investigate whether we can extract these biases and transfer them into a machine recognition system. We introduce a novel method that, inspired by well-known tools in human psychophysics, estimates the biases that the human visual system might use for recognition, but in computer vision feature spaces. Our experiments are surprising, and suggest that classifiers from the human visual system can be transferred into a machine with some success. Since these classifiers seem to capture favorable biases in the human visual system, we further present an SVM formulation that constrains the orientation of the SVM hyperplane to agree with the bias from human visual system. Our results suggest that transferring this human bias into machines may help object recognition systems generalize across datasets and perform better when very little training data is available.