 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Biometrics in the Age of Deep Learning
Aug 19, 2022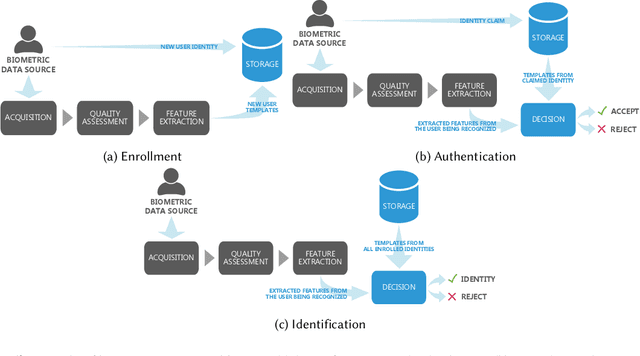
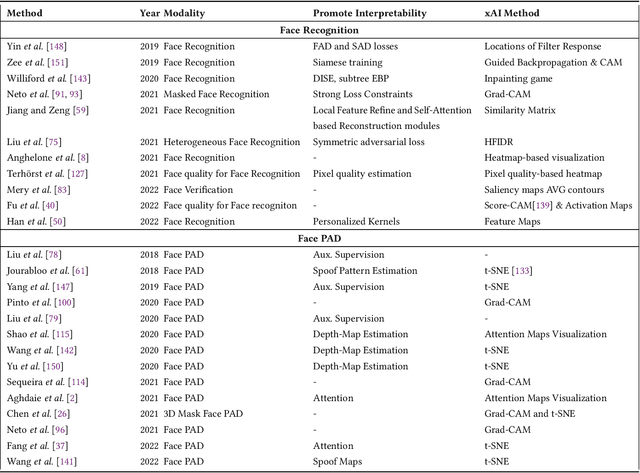
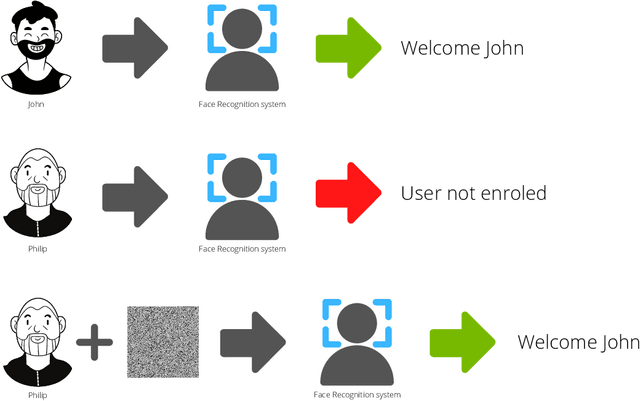
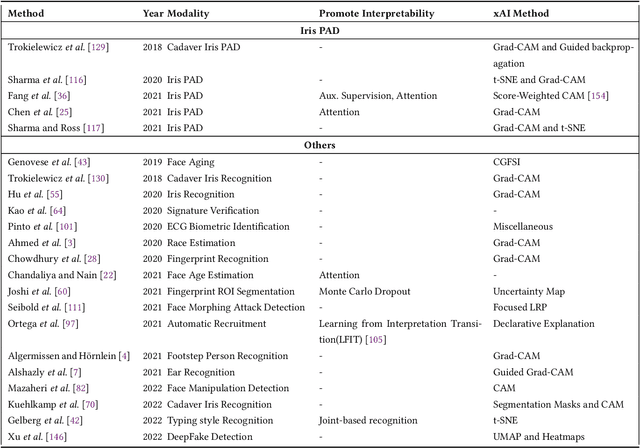
Systems capable of analyzing and quantifying human physical or behavioral traits, known as biometrics systems, are growing in use and application variability. Since its evolution from handcrafted features and traditional machine learning to deep learning and automatic feature extraction, the performance of biometric systems increased to outstanding values. Nonetheless, the cost of this fast progression is still not understood. Due to its opacity, deep neural networks are difficult to understand and analyze, hence, hidden capacities or decisions motivated by the wrong motives are a potential risk. Researchers have started to pivot their focus towards the understanding of deep neural networks and the explanation of their predictions. In this paper, we provide a review of the current state of explainable biometrics based on the study of 47 papers and discuss comprehensively the direction in which this field should be developed.
HEFT: Homomorphically Encrypted Fusion of Biometric Templates
Aug 15, 2022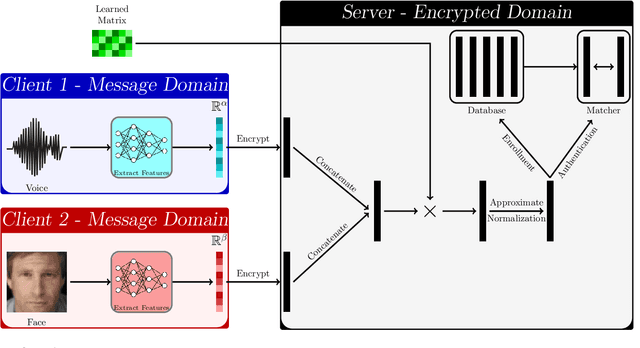

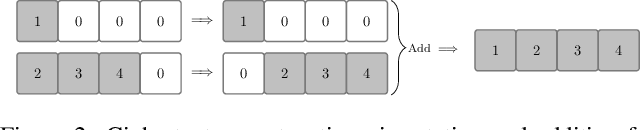
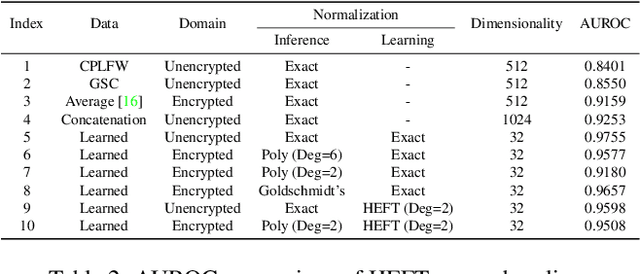
This paper proposes a non-interactive end-to-end solution for secure fusion and matching of biometric templates using fully homomorphic encryption (FHE). Given a pair of encrypted feature vectors, we perform the following ciphertext operations, i) feature concatenation, ii) fusion and dimensionality reduction through a learned linear projection, iii) scale normalization to unit $\ell_2$-norm, and iv) match score computation. Our method, dubbed HEFT (Homomorphically Encrypted Fusion of biometric Templates), is custom-designed to overcome the unique constraint imposed by FHE, namely the lack of support for non-arithmetic operations. From an inference perspective, we systematically explore different data packing schemes for computationally efficient linear projection and introduce a polynomial approximation for scale normalization. From a training perspective, we introduce an FHE-aware algorithm for learning the linear projection matrix to mitigate errors induced by approximate normalization. Experimental evaluation for template fusion and matching of face and voice biometrics shows that HEFT (i) improves biometric verification performance by 11.07% and 9.58% AUROC compared to the respective unibiometric representations while compressing the feature vectors by a factor of 16 (512D to 32D), and (ii) fuses a pair of encrypted feature vectors and computes its match score against a gallery of size 1024 in 884 ms. Code and data are available at https://github.com/human-analysis/encrypted-biometric-fusion
Periocular Biometrics and its Relevance to Partially Masked Faces: A Survey
Mar 29, 2022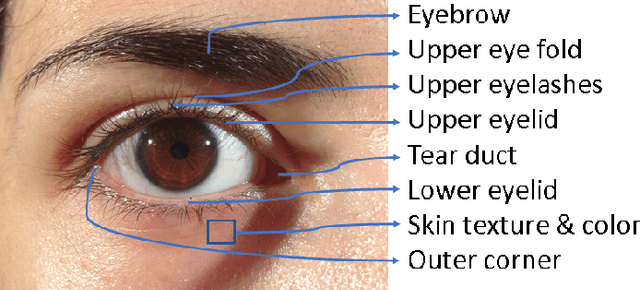
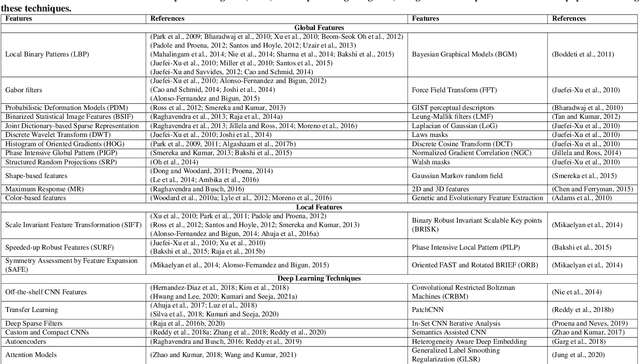

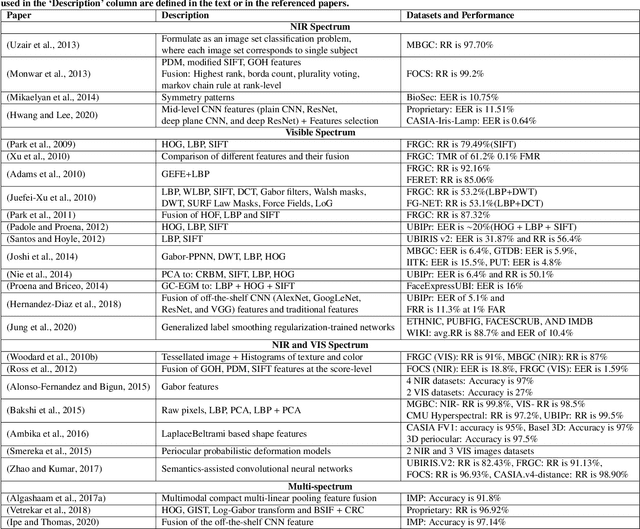
The performance of face recognition systems can be negatively impacted in the presence of masks and other types of facial coverings that have become prevalent due to the COVID-19 pandemic. In such cases, the periocular region of the human face becomes an important biometric cue. In this article, we present a detailed review of periocular biometrics. We first examine the various face and periocular techniques specially designed to recognize humans wearing a face mask. Then, we review different aspects of periocular biometrics: (a) the anatomical cues present in the periocular region useful for recognition, (b) the various feature extraction and matching techniques developed, (c) recognition across different spectra, (d) fusion with other biometric modalities (face or iris), (e) recognition on mobile devices, (f) its usefulness in other applications, (g) periocular datasets, and (h) competitions organized for evaluating the efficacy of this biometric modality. Finally, we discuss various challenges and future directions in the field of periocular biometrics.
Trust in AI and Its Role in the Acceptance of AI Technologies
Mar 23, 2022
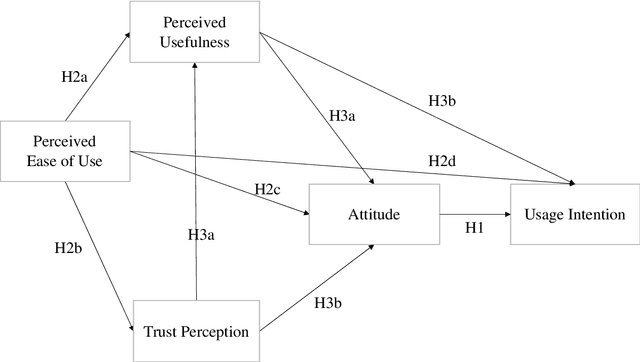
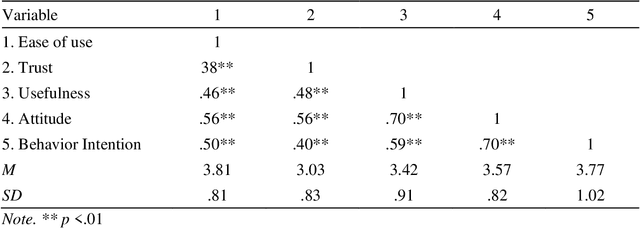
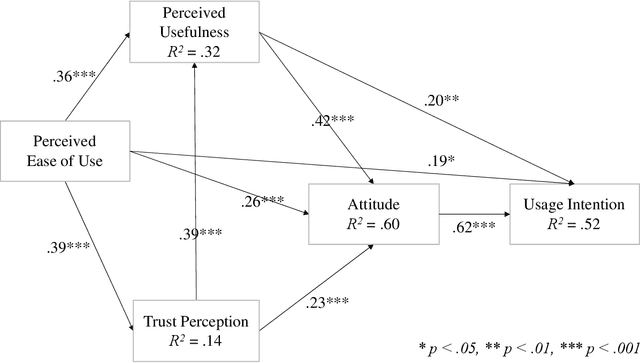
As AI-enhanced technologies become common in a variety of domains, there is an increasing need to define and examine the trust that users have in such technologies. Given the progress in the development of AI, a correspondingly sophisticated understanding of trust in the technology is required. This paper addresses this need by explaining the role of trust on the intention to use AI technologies. Study 1 examined the role of trust in the use of AI voice assistants based on survey responses from college students. A path analysis confirmed that trust had a significant effect on the intention to use AI, which operated through perceived usefulness and participants' attitude toward voice assistants. In study 2, using data from a representative sample of the U.S. population, different dimensions of trust were examined using exploratory factor analysis, which yielded two dimensions: human-like trust and functionality trust. The results of the path analyses from Study 1 were replicated in Study 2, confirming the indirect effect of trust and the effects of perceived usefulness, ease of use, and attitude on intention to use. Further, both dimensions of trust shared a similar pattern of effects within the model, with functionality-related trust exhibiting a greater total impact on usage intention than human-like trust. Overall, the role of trust in the acceptance of AI technologies was significant across both studies. This research contributes to the advancement and application of the TAM in AI-related applications and offers a multidimensional measure of trust that can be utilized in the future study of trustworthy AI.
The State of Aerial Surveillance: A Survey
Jan 13, 2022
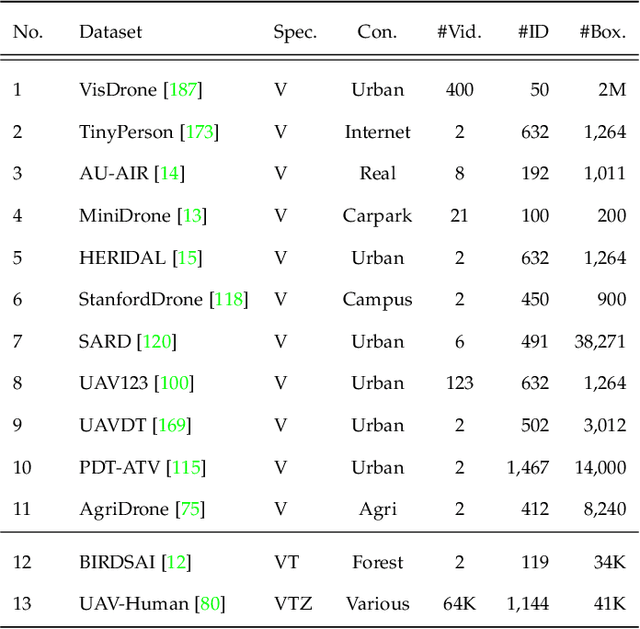
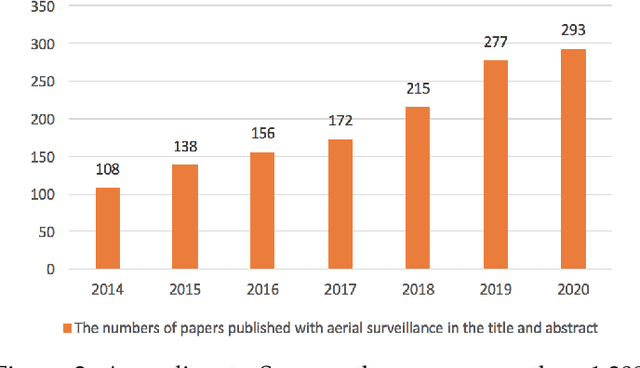
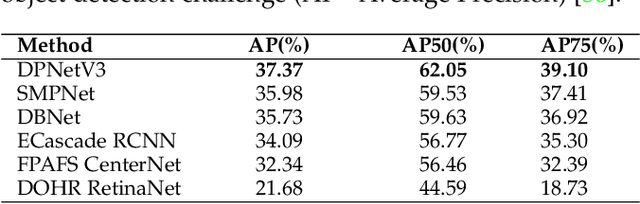
The rapid emergence of airborne platforms and imaging sensors are enabling new forms of aerial surveillance due to their unprecedented advantages in scale, mobility, deployment and covert observation capabilities. This paper provides a comprehensive overview of human-centric aerial surveillance tasks from a computer vision and pattern recognition perspective. It aims to provide readers with an in-depth systematic review and technical analysis of the current state of aerial surveillance tasks using drones, UAVs and other airborne platforms. The main object of interest is humans, where single or multiple subjects are to be detected, identified, tracked, re-identified and have their behavior analyzed. More specifically, for each of these four tasks, we first discuss unique challenges in performing these tasks in an aerial setting compared to a ground-based setting. We then review and analyze the aerial datasets publicly available for each task, and delve deep into the approaches in the aerial literature and investigate how they presently address the aerial challenges. We conclude the paper with discussion on the missing gaps and open research questions to inform future research avenues.
Beyond the Visible: A Survey on Cross-spectral Face Recognition
Jan 12, 2022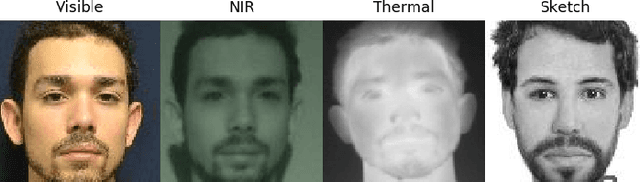
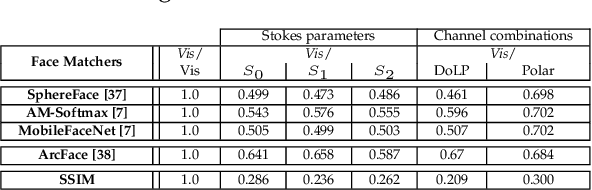
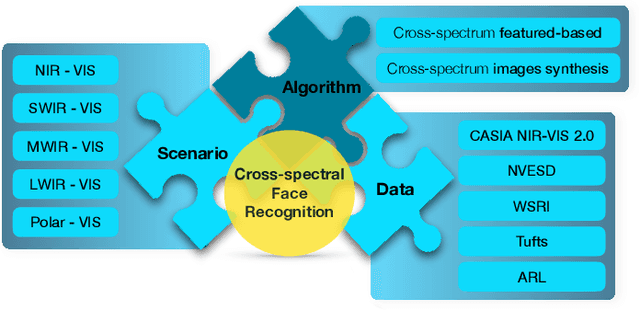
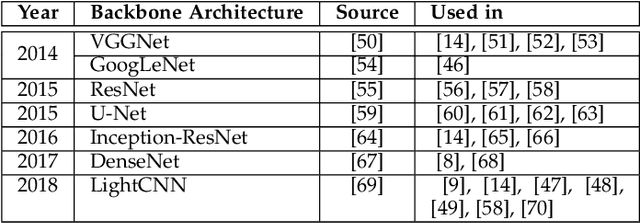
Cross-spectral face recognition (CFR) is aimed at recognizing individuals, where compared face images stem from different sensing modalities, for example infrared vs. visible. While CFR is inherently more challenging than classical face recognition due to significant variation in facial appearance associated to a modality gap, it is superior in scenarios with limited or challenging illumination, as well as in the presence of presentation attacks. Recent advances in artificial intelligence related to convolutional neural networks (CNNs) have brought to the fore a significant performance improvement in CFR. Motivated by this, the contributions of this survey are three-fold. We provide an overview of CFR, targeted to compare face images captured in different spectra, by firstly formalizing CFR and then presenting concrete related applications. Secondly, we explore suitable spectral bands for recognition and discuss recent CFR-methods, placing emphasis on deep neural networks. In particular we revisit techniques that have been proposed to extract and compare heterogeneous features, as well as datasets. We enumerate strengths and limitations of different spectra and associated algorithms. Finally, we discuss research challenges and future lines of research.
Conditional Identity Disentanglement for Differential Face Morph Detection
Jul 05, 2021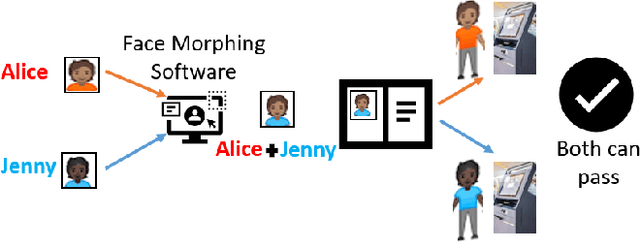
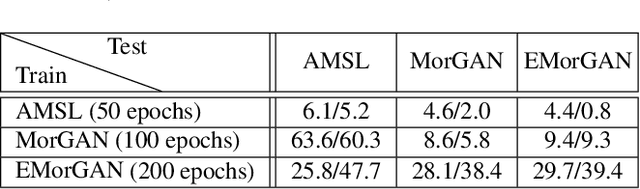

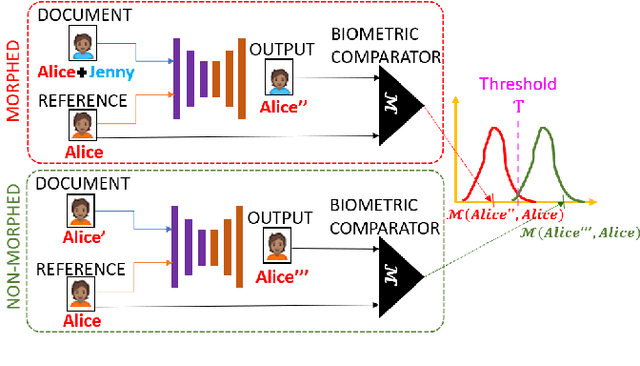
We present the task of differential face morph attack detection using a conditional generative network (cGAN). To determine whether a face image in an identification document, such as a passport, is morphed or not, we propose an algorithm that learns to implicitly disentangle identities from the morphed image conditioned on the trusted reference image using the cGAN. Furthermore, the proposed method can also recover some underlying information about the second subject used in generating the morph. We performed experiments on AMSL face morph, MorGAN, and EMorGAN datasets to demonstrate the effectiveness of the proposed method. We also conducted cross-dataset and cross-attack detection experiments. We obtained promising results of 3% BPCER @ 10% APCER on intra-dataset evaluation, which is comparable to existing methods; and 4.6% BPCER @ 10% APCER on cross-dataset evaluation, which outperforms state-of-the-art methods by at least 13.9%.
Fingerprint Presentation Attack Detection utilizing Time-Series, Color Fingerprint Captures
Apr 08, 2021
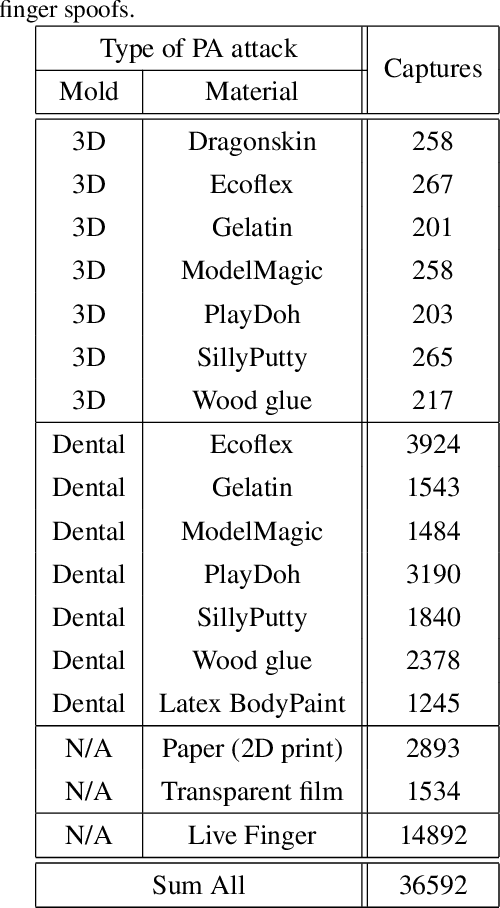

Fingerprint capture systems can be fooled by widely accessible methods to spoof the system using fake fingers, known as presentation attacks. As biometric recognition systems become more extensively relied upon at international borders and in consumer electronics, presentation attacks are becoming an increasingly serious issue. A robust solution is needed that can handle the increased variability and complexity of spoofing techniques. This paper demonstrates the viability of utilizing a sensor with time-series and color-sensing capabilities to improve the robustness of a traditional fingerprint sensor and introduces a comprehensive fingerprint dataset with over 36,000 image sequences and a state-of-the-art set of spoofing techniques. The specific sensor used in this research captures a traditional gray-scale static capture and a time-series color capture simultaneously. Two different methods for Presentation Attack Detection (PAD) are used to assess the benefit of a color dynamic capture. The first algorithm utilizes Static-Temporal Feature Engineering on the fingerprint capture to generate a classification decision. The second generates its classification decision using features extracted by way of the Inception V3 CNN trained on ImageNet. Classification performance is evaluated using features extracted exclusively from the static capture, exclusively from the dynamic capture, and on a fusion of the two feature sets. With both PAD approaches we find that the fusion of the dynamic and static feature-set is shown to improve performance to a level not individually achievable.
* 8 pages, 3 figures, ICB-2019
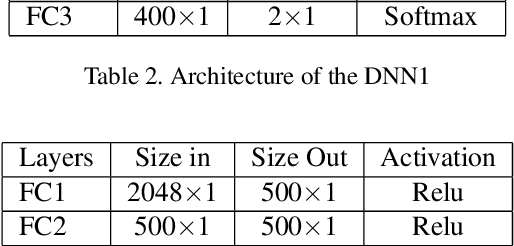
One-shot Representational Learning for Joint Biometric and Device Authentication
Jan 02, 2021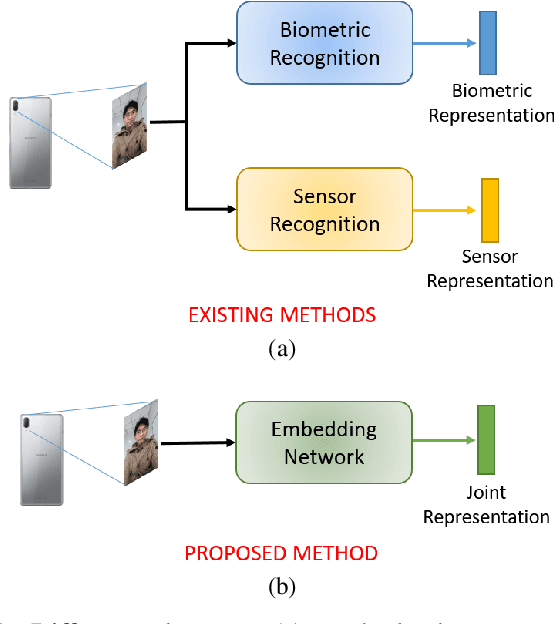
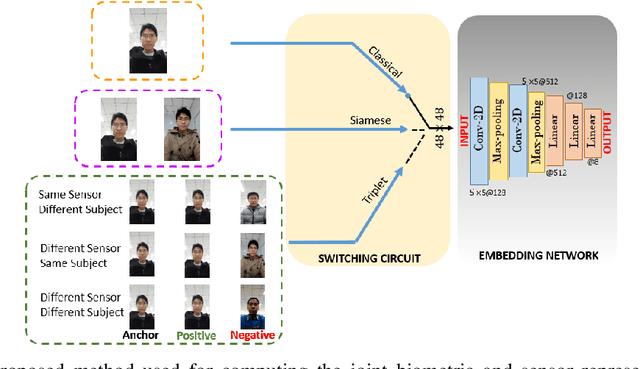
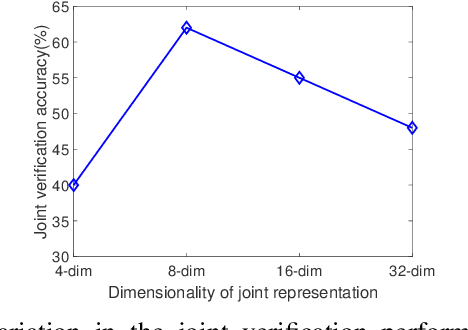
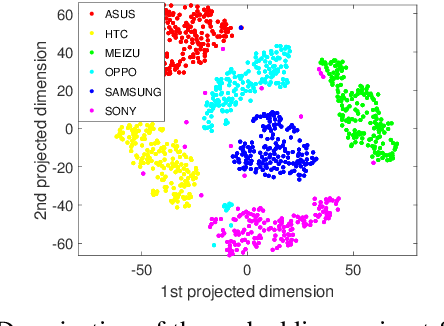
In this work, we propose a method to simultaneously perform (i) biometric recognition (i.e., identify the individual), and (ii) device recognition, (i.e., identify the device) from a single biometric image, say, a face image, using a one-shot schema. Such a joint recognition scheme can be useful in devices such as smartphones for enhancing security as well as privacy. We propose to automatically learn a joint representation that encapsulates both biometric-specific and sensor-specific features. We evaluate the proposed approach using iris, face and periocular images acquired using near-infrared iris sensors and smartphone cameras. Experiments conducted using 14,451 images from 15 sensors resulted in a rank-1 identification accuracy of upto 99.81% and a verification accuracy of upto 100% at a false match rate of 1%.
DeepTalk: Vocal Style Encoding for Speaker Recognition and Speech Synthesis
Dec 09, 2020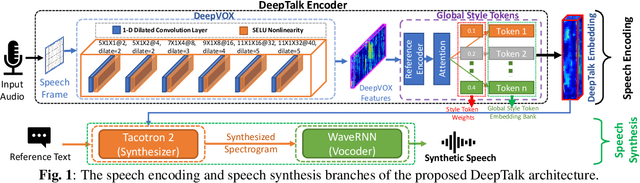
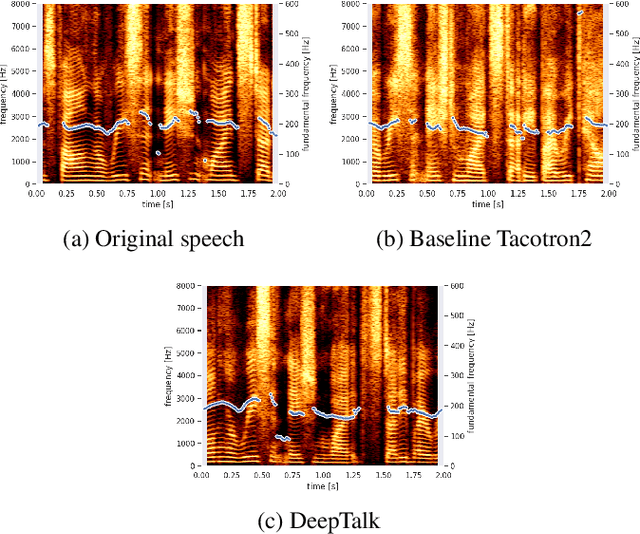
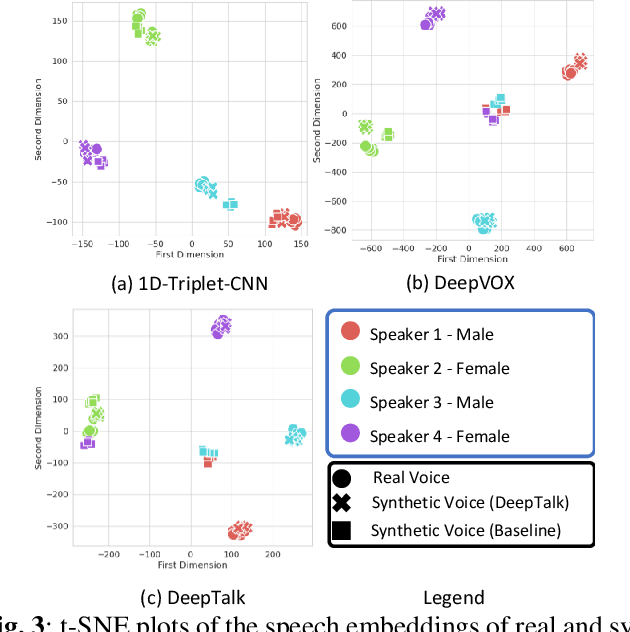
Automatic speaker recognition algorithms typically use physiological speech characteristics encoded in the short term spectral features for characterizing speech audio. Such algorithms do not capitalize on the complementary and discriminative speaker-dependent characteristics present in the behavioral speech features. In this work, we propose a prosody encoding network called DeepTalk for extracting vocal style features directly from raw audio data. The DeepTalk method outperforms several state-of-the-art physiological speech characteristics-based speaker recognition systems across multiple challenging datasets. The speaker recognition performance is further improved by combining DeepTalk with a state-of-the-art physiological speech feature-based speaker recognition system. We also integrate the DeepTalk method into a current state-of-the-art speech synthesizer to generate synthetic speech. A detailed analysis of the synthetic speech shows that the DeepTalk captures F0 contours essential for vocal style modeling. Furthermore, DeepTalk-based synthetic speech is shown to be almost indistinguishable from real speech in the context of speaker recognition.