 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMA: Rapid Motor Adaptation for Legged Robots
Jul 08, 2021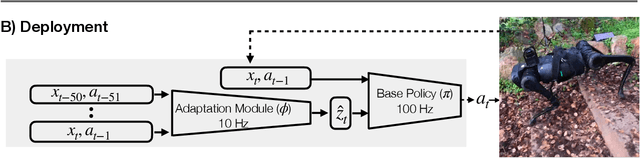
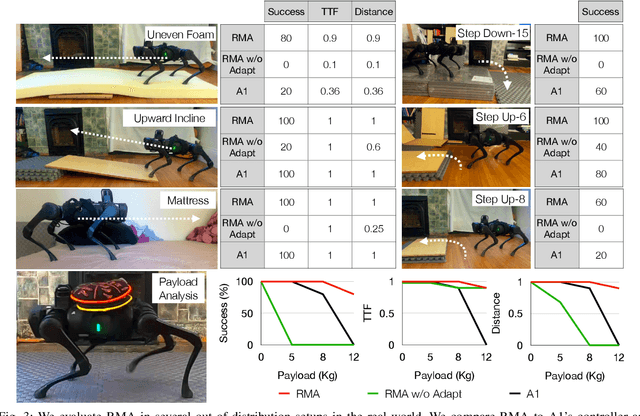
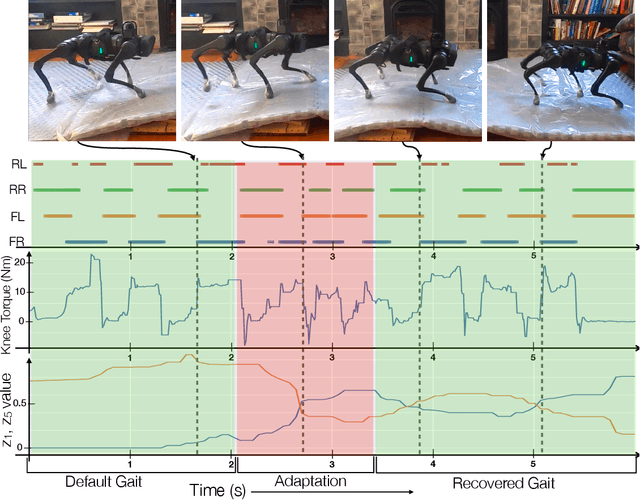
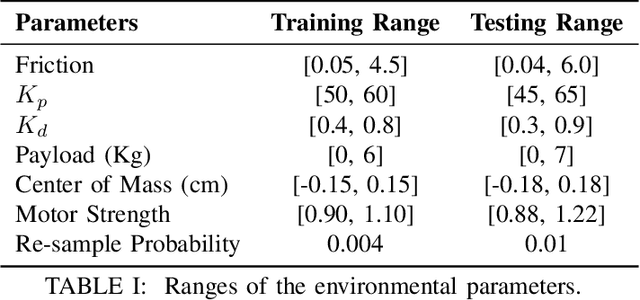
Successful real-world deployment of legged robots would require them to adapt in real-time to unseen scenarios like changing terrains, changing payloads, wear and tear. This paper presents Rapid Motor Adaptation (RMA) algorithm to solve this problem of real-time online adaptation in quadruped robots. RMA consists of two components: a base policy and an adaptation module. The combination of these components enables the robot to adapt to novel situations in fractions of a second. RMA is trained completely in simulation without using any domain knowledge like reference trajectories or predefined foot trajectory generators and is deployed on the A1 robot without any fine-tuning. We train RMA on a varied terrain generator using bioenergetics-inspired rewards and deploy it on a variety of difficult terrains including rocky, slippery, deformable surfaces in environments with grass, long vegetation, concrete, pebbles, stairs, sand, etc. RMA shows state-of-the-art performance across diverse real-world as well as simulation experiments. Video results at https://ashish-kmr.github.io/rma-legged-robots/
Deep Learning Body Region Classification of MRI and CT examinations
Apr 28, 2021
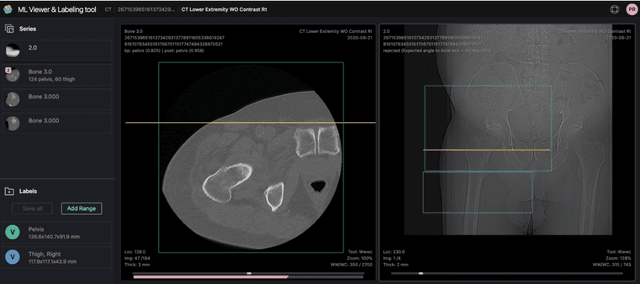
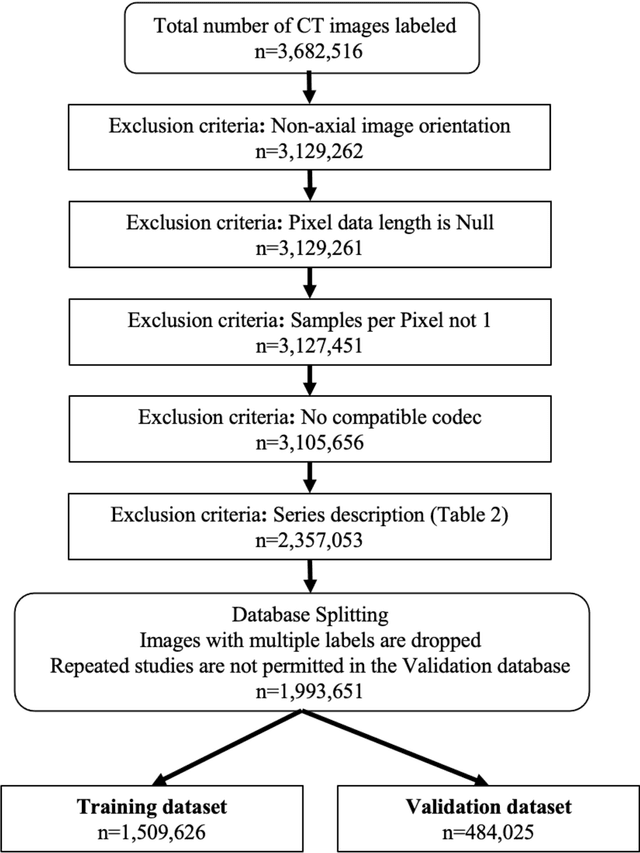

Standardized body region labelling of individual images provides data that can improve human and computer use of medical images. A CNN-based classifier was developed to identify body regions in CT and MRI. 17 CT (18 MRI) body regions covering the entire human body were defined for the classification task. Three retrospective databases were built for the AI model training, validation, and testing, with a balanced distribution of studies per body region. The test databases originated from a different healthcare network. Accuracy, recall and precision of the classifier was evaluated for patient age, patient gender, institution, scanner manufacturer, contrast, slice thickness, MRI sequence, and CT kernel. The data included a retrospective cohort of 2,934 anonymized CT cases (training: 1,804 studies, validation: 602 studies, test: 528 studies) and 3,185 anonymized MRI cases (training: 1,911 studies, validation: 636 studies, test: 638 studies). 27 institutions from primary care hospitals, community hospitals and imaging centers contributed to the test datasets. The data included cases of all genders in equal proportions and subjects aged from a few months old to +90 years old. An image-level prediction accuracy of 91.9% (90.2 - 92.1) for CT, and 94.2% (92.0 - 95.6) for MRI was achieved. The classification results were robust across all body regions and confounding factors. Due to limited data, performance results for subjects under 10 years-old could not be reliably evaluated. We show that deep learning models can classify CT and MRI images by body region including lower and upper extremities with high accuracy.
Towards Deep Learning Assisted Autonomous UAVs for Manipulation Tasks in GPS-Denied Environments
Jan 16, 2021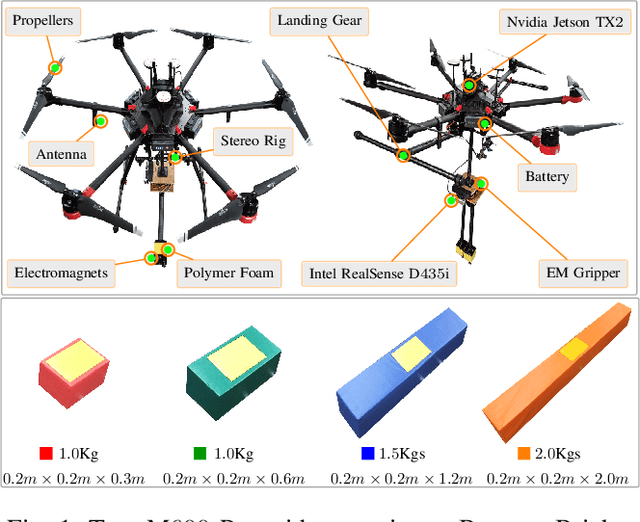

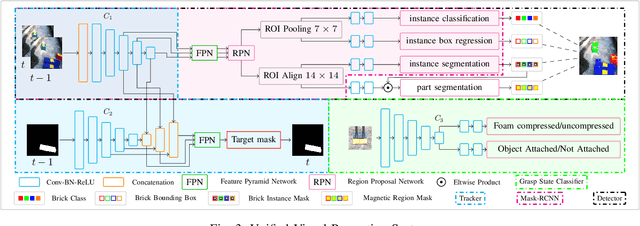
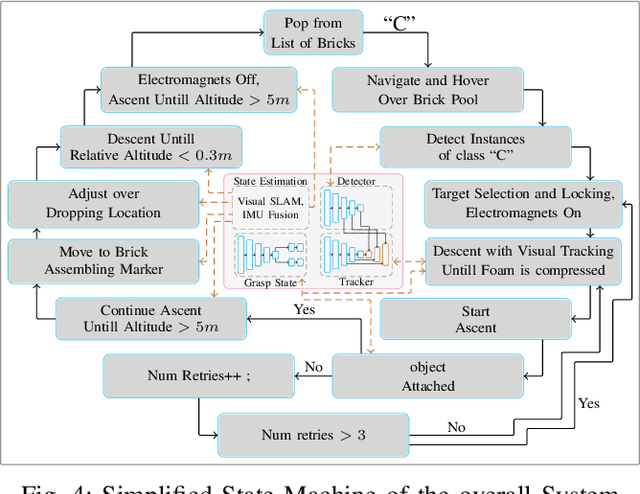
In this work, we present a pragmatic approach to enable unmanned aerial vehicle (UAVs) to autonomously perform highly complicated tasks of object pick and place. This paper is largely inspired by challenge-2 of MBZIRC 2020 and is primarily focused on the task of assembling large 3D structures in outdoors and GPS-denied environments. Primary contributions of this system are: (i) a novel computationally efficient deep learning based unified multi-task visual perception system for target localization, part segmentation, and tracking, (ii) a novel deep learning based grasp state estimation, (iii) a retracting electromagnetic gripper design, (iv) a remote computing approach which exploits state-of-the-art MIMO based high speed (5000Mb/s) wireless links to allow the UAVs to execute compute intensive tasks on remote high end compute servers, and (v) system integration in which several system components are weaved together in order to develop an optimized software stack. We use DJI Matrice-600 Pro, a hex-rotor UAV and interface it with the custom designed gripper. Our framework is deployed on the specified UAV in order to report the performance analysis of the individual modules. Apart from the manipulation system, we also highlight several hidden challenges associated with the UAVs in this context.
DeepMI: A Mutual Information Based Framework For Unsupervised Deep Learning of Tasks
Jan 16, 2021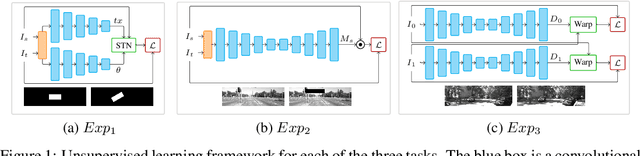
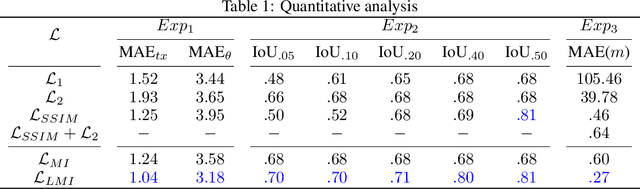
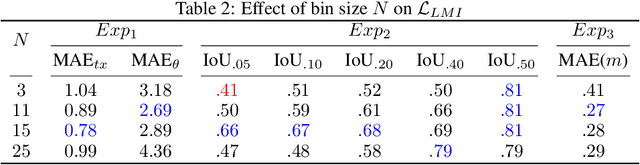
In this work, we propose an information theory based framework DeepMI to train deep neural networks (DNN) using Mutual Information (MI). The DeepMI framework is especially targeted but not limited to the learning of real world tasks in an unsupervised manner. The primary motivation behind this work is the insufficiency of traditional loss functions for unsupervised task learning. Moreover, directly using MI for the training purpose is quite challenging to deal because of its unbounded above nature. Hence, we develop an alternative linearized representation of MI as a part of the framework. Contributions of this paper are three fold: i) investigation of MI to train deep neural networks, ii) novel loss function LLMI, and iii) a fuzzy logic based end-to-end differentiable pipeline to integrate DeepMI into deep learning framework. We choose a few unsupervised learning tasks for our experimental study. We demonstrate that L LM I alone provides better gradients to achieve a neural network better performance over the cases when multiple loss functions are used for a given task.
Shape Back-Projection In 3D Scenes
Jan 16, 2021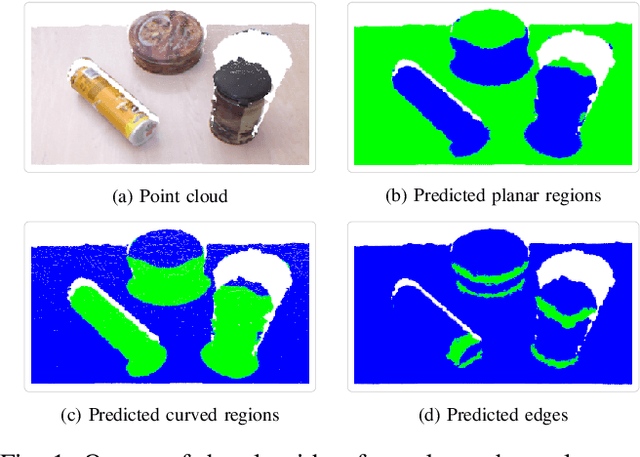
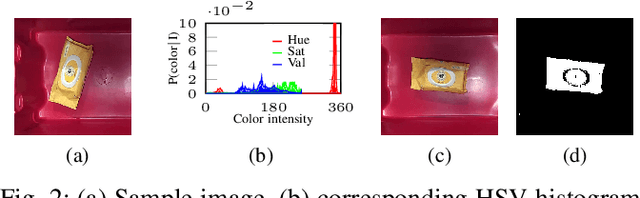
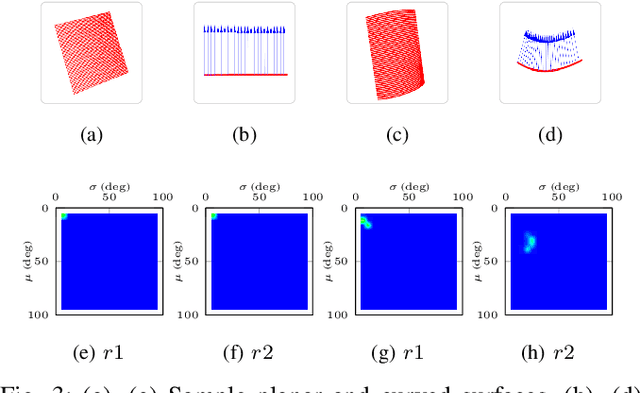
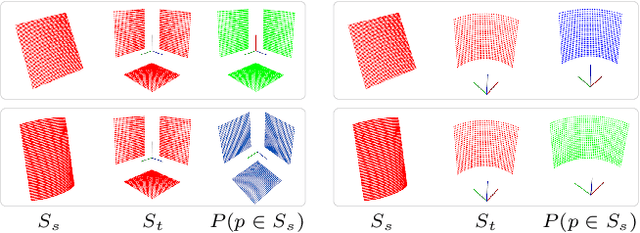
In this work, we propose a novel framework shape back-projection for computationally efficient point cloud processing in a probabilistic manner. The primary component of the technique is shape histogram and a back-projection procedure. The technique measures similarity between 3D surfaces, by analyzing their geometrical properties. It is analogous to color back-projection which measures similarity between images, simply by looking at their color distributions. In the overall process, first, shape histogram of a sample surface (e.g. planar) is computed, which captures the profile of surface normals around a point in form of a probability distribution. Later, the histogram is back-projected onto a test surface and a likelihood score is obtained. The score depicts that how likely a point in the test surface behaves similar to the sample surface, geometrically. Shape back-projection finds its application in binary surface classification, high curvature edge detection in unorganized point cloud, automated point cloud labeling for 3D-CNNs (convolutional neural network) etc. The algorithm can also be used for real-time robotic operations such as autonomous object picking in warehouse automation, ground plane extraction for autonomous vehicles and can be deployed easily on computationally limited platforms (UAVs).
Semi Supervised Deep Quick Instance Detection and Segmentation
Jan 16, 2021
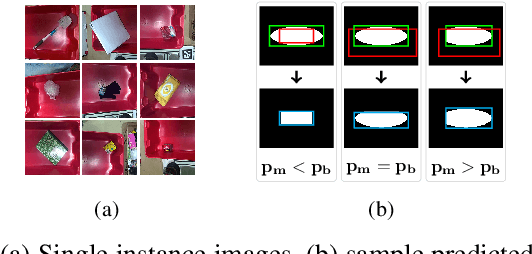


In this paper, we present a semi supervised deep quick learning framework for instance detection and pixel-wise semantic segmentation of images in a dense clutter of items. The framework can quickly and incrementally learn novel items in an online manner by real-time data acquisition and generating corresponding ground truths on its own. To learn various combinations of items, it can synthesize cluttered scenes, in real time. The overall approach is based on the tutor-child analogy in which a deep network (tutor) is pretrained for class-agnostic object detection which generates labeled data for another deep network (child). The child utilizes a customized convolutional neural network head for the purpose of quick learning. There are broadly four key components of the proposed framework semi supervised labeling, occlusion aware clutter synthesis, a customized convolutional neural network head, and instance detection. The initial version of this framework was implemented during our participation in Amazon Robotics Challenge (ARC), 2017. Our system was ranked 3rd, 4th and 5th worldwide in pick, stow-pick and stow task respectively. The proposed framework is an improved version over ARC17 where novel features such as instance detection and online learning has been added.
Real Time Incremental Foveal Texture Mapping for Autonomous Vehicles
Jan 16, 2021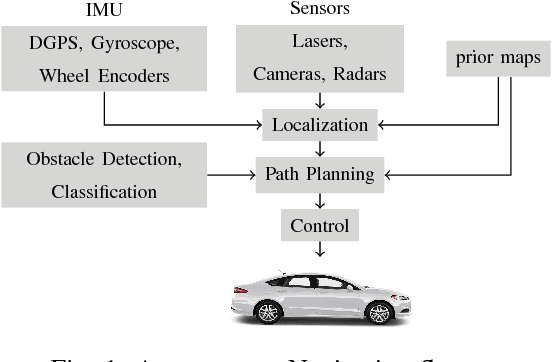
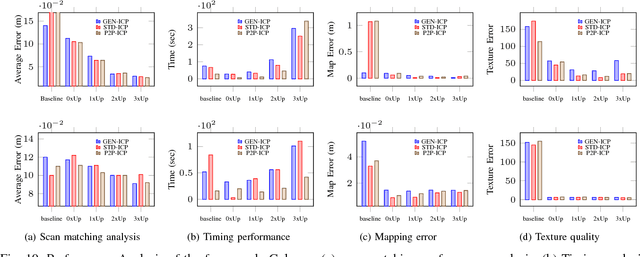
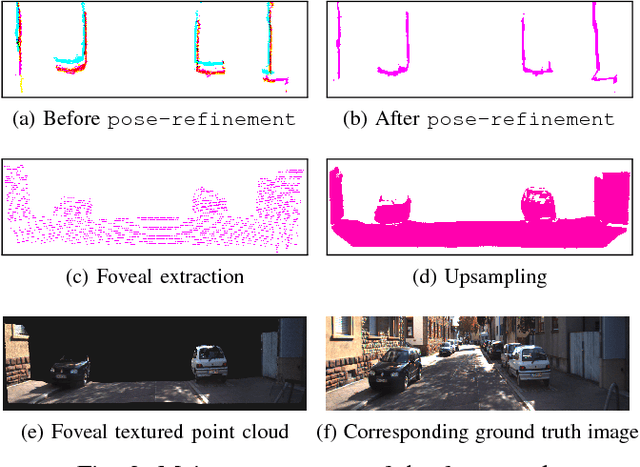
We propose an end-to-end real time framework to generate high resolution graphics grade textured 3D map of urban environment. The generated detailed map finds its application in the precise localization and navigation of autonomous vehicles. It can also serve as a virtual test bed for various vision and planning algorithms as well as a background map in the computer games. In this paper, we focus on two important issues: (i) incrementally generating a map with coherent 3D surface, in real time and (ii) preserving the quality of color texture. To handle the above issues, firstly, we perform a pose-refinement procedure which leverages camera image information, Delaunay triangulation and existing scan matching techniques to produce high resolution 3D map from the sparse input LIDAR scan. This 3D map is then texturized and accumulated by using a novel technique of ray-filtering which handles occlusion and inconsistencies in pose-refinement. Further, inspired by human fovea, we introduce foveal-processing which significantly reduces the computation time and also assists ray-filtering to maintain consistency in color texture and coherency in 3D surface of the output map. Moreover, we also introduce texture error (TE) and mean texture mapping error (MTME), which provides quantitative measure of texturing and overall quality of the textured maps.
MACE: Model Agnostic Concept Extractor for Explaining Image Classification Networks
Nov 03, 2020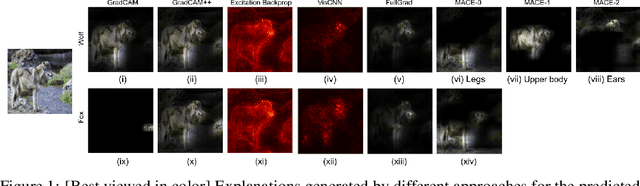
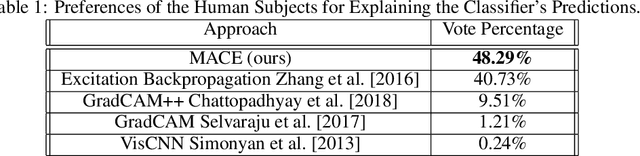

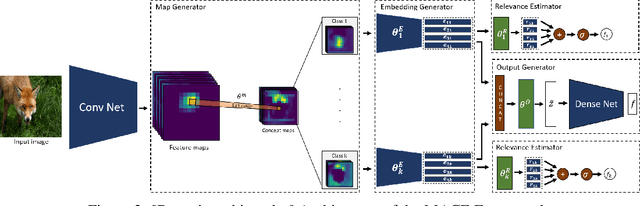
Deep convolutional networks have been quite successful at various image classification tasks. The current methods to explain the predictions of a pre-trained model rely on gradient information, often resulting in saliency maps that focus on the foreground object as a whole. However, humans typically reason by dissecting an image and pointing out the presence of smaller concepts. The final output is often an aggregation of the presence or absence of these smaller concepts. In this work, we propose MACE: a Model Agnostic Concept Extractor, which can explain the working of a convolutional network through smaller concepts. The MACE framework dissects the feature maps generated by a convolution network for an image to extract concept based prototypical explanations. Further, it estimates the relevance of the extracted concepts to the pre-trained model's predictions, a critical aspect required for explaining the individual class predictions, missing in existing approaches. We validate our framework using VGG16 and ResNet50 CNN architectures, and on datasets like Animals With Attributes 2 (AWA2) and Places365. Our experiments demonstrate that the concepts extracted by the MACE framework increase the human interpretability of the explanations, and are faithful to the underlying pre-trained black-box model.
Domain Independent Unsupervised Learning to grasp the Novel Objects
Jan 09, 2020
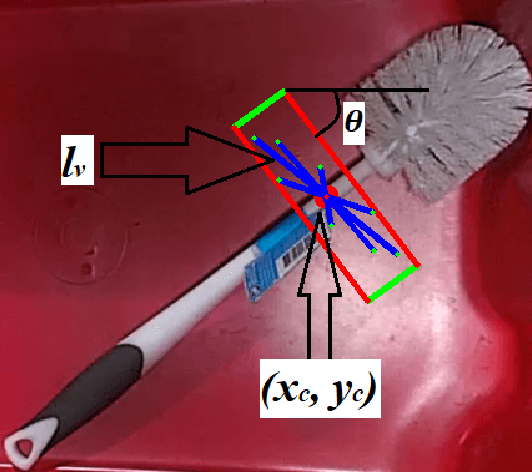
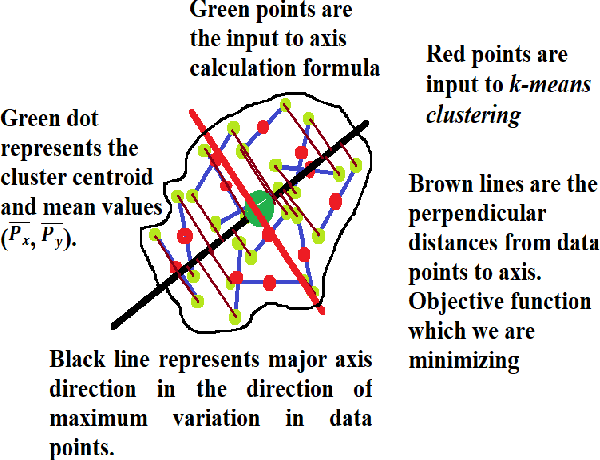
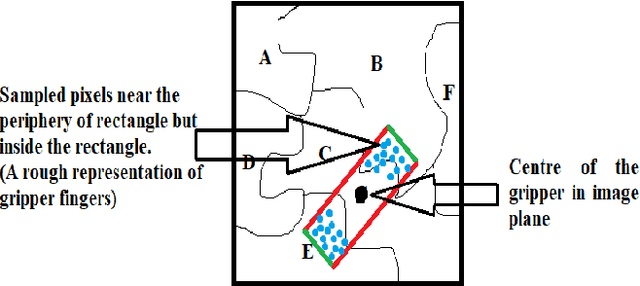
One of the main challenges in the vision-based grasping is the selection of feasible grasp regions while interacting with novel objects. Recent approaches exploit the power of the convolutional neural network (CNN) to achieve accurate grasping at the cost of high computational power and time. In this paper, we present a novel unsupervised learning based algorithm for the selection of feasible grasp regions. Unsupervised learning infers the pattern in data-set without any external labels. We apply k-means clustering on the image plane to identify the grasp regions, followed by an axis assignment method. We define a novel concept of Grasp Decide Index (GDI) to select the best grasp pose in image plane. We have conducted several experiments in clutter or isolated environment on standard objects of Amazon Robotics Challenge 2017 and Amazon Picking Challenge 2016. We compare the results with prior learning based approaches to validate the robustness and adaptive nature of our algorithm for a variety of novel objects in different domains.
OffWorld Gym: open-access physical robotics environment for real-world reinforcement learning benchmark and research
Oct 18, 2019
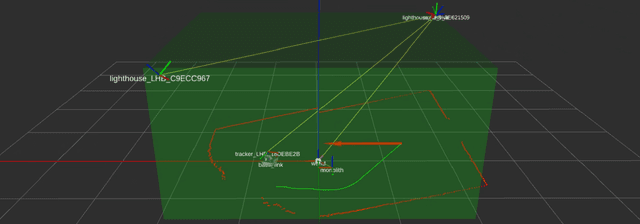
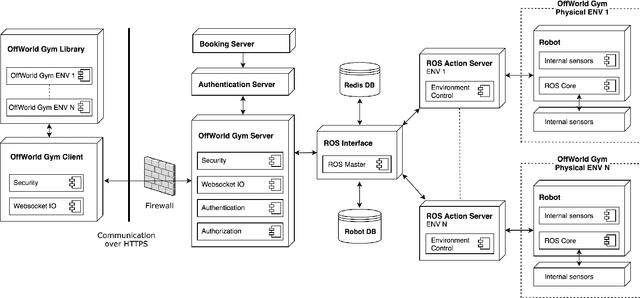
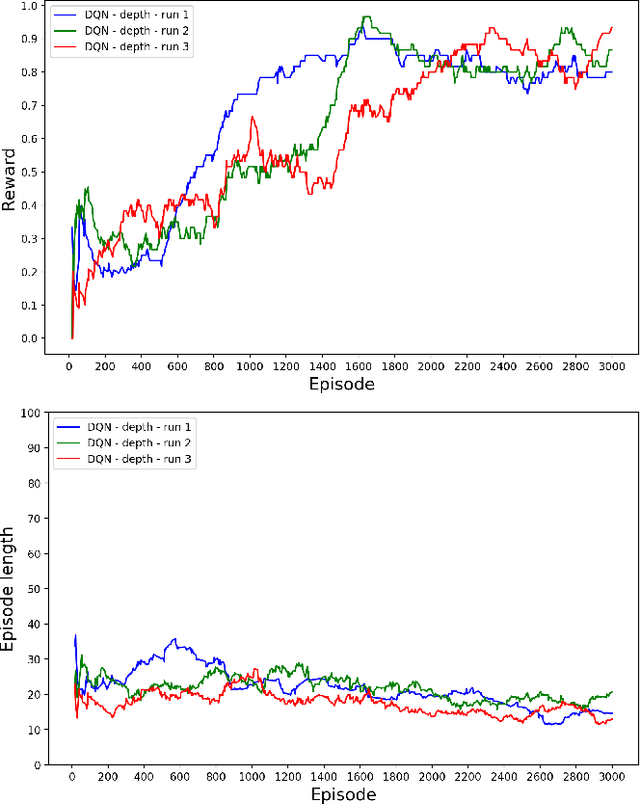
Success stories of applied machine learning can be traced back to the datasets and environments that were put forward as challenges for the community. The challenge that the community sets as a benchmark is usually the challenge that the community eventually solves. The ultimate challenge of reinforcement learning research is to train real agents to operate in the real environment, but until now there has not been a common real-world RL benchmark. In this work, we present a prototype real-world environment from OffWorld Gym -- a collection of real-world environments for reinforcement learning in robotics with free public remote access. Close integration into existing ecosystem allows the community to start using OffWorld Gym without any prior experience in robotics and takes away the burden of managing a physical robotics system, abstracting it under a familiar API. We introduce a navigation task, where a robot has to reach a visual beacon on an uneven terrain using only the camera input and provide baseline results in both the real environment and the simulated replica. To start training, visit https://gym.offworld.ai.