 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-To-End Memory Networks
Nov 24, 2015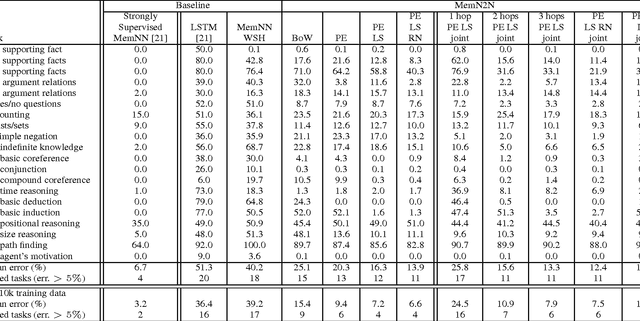
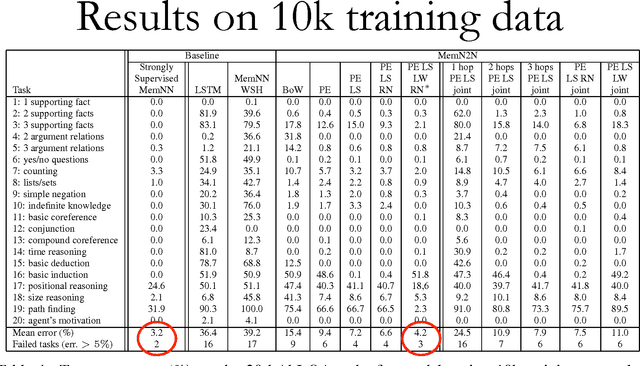
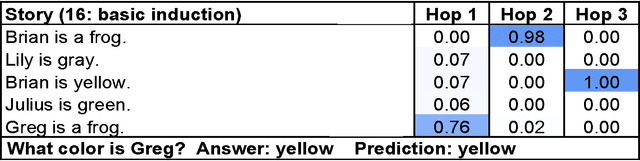
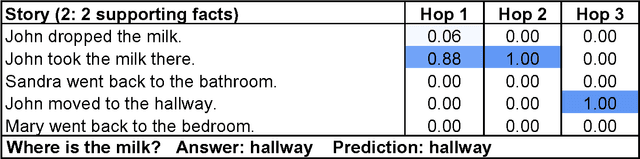
We introduce a neural network with a recurrent attention model over a possibly large external memory. The architecture is a form of Memory Network (Weston et al., 2015) but unlike the model in that work, it is trained end-to-end, and hence requires significantly less supervision during training, making it more generally applicable in realistic settings. It can also be seen as an extension of RNNsearch to the case where multiple computational steps (hops) are performed per output symbol. The flexibility of the model allows us to apply it to tasks as diverse as (synthetic) question answering and to language modeling. For the former our approach is competitive with Memory Networks, but with less supervision. For the latter, on the Penn TreeBank and Text8 datasets our approach demonstrates comparable performance to RNNs and LSTMs. In both cases we show that the key concept of multiple computational hops yields improved results.
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Jun 18, 2015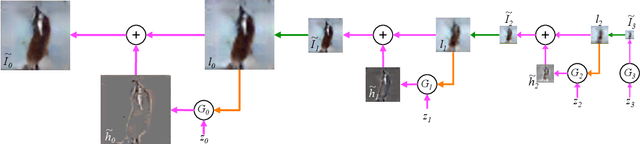
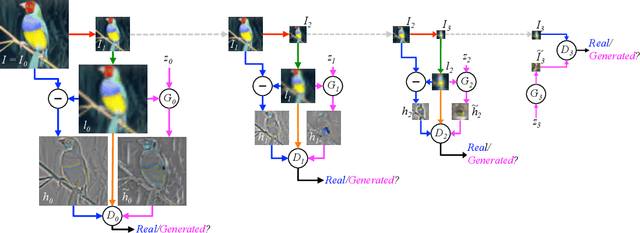


In this paper we introduce a generative parametric model capable of producing high quality samples of natural images. Our approach uses a cascade of convolutional networks within a Laplacian pyramid framework to generate images in a coarse-to-fine fashion. At each level of the pyramid, a separate generative convnet model is trained using the Generative Adversarial Nets (GAN) approach (Goodfellow et al.). Samples drawn from our model are of significantly higher quality than alternate approaches. In a quantitative assessment by human evaluators, our CIFAR10 samples were mistaken for real images around 40% of the time, compared to 10% for samples drawn from a GAN baseline model. We also show samples from models trained on the higher resolution images of the LSUN scene dataset.
An Incremental Reseeding Strategy for Clustering
Jun 15, 2014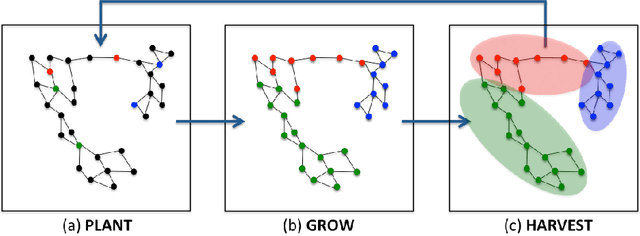

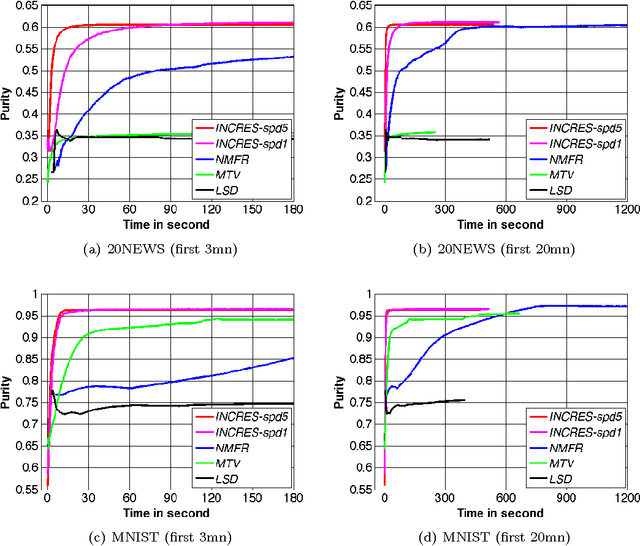
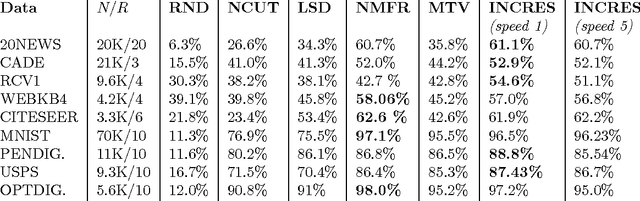
In this work we propose a simple and easily parallelizable algorithm for multiway graph partitioning. The algorithm alternates between three basic components: diffusing seed vertices over the graph, thresholding the diffused seeds, and then randomly reseeding the thresholded clusters. We demonstrate experimentally that the proper combination of these ingredients leads to an algorithm that achieves state-of-the-art performance in terms of cluster purity on standard benchmarks datasets. Moreover, the algorithm runs an order of magnitude faster than the other algorithms that achieve comparable results in terms of accuracy. We also describe a coarsen, cluster and refine approach similar to GRACLUS and METIS that removes an additional order of magnitude from the runtime of our algorithm while still maintaining competitive accuracy.
Spectral Networks and Locally Connected Networks on Graphs
May 21, 2014

Convolutional Neural Networks are extremely efficient architectures in image and audio recognition tasks, thanks to their ability to exploit the local translational invariance of signal classes over their domain. In this paper we consider possible generalizations of CNNs to signals defined on more general domains without the action of a translation group. In particular, we propose two constructions, one based upon a hierarchical clustering of the domain, and another based on the spectrum of the graph Laplacian. We show through experiments that for low-dimensional graphs it is possible to learn convolutional layers with a number of parameters independent of the input size, resulting in efficient deep architectures.
Better Feature Tracking Through Subspace Constraints
May 09, 2014


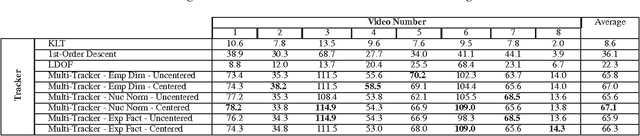
Feature tracking in video is a crucial task in computer vision. Usually, the tracking problem is handled one feature at a time, using a single-feature tracker like the Kanade-Lucas-Tomasi algorithm, or one of its derivatives. While this approach works quite well when dealing with high-quality video and "strong" features, it often falters when faced with dark and noisy video containing low-quality features. We present a framework for jointly tracking a set of features, which enables sharing information between the different features in the scene. We show that our method can be employed to track features for both rigid and nonrigid motions (possibly of few moving bodies) even when some features are occluded. Furthermore, it can be used to significantly improve tracking results in poorly-lit scenes (where there is a mix of good and bad features). Our approach does not require direct modeling of the structure or the motion of the scene, and runs in real time on a single CPU core.
Signal Recovery from Pooling Representations
Feb 27, 2014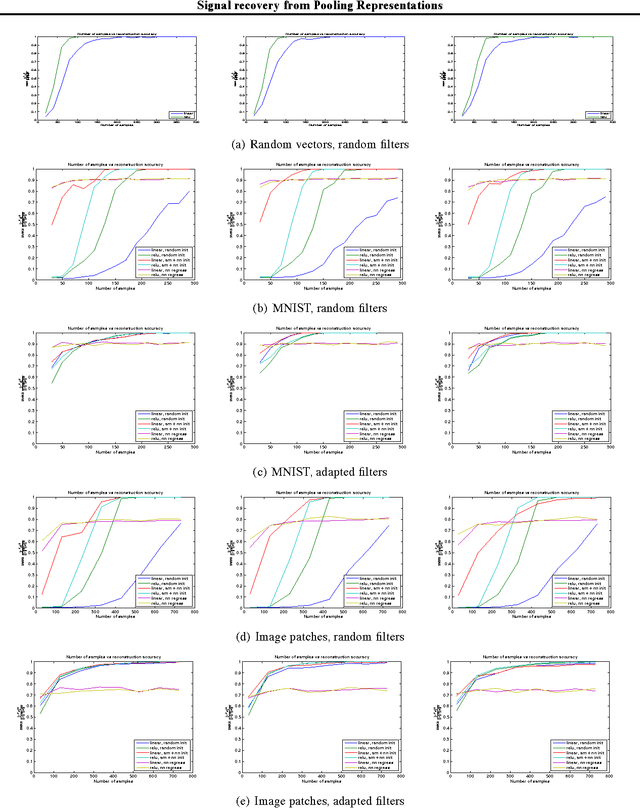
In this work we compute lower Lipschitz bounds of $\ell_p$ pooling operators for $p=1, 2, \infty$ as well as $\ell_p$ pooling operators preceded by half-rectification layers. These give sufficient conditions for the design of invertible neural network layers. Numerical experiments on MNIST and image patches confirm that pooling layers can be inverted with phase recovery algorithms. Moreover, the regularity of the inverse pooling, controlled by the lower Lipschitz constant, is empirically verified with a nearest neighbor regression.
Unsupervised Feature Learning by Deep Sparse Coding
Dec 20, 2013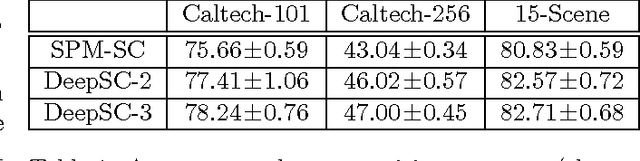
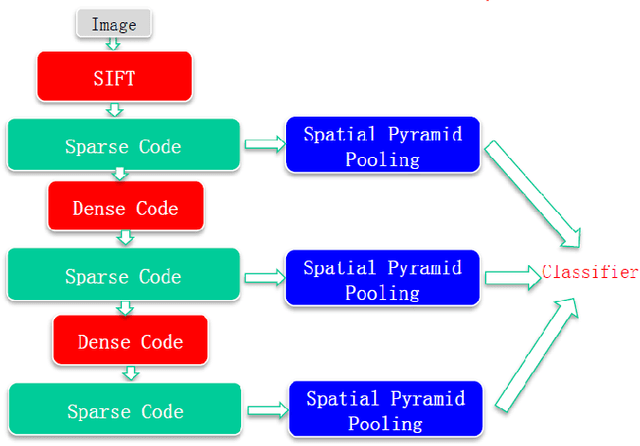
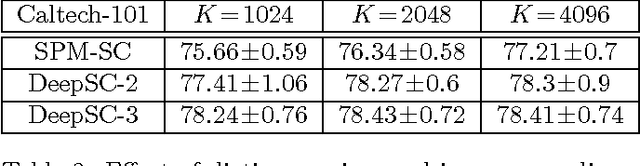

In this paper, we propose a new unsupervised feature learning framework, namely Deep Sparse Coding (DeepSC), that extends sparse coding to a multi-layer architecture for visual object recognition tasks. The main innovation of the framework is that it connects the sparse-encoders from different layers by a sparse-to-dense module. The sparse-to-dense module is a composition of a local spatial pooling step and a low-dimensional embedding process, which takes advantage of the spatial smoothness information in the image. As a result, the new method is able to learn several levels of sparse representation of the image which capture features at a variety of abstraction levels and simultaneously preserve the spatial smoothness between the neighboring image patches. Combining the feature representations from multiple layers, DeepSC achieves the state-of-the-art performance on multiple object recognition tasks.
Tree structured sparse coding on cubes
Jan 16, 2013
A brief description of tree structured sparse coding on the binary cube.
Learning Stable Group Invariant Representations with Convolutional Networks
Jan 16, 2013Transformation groups, such as translations or rotations, effectively express part of the variability observed in many recognition problems. The group structure enables the construction of invariant signal representations with appealing mathematical properties, where convolutions, together with pooling operators, bring stability to additive and geometric perturbations of the input. Whereas physical transformation groups are ubiquitous in image and audio applications, they do not account for all the variability of complex signal classes. We show that the invariance properties built by deep convolutional networks can be cast as a form of stable group invariance. The network wiring architecture determines the invariance group, while the trainable filter coefficients characterize the group action. We give explanatory examples which illustrate how the network architecture controls the resulting invariance group. We also explore the principle by which additional convolutional layers induce a group factorization enabling more abstract, powerful invariant representations.
Hybrid Linear Modeling via Local Best-fit Flats
May 01, 2012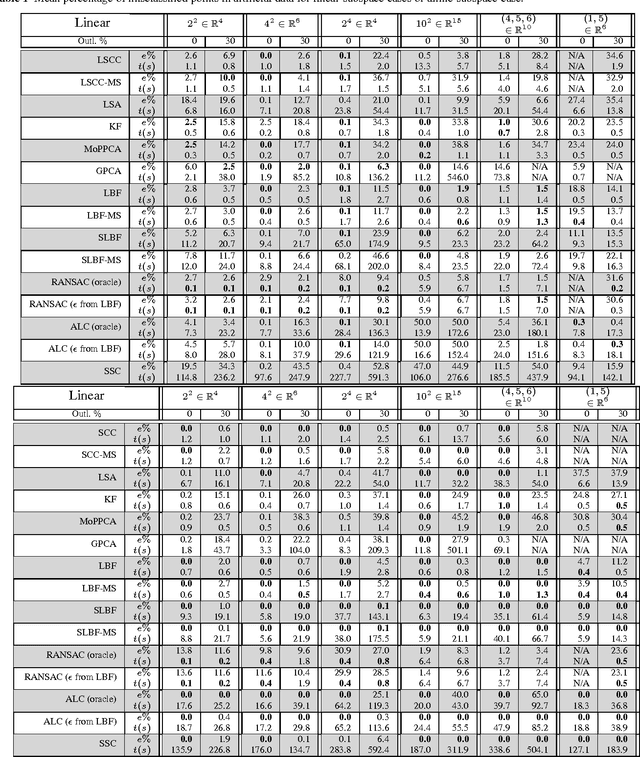
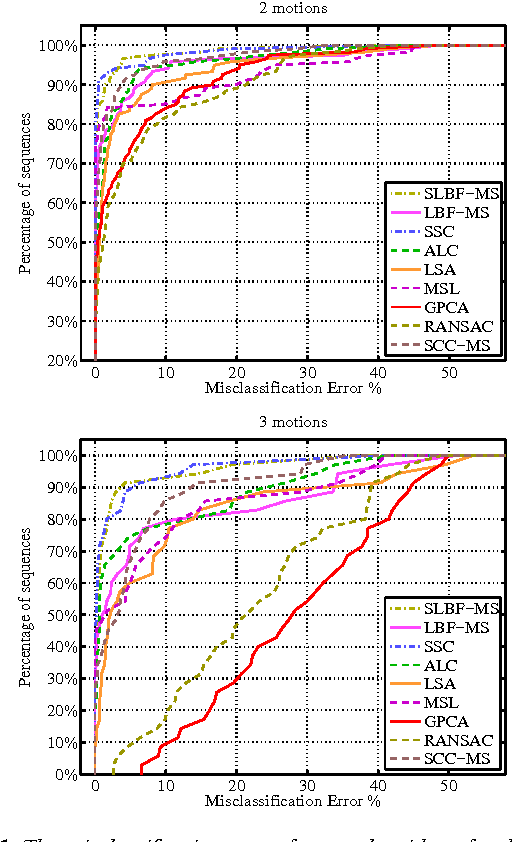


We present a simple and fast geometric method for modeling data by a union of affine subspaces. The method begins by forming a collection of local best-fit affine subspaces, i.e., subspaces approximating the data in local neighborhoods. The correct sizes of the local neighborhoods are determined automatically by the Jones' $\beta_2$ numbers (we prove under certain geometric conditions that our method finds the optimal local neighborhoods). The collection of subspaces is further processed by a greedy selection procedure or a spectral method to generate the final model. We discuss applications to tracking-based motion segmentation and clustering of faces under different illuminating conditions. We give extensive experimental evidence demonstrating the state of the art accuracy and speed of the suggested algorithms on these problems and also on synthetic hybrid linear data as well as the MNIST handwritten digits data; and we demonstrate how to use our algorithms for fast determination of the number of affine subspaces.
* This version adds some clarifications and numerical experiments as well as strengthens the previous theorem. For face experiments, we use here the Extended Yale Face Database B (cropped faces unlike previous version). This database points to a failure mode of our algorithms, but we suggest and successfully test a workaround