 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYaART: Yet Another ART Rendering Technology
Apr 08, 2024



In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
QUASAR: QUality and Aesthetics Scoring with Advanced Representations
Mar 20, 2024



This paper introduces a new data-driven, non-parametric method for image quality and aesthetics assessment, surpassing existing approaches and requiring no prompt engineering or fine-tuning. We eliminate the need for expressive textual embeddings by proposing efficient image anchors in the data. Through extensive evaluations of 7 state-of-the-art self-supervised models, our method demonstrates superior performance and robustness across various datasets and benchmarks. Notably, it achieves high agreement with human assessments even with limited data and shows high robustness to the nature of data and their pre-processing pipeline. Our contributions offer a streamlined solution for assessment of images while providing insights into the perception of visual information.
Extreme Compression of Large Language Models via Additive Quantization
Jan 11, 2024



The emergence of accurate open large language models (LLMs) has led to a race towards quantization techniques for such models enabling execution on end-user devices. In this paper, we revisit the problem of "extreme" LLM compression--defined as targeting extremely low bit counts, such as 2 to 3 bits per parameter, from the point of view of classic methods in Multi-Codebook Quantization (MCQ). Our work builds on top of Additive Quantization, a classic algorithm from the MCQ family, and adapts it to the quantization of language models. The resulting algorithm advances the state-of-the-art in LLM compression, outperforming all recently-proposed techniques in terms of accuracy at a given compression budget. For instance, when compressing Llama 2 models to 2 bits per parameter, our algorithm quantizes the 7B model to 6.93 perplexity (a 1.29 improvement relative to the best prior work, and 1.81 points from FP16), the 13B model to 5.70 perplexity (a .36 improvement) and the 70B model to 3.94 perplexity (a .22 improvement) on WikiText2. We release our implementation of Additive Quantization for Language Models AQLM as a baseline to facilitate future research in LLM quantization.
Your Student is Better Than Expected: Adaptive Teacher-Student Collaboration for Text-Conditional Diffusion Models
Dec 28, 2023



Knowledge distillation methods have recently shown to be a promising direction to speedup the synthesis of large-scale diffusion models by requiring only a few inference steps. While several powerful distillation methods were recently proposed, the overall quality of student samples is typically lower compared to the teacher ones, which hinders their practical usage. In this work, we investigate the relative quality of samples produced by the teacher text-to-image diffusion model and its distilled student version. As our main empirical finding, we discover that a noticeable portion of student samples exhibit superior fidelity compared to the teacher ones, despite the ``approximate'' nature of the student. Based on this finding, we propose an adaptive collaboration between student and teacher diffusion models for effective text-to-image synthesis. Specifically, the distilled model produces the initial sample, and then an oracle decides whether it needs further improvements with a slow teacher model. Extensive experiments demonstrate that the designed pipeline surpasses state-of-the-art text-to-image alternatives for various inference budgets in terms of human preference. Furthermore, the proposed approach can be naturally used in popular applications such as text-guided image editing and controllable generation.
TabR: Unlocking the Power of Retrieval-Augmented Tabular Deep Learning
Jul 26, 2023



Deep learning (DL) models for tabular data problems are receiving increasingly more attention, while the algorithms based on gradient-boosted decision trees (GBDT) remain a strong go-to solution. Following the recent trends in other domains, such as natural language processing and computer vision, several retrieval-augmented tabular DL models have been recently proposed. For a given target object, a retrieval-based model retrieves other relevant objects, such as the nearest neighbors, from the available (training) data and uses their features or even labels to make a better prediction. However, we show that the existing retrieval-based tabular DL solutions provide only minor, if any, benefits over the properly tuned simple retrieval-free baselines. Thus, it remains unclear whether the retrieval-based approach is a worthy direction for tabular DL. In this work, we give a strong positive answer to this question. We start by incrementally augmenting a simple feed-forward architecture with an attention-like retrieval component similar to those of many (tabular) retrieval-based models. Then, we highlight several details of the attention mechanism that turn out to have a massive impact on the performance on tabular data problems, but that were not explored in prior work. As a result, we design TabR -- a simple retrieval-based tabular DL model which, on a set of public benchmarks, demonstrates the best average performance among tabular DL models, becomes the new state-of-the-art on several datasets, and even outperforms GBDT models on the recently proposed ``GBDT-friendly'' benchmark (see the first figure).
Towards Real-time Text-driven Image Manipulation with Unconditional Diffusion Models
Apr 10, 2023



Recent advances in diffusion models enable many powerful instruments for image editing. One of these instruments is text-driven image manipulations: editing semantic attributes of an image according to the provided text description. % Popular text-conditional diffusion models offer various high-quality image manipulation methods for a broad range of text prompts. Existing diffusion-based methods already achieve high-quality image manipulations for a broad range of text prompts. However, in practice, these methods require high computation costs even with a high-end GPU. This greatly limits potential real-world applications of diffusion-based image editing, especially when running on user devices. In this paper, we address efficiency of the recent text-driven editing methods based on unconditional diffusion models and develop a novel algorithm that learns image manipulations 4.5-10 times faster and applies them 8 times faster. We carefully evaluate the visual quality and expressiveness of our approach on multiple datasets using human annotators. Our experiments demonstrate that our algorithm achieves the quality of much more expensive methods. Finally, we show that our approach can adapt the pretrained model to the user-specified image and text description on the fly just for 4 seconds. In this setting, we notice that more compact unconditional diffusion models can be considered as a rational alternative to the popular text-conditional counterparts.
Evaluating Robustness and Uncertainty of Graph Models Under Structural Distributional Shifts
Feb 27, 2023



In reliable decision-making systems based on machine learning, models have to be robust to distributional shifts or provide the uncertainty of their predictions. In node-level problems of graph learning, distributional shifts can be especially complex since the samples are interdependent. To evaluate the performance of graph models, it is important to test them on diverse and meaningful distributional shifts. However, most graph benchmarks that consider distributional shifts for node-level problems focus mainly on node features, while data in graph problems is primarily defined by its structural properties. In this work, we propose a general approach for inducing diverse distributional shifts based on graph structure. We use this approach to create data splits according to several structural node properties: popularity, locality, and density. In our experiments, we thoroughly evaluate the proposed distributional shifts and show that they are quite challenging for existing graph models. We hope that the proposed approach will be helpful for the further development of reliable graph machine learning.
A critical look at the evaluation of GNNs under heterophily: are we really making progress?
Feb 22, 2023



Node classification is a classical graph representation learning task on which Graph Neural Networks (GNNs) have recently achieved strong results. However, it is often believed that standard GNNs only work well for homophilous graphs, i.e., graphs where edges tend to connect nodes of the same class. Graphs without this property are called heterophilous, and it is typically assumed that specialized methods are required to achieve strong performance on such graphs. In this work, we challenge this assumption. First, we show that the standard datasets used for evaluating heterophily-specific models have serious drawbacks, making results obtained by using them unreliable. The most significant of these drawbacks is the presence of a large number of duplicate nodes in the datsets Squirrel and Chameleon, which leads to train-test data leakage. We show that removing duplicate nodes strongly affects GNN performance on these datasets. Then, we propose a set of heterophilous graphs of varying properties that we believe can serve as a better benchmark for evaluating the performance of GNNs under heterophily. We show that standard GNNs achieve strong results on these heterophilous graphs, almost always outperforming specialized models. Our datasets and the code for reproducing our experiments are available at https://github.com/yandex-research/heterophilous-graphs
Is This Loss Informative? Speeding Up Textual Inversion with Deterministic Objective Evaluation
Feb 09, 2023Text-to-image generation models represent the next step of evolution in image synthesis, offering natural means of flexible yet fine-grained control over the result. One emerging area of research is the rapid adaptation of large text-to-image models to smaller datasets or new visual concepts. However, the most efficient method of adaptation, called textual inversion, has a known limitation of long training time, which both restricts practical applications and increases the experiment time for research. In this work, we study the training dynamics of textual inversion, aiming to speed it up. We observe that most concepts are learned at early stages and do not improve in quality later, but standard model convergence metrics fail to indicate that. Instead, we propose a simple early stopping criterion that only requires computing the textual inversion loss on the same inputs for all training iterations. Our experiments on both Latent Diffusion and Stable Diffusion models for 93 concepts demonstrate the competitive performance of our method, speeding adaptation up to 15 times with no significant drops in quality.
TabDDPM: Modelling Tabular Data with Diffusion Models
Sep 30, 2022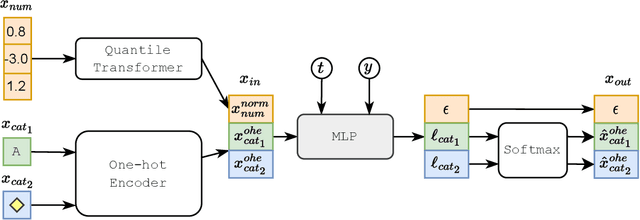
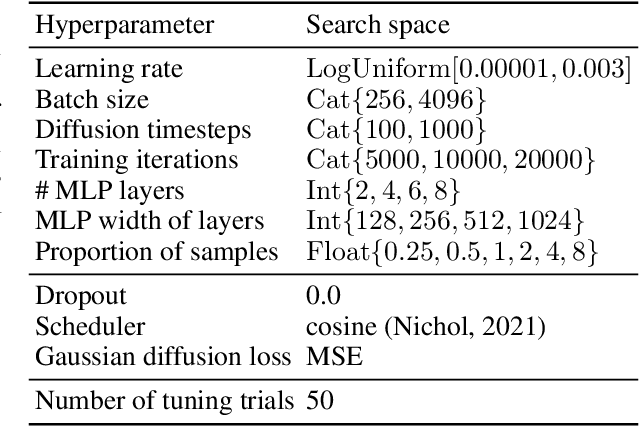
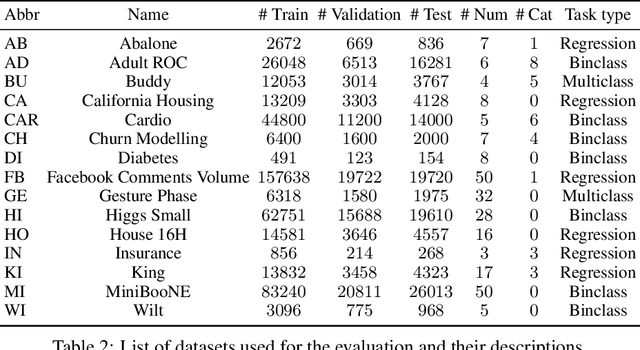
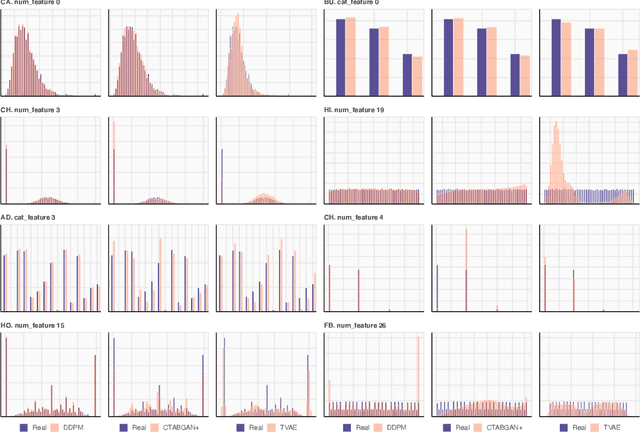
Denoising diffusion probabilistic models are currently becoming the leading paradigm of generative modeling for many important data modalities. Being the most prevalent in the computer vision community, diffusion models have also recently gained some attention in other domains, including speech, NLP, and graph-like data. In this work, we investigate if the framework of diffusion models can be advantageous for general tabular problems, where datapoints are typically represented by vectors of heterogeneous features. The inherent heterogeneity of tabular data makes it quite challenging for accurate modeling, since the individual features can be of completely different nature, i.e., some of them can be continuous and some of them can be discrete. To address such data types, we introduce TabDDPM -- a diffusion model that can be universally applied to any tabular dataset and handles any type of feature. We extensively evaluate TabDDPM on a wide set of benchmarks and demonstrate its superiority over existing GAN/VAE alternatives, which is consistent with the advantage of diffusion models in other fields. Additionally, we show that TabDDPM is eligible for privacy-oriented setups, where the original datapoints cannot be publicly shared.