 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Modular Networks: Learning to Decompose Tasks in the Language of Existing Models
Sep 01, 2020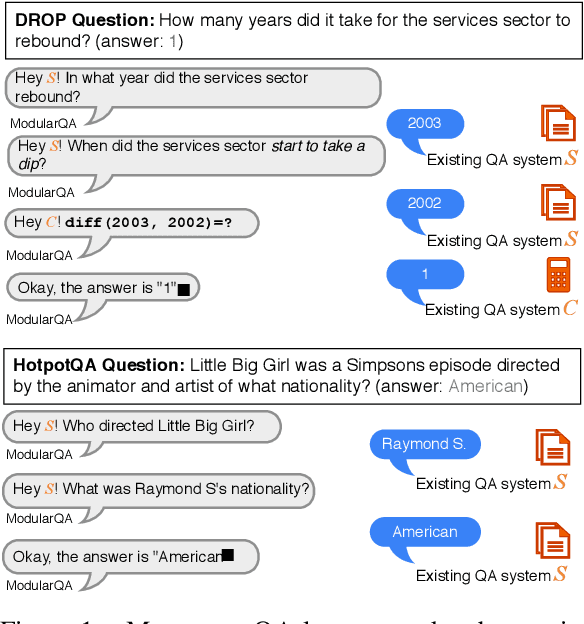

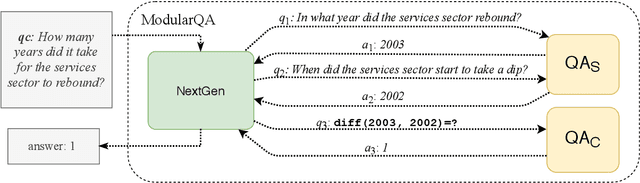
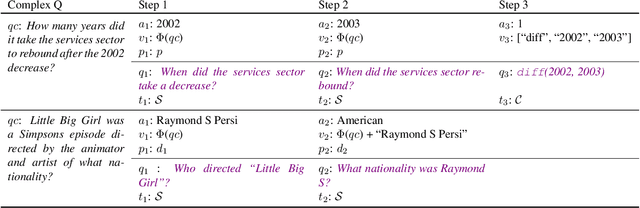
A common approach to solve complex tasks is by breaking them down into simple sub-problems that can then be solved by simpler modules. However, these approaches often need to be designed and trained specifically for each complex task. We propose a general approach, Text Modular Networks(TMNs), where the system learns to decompose any complex task into the language of existing models. Specifically, we focus on Question Answering (QA) and learn to decompose complex questions into sub-questions answerable by existing QA models. TMNs treat these models as blackboxes and learn their textual input-output behavior (i.e., their language) through their task datasets. Our next-question generator then learns to sequentially produce sub-questions that help answer a given complex question. These sub-questions are posed to different existing QA models and, together with their answers, provide a natural language explanation of the exact reasoning used by the model. We present the first system, incorporating a neural factoid QA model and a symbolic calculator, that uses decomposition for the DROP dataset, while also generalizing to the multi-hop HotpotQA dataset. Our system, ModularQA, outperforms a cross-task baseline by 10-60 F1 points and performs comparable to task-specific systems, while also providing an easy-to-read explanation of its reasoning.
Belief Propagation Neural Networks
Jul 01, 2020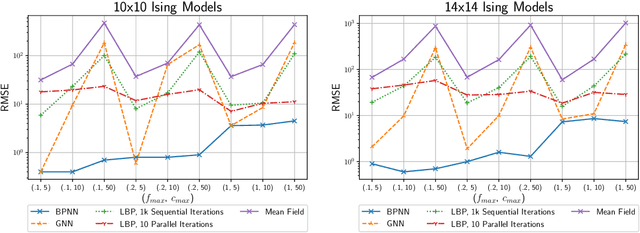

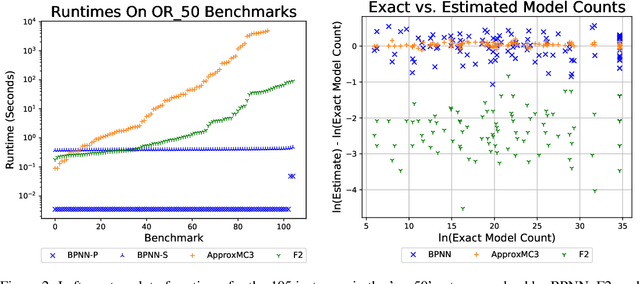
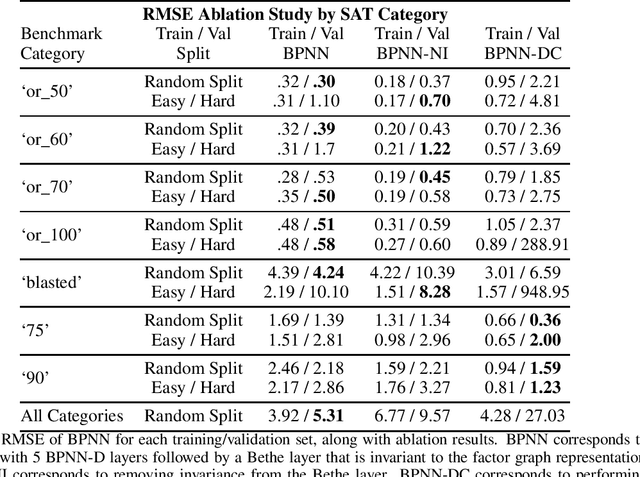
Learned neural solvers have successfully been used to solve combinatorial optimization and decision problems. More general counting variants of these problems, however, are still largely solved with hand-crafted solvers. To bridge this gap, we introduce belief propagation neural networks (BPNNs), a class of parameterized operators that operate on factor graphs and generalize Belief Propagation (BP). In its strictest form, a BPNN layer (BPNN-D) is a learned iterative operator that provably maintains many of the desirable properties of BP for any choice of the parameters. Empirically, we show that by training BPNN-D learns to perform the task better than the original BP: it converges 1.7x faster on Ising models while providing tighter bounds. On challenging model counting problems, BPNNs compute estimates 100's of times faster than state-of-the-art handcrafted methods, while returning an estimate of comparable quality.
Measuring and Reducing Non-Multifact Reasoning in Multi-hop Question Answering
May 02, 2020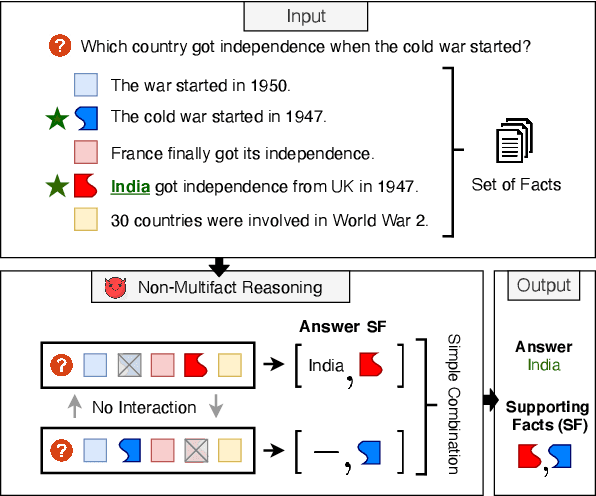
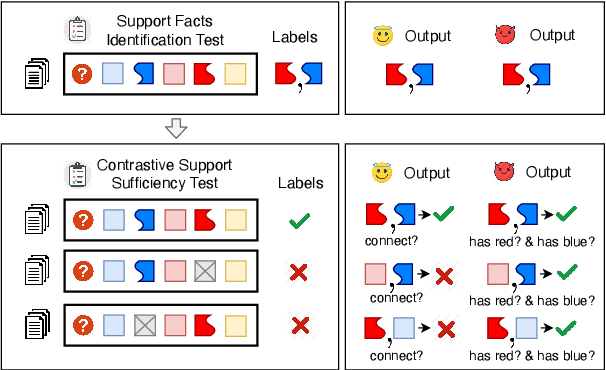
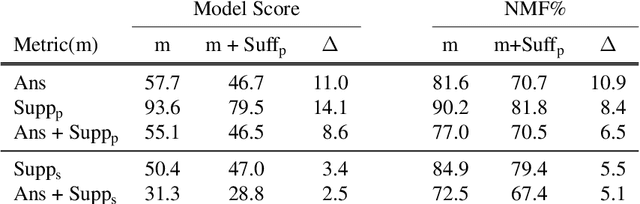
The measurement of true progress in multihop question-answering has been muddled by the strong ability of models to exploit artifacts and other reasoning shortcuts. Models can produce the correct answer, and even independently identify the supporting facts, without necessarily connecting the information between the facts. This defeats the purpose of building multihop QA datasets. We make three contributions towards addressing this issue. First, we formalize this form of disconnected reasoning and propose contrastive support sufficiency as a better test of multifact reasoning. To this end, we introduce an automated sufficiency-based dataset transformation that considers all possible partitions of supporting facts, capturing disconnected reasoning. Second, we develop a probe to measure how much can a model cheat (via non-multifact reasoning) on existing tests and our sufficiency test. Third, we conduct experiments using a transformer based model (XLNet), demonstrating that the sufficiency transform not only reduces the amount of non-multifact reasoning in this model by 6.5% but is also harder to cheat -- a non-multifact model sees a 20.8% (absolute) reduction in score compared to previous metrics.
UnifiedQA: Crossing Format Boundaries With a Single QA System
May 02, 2020


Question answering (QA) tasks have been posed using a variety of formats, such as extractive span selection, multiple choice, etc. This has led to format-specialized models, and even to an implicit division in the QA community. We argue that such boundaries are artificial and perhaps unnecessary, given the reasoning abilities we seek to teach are not governed by the format. As evidence, we use the latest advances in language modeling to build a single pre-trained QA model, UnifiedQA, that performs surprisingly well across 17 QA datasets spanning 4 diverse formats. UnifiedQA performs on par with 9 different models that were trained on individual datasets themselves. Even when faced with 12 unseen datasets of observed formats, UnifiedQA performs surprisingly well, showing strong generalization from its out-of-format training data. Finally, simply fine-tuning this pre-trained QA model into specialized models results in a new state of the art on 6 datasets, establishing UnifiedQA as a strong starting point for building QA systems.
A Simple Yet Strong Pipeline for HotpotQA
Apr 14, 2020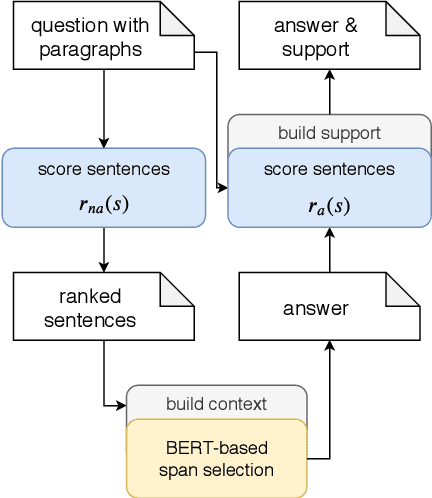
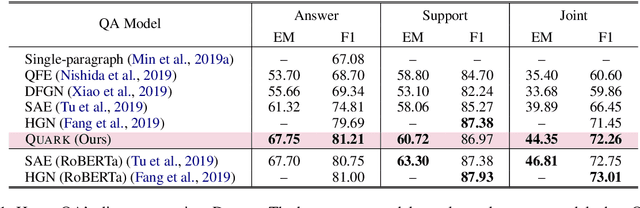
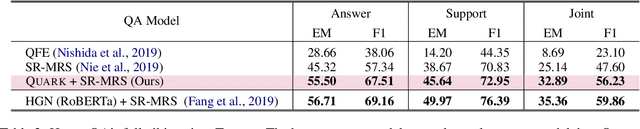
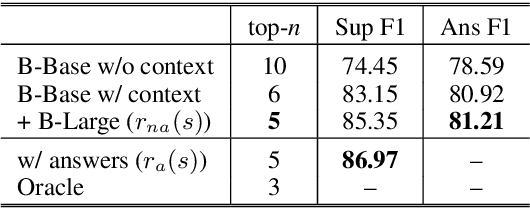
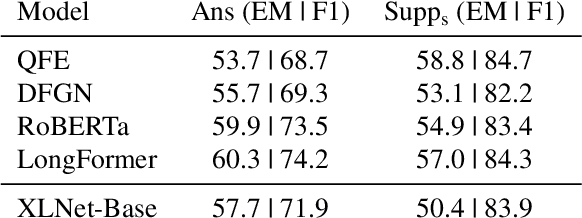
State-of-the-art models for multi-hop question answering typically augment large-scale language models like BERT with additional, intuitively useful capabilities such as named entity recognition, graph-based reasoning, and question decomposition. However, does their strong performance on popular multi-hop datasets really justify this added design complexity? Our results suggest that the answer may be no, because even our simple pipeline based on BERT, named Quark, performs surprisingly well. Specifically, on HotpotQA, Quark outperforms these models on both question answering and support identification (and achieves performance very close to a RoBERTa model). Our pipeline has three steps: 1) use BERT to identify potentially relevant sentences independently of each other; 2) feed the set of selected sentences as context into a standard BERT span prediction model to choose an answer; and 3) use the sentence selection model, now with the chosen answer, to produce supporting sentences. The strong performance of Quark resurfaces the importance of carefully exploring simple model designs before using popular benchmarks to justify the value of complex techniques.
Natural Perturbation for Robust Question Answering
Apr 09, 2020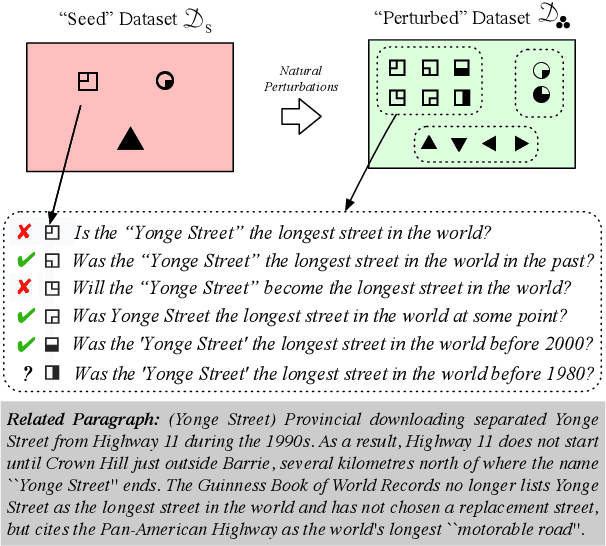
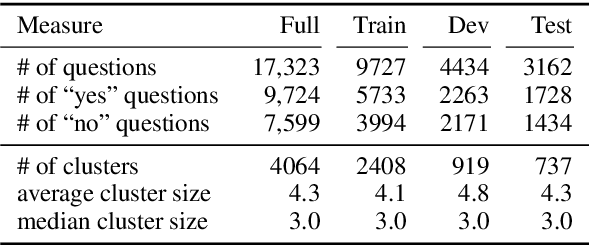
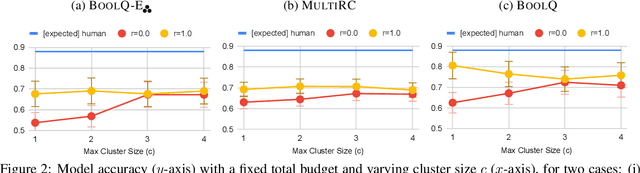
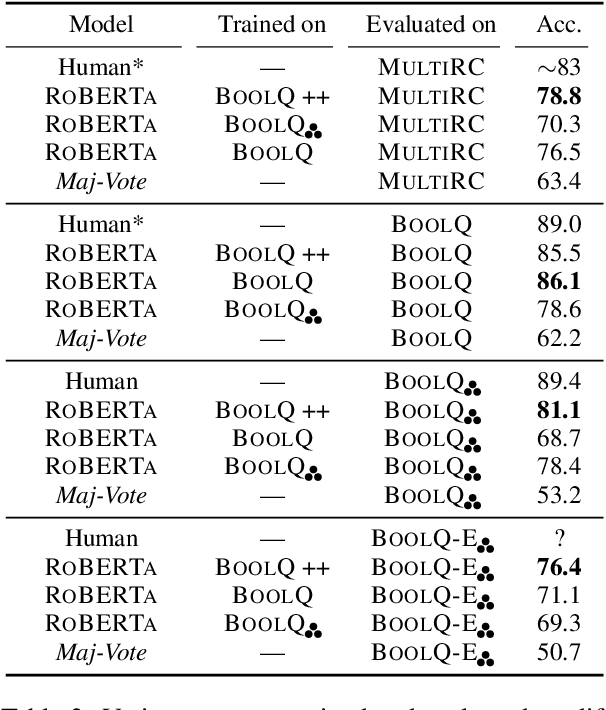
While recent models have achieved human-level scores on many NLP datasets, we observe that they are considerably sensitive to small changes in input. As an alternative to the standard approach of addressing this issue by constructing training sets of completely new examples, we propose doing so via minimal perturbation of examples. Specifically, our approach involves first collecting a set of seed examples and then applying human-driven natural perturbations (as opposed to rule-based machine perturbations), which often change the gold label as well. Local perturbations have the advantage of being relatively easier (and hence cheaper) to create than writing out completely new examples. To evaluate the impact of this phenomenon, we consider a recent question-answering dataset (BoolQ) and study the benefit of our approach as a function of the perturbation cost ratio, the relative cost of perturbing an existing question vs. creating a new one from scratch. We find that when natural perturbations are moderately cheaper to create, it is more effective to train models using them: such models exhibit higher robustness and better generalization, while retaining performance on the original BoolQ dataset.
Adversarial Filters of Dataset Biases
Feb 20, 2020
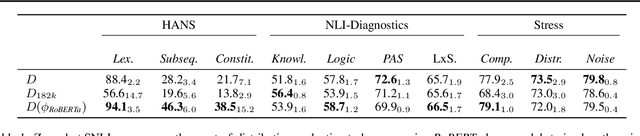
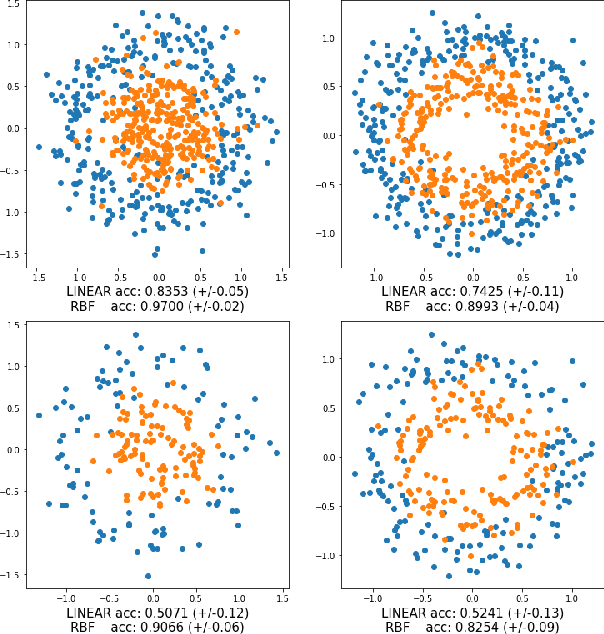

Large neural models have demonstrated human-level performance on language and vision benchmarks such as ImageNet and Stanford Natural Language Inference (SNLI). Yet, their performance degrades considerably when tested on adversarial or out-of-distribution samples. This raises the question of whether these models have learned to solve a dataset rather than the underlying task by overfitting on spurious dataset biases. We investigate one recently proposed approach, AFLite, which adversarially filters such dataset biases, as a means to mitigate the prevalent overestimation of machine performance. We provide a theoretical understanding for AFLite, by situating it in the generalized framework for optimum bias reduction. Our experiments show that as a result of the substantial reduction of these biases, models trained on the filtered datasets yield better generalization to out-of-distribution tasks, especially when the benchmarks used for training are over-populated with biased samples. We show that AFLite is broadly applicable to a variety of both real and synthetic datasets for reduction of measurable dataset biases and provide extensive supporting analyses. Finally, filtering results in a large drop in model performance (e.g., from 92% to 63% for SNLI), while human performance still remains high. Our work thus shows that such filtered datasets can pose new research challenges for robust generalization by serving as upgraded benchmarks.
What Does My QA Model Know? Devising Controlled Probes using Expert Knowledge
Dec 31, 2019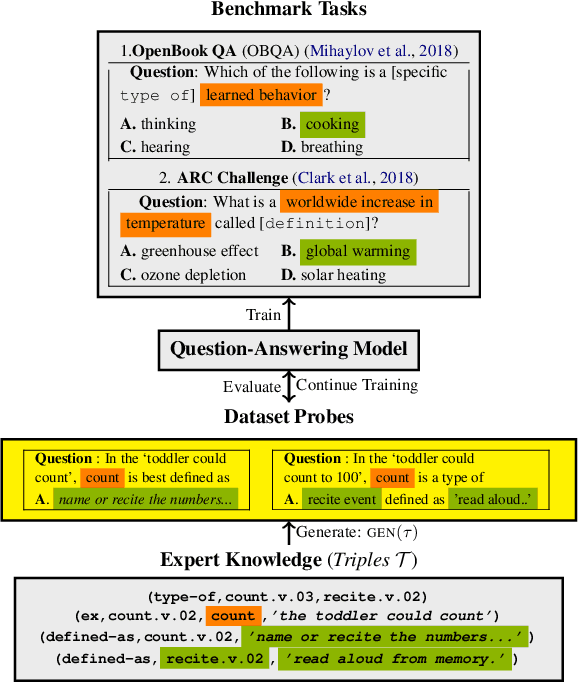
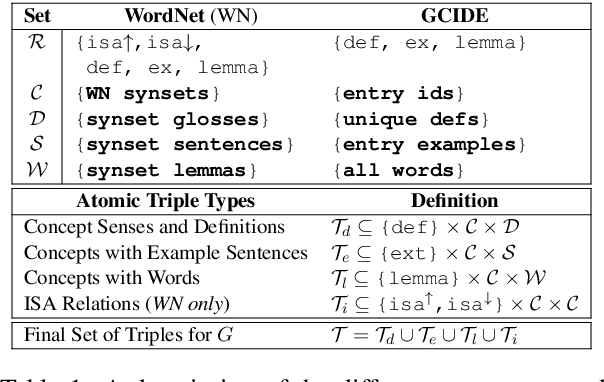
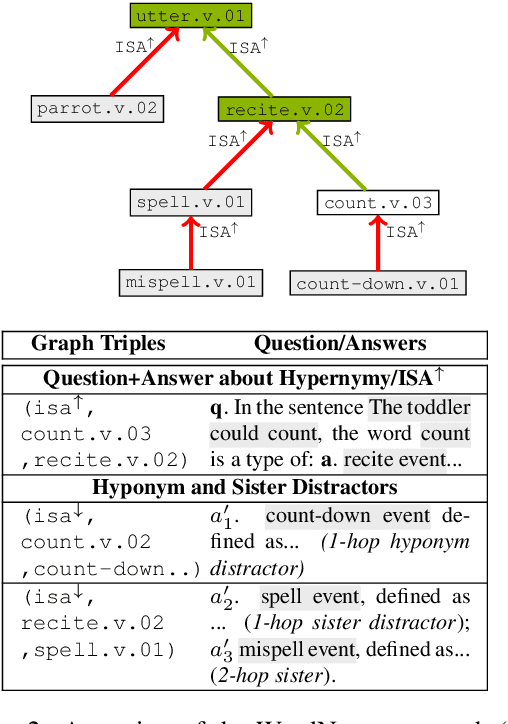
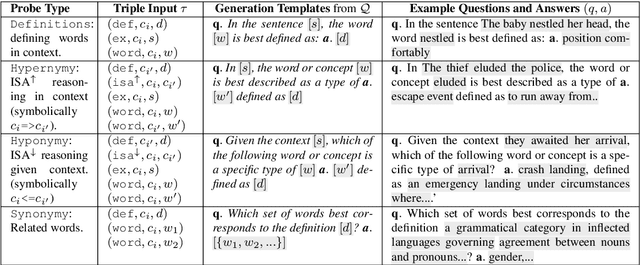
Open-domain question answering (QA) is known to involve several underlying knowledge and reasoning challenges, but are models actually learning such knowledge when trained on benchmark tasks? To investigate this, we introduce several new challenge tasks that probe whether state-of-the-art QA models have general knowledge about word definitions and general taxonomic reasoning, both of which are fundamental to more complex forms of reasoning and are widespread in benchmark datasets. As an alternative to expensive crowd-sourcing, we introduce a methodology for automatically building datasets from various types of expert knowledge (e.g., knowledge graphs and lexical taxonomies), allowing for systematic control over the resulting probes and for a more comprehensive evaluation. We find automatically constructing probes to be vulnerable to annotation artifacts, which we carefully control for. Our evaluation confirms that transformer-based QA models are already predisposed to recognize certain types of structural lexical knowledge. However, it also reveals a more nuanced picture: their performance degrades substantially with even a slight increase in the number of hops in the underlying taxonomic hierarchy, or as more challenging distractor candidate answers are introduced. Further, even when these models succeed at the standard instance-level evaluation, they leave much room for improvement when assessed at the level of clusters of semantically connected probes (e.g., all Isa questions about a concept).
Approximating the Permanent by Sampling from Adaptive Partitions
Nov 26, 2019

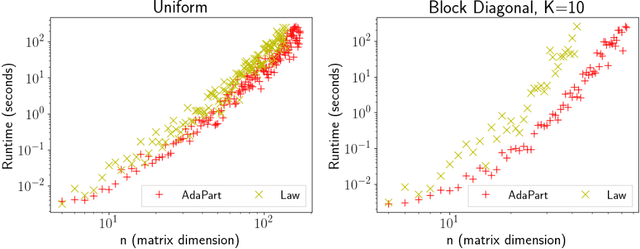
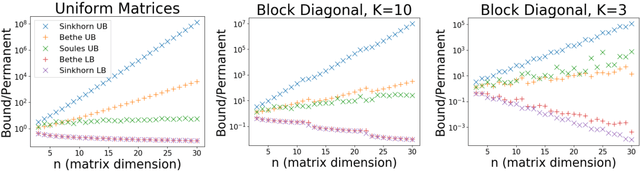
Computing the permanent of a non-negative matrix is a core problem with practical applications ranging from target tracking to statistical thermodynamics. However, this problem is also #P-complete, which leaves little hope for finding an exact solution that can be computed efficiently. While the problem admits a fully polynomial randomized approximation scheme, this method has seen little use because it is both inefficient in practice and difficult to implement. We present AdaPart, a simple and efficient method for drawing exact samples from an unnormalized distribution. Using AdaPart, we show how to construct tight bounds on the permanent which hold with high probability, with guaranteed polynomial runtime for dense matrices. We find that AdaPart can provide empirical speedups exceeding 25x over prior sampling methods on matrices that are challenging for variational based approaches. Finally, in the context of multi-target tracking, exact sampling from the distribution defined by the matrix permanent allows us to use the optimal proposal distribution during particle filtering. Using AdaPart, we show that this leads to improved tracking performance using an order of magnitude fewer samples.
Not All Claims are Created Equal: Choosing the Right Approach to Assess Your Hypotheses
Nov 10, 2019
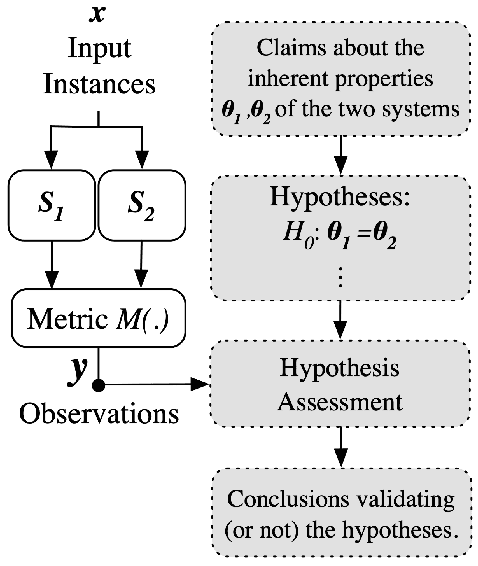
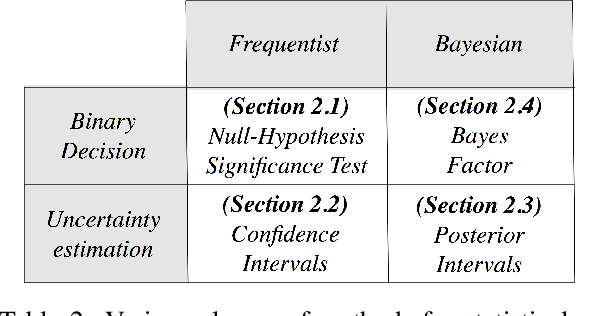
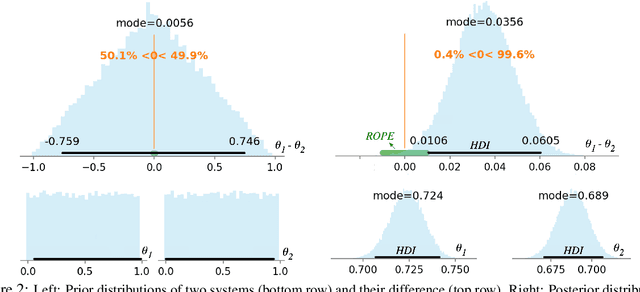
Empirical research in Natural Language Processing (NLP) has adopted a narrow set of principles for assessing hypotheses, relying mainly on p-value computation, which suffers from several known issues. While alternative proposals have been well-debated and adopted in other fields, they remain rarely discussed or used within the NLP community. We address this gap by contrasting various hypothesis assessment techniques, especially those not commonly used in the field (such as evaluations based on Bayesian inference). Since these statistical techniques differ in the hypotheses they can support, we argue that practitioners should first decide their target hypothesis before choosing an assessment method. This is crucial because common fallacies, misconceptions, and misinterpretation surrounding hypothesis assessment methods often stem from a discrepancy between what one would like to claim versus what the method used actually assesses. Our survey reveals that these issues are omnipresent in the NLP research community. As a step forward, we provide best practices and guidelines tailored to NLP research, as well as an easy-to-use package called 'HyBayes' for Bayesian assessment of hypotheses, complementing existing tools.