 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMD Aggregated Two-Sample Test
Oct 28, 2021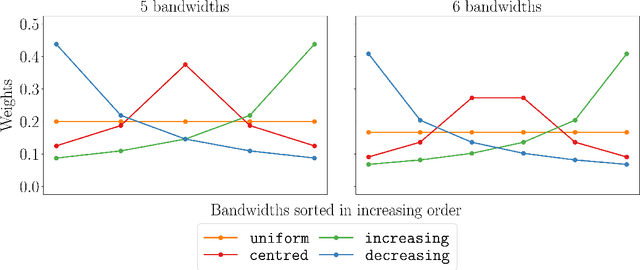
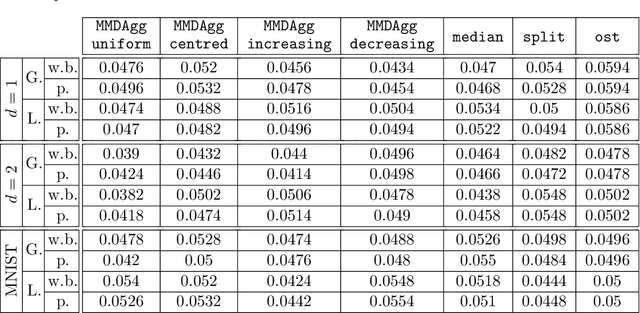
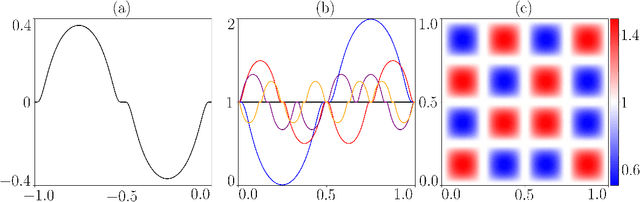
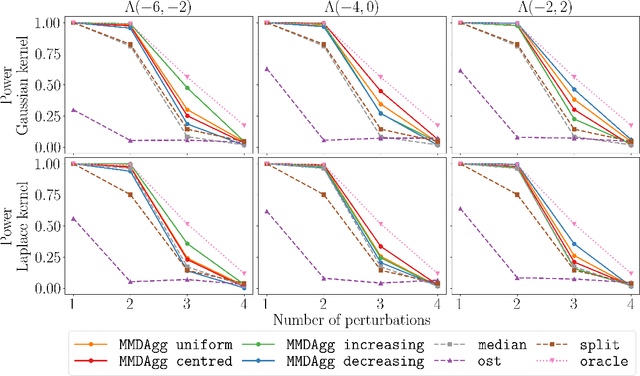
We propose a novel nonparametric two-sample test based on the Maximum Mean Discrepancy (MMD), which is constructed by aggregating tests with different kernel bandwidths. This aggregation procedure, called MMDAgg, ensures that test power is maximised over the collection of kernels used, without requiring held-out data for kernel selection (which results in a loss of test power), or arbitrary kernel choices such as the median heuristic. We work in the non-asymptotic framework, and prove that our aggregated test is minimax adaptive over Sobolev balls. Our guarantees are not restricted to a specific kernel, but hold for any product of one-dimensional translation invariant characteristic kernels which are absolutely and square integrable. Moreover, our results apply for popular numerical procedures to determine the test threshold, namely permutations and the wild bootstrap. Through numerical experiments on both synthetic and real-world datasets, we demonstrate that MMDAgg outperforms alternative state-of-the-art approaches to MMD kernel adaptation for two-sample testing.
KALE Flow: A Relaxed KL Gradient Flow for Probabilities with Disjoint Support
Jun 16, 2021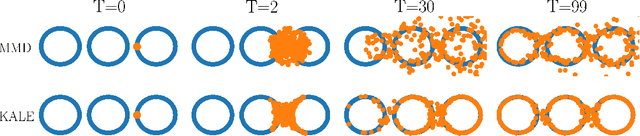

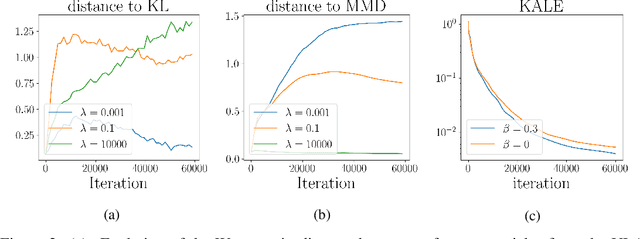
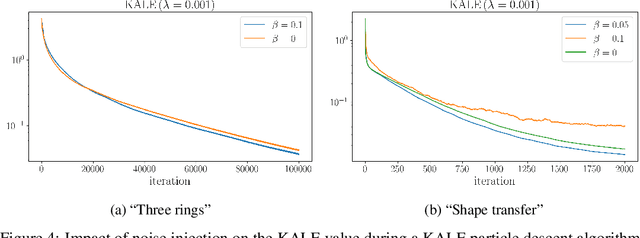
We study the gradient flow for a relaxed approximation to the Kullback-Leibler (KL) divergence between a moving source and a fixed target distribution. This approximation, termed the KALE (KL approximate lower-bound estimator), solves a regularized version of the Fenchel dual problem defining the KL over a restricted class of functions. When using a Reproducing Kernel Hilbert Space (RKHS) to define the function class, we show that the KALE continuously interpolates between the KL and the Maximum Mean Discrepancy (MMD). Like the MMD and other Integral Probability Metrics, the KALE remains well defined for mutually singular distributions. Nonetheless, the KALE inherits from the limiting KL a greater sensitivity to mismatch in the support of the distributions, compared with the MMD. These two properties make the KALE gradient flow particularly well suited when the target distribution is supported on a low-dimensional manifold. Under an assumption of sufficient smoothness of the trajectories, we show the global convergence of the KALE flow. We propose a particle implementation of the flow given initial samples from the source and the target distribution, which we use to empirically confirm the KALE's properties.
Self-Supervised Learning with Kernel Dependence Maximization
Jun 15, 2021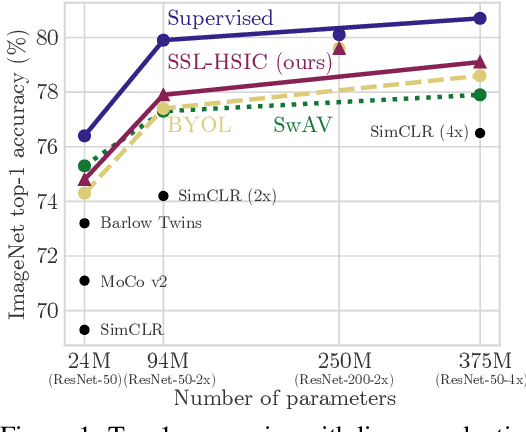
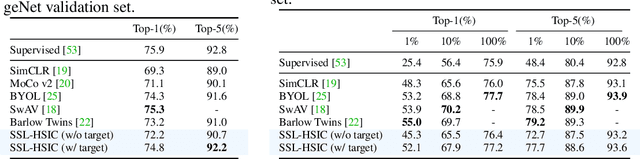
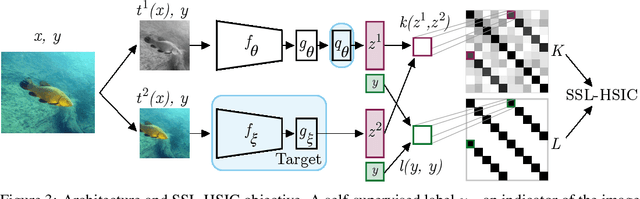
We approach self-supervised learning of image representations from a statistical dependence perspective, proposing Self-Supervised Learning with the Hilbert-Schmidt Independence Criterion (SSL-HSIC). SSL-HSIC maximizes dependence between representations of transformed versions of an image and the image identity, while minimizing the kernelized variance of those features. This self-supervised learning framework yields a new understanding of InfoNCE, a variational lower bound on the mutual information (MI) between different transformations. While the MI itself is known to have pathologies which can result in meaningless representations being learned, its bound is much better behaved: we show that it implicitly approximates SSL-HSIC (with a slightly different regularizer). Our approach also gives us insight into BYOL, since SSL-HSIC similarly learns local neighborhoods of samples. SSL-HSIC allows us to directly optimize statistical dependence in time linear in the batch size, without restrictive data assumptions or indirect mutual information estimators. Trained with or without a target network, SSL-HSIC matches the current state-of-the-art for standard linear evaluation on ImageNet, semi-supervised learning and transfer to other classification and vision tasks such as semantic segmentation, depth estimation and object recognition.
Deep Proxy Causal Learning and its Application to Confounded Bandit Policy Evaluation
Jun 07, 2021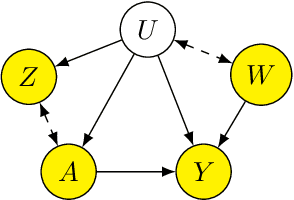
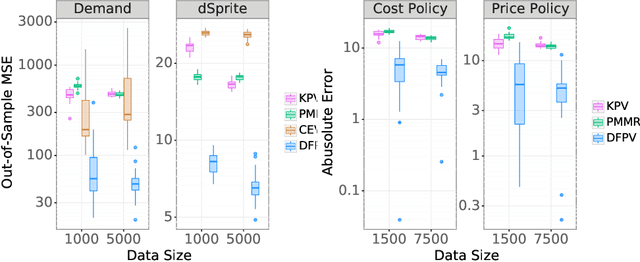

Proxy causal learning (PCL) is a method for estimating the causal effect of treatments on outcomes in the presence of unobserved confounding, using proxies (structured side information) for the confounder. This is achieved via two-stage regression: in the first stage, we model relations among the treatment and proxies; in the second stage, we use this model to learn the effect of treatment on the outcome, given the context provided by the proxies. PCL guarantees recovery of the true causal effect, subject to identifiability conditions. We propose a novel method for PCL, the deep feature proxy variable method (DFPV), to address the case where the proxies, treatments, and outcomes are high-dimensional and have nonlinear complex relationships, as represented by deep neural network features. We show that DFPV outperforms recent state-of-the-art PCL methods on challenging synthetic benchmarks, including settings involving high dimensional image data. Furthermore, we show that PCL can be applied to off-policy evaluation for the confounded bandit problem, in which DFPV also exhibits competitive performance.
Proximal Causal Learning with Kernels: Two-Stage Estimation and Moment Restriction
Jun 06, 2021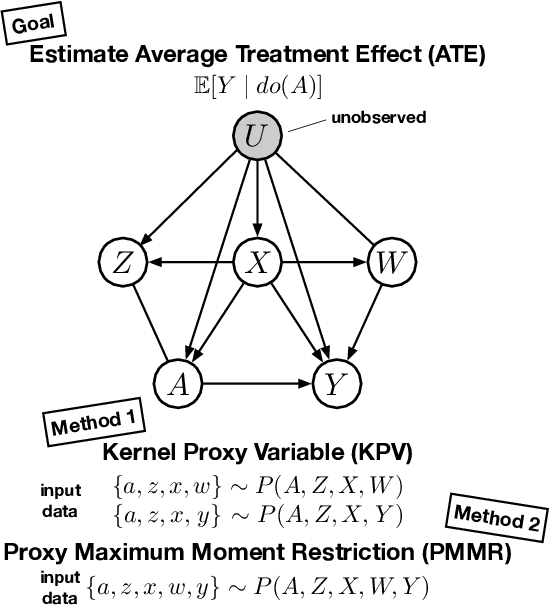
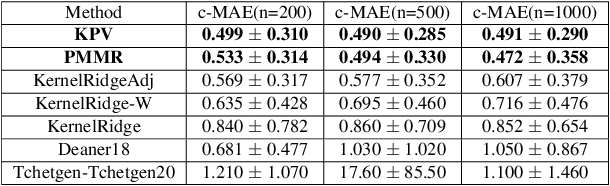
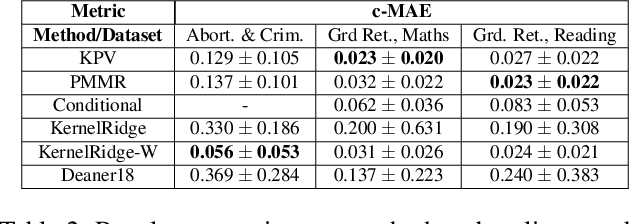
We address the problem of causal effect estimation in the presence of unobserved confounding, but where proxies for the latent confounder(s) are observed. We propose two kernel-based methods for nonlinear causal effect estimation in this setting: (a) a two-stage regression approach, and (b) a maximum moment restriction approach. We focus on the proximal causal learning setting, but our methods can be used to solve a wider class of inverse problems characterised by a Fredholm integral equation. In particular, we provide a unifying view of two-stage and moment restriction approaches for solving this problem in a nonlinear setting. We provide consistency guarantees for each algorithm, and we demonstrate these approaches achieve competitive results on synthetic data and data simulating a real-world task. In particular, our approach outperforms earlier methods that are not suited to leveraging proxy variables.
Towards an Understanding of Benign Overfitting in Neural Networks
Jun 06, 2021Modern machine learning models often employ a huge number of parameters and are typically optimized to have zero training loss; yet surprisingly, they possess near-optimal prediction performance, contradicting classical learning theory. We examine how these benign overfitting phenomena occur in a two-layer neural network setting where sample covariates are corrupted with noise. We address the high dimensional regime, where the data dimension $d$ grows with the number $n$ of data points. Our analysis combines an upper bound on the bias with matching upper and lower bounds on the variance of the interpolator (an estimator that interpolates the data). These results indicate that the excess learning risk of the interpolator decays under mild conditions. We further show that it is possible for the two-layer ReLU network interpolator to achieve a near minimax-optimal learning rate, which to our knowledge is the first generalization result for such networks. Finally, our theory predicts that the excess learning risk starts to increase once the number of parameters $s$ grows beyond $O(n^2)$, matching recent empirical findings.
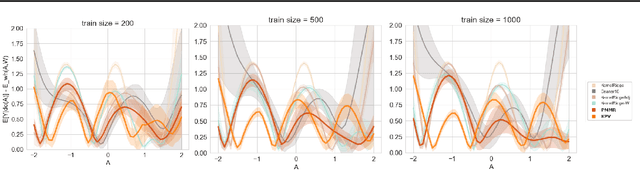
On Instrumental Variable Regression for Deep Offline Policy Evaluation
May 21, 2021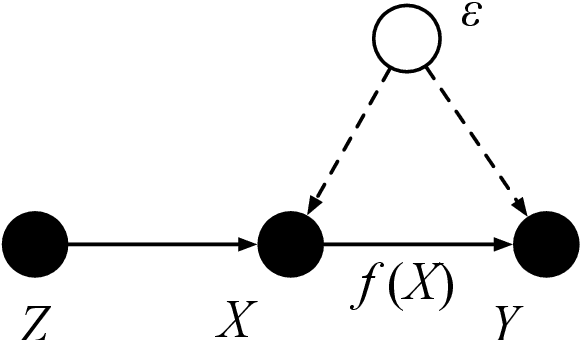
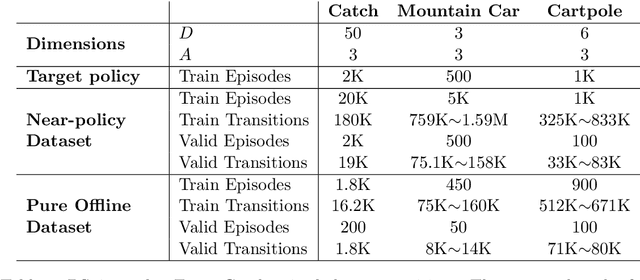
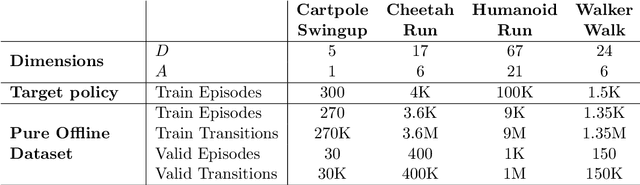
We show that the popular reinforcement learning (RL) strategy of estimating the state-action value (Q-function) by minimizing the mean squared Bellman error leads to a regression problem with confounding, the inputs and output noise being correlated. Hence, direct minimization of the Bellman error can result in significantly biased Q-function estimates. We explain why fixing the target Q-network in Deep Q-Networks and Fitted Q Evaluation provides a way of overcoming this confounding, thus shedding new light on this popular but not well understood trick in the deep RL literature. An alternative approach to address confounding is to leverage techniques developed in the causality literature, notably instrumental variables (IV). We bring together here the literature on IV and RL by investigating whether IV approaches can lead to improved Q-function estimates. This paper analyzes and compares a wide range of recent IV methods in the context of offline policy evaluation (OPE), where the goal is to estimate the value of a policy using logged data only. By applying different IV techniques to OPE, we are not only able to recover previously proposed OPE methods such as model-based techniques but also to obtain competitive new techniques. We find empirically that state-of-the-art OPE methods are closely matched in performance by some IV methods such as AGMM, which were not developed for OPE. We open-source all our code and datasets at https://github.com/liyuan9988/IVOPEwithACME.
A case for new neural network smoothness constraints
Dec 21, 2020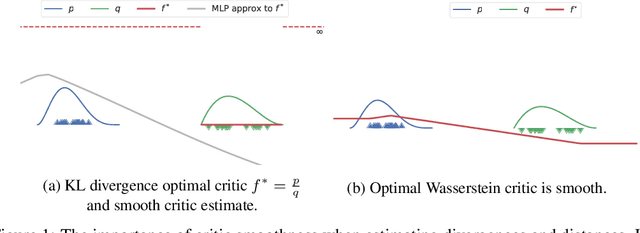
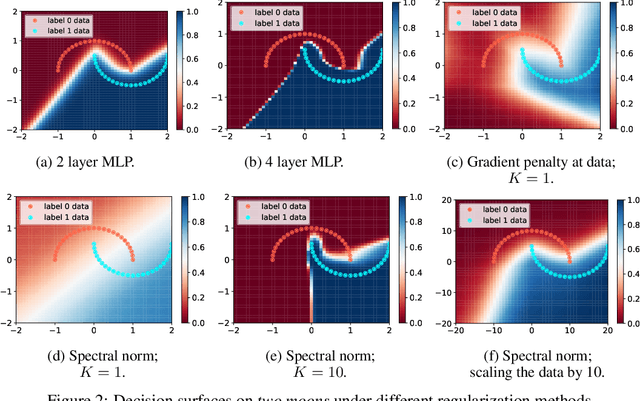
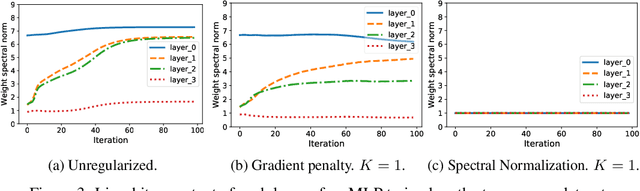
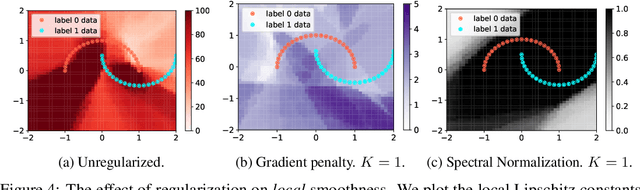
How sensitive should machine learning models be to input changes? We tackle the question of model smoothness and show that it is a useful inductive bias which aids generalization, adversarial robustness, generative modeling and reinforcement learning. We explore current methods of imposing smoothness constraints and observe they lack the flexibility to adapt to new tasks, they don't account for data modalities, they interact with losses, architectures and optimization in ways not yet fully understood. We conclude that new advances in the field are hinging on finding ways to incorporate data, tasks and learning into our definitions of smoothness.
A kernel test for quasi-independence
Nov 17, 2020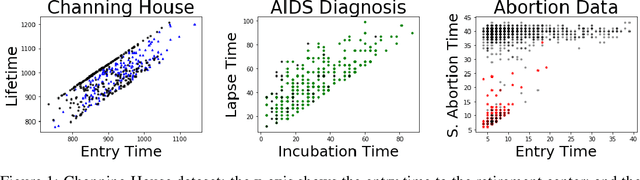
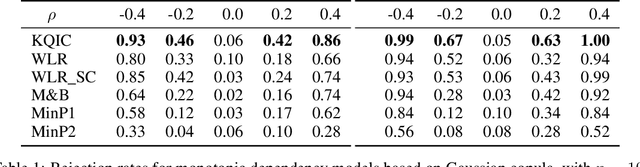
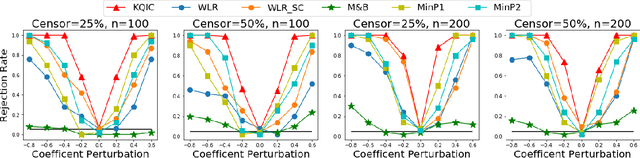

We consider settings in which the data of interest correspond to pairs of ordered times, e.g, the birth times of the first and second child, the times at which a new user creates an account and makes the first purchase on a website, and the entry and survival times of patients in a clinical trial. In these settings, the two times are not independent (the second occurs after the first), yet it is still of interest to determine whether there exists significant dependence {\em beyond} their ordering in time. We refer to this notion as "quasi-(in)dependence". For instance, in a clinical trial, to avoid biased selection, we might wish to verify that recruitment times are quasi-independent of survival times, where dependencies might arise due to seasonal effects. In this paper, we propose a nonparametric statistical test of quasi-independence. Our test considers a potentially infinite space of alternatives, making it suitable for complex data where the nature of the possible quasi-dependence is not known in advance. Standard parametric approaches are recovered as special cases, such as the classical conditional Kendall's tau, and log-rank tests. The tests apply in the right-censored setting: an essential feature in clinical trials, where patients can withdraw from the study. We provide an asymptotic analysis of our test-statistic, and demonstrate in experiments that our test obtains better power than existing approaches, while being more computationally efficient.
Kernel Dependence Network
Nov 09, 2020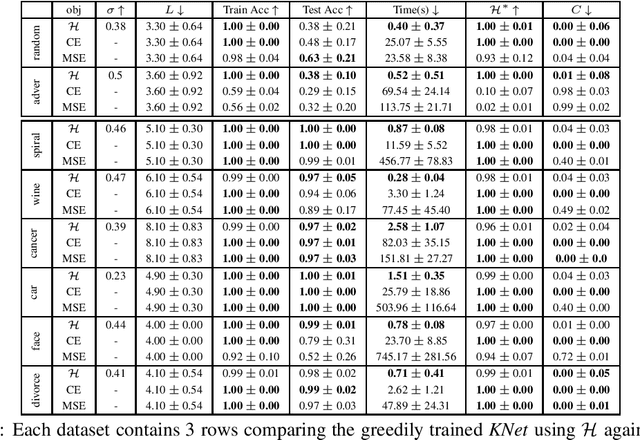
We propose a greedy strategy to spectrally train a deep network for multi-class classification. Each layer is defined as a composition of linear weights with the feature map of a Gaussian kernel acting as the activation function. At each layer, the linear weights are learned by maximizing the dependence between the layer output and the labels using the Hilbert Schmidt Independence Criterion (HSIC). By constraining the solution space on the Stiefel Manifold, we demonstrate how our network construct (Kernel Dependence Network or KNet) can be solved spectrally while leveraging the eigenvalues to automatically find the width and the depth of the network. We theoretically guarantee the existence of a solution for the global optimum while providing insight into our network's ability to generalize.
* arXiv admin note: substantial text overlap with arXiv:2006.08539